Storm集群部署及单词技术
1、 集群部署的基本流程
集群部署的流程:下载安装包、解压安装包、修改配置文件、分发安装包、启动集群
注意:
所有的集群上都需要配置hosts
vi /etc/hosts
192.168.239.128 storm01 zk01 hadoop01
192.168.239.129 storm02 zk02 hadoop02
192.168.239.130 storm03 zk03 hadoop03
1、 集群部署的基础环境准备
安装前的准备工作(zk集群已经部署完毕)
l 关闭防火墙
chkconfig iptables off && setenforce 0
l 创建用户
groupadd realtime && useradd realtime && usermod -a -G realtime realtime
l 创建工作目录并赋权
mkdir /export
mkdir /export/servers
chmod 755 -R /export
l 切换到realtime用户下
su realtime
3、Storm集群部署
3.1、下载安装包
3.2、解压安装包
tar -zxvf apache-storm-0.9.5.tar.gz -C /export/servers/
cd /export/servers/
ln -s apache-storm-0.9.5 storm
3.3、修改配置文件
mv /export/servers/storm/conf/storm.yaml /export/servers/storm/conf/storm.yaml.bak
vi /export/servers/storm/conf/storm.yaml
输入以下内容:

3.4、分发安装包
scp -r /export/servers/apache-storm-0.9.5 storm02:/export/servers
然后分别在各机器上创建软连接
cd /export/servers/
ln -s apache-storm-0.9.5 storm
3.5、启动集群
l 在nimbus.host所属的机器上启动 nimbus服务
cd /export/servers/storm/bin/
nohup ./storm nimbus &
l 在nimbus.host所属的机器上启动ui服务
cd /export/servers/storm/bin/
nohup ./storm ui &
l 在其它个点击上启动supervisor服务
cd /export/servers/storm/bin/
nohup ./storm supervisor &
3.6、查看集群
访问nimbus.host:/8080,即可看到storm的ui界面。

4、Storm常用操作命令
有许多简单且有用的命令可以用来管理拓扑,它们可以提交、杀死、禁用、再平衡拓扑。
l 提交任务命令格式:storm jar 【jar路径】 【拓扑包名.拓扑类名】 【拓扑名称】
bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.6.jar storm.starter.WordCountTopology wordcount
l 杀死任务命令格式:storm kill 【拓扑名称】 -w 10(执行kill命令时可以通过-w [等待秒数]指定拓扑停用以后的等待时间)
storm kill topology-name -w 10
l 停用任务命令格式:storm deactivte 【拓扑名称】
storm deactivte topology-name
我们能够挂起或停用运行中的拓扑。当停用拓扑时,所有已分发的元组都会得到处理,但是spouts的nextTuple方法不会被调用。销毁一个拓扑,可以使用kill命令。它会以一种安全的方式销毁一个拓扑,首先停用拓扑,在等待拓扑消息的时间段内允许拓扑完成当前的数据流。
l 启用任务命令格式:storm activate【拓扑名称】
storm activate topology-name
l 重新部署任务命令格式:storm rebalance 【拓扑名称】
storm rebalance topology-name
再平衡使你重分配集群任务。这是个很强大的命令。比如,你向一个运行中的集群增加了节点。再平衡命令将会停用拓扑,然后在相应超时时间之后重分配工人,并重启拓扑。
5、Storm集群的进程及日志熟悉
5.1、部署成功之后,启动storm集群。
依次启动集群的各种角色
5.2、查看nimbus的日志信息
在nimbus的服务器上
cd /export/servers/storm/logs
tail -100f /export/servers/storm/logs/nimbus.log
5.3、查看ui运行日志信息
在ui的服务器上,一般和nimbus一个服务器
cd /export/servers/storm/logs
tail -100f /export/servers/storm/logs/ui.log
5.4、查看supervisor运行日志信息
在supervisor服务上
cd /export/servers/storm/logs
tail -100f /export/servers/storm/logs/supervisor.log
5.5、查看supervisor上worker运行日志信息
在supervisor服务上
cd /export/servers/storm/logs
tail -100f /export/servers/storm/logs/worker-6702.log
 (该worker正在运行wordcount程序)
(该worker正在运行wordcount程序)
6、Storm源码下载及目录熟悉
6.1、在Storm官方网站上寻找源码地址
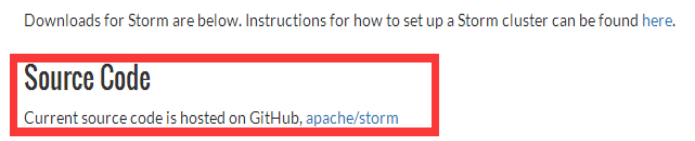
6.2、点击文字标签进入github
点击Apache/storm文字标签,进入github
https://github.com/apache/storm
6.3、拷贝storm源码地址
在网页右侧,拷贝storm源码地址

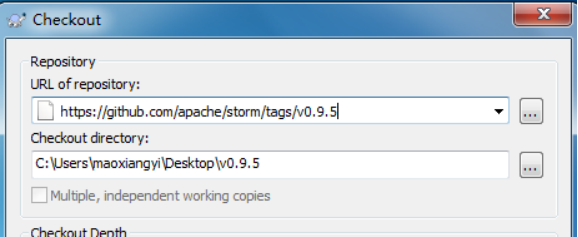
6.4、使用Subversion客户端下载
6.5、Storm源码目录分析(重要)

扩展包中的三个项目,使storm能与hbase、hdfs、kafka交互

7、Storm单词技术案例(重点掌握)
7.1、功能说明
设计一个topology,来实现对文档里面的单词出现的频率进行统计。
整个topology分为三个部分:
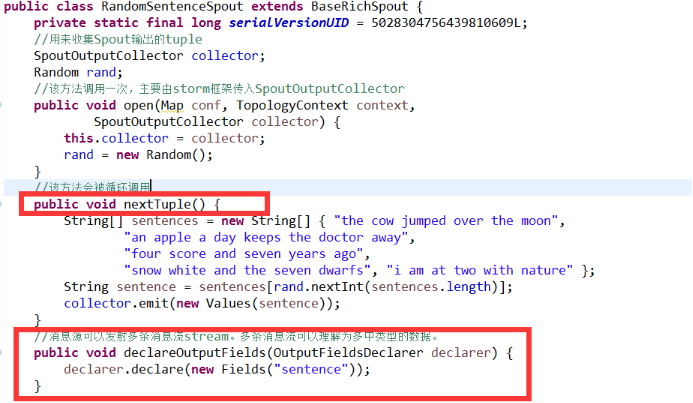
l RandomSentenceSpout:数据源,在已知的英文句子中,随机发送一条句子出去。
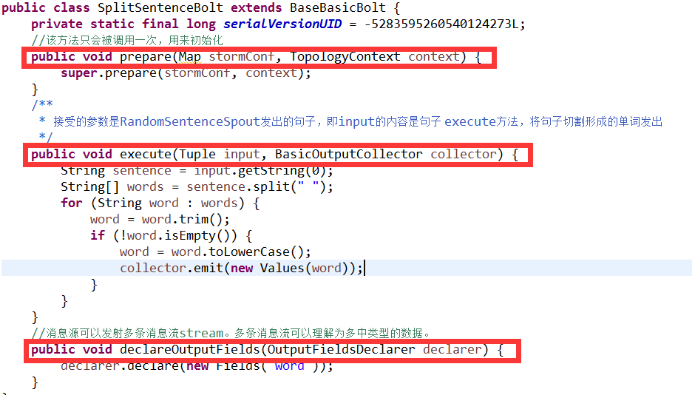
l SplitSentenceBolt:负责将单行文本记录(句子)切分成单词
l WordCountBolt:负责对单词的频率进行累加
7.2、项目主要流程

7.3、RandomSentenceSpout的实现及生命周期
7.4、SplitSentenceBolt的实现及生命周期
7.5、WordCountBolt的实现及生命周期
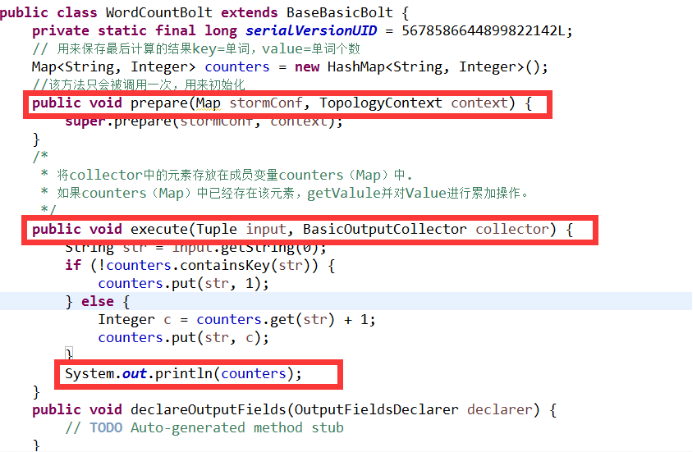
7.6、Stream Grouping详解
Storm里面有7种类型的stream grouping
l Shuffle Grouping: 随机分组, 随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同。
l Fields Grouping:按字段分组,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts里的一个task,而不同的userid则会被分配到不同的bolts里的task。
l All Grouping:广播发送,对于每一个tuple,所有的bolts都会收到。
l Global Grouping:全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
l Non Grouping:不分组,这stream grouping个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。
l Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)。
l Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发生给这些tasks。否则,和普通的Shuffle Grouping行为一致。
Storm集群部署及单词技术的更多相关文章
- 2.Storm集群部署及单词统计案例
1.集群部署的基本流程 2.集群部署的基础环境准备 3.Storm集群部署 4.Storm集群的进程及日志熟悉 5.Storm集群的常用操作命令 6.Storm源码下载及目录熟悉 7.Storm 单词 ...
- Storm 系列(三)Storm 集群部署和配置
Storm 系列(二)Storm 集群部署和配置 本章中主要介绍了 Storm 的部署过程以及相关的配置信息.通过本章内容,帮助读者从零开始搭建一个 Storm 集群. 一.Storm 的依赖组件 1 ...
- storm集群部署和配置过程详解
先整体介绍一下搭建storm集群的步骤: 设置zookeeper集群 安装依赖到所有nimbus和worker节点 下载并解压storm发布版本到所有nimbus和worker节点 配置storm ...
- Storm集群部署
一. 说明 Storm是一个分布式实时计算系统,Storm对于实时计算的意义就相当于Hadoop对于批量计算的意义.对于实时性较高的系统Storm是不错的选择.Hadoop提供了map, reduce ...
- Storm1.0.3集群部署
Storm集群部署 所有集群部署的基本流程都差不多:下载安装包并上传.解压安装包并配置环境变量.修改配置文件.分发安装包.启动集群.查看集群是否部署成功. 1.所有的集群上都要配置hosts vi ...
- 02_Storm集群部署
1. 部署前的硬件及软件检查 硬件要求 1)storm集群部署包括zookeeper部署,而zookeeper集群最小为3台机器2)storm的计算过程都在内存中完成,因此内存要尽量大3)storm少 ...
- Storm集群安装部署步骤【详细版】
作者: 大圆那些事 | 文章可以转载,请以超链接形式标明文章原始出处和作者信息 网址: http://www.cnblogs.com/panfeng412/archive/2012/11/30/how ...
- Storm入门教程 第三章Storm集群安装部署步骤、storm开发环境
一. Storm集群组件 Storm集群中包含两类节点:主控节点(Master Node)和工作节点(Work Node).其分别对应的角色如下: 主控节点(Master Node)上运行一个被称为N ...
- Storm集群安装部署步骤
本文以Twitter Storm官方Wiki为基础,详细描述如何快速搭建一个Storm集群,其中,项目实践中遇到的问题及经验总结,在相应章节以"注意事项"的形式给出. 1. Sto ...
随机推荐
- ActiveReports报表控件V11 SP1版本正式发布!
无需编码,即可轻松搞定商业报表六大需求的 ActiveReports 报表控件,于今日宣布正式发布 V11 SP1 版本,并在其 官方网站 提供免费下载. V11 版本是 ActiveReports ...
- poj1655(dfs,树形dp,树的重心)
这是找树的重心的经典题目. 树的重心有下面几条常见性质: 定义1:找到一个点,其所有的子树中最大的子树节点数最少,那么这个点就是这棵树的重心.定义2:以这个点为根,那么所有的子树(不算整个树自身)的大 ...
- php str_pad() 用法
$temp = str_pad(" ", 10000); for($i=0;$i<20;$i++){ echo $temp; echo $i; sle ...
- HDU - 6231:K-th Number (不错的二分)
Alice are given an array A[1..N]A[1..N] with NN numbers. Now Alice want to build an array BB by a pa ...
- UltraEdit工具安装和注册机破解
1.关闭网络连接(或者直接拔掉网线). 2.打开UltraEdit软件,稍等片刻会出现提示你你使用的是试用版本的窗口.如下图,点击“注册”. 3.填写许可证id和密码.许可证id可任意填写,不过根据经 ...
- SVN客户端与服务器端搭建操作
一.客户端的安装 1.点击安装程序 2.修改svn安装位置 3.开始安装 4.客户端安装成功 5.回到左面 右键出现svn检出 tortoiSVN 表示安装成功 Myeclipse svn插件安装 ...
- C# 自定义exe引用的dll路径
MSDN原文:https://msdn.microsoft.com/library/twy1dw1e(v=vs.100).aspx <runtime> 的 <assemblyBind ...
- Pycharm简单使用教程
转自https://blog.csdn.net/qq_40130759/article/details/79421242 1.下载pycharm pycharm是一种Python IDE,能够帮助我们 ...
- C# 用wps(api v9) 将word转成pdf
我们不产生代码只是代码的搬运工 我们先来看一段跑不起来的代码 ..各种未将对象应用到实例.. using System; using System.Collections.Generic; usin ...
- 使用 key 登录时分开记录操作历史记录
线上服务器一般都是配置 key 登录,一个账号可以多个工作人员连接,操作命令历史却全部记录在一个文件中,当然后查看某条命令是谁执行的时候就不好查了.这时候我们就可以通过配置 histroy 相关环境变 ...