SQL的执行需要编译和解析
Statement每次的执行都需要编译SQL
PreparedStatement会预编译,会被缓冲,在缓存区中可以发现预编译的命令,虽然会被再次解析,但不会被再次编译,能够有效提高系统性能
使用PreparedStatement能够预防SQL注入攻击
假如登录SQL为select * from user where name='姓名' and password='密码' ,如果在登录框密码处输入 “密码 or 1=1”,那么SQL就成为了
select * from user where name='姓名' and password='密码' or 1=1 ,这就是SQL注入
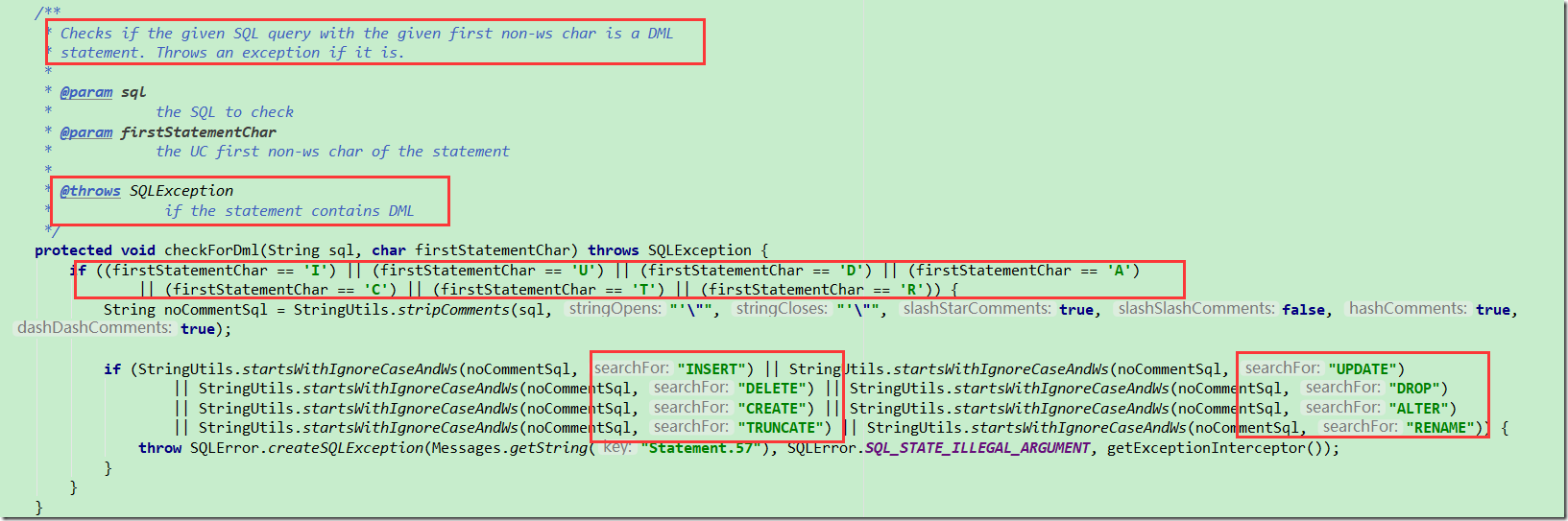
所谓SQL注入就是将SQL语句片段插入到被执行的语句中,把SQL命令插入到Web表单提交或者输入域名或者页面请求的查询字符串,最终达到欺骗服务器,达到执行恶意SQL命令的目的。
PreparedStatement通过预编译,原有的SQL语句中的参数转换为占位符? 的形式,相当于变成了填空题,不管你输入的内容是什么,都是作为参数,而不可能作为SQL的一部分
(要注意 #与$的区别)
你把密码输入为‘密码 or 1=1’然后提交,他会转换为 and password='密码' or 1=1' 输入内容都转换为纯粹参数
小结:
静态SQL可以用Statement和PreparedStatement,带参数的用PreparedStatement,存储过程用CallableStatement
但是基本上没有道理非要使用Statement,而且很少情况不需要参数,所以能使用PreparedStatement的情况下就不要使用Statement了
Statement、PreparedStatement和CallableStatement三种执行对象,为执行SQL而生,所以他们的重中之重全都是执行SQL
Statement详解
Statement有四种形式的执行
- executeQuery
- executeUpdate
- execute
- Batch
executeQuery
用于产生单个结果集的语句,用于执行 SELECT 语句(SELECT无疑是是使用最多的 SQL 语句) ,返回值为ResultSet
executeUpdate
用于执行 INSERT、UPDATE 或 DELETE 语句以及 SQL DDL(数据定义语言)语句,例如 CREATE TABLE 和 DROP TABLE。
executeUpdate 的返回值是一个整数,指示受影响的行数(即更新计数)。对于 CREATE TABLE 或 DROP TABLE 等不操作行的语句,executeUpdate 的返回值总为零。
execute
用于执行返回多个结果集、多个更新计数或二者组合的语句。execute对与结果的处理比较麻烦
execute方法应该仅在语句能返回多个ResultSet对象、多个更新计数或ResultSet对象与更新计数的组合时使用。
返回值指示类型情况:如果下一个结果为 ResultSet 对象,则返回 true;如果其为更新计数或者不存在更多结果,则返回 false
小结:
executeQuery 执行SELECT,返回结果集
executeUpdate 执行INSERT UPDATE DELETE 以及SQL DDL(数据定义语言)语句,返回受影响的行
execute可以执行所有SQL,所以他可能返回结果集,也可能返回受影响的行
所以execute的返回值用于区分是返回的结果集还是受影响的行,换句话说,true表示SELECT false表示INSERT UPDATE DELETE
如果是返回结果集,必须使用方法 getResultSet 或 getUpdateCount 来获取结果,使用 getMoreResults 来移动后续结果。
=================================================================================
executeQuery
ResultSet executeQuery(String sql)
执行给定的 SQL 语句,该语句返回单个 ResultSet 对象
executeQuery只能够用来查询,比如试图进行插入操作,将会抛出一样
内部有校验方法
=================================================================================
executeUpdate
int executeUpdate(String sql)
执行给定 SQL 语句,该语句可能为 INSERT、UPDATE 或 DELETE 语句,或者不返回任何内容的 SQL 语句(如 SQL DDL 语句)
int executeUpdate(String sql, int autoGeneratedKeys)
执行给定的 SQL 语句,并用给定标志通知驱动程序由此 Statement 生成的自动生成键是否可用于获取
int executeUpdate(String sql, int[] columnIndexes)
执行给定的 SQL 语句,并通知驱动程序在给定数组中指示的自动生成的键应该可用于获取
int executeUpdate(String sql, String[] columnNames)
执行给定的 SQL 语句,并通知驱动程序在给定数组中指示的自动生成的键应该可用于获取
executeUpdate能够执行的SQL类型比较多,可以执行INSERT、UPDATE 或 DELETE 语句,或者不返回任何内容的 SQL 语句(如 SQL DDL 语句)。
对于 SQL 数据操作语言 (DML) 语句,返回行计数, 对于那些什么都不返回的 SQL 语句,返回 0
对于寻常的应用程序执行SQL来说就是返回受影响的行
在Connection的prepareStatement方法中,有提到过自动创建键值的返回
对于PrepareStatement在构造执行对象PrepareStatement时进行设置,而对于Statement的executeUpdate方法,则是在执行executeUpdate方法时进行设置
参数的语意是相同的
=================================================================================
execute
boolean execute(String sql)
执行给定的 SQL 语句,该语句可能返回多个结果
boolean execute(String sql, int autoGeneratedKeys)
执行给定的 SQL 语句(该语句可能返回多个结果),并通知驱动程序所有自动生成的键都应该可用于获取
boolean execute(String sql, int[] columnIndexes)
执行给定的 SQL 语句(该语句可能返回多个结果),并通知驱动程序在给定数组中指示的自动生成的键应该可用于获取
boolean execute(String sql, String[] columnNames)
执行给定的 SQL 语句(该语句可能返回多个结果),并通知驱动程序在给定数组中指示的自动生成的键应该可用于获取
execute可以执行所有形式的语句,既然也可以执行INSERT,自然也有返回键值的需求,所以类似executeUpdate,也提供了相关的支持用于返回键值
对于execute一定要注意返回值:如果第一个结果为 ResultSet 对象,则返回 true;如果其为更新计数或者不存在任何结果,则返回 false
通过返回值指示第一个结果的形式。然后,必须使用方法 getResultSet 或 getUpdateCount 来获取结果,使用 getMoreResults 来移动后续结果。
看得出来execute对于结果的处理是比较麻烦的
你要分情况判断,然后才能获取解析结果
=================================================================================
Batch
void addBatch(String sql)
将给定的 SQL 命令添加到此 Statement 对象的当前命令列表中
void clearBatch()
清空此 Statement 对象的当前 SQL 命令列表
int[] executeBatch()
将一批命令提交给数据库来执行,如果全部命令执行成功,则返回更新计数组成的数组
对于batch操作,简单说就是有一个列表,保存了执行命令。
add是添加方法,clear就是清空方法,execute就是执行列表内命令。
如下面示例,将李丽丽1 ~ 李丽丽100 分10次批量插入到数据库中
如果不分批次,只需要addBatch和executeBatch即可。
=================================================================================
JDK8 新增了对于大数据的处理,对于行数超过Integer.MAX_VALUE(2的31次方减一)时才应该被使用。
一般情况下用不到。
default long[] executeLargeBatch()
default long executeLargeUpdate(String sql)
default long executeLargeUpdate(String sql, int autoGeneratedKeys)
default long executeLargeUpdate(String sql, int[] columnIndexes)
default long executeLargeUpdate(String sql, String[] columnNames)
=================================================================================
以上就是Statement提供的SQL执行相关的方法
execute结果处理
因为execute可以CRUD,所以可能是ResultSet也可能是UpdateCount,根据返回值进行判断
如果true 可以使用getResultSet进行获取结果,并且借助于getMoreResults获取接下来的结果
如果是false可以通过getUpdateCount获取受影响的行。
ResultSet getResultSet()
以 ResultSet 对象的形式获取当前结果
int getUpdateCount()
以更新计数的形式获取当前结果;如果结果为 ResultSet 对象或没有更多结果,则返回 -1
boolean getMoreResults()
移动到此 Statement 对象的下一个结果,如果其为 ResultSet 对象,则返回 true,并隐式关闭利用方法 getResultSet 获取的所有当前 ResultSet 对象
boolean getMoreResults(int current)
将此 Statement 对象移动到下一个结果,根据给定标志指定的指令处理所有当前 ResultSet 对象;如果下一个结果为 ResultSet 对象,则返回 true
还有新增的default long getLargeUpdateCount()
连接信息与对象关闭
Statement由Connection创建,所以自然知道创建他的Connection信息,所以有获取方法
执行对象Statement如同连接Connection,使用后需要关闭,所以也提供了关闭方法
既然可以关闭,那么有是否关闭状态一说,所以也提供了状态检验方法
另外还可以终止执行SQL(如果支持的话)
相关方法如下:
Connection getConnection()
获取生成此 Statement 对象的 Connection 对象
void close()
立即释放此 Statement 对象的数据库和 JDBC 资源,而不是等待该对象自动关闭时发生此操作
boolean isClosed()
获取是否已关闭了此 Statement 对象
void cancel()
如果 DBMS 和驱动程序都支持中止 SQL 语句,则取消此 Statement 对象
键值返回
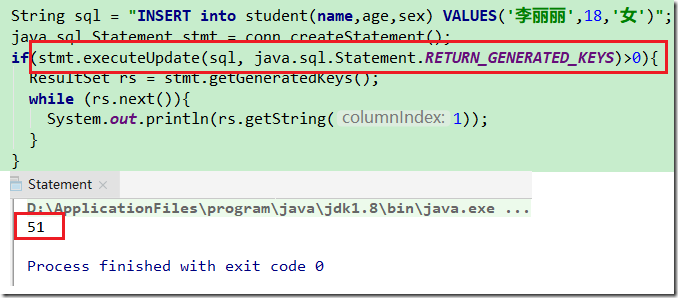
数据库可以自动生成键,对于这个键值,提供了相关的获取方法getGeneratedKeys
ResultSet getGeneratedKeys()
获取由于执行此 Statement 对象而创建的所有自动生成的键
在创建PrepareStatement以及executeUpdate方法以及execute方法中,都可以对键值返回进行设置
如果此 Statement 对象没有生成任何键,则返回空的 ResultSet 对象。
结果集类型、并发性、可保存性
Connection中的createStatement方法,创建Statement对象时,有关于结果集类型、并发性、可保存性的设置
可以在Statement中进行获取
int getResultSetType()
获取此 Statement 对象生成的 ResultSet 对象的结果集合类型
int getResultSetConcurrency()
获取此 Statement 对象生成的 ResultSet 对象的结果集合并发性
int getResultSetHoldability()
获取此 Statement 对象生成的 ResultSet 对象的结果集合可保存性
超时设置
语句执行需要时间,一个执行对象的执行,不可能是无限时的,那么驱动程序到底要等待多久呢?
这个时长,是可以设置和获取的
void setQueryTimeout(int seconds)
将驱动程序等待 Statement 对象执行的秒数设置为给定秒数
int getQueryTimeout()
获取驱动程序等待 Statement 对象执行的秒数
长度限制
执行对象执行SQL,不可避免的需要返回结果,这也是我们需要的
但是一个字段长度最长是多少? 最多可以返回多少行的数据呢?这些都是可以设置的
void setMaxFieldSize(int max)
设置此 Statement 对象生成的 ResultSet 对象中字符和二进制列值可以返回的最大字节数限制
int getMaxFieldSize()
获取可以为此 Statement 对象所生成 ResultSet 对象中的字符和二进制列值返回的最大字节数
void setMaxRows(int max)
将此 Statement 对象生成的所有 ResultSet 对象可以包含的最大行数限制设置为给定数
int getMaxRows()
获取由此 Statement 对象生成的 ResultSet 对象可以包含的最大行数
还有新增的
default void setLargeMaxRows(long max)
default long getLargeMaxRows()
default方法,你懂得,对于这种新增加的方法,无权要求别人一定立即实现,所以到底有没有实现,你还需要查看数据库驱动的版本情况。
默认是不可用的,比如下面这个,如果你没实现,是不能用的,直接抛出异常
告警信息
SQLWarning getWarnings()
获取此 Statement 对象上的调用报告的第一个警告
void clearWarnings()
清除在此 Statement 对象上报告的所有警告
池化(连接池)
语句的可池化的值对驱动程序实现的内部语句缓存以及应用程序服务器和其他应用程序实现的外部语句缓存都适用。
默认情况下,Statement 在创建时不是可池化的,而 PreparedStatement 和 CallableStatement 在创建时是可池化的。
void setPoolable(boolean poolable)
请求将 Statement 池化或非池化
boolean isPoolable()
返回指示 Statement 是否是可池化的值
数据返回检索
默认情况下,数据库会将查询结果一次性返回给应用程序,这些数据会保存在内存中。
平常情况下不会有什么问题,但是,如果一旦返回结果巨大,很可能造成内存不足,发生OOM
为此,设置了这么一个类似MYSQL 分页LIMIT的东西,LIMIT分页从数据库检索数据,而FetchSize 控制的是从数据库向应用程序客户端发送数据的页面大小
不再是一口气发送了,通过setFetchSize设置,getFetchSize获取,这个方法跟具体的驱动程序以及结果集类型都有关系,使用时要留心注意
void setFetchSize(int rows)
为 JDBC 驱动程序提供一个提示,它提示此 Statement 生成的 ResultSet 对象需要更多行时应该从数据库获取的行数
int getFetchSize()
获取结果集合的行数,该数是根据此 Statement 对象生成的 ResultSet 对象的默认获取大小
void setFetchDirection(int direction)
向驱动程序提供关于方向的提示,在使用此 Statement 对象创建的 ResultSet 对象中将按该方向处理行,默认值是 ResultSet.FETCH_FORWARD
int getFetchDirection()
获取从数据库表获取行的方向,该方向是根据此 Statement 对象生成的结果集合的默认值
其他
void setCursorName(String name)
将 SQL 光标名称设置为给定的 String,后续 Statement 对象的 execute 方法将使用此字符串
void setEscapeProcessing(boolean enable)
将转义处理设置为开或关
如果转义扫描为开启(默认值),则驱动程序在将 SQL 语句发送到数据库之前执行转义替换。
因为预编译语句通常在进行此调用之前解析,所以对 PreparedStatements 对象禁用转义处理无效。
自动关闭
可以指定语句所有依赖的结果集都被关闭时,关闭这个Statement,1.7新增
如果语句的执行不产生任何结果集,则此方法无效。
void closeOnCompletion()
throws SQLException
还有检测方法
boolean isCloseOnCompletion()
throws SQLException
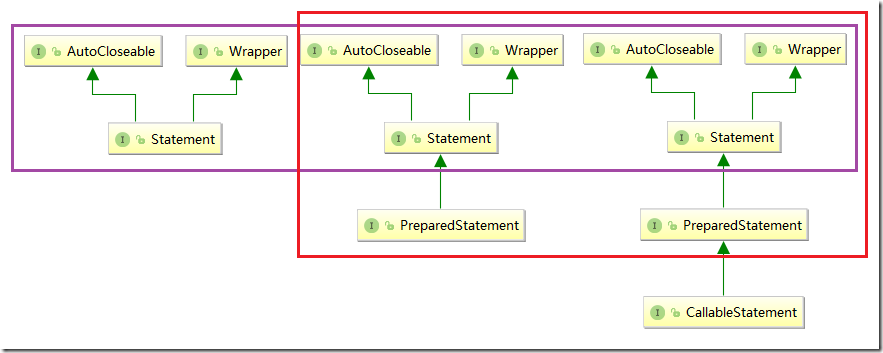
PreparedStatement详解
PreparedStatement表示预编译的 SQL 语句的对象
SQL 语句被预编译并存储在 PreparedStatement 对象中。然后可以使用此对象多次高效地执行该语句。
如前面所述,PreparedStatement继承了Statement,PreparedStatement接口添加了处理输入参数的方法;
PreparedStatement定义了execute、executeQuery、addBatch
既然添加了处理输入参数的方法,所以也附带给了一个清除参数的方法
还有两个元数据相关的方法
boolean execute()
在此 PreparedStatement 对象中执行 SQL 语句,该语句可以是任何种类的 SQL 语句
ResultSet executeQuery()
在此 PreparedStatement 对象中执行 SQL 查询,并返回该查询生成的 ResultSet 对象
int executeUpdate()
在此 PreparedStatement 对象中执行 SQL 语句,该语句必须是一个 SQL 数据操作语言(Data Manipulation Language,DML)语句,比如 INSERT、UPDATE 或 DELETE 语句;或者是无返回内容的 SQL 语句,比如 DDL 语句
void addBatch()
将一组参数添加到此 PreparedStatement 对象的批处理命令中
void clearParameters()
立即清除当前参数值
ResultSetMetaData getMetaData()
获取包含有关 ResultSet 对象列信息的 ResultSetMetaData 对象,ResultSet 对象将在执行此 PreparedStatement 对象时返回
ParameterMetaData getParameterMetaData()
获取此 PreparedStatement 对象的参数的编号、类型和属性
=================================================================================
其余所有的方法,全部都是“处理输入参数”相关的
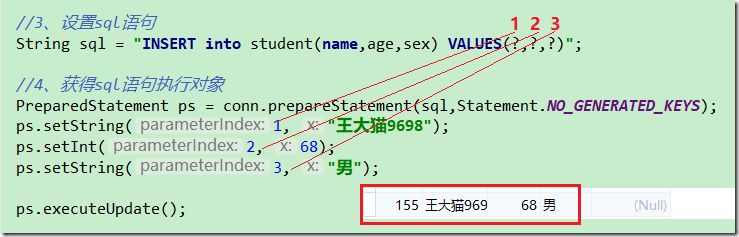
setXXX方法,第一个参数是int parameterIndex
表示的是参数的索引位置,第一个为1,第二个为2
setXXX,XXX大多数都是类型,但是也有一些特殊的,可以设置流
比如:
setAsciiStream(int parameterIndex, InputStream x)
将指定参数设置为给定输入流。
setBinaryStream(int parameterIndex, InputStream x)
将指定参数设置为给定输入流。
流是来做什么的呢?
这是因为个别时候,可能字段值很大,当你需要将一个很大的 ASCII 值输入到 LONGVARCHAR 参数时或者二进制值输入到 LONGVARBINARY 参数时,使用InputStream发送可能更好。
CallableStatement详解
CallableStatement继承自prepareStatement,实现了存储过程函数调用的方法以及对于输出的处理。
以一个简单的示例简单了解一下存储过程的调用,以及存储过程中输入输出参数的处理。
有这么一个表
CREATE TABLE `student` (
`id` int() NOT NULL AUTO_INCREMENT,
`name` varchar() NOT NULL DEFAULT '默认姓名' COMMENT '姓名',
`age` int() DEFAULT '1',
`sex` varchar() DEFAULT NULL,
`random` int() DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
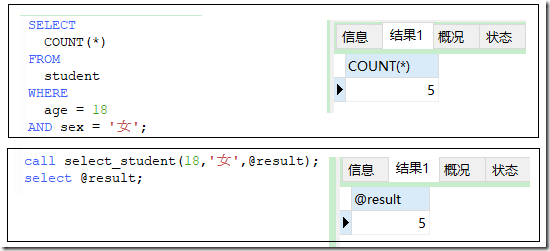
一个最简单的存储过程,输入年龄,性别,统计个数
DROP PROCEDURE
IF EXISTS
select_student;
CREATE PROCEDURE select_student(
IN age_param INT,
),
OUT result INT
)
BEGIN
SELECT COUNT(*) FROM student WHERE age=age_param and sex=sex_param INTO result;
END;
现在我的数据的查询结果是这样子的:
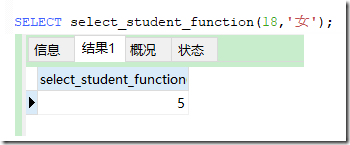
一个简单的函数
DROP FUNCTION IF EXISTS select_student_function;
))
RETURNS INT
BEGIN
DECLARE count INT;
SELECT COUNT(*) FROM student WHERE age=age_param and sex=sex_param INTO count;
return count;
END;
Navicat测试
通过调用执行,可以看到,与数据库直接查询结果一致
上面给出了在MYSQL中,对于存储过程和函数的调用
再回过头来看CallableStatement的API解释就很容易理解了
CallableStatement是用于执行 SQL 存储过程的接口
JDBC API 提供了一个存储过程 SQL 转义语法,该语法允许对所有 RDBMS 使用标准方式调用存储过程
此转义语法有一个包含结果参数的形式和一个不包含结果参数的形式
如果使用结果参数,则必须将其注册为 OUT 参数。其他参数可用于输入、输出或同时用于二者。
参数是根据编号按顺序引用的,第一个参数的编号是 1。
{?= call <procedure-name>[(<arg1>,<arg2>, ...)]}
{call <procedure-name>[(<arg1>,<arg2>, ...)]}
IN 参数值是使用继承自 PreparedStatement 的 set 方法设置的。
在执行存储过程之前,必须注册所有 OUT 参数的类型;它们的值是在执行后通过此类提供的 get 方法获取的。
CallableStatement 可以返回一个 ResultSet 对象或多个 ResultSet 对象。多个 ResultSet 对象是使用继承自 Statement 的操作处理的。
两种形式
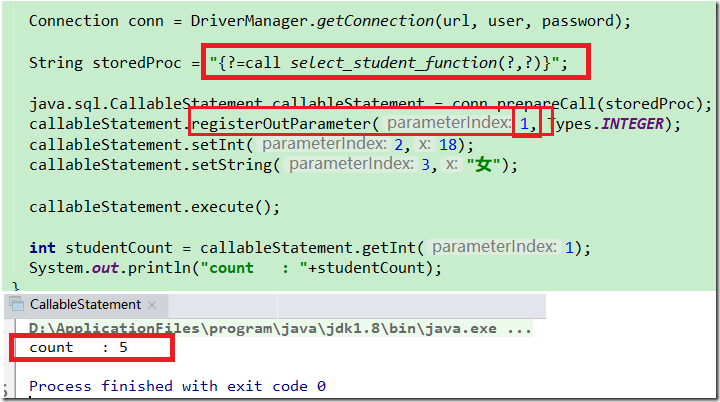
{?= call <procedure-name>[(<arg1>,<arg2>, ...)]} 返回结果
{call <procedure-name>[(<arg1>,<arg2>, ...)]} 不返回结果
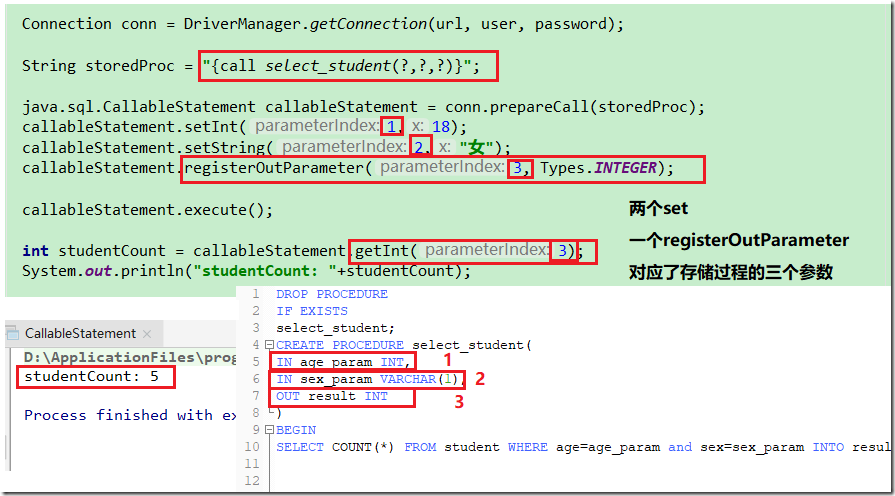
他们的使用是一致的,比如setXXX设置输入参数或者registerOutParameter 注册OUT参数,然后使用getXXX读取输出参数
对于有返回结果的形式(上面第一种),那么必然第一个? 占位符是输出,所以必然有registerOutParameter
但是其他的arg1,arg2.....可能是输出,也可能是输入,比如我们上面存储过程的例子,前两个参数是输入,第三个参数是输出
对于不返回结果的形式(第二种),arg1,arg2.....的含义也是如此,可能是输入,也可能是输出。
简言之,两种形式的arg1,arg2.....可能是输入也可能是输出,如果是输出那么需要使用registerOutParameter注册
但是有返回结果的形式,第一个占位符? 必然是输出,必须要使用registerOutParameter注册
CallableStatement继承自prepareStatement,实现了对输入和输出的支持,在prepareStatement大量setXXX方法基础上扩展了getXXX
所以API中绝大多数是setXXX和getXXX
在PrepareStatement中,setXXX中第一个参数为parameterIndex,表示参数索引顺序
在CallableStatement中,不仅仅支持参数索引顺序,还有一些是支持参数名称的,比如
getDouble(String parameterName)
setString(String parameterName, String x)
CallableStatement调用存储过程和函数,一个很重要的部分就是输出的处理
在JDBC中需要使用registerOutParameter将参数注册为输出
registerOutParameter的责任就是申明XXX参数是一个输出
对于这个参数可以使用int parameterIndex 下标索引(1开始)也可以使用String parameterName来指明
对于参数对应的类型也需要指明
java.sql.Types ,这个类定义了用于标识一般 SQL 类型(称为 JDBC 类型)的常量的类。比如static int VARCHAR
所有常量均为static int
对于类型的描述使用java.sql.Types类中定义的常量相对于枚举使用起来自然是没有那么顺手,枚举可读性更好,健壮性更强
所以还有类型的枚举版本JDBCType,定义用于标识通用SQL类型(称为JDBC类型)的常量。始于1.8
public enum JDBCType implements SQLType
以下截取部分对比(左Types 右JDBCType),可以看得出来,逻辑含义如出一辙。
既然是数据类型,那么某些数据类型就会涉及到精度的问题,就如同Java里面的double,小数部分终归要有一个精度约束
所以有一个参数int scale用于定义小数点右边所需的位数。该参数必须大于等于 0。
JDBC 类型 NUMERIC 或 DECIMAL 时,应该使用带scale参数的方法
另外还有用户命名的输出参数或 REF(引用)输出参数,用户命名类型的示例有:STRUCT、DISTINCT、JAVA_OBJECT 和指定的数组类型。
对于用户命名的参数,还应该提供参数的完全限定 SQL 类型名称,而 REF 参数则要求提供所引用类型的完全限定类型名称。
不需要类型代码和类型名称信息的 JDBC 驱动程序可以忽略它。
为了便于移植,应用程序应该为用户命名的参数和 REF 参数提供这些值。尽管此方法是供用户命名的参数和 REF 参数使用的,但也可以将其用于注册任何 JDBC 类型的参数。
如果参数没有用户命名的类型或 REF 类型,则忽略 typeName 参数。
对于这种情况,还提供了参数 String typeName 用于描述,表示SQL 结构类型的完全限定名称。
概括的说,registerOutParameter的主要参数为:
- 用于指明列的int parameterIndex或者String parameterName
- 用于指明类型的int sqlType或者SQLType sqlType(应该使用新的枚举方式)
- 用于指明精度的int sqlType(部分类型的字段才需要)
- 用于指明SQL 结构类型的完全限定名称的String typeName
所有的方法都是这几种信息的组合
default为1.8新增
----------------------------------------------------------------------------------------------------
void registerOutParameter(int parameterIndex, int sqlType)
void registerOutParameter(int parameterIndex, int sqlType, int scale)
void registerOutParameter(int parameterIndex, int sqlType, String typeName)
default void registerOutParameter(int parameterIndex, SQLType sqlType)
default void registerOutParameter(int parameterIndex, SQLType sqlType, int scale)
default void registerOutParameter(int parameterIndex, SQLType sqlType, String typeName)
void registerOutParameter(String parameterName, int sqlType)
void registerOutParameter(String parameterName, int sqlType, int scale)
void registerOutParameter(String parameterName, int sqlType, String typeName)
default void registerOutParameter(String parameterName, SQLType sqlType)
default void registerOutParameter(String parameterName, SQLType sqlType, int scale)
default void registerOutParameter(String parameterName, SQLType sqlType, String typeName)
----------------------------------------------------------------------------------------------------
总结
以上为三种执行对象的API了解部分,尽管方法繁多,但是核心根本却并不复杂
CallableStatement 扩展自PrepareStatement,PrepareStatement又扩展自Statement
Statement定义了基本的SQL的执行,PrepareStatement扩展了对于参数的处理部分,也就是拥有了IN的能力,并且提供了一系列的setXXX
CallableStatement在PrepareStatement的基础上扩展了OUT的能力,并且提供了存储过程以及函数的执行处理。
这就是三大执行对象内在血统的联系。
Statement是始祖,所有的方法逻辑根本来自于他,所以要理解记忆Statement的各类方法以及形式