C# - LINQ 语言集成查询
LINQ(Language Integrated Query)

Lambda表达式
格式
Lambda表达式比函数有着更为简洁的语法格式。在某些情况下使用Lamnbda就可以替代函数,让代码变得更简洁易读。而定义Lambda表达式与定义函数其实差别不大,而且还做到了简化。
e => e.Name == "sam"
定义函数你得声明函数的权限修饰符、形态修饰符和参数列表、返回类型等,而Lambda就这么一段代码就做完了函数的工作
e:参数
=>:操作符,可描述执行后面的逻辑……操作符后面的则是单个表达式,也可以是语句块。即函数的方法体。
示例
//有{}代码块的称为语句Lambda,无{}代码块的称为Lambda表达式
(string e) => e.Name == "sam"; // 显示声明了参数 操作符后面是求值表达式 也即返回一个求值的结果
e => e.Name == "sam"; // 隐式声明了参数 操作符后面是求值表达式
e => { return e.Name == "sam"; } // 隐式声明了参数 操作符后面是求值语句块
(string e, string x)=>{ return e.Name == "sam" && e.Age = 32; } //显示声明了多参数 操作符后面是求值语句块
(e, x) => { return e.Name == "sam" && e.Age = 32; } //隐式声明了多参数 操作符后面是求值语句块
()=>Console.WriteLine(); //无参数 操作符后面是执行语句 返回void
Lambda与委托
Lambda就是一个匿名的函数,所以你可以将Lambda当成委托实例作为参数进行传递,如果要这样做,则你定义的Lambda表达式的签名和返回类型必须符合委托的签名和返回类型
{
Console.WriteLine(d().ToString());
}
static void Main(string[] args)
{
Func<DateTime> getDateTime = () => DateTime.Now; //将匹配Func<T>委托签名和返回类型的lambda表达式当做委托使用
ShowTime(getDateTime);
}
LINQ延迟查询机制
LINQ查询操作符并不会立即执行,它总是在查询结果集真正被使用的时候才会开启查询。 而且每次只将迭代的当前项存入内存中处理,这就降低了内存占用率。那些需要一次性统计所有集合的操作符如:OrderBy、Reverse、ToList、ToArray、ToDictionary,它们都会破坏延迟查询,也即调用这些操作符则会立即开启查询。
var result = numbers.Where(n => n <= 2); //不做任何操作,等待后续调用时才开始执行查询
foreach (var item in result) //开始linq查询
Console.WriteLine(item); // print 0,1,2
for (int i = 0; i < 10; ++i) //更改numbers的每个元素,取相反数
numbers[i] = -numbers[i];
foreach (var item in result) //开始linq查询
Console.WriteLine(item); // print 0,-1,-2,-100
//在这个例子中,如果Where查询是立即执行的,那么result只会存储0,1,2,第二次foreach时,也应该输出0,1,2,但实际情况却不是这样
//为什么为linq使用延迟查询?
//因为上面例子中的numbers只调用了Where方法,如果它不立即开启查询,直到你要用到查询结果的时候才去执行查询
//那么这样做的好处是显而易见,因为在你还未使用查询结果之前,你可能还会继续在numbers上调用其它的linq扩展方法
//那么这些扩展方法就形成了一个链式的操作
//而这个链式操作只返回最终一个结果,省去了每调用一次扩展方法就开启查询,无形中就增加了内存或数据库的查询压力
LINQ查询表达式
LINQ查询表达式类似于SQL查询语句,但个人不喜欢它的书写格式。它是由from、join group by等句子组成的LINQ查询表达式,而LINQ查询表达式与直接使用LINQ扩展方法执行查询在语法结构上是不一样的,我认为后者更易于阅读,所以此处略过。
LINQ操作符
几乎每个Linq操作符都接收一个委托实例(Lambda),操作符对集合进行迭代,每迭代一次会自动调用Lambda,根据lambda来返回结果集。
1.过滤
根据参数提供的lambda表达式指定的逻辑过滤集合中的元素,将计算的结果存入结果集返回。可以按条件、按索引、按开头或结尾、按唯一的单个项进行筛选。
//根据lambda的逻辑筛选符合条件的元素
//此方法所要求的委托还可以有第三个参数:Index,表示当前对象在集合中的索引号
ElementAt( int index )
//根据参数索引查找处于该索引处的项
Single( [ lambda ] )
//lambda:可选的lambda表达式,用于提供过滤的条件
//返回集合中的唯一的项
//类似的有FirstOrDefault方法,该方法保证无唯一的项时安全返回一个default<T>
//如果集合存在多个项则会引发异常
First( [ lambda ] )
//lambda:可选的lambda表达式,用于提供过滤的条件
//类似的有FirstOrDefault,该方法保证无项时安全返回一个default<T>
//返回集合中的第一个项,或根据过滤获取指定的项
Last( [ lambda ] )
//lambda:可选的lambda表达式,用于提供过滤的条件
//类似的有LastOrDefault,该方法保证无项时安全返回一个default<T>
//返回集合中的最后一个项,或根据过滤获取指定的项
2.投影
根据参数提供的lambda表达式返回的项,将项存入结果集返回
//根据lambda表达式的计算逻辑,将计算的结果存入结果集返回
//示例1:
int[] a = { 1, 2, 3 };
var s = a.Select(i => i > 2); //计算i>2的结果,将结果存入结果集返回
foreach (var item in s)
{
Console.WriteLine(item); //print flse,false,true
}
//示例2:
public class Book
{
public string Title { get; set; }
public double Price { get; set; }
public List<Author> Authors { get; set; }
}
public class Author
{
public string Name { get; set; }
}
public class Programe
{
static void Main(string[] args)
{
List<Book> books = new List<Book>
{
new Book
{
Title="寂静的春天",
Price=19.8,
Authors = new List<Author>
{
new Author{ Name="sam" },
new Author{ Name="leo" }
}
},
new Book
{
Title="万有引力之虹",
Price=20.7,
Authors=new List<Author>
{
new Author{ Name="korn" },
new Author{ Name="Tim" }
}
},
new Book
{
Title="卡拉马佐夫兄弟",
Price=30.5,
Authors=new List<Author>
{
new Author{ Name="lily" },
new Author{ Name="lvis" }
}
}
};
IEnumerable<string> titleList = books.Select(book => book.Title); //将lambda表达式的计算结果Book的Title存储到结果集IEnumerable中,将IEnumerable<string>作为结果集返回
foreach (var title in titleList)
{
Console.WriteLine(title);//print 寂静的春天,万有引力之虹,卡拉马佐夫兄弟
}
IEnumerable<double> priceList = books.Select(book => book.Price); //将lambda表达式的计算结果Book的Price存储到结果集IEnumerable中,将IEnumerable<double>作为结果集返回
foreach (var price in priceList)
{
Console.WriteLine(price);//print 19.8,20.7,30.5
}
IEnumerable<Book> bookList = books.Select(book => book); //将lambda表达式的计算结果Book存储到结果集IEnumerable中,将IEnumerable<Book>作为结果集返回
foreach (var book in bookList)
{
Console.WriteLine($"{book.Title}{book.Price}");//print ……
}
IEnumerable<List<Author>> authorListList = books.Select(book => book.Authors); //将lambda表达式的计算结果Book的Authors存储到IEnumerable中,将 IEnumerable<List<Author>>作为结果集返回
foreach (var authorList in authorListList)
{
foreach (var author in authorList)
{
Console.WriteLine(author.Name); //print sam,leo,korn,Tim,lily,lvis
}
}
}
}
SelectMany ( lambda )
//根据lambda表达式指定的逻辑将计算的结果从集合中抽取出来存入结果集返回
//此方法所要求的委托还可以有第三个参数:Index,表示当前对象在集合中的索引号
//示例:
IEnumerable<Author> authorList = books.SelectMany(book => book.Authors); //将lambda表达式的计算逻辑的结果从集合中抽取出来存入结果集返回,因为Authors是一个List<Author>,抽取Author后存入结果集,所以结果集就是一个 IEnumerable<Author>
3.去重
根据参数提供的lambda表达式返回的项对集合进行去重,将去重后的结果存入结果集返回
//去除集合中的重复项
//comparer:引用类型的去重需要手动为类型实现 IEqualityComparer<T>
//此方法内部维护了一个测试相等性的比较器
//如果项是struct或string,则比较值的相等性
//如果项是class,则比较堆地址的相等性,可是多半在执行查询时查询的是class,class多半都是不相等的堆引用,所以此方法无参版只能用于struct或string的去重
Except( IEnumerable < T > second [ , IEqualityComparer < T > comparer ] )
//将参数1的集合与当前集合做比较,返回没有同时出现在两个集合中的项。也即求差集
//comparer:可选,引用类型的比较需要手动为类型实现 IEqualityComparer<T>
//此方法内部维护了一个测试相等性的比较器
//如果项是struct或string,则比较值的相等性
//如果项是class,则比较堆地址的相等性,可是多半在执行查询时查询的是class,class多半都是不相等的堆引用,所以此方法无参版只能用于struct或string的差集
Intersect( IEnumerable < T > second [ , IEqualityComparer < T > comparer ] )
//将参数1的集合与当前集合做比较,返回同时出现在两个集合中的项。也即求交集
//comparer:可选,引用类型的比较需要手动为类型实现 IEqualityComparer<T>
//此方法内部维护了一个测试相等性的比较器
//如果项是struct或string,则比较值的相等性
//如果项是class,则比较堆地址的相等性,可是多半在执行查询时查询的是class,class多半都是不相等的堆引用,所以此方法无参版只能用于struct或string的交集
Union( IEnumerable < T > second )
//将参数1的集合与当前集合进行合并,也即求并集
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Text;
using System.Web.UI;
using System.IO;
namespace Yin.General
{
public static class LinqHelper<T>
{
public static IEqualityComparer<T> CreateComparer<TV>(Func<T, TV> keySelector)
{
return new CommonEqualityComparer<TV>(keySelector);
}
public static IEqualityComparer<T> CreateComparer<TV>(Func<T, TV> keySelector, IEqualityComparer<TV> comparer)
{
return new CommonEqualityComparer<TV>(keySelector, comparer);
}
private class CommonEqualityComparer<TV> : IEqualityComparer<T>
{
private readonly IEqualityComparer<TV> _comparer;
private readonly Func<T, TV> _keySelector;
public CommonEqualityComparer(Func<T, TV> keySelector, IEqualityComparer<TV> comparer)
{
_keySelector = keySelector;
_comparer = comparer;
}
public CommonEqualityComparer(Func<T, TV> keySelector)
: this(keySelector, EqualityComparer<TV>.Default)
{ }
public bool Equals(T x, T y)
{
return _comparer.Equals(_keySelector(x), _keySelector(y));
}
public int GetHashCode(T obj)
{
return _comparer.GetHashCode(_keySelector(obj));
}
}
}
}
相等性比较器
var records = Authors.Distinct(LinqHelper<Author>.CreateComparer<string>(a => a.FirstName)); //根据引用类型Author的FirstName进行去重
4.转换
//将结果集转换为数组,不再具有延迟机制,查询将立即执行
ToList( )
//立即将结果集转换为列表集合,不再具有延迟机制,查询将立即执行
ToDictionary( )
//立即将结果集转换为哈希字典,主要用于将List<T>集合中的元素的某个成员作为哈希字典的key来存取元素,不再具有延迟机制,查询将立即执行
//示例
public class Animal
{
public int Id { get; set; }
public string Name { get; set; }
}
List<Animal> list = new List<Animal>
{
new Animal{ Id=1, Name="sam"},
new Animal{ Id=2, Name="leo"}
};
Dictionary<int, Animal> dictionary = list.ToDictionary( animal => animal.Id ); //用元素的id作为哈希字典的键
Console.WriteLine(dictionary[1].Name );
Cast<T>()
//将非泛型集合转换为泛型集合,非泛型集合没有Linq查询,因为存储的都是object,转换之后就可以执行linq查询
AsEnumerable( )
//将结果集转换为IEnumerable<T>类型,主要用于屏蔽集合的索引器,因为IEnumerable只有一个可迭代的方法,所以如果你只想将集合暴露给用户查看而不需要他们去设置集合的元素,就可以使用此方法
AsQueryable( )
//将结果集转换为IQueryable<T>类型
聚合
//所见即所得
Count()
//所见即所得
//ICollection接口有一个Count的属性
//而扩展方法为集合提供了Count()方法
//两者都会执行遍历计算总项数,如果只想测试是否有项,可使用效率更高的Any()
Min()
//所见即所得
Max()
//所见即所得
Average()
//所见即所得
Aggregate()
//所见即所得
6.排序
按lambda表达式返回的项进行排序
//按lambda表达式返回的项进行升序排序,返回一个 IOrderedEnumerable<TSource>
//只能使用一次,如果多次使用了OrderBy方法,那么只有最后一个会生效
//要在一个已经OrderBy的集合上执行再排序应使用ThenBy(),ThenBy()可出现N次
OrderByDescending( lambda [ , IComparer < T > comparer] )
//降序排序
ThenBy( lambda [ , IComparer < T > comparer] )
//在IOrderedEnumerable<TSource>集合上执行升序排序
ThenByDescending( lambda [ , IComparer < T > comparer] )
//在IOrderedEnumerable<TSource>集合上执行降序排序
Reverse( lambda [ , IComparer < T > comparer] )
//倒转序列
7.分组
按lambda表达式返回的项进行分组
//按lambda表达式指定的项进行分组,返回一个IEnumerable<IGrouping<TKey,T>>
{
new Book{ Title="寂静的春天", Price=19.8, Type="社科"},
new Book{ Title="单向度的人", Price=19.8, Type="社科"},
new Book{ Title="历史研究", Price=10.8,Type="历史"},
new Book{ Title="卡拉马佐夫兄弟", Price=10.8,Type="小说"},
};
//单条件分组
var query = list.GroupBy(book => book.Type);
StringBuilder bs = new StringBuilder();
foreach (var group in query)
{
bs.Append("-----" + group.Key + "-----\r\n"); //Key是组头,此处是book.Type
foreach (var book in group)
{
bs.Append(" " + book.Title + "\r\n");
}
Console.WriteLine(bs.ToString());
bs.Clear();
}
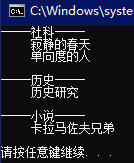
//多条件分组,同时满足指定的条件会被分为一组
var query = list.GroupBy(book =>new { book.Type, book.Price });
StringBuilder bs = new StringBuilder();
foreach (var group in query)
{
bs.Append("-----" + group.Key.Type + "-----\r\n"); //Key是匿名对象,此处是new { book.Type, book.Price }
foreach (var book in group)
{
bs.Append(" " + book.Title + "\r\n");
}
Console.WriteLine(bs.ToString());
bs.Clear();
}
ToLookup(lambda )
//与GroupBy是一样的,但不延迟查询,返回一个ILookup<TKey, T>,该类型是IEnumerable<IGrouping<TKey, T>> 的简化版
var grouping = list.ToLookup(book => book.Type); //立即分组
foreach (var group in grouping)
{
Console.WriteLine($"========{group.Key}========");
foreach(var item in group)
{
Console.WriteLine(item.Title);
}
}
8.联结
将N张表(集合)建立联结,每张表都有一个共同的键,键相同的行数据则被归纳到一行中, 下表中的出版社和图书以出版社ID为关联键位,使用联结查询后,相同关联键位的行数据会被整合到一行中
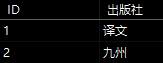
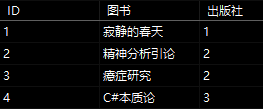

操作符:Join ( ) | GroupJoin ( )
9-1.内联结:查询关联的多张表,但不返回无关联的记录(inner join)
Join ( 联结的另一个集合,能返回被查询的左边集合的关联键位的函数,能返回被联结的右边集合的关联键位的函数,根据前两个函数的参数能创建新结果集的函数 )

//适用于1对1、1对多关系,类似于sql的inner join,无关联的记录不会返回
var query = publishers.Join(books, publish => publish.ID, book => book.PublisherID, (publish, book) => new
{
pubID = publish.ID,
pubName = publish.Name,
bookName = book.Name
});
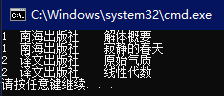
9-1.分组联结:将关联的多张表的记录进行分组
单表分组使用GroupBy,多表连接分组则使用GroupJoin
GroupJoin ( 联结的另一个集合,能返回被查询的左边集合的关联键位的函数,能返回被联结的右边集合的关联键位的函数,根据前两个函数的参数能创建新结果集的函数 )

{
pubID = publish.ID,
pubName = publish.Name,
bookAllName = !bookList.Any()==true?"无":string.Join(",",bookList.Select(b=>b.Name))
});
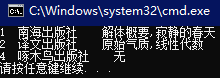
9-2.外连接:键位不相等时,保证左边可以返回,右边则以null填充(left join)
使用GroupJoin 方法,利用投影和DefaultIfEmpty方法可实现左外连接。

var query = publishers.GroupJoin(books, p => p.ID, b => b.PublisherID, (publish, bookList) => new { publish.ID, publish.Name, bookList }).
SelectMany(x => x.bookList.DefaultIfEmpty(), (publish, book) => new
{
pubID = publish.ID,
pubName = publish.Name,
bookName = book == null ? "无" : book.Name
});
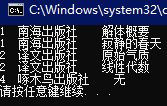
左联结的表达式版本
join p in publishers
on b.PublisherID equals p.ID
into newTable
from x in newTable.DefaultIfEmpty( )
select new
{
ID = b.ID,
Name = b.Name,
pubName = x==null? "null":x.Name
};
大部分情况下可能会使用GroupJoin方法,但是假如关键键位本身是必填的,那么使用Join方法就可以了,因为关联键位是必填,则不会存在关联到空数据的情况,也就没必要使用GroupJoin。
10.全连接
在sql中存在全连接的概念,它是指两张或N张表无论左或右出现了未匹配上的行时,都以null填充。在linq中并不支持全连接,如果有这种需求,可以考虑先得到两个结果集,最后再UNION即可。
11.交叉连接
也称笛卡尔积查询,可使用linq表达式写个简单的例子:
{
'A','B','C'
};
List<char> bList = new List<char>
{
'x','y'
};
var query =
from a in aList
from b in bList
select new { a, b };
foreach (var item in query)
{
Console.WriteLine($"{item.a}与上{item.b}");
}
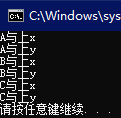
12.串联
操作符:Concat ( )
将5另一个序列与当前序列合并为一个序列
13.分区
操作符:Skip ( ) | SkipWhile ( ) | Take ( ) | TakeWhile ( )
Skip():跳过集合中指定个数的项,返回剩下的项。
SkipWhile():返回满足条件的项。
Take():从索引起始位置开始提取指定个数的项。
TakeWhile():提取满足条件的项
14.生成
操作符:DefaultIfEmpty ( )
DefaultIfEmpty() :用于当集合为空时为集合提供带有默认值的一个项
15.判断
操作符:All ( ) | Any ( ) | Contains ( )
All() :集合中所有项都满足条件吗?
Any():集合至少包含了一个项吗?
Contains():集合包含了参数指定的项吗?
16.比较
操作符:SequenceEqual ( )
LINQ To Object
查询泛型集合
所有的LINQ操作符(即扩展方法)均定义在System.Linq.Enumerable静态类中,为所有实现了IEnumerable<T>的强类型集合扩展出了LINQ查询方法。所以数组、泛型集合都可以使用LINQ查询。
var records = objArray.Select(m => m.GetType().FullName).OrderBy(t => t);
ObjectDumper.Write(records);
Book[] books =
{
new Book{ Title="万有引力之虹", Isbn="993748928", PageCount=300 },
new Book{ Title="解体概要", Isbn="325757665", PageCount=500 },
new Book{ Title="寂静的春天", Isbn="229911000", PageCount=200 }
};
var records = books.Where(b => b.Isbn.Contains("9")).Select(b => b.Title);
ObjectDumper.Write(records);
List<Book> bList = new List<Book>
{
new Book{ Title="万有引力之虹", Isbn="993748928", PageCount=300 },
new Book{ Title="解体概要", Isbn="325757665", PageCount=500 },
new Book{ Title="寂静的春天", Isbn="229911000", PageCount=200 }
};
var records = bList.Where(b => b.Isbn.Contains("9")).Select(b => b.Title);
ObjectDumper.Write(records);
Dictionary<string, int> bNary = new Dictionary<string, int>
{
{ "sam", 12 },
{ "corz", 22 },
{ "korn", 53 },
};
var records = bNary.Where(o => o.Value > 20);
ObjectDumper.Write(records);
查询非泛型集合
只需要使用Cast<T>将非泛型集合转换为泛型即可。
ArrayList list = new ArrayList()
{
new Book{ Title="寂静的春天"},
new Book{ Title="万有引力之虹"},
new Book{ Title="解体概要"}
};
var records = list.Cast<Book>().Select(b => new { bName= b.Title });
参数化查询
可在查询中使用变量,还可以动态构造查询,比如定义一个函数,函数以Func泛型委托做参数,通过条件测试传递不同的Lambda表达式。
<select name="combobox">
<option value="0">查询标题</option>
<option value="1">查询出版社</option>
</select>
<div>
@ViewData["show"]
</div>
</body>
public ActionResult Index(string combobox)
{
string recordsJson = string.Empty;
switch (combobox)
{
case "0":
recordsJson=ComboboxLambda(b => b.Title);
break;
case "1":
recordsJson=ComboboxLambda(b=>b.Publisher.Name);
break;
}
ViewData["show"] = recordsJson;
return View();
}
[NonAction]
public string ComboboxLambda<T>(Func<Book,T> selector)
{
var records = SampleData.books.Select(selector);
return JsonConvert.SerializeObject(records);
}
LINQ查询是一系列的链式操作,所以完全可以根据条件动态增加查询,所以以下代码并不会发生覆盖而是追加。
public ActionResult Index(int maxPage, string orderByTitle)
{
IEnumerable<Book> books = SampleData.books;
if (maxPage != )
{
books = books.Where(b => b.PageCount > maxPage);
}
if (!string.IsNullOrEmpty(orderByTitle))
{
books = books.OrderBy(b => b.Title);
}
books = books.Select(b => b); //查询会在符合条件的判断中形成链式操作
ViewData["show"] = JsonConvert.SerializeObject(books);
return View();
}
读取文件
一个txt文件存储了图书信息,为StreamReder添加一个扩展方法用于获取所有行,再通过LINQ查询将数据打包。

{
/// <summary>
/// 读取每一行
/// </summary>
/// <param name="source"></param>
/// <returns></returns>
public static IEnumerable<string> Lines(this StreamReader source)
{
string line;
while (!string.IsNullOrEmpty(line = source.ReadLine()))
{
yield return line;
}
}
}
{
string filePath = Server.MapPath("~/bookMessage.txt");
StreamReader reader = new StreamReader(filePath);
using (reader)
{
var bookMsg = reader.Lines()
.Where(line => !line.StartsWith("#")) //过滤掉首行
.Select(line => line.Split(','))
.Select(part => new
{
Isnb = part[],
title = part[],
publisher = part[],
author = part[].Split(';').Select(authorPerson => authorPerson)
});
ViewData["show"] = JsonConvert.SerializeObject(bookMsg);
}
return View();
}
LINQ To XML


XObject类
//添加注释节点。
Annotation(Type)
//获取第一个注释节点,类似行为的有Annotation<T>()、Annotations(Type)、Annotations<T>()。
方法
XNode类
表示项、注释、 文档类型、处理指令、文本节点。节点可以是项节点、属性节点、文本节点。
//紧跟在此节点之后添加指定的内容
AddBeforeSelf(object)
//紧跟在此节点之前添加指定的内容
Remove()
//从父节点总移除自身
Ancestors()
//获取当前节点的祖先元素节点集合
ElementsAfterSelf()
//获取当前节点后面的兄弟元素节点集合
ElementsBeforeSelf()
//获取当前节点的前面的兄弟元素节点集合
NodesAfterSelf()
//获取当前节点后面的兄弟元素节点集合
NodesBeforeSelf()
//获取当前节点前面的兄弟元素节点集合
方法
XContainer类
//获取当前节点包含的所有子节点集合
Elements()
//获取当前节点包含的所有子元素节点集合
Elements(XName)
//获取当前节点包含的所有能匹配参数指定的XName的子元素节点集合
Element(XName)
//获取当前节点包含的能匹配参数指定的XName的第一个子元素节点
Descendants()
//获取当前节点包含的所有子代元素节点集合,即后代元素节点集合
DescendantNodes()
//获取当前节点包含的所有子代节点集合,即后代节点集合
Descendants(XName)
//获取当前节点包含的所有能匹配参数指定的XName的子代元素节点集合,即后代元素节点集合
Add(object)
//添加子节
AddFirst(object)
//将参数指定的节点添加为作为自身包含的第一个子节
RemoveNodes()
//删除自身的所有子节
ReplaceNodes(object)
//将自身包含的所有子节替换为参数指定的节点
ReplaceWith(object)
//将自身替换为参数指定的节点
方法
XElement类
表示XML项节点。
//XElement的构造函数,用于创建XML元素节点,参数2如果是String则成为元素节点包含的文本节点,否则可同时创建出后代元素节点
XNameString:元素节点名称的字符表示或XName对象
//示例1:使用函数式链式操作创建XML元素节点
XElement books = new XElement("books",
new XElement("book",
new XElement("author", "寒食"),
new XElement("author", "寒食")
)
);
//示例2:调用函数创建XML元素节点
XElement book = new XElement("book");
book.Add(new XElement("author","寒食"));
book.Add(new XElement("author", "无垠"));
XElement books = new XElement("books");
books.Add(book);
//示例3:创建命名空间
XElement books = new XElement("{http://google.com/}books",
new XElement("book",
new XElement("author", "寒食"),
new XElement("author", "寒食")
)
);
//示例4:创建命名空间前缀
XElement books = new XElement("books",
new XElement("book",
new XAttribute(XNamespace.Xmlns + "1", ns),
new XElement("author", "寒食"),
new XElement("author", "寒食")
)
);
Add(XElement)
//添加子元素节点
Save()
//保存XML文档
WriteTo(XmlWriter)
//将元素节点写入XmlWriter中
Attribute(XName)
//获取属性节点集合
Attribute(XName)
//根据指定的属性节点名获取属性节点值
AncestorsAndSelf()
//获取自身并包括其祖先元素节点集合
DescendantsAndSelf()
//获取自身并包括其后代元素节点集合
RemoveAll()
//移除所有后代
RemoveAttributes()
//移除自身的所有属性节点
RemoveAnnotations(Type)
//移除自身的所有注释节点
SetAttributeValue(XName, Object)
//根据指定的属性节点名设置属性节点值
SetElementValue(XName, Object)
//根据指定的属性节点名设置子元素节点的属性节点值
//==========静态方法==========
load(Path, LoadOptions)
//加载XML文档
//LoadOptions:可选的枚举,可能的值有:
//None:不保留无意义的空白
//PreserveWhitespace:保留无意义的空白
//SetBaseUri:保留URI信息
//SetLineInfo:保留请求的行信息
//示例:
try
{
XElement x = XElement.Load(Server.MapPath("/books.xml"), LoadOptions.PreserveWhitespace); // 可从URL、磁盘路径加载
}
Parse()
//从XML字符串解析出XElement
//示例:
XElement x = XElement.Parse(@"
<book>
<title>LINQ in Action</title>
<author>Fabrice Marguerie</author>
<author>Steve Eichert</author>
<author>Jim Wooley</author>
<publisher>Manning</publisher>
<rating>4</rating>
</book>
");
方法
XDocument类
表示XML文档,与XElement一样,它们都提供Load()、Parse()、Save()和WriteTo()方法,但此类可以包含更多信息,如包含一个根项的XElement、XML声明、XML文档类型和XML处理指令。如果使用函数式链式操作创建XML项,则使用XDocument与使用XElement创建XML项的语法格式是完全一样的。
XDocument doc = new XDocument("books",
new XDeclaration("1.0", "utf-8", "yes"), // 表示XML文档版本、字符编码、是否是独立信息的节点
new XProcessingInstruction("XML-sylesheet", "friendly-rss.xsl"), // 表示XML文档处理指令的节点,此处为XML文档配置了一个样式表用以格式化XML文档以便在浏览器以友好的界面显示XML数据
new XDocumentType("HTML", "-//w3c//DTD HTML 4.01//EN", "http://www.w3.org/TR/html4/strict/dtd", null) // 表示XML文档类型声明的节点
)
);
XAttribute类
//从父元素节点中移除自身
//==========属性==========
Parent
//获取父元素节点
方法
XName
表示项的名字或项属性的名字
读取XML的简单示例
<category name="知识">
<childcategory name="自然">
<books>
<book>寂静的春天</book>
<book>自然之力</book>
</books>
</childcategory>
<childcategory name="宗教">
<books>
<book>佛陀的证悟</book>
</books>
</childcategory>
<childcategory name="社会">
<books>
<book>智利天下写春秋</book>
<book>文明的解析</book>
</books>
</childcategory>
</category>
XML
{
public ActionResult Index()
{
XElement root = XElement.Load(Server.MapPath("~/books.xml"), LoadOptions.PreserveWhitespace);
var childcategory = root.Element("childcategory"); // 获取第一个childcategory元素节点
var childcategoryAttri = childcategory.Attribute("name"); // 获取第一个childcategory的name属性节点
IEnumerable<XElement> books = childcategory.Element("books").Elements("book"); // 获取第一个childcategory所包含的第一个books元素节点包含的所有book元素节点
ViewData["childcategory"] = childcategory;
ViewData["childcategoryAttri"] = childcategoryAttri;
ViewData["childs"] = string.Join("", books.ToList());
// 输出XElement时会将它所包含的所有后代一并输出
// 输出 IEnumerable<XElement>元素节点集合时必须ToList后与字符相连
return View();
}
}
读取XML
// (string)XElement可将元素节点转为其包含的文本 这样就可以执行一次判断 前提是该元素节点和包含的文本是在一行显示的
ViewData["show"] =string.Join("",root.Descendants("book").Where(book => (string)book == "寂静的春天"));
获取包含指定文本的项节点
LINQ To Entity
MyEntity.DrugsErpEntities dbcontext = new MyEntity.DrugsErpEntities();
//如果Where后没有ToList,而是直接调用Select方法将会引发异常
var list = dbcontext.UserManagers.Where(user => user.LoginName == "a").ToList().Select((p, i) => new { u = p.LoginName, id = p.UserId, index = i }).ToList();
DbSet<TEntity> 类
Include()
//使用预加载策略建立左联结查询,模型必须具有导航属性,此方法根据导航属性来查询与主实体所关联的其它实体,此方法会立即开启查询
MusicStoreDB db = new MusicStoreDB();
var albums = db.Albums.Include(a => a.Artist).Include(a => a.Genre); //Artist和Genre都是Album的导航属性,不需要像Join方法那般指定主外键,只需要指定导航属性即可建立左联结查询 //批量删除记录
//示例:
public ContentResult DelBtch(string IDs) //IDs,需要被删除的记录的ID,如"1,15,32"
{
try
{
var records = DBContext.TbRights.RemoveRange(DBContext.TbRights.Where(t => IDs.Contains(t.TbRightId.ToString())));
DBContext.SaveChanges();
DBContext.Dispose();
return Content("{msg:'操作成功'}");
}
catch
{
return Content("{msg:'操作失败'}");
}
} AddRange()
//批量添加记录 AddOrUpdate(TEntity[] )
//System.Data.Entity.Migrations命名空间中为DbSet<TEntity>定义的扩展,自动识别插入或更新,当实体主键在数据库表中不存在时视为插入,当实体主键在数据库表中存在时视为更新。在参数数组包含的实体的主键在数据库表中既有存在的也有不存在的情况时,没关系,该更新该插入,此方法自动帮你完成。
//注意:如果某个字段为空,也将插入或更新到数据库,如果数据库设置了不允许空则引发异常
//示例:
var dirtyRecs = JsonConvert.DeserializeObject<List<TbRight>>(dirtyRecords); //包含了需要更新和需要插入的实体
DBContext.TbRights.AddOrUpdate(dirtyRecs.ToArray() ); //同时执行了插入和更新
插入数据前检测数据库是否已经具有一条完全相同的记录
/*
xTbUserRight:需要插入数据库的记录的Json表示
userIDs:以逗号分隔的员工ID的字符表示
checkValues:以逗号分隔的权限ID的字符表示
查询员工权限表时先对照userIDs和checkValues查出相同的记录,如果存在这样的记录则先删除它们
最后将xTbUserRight转化为的实体记录集合插入数据库
*/
public ContentResult AddTbUserRightBtch( string xTbUserRight , string xUserIDs , string xCheckValues )
{
int [ ] userIDs = Array.ConvertAll ( xUserIDs.Split ( ',' ) , o => int.Parse ( o ) );
int [ ] checkValues = Array.ConvertAll ( xCheckValues.Split ( ',' ) , o => int.Parse ( o ) );
var newRecords = JsonConvert.DeserializeObject<List<TbUserRight>> ( xTbUserRight );
var oldRecords = DBContext.TbUserRights.Where ( t => userIDs.Contains ( t.UserId ) && checkValues.Contains ( t.TbRightId ) );
if ( oldRecords.Count ( ) != )
{
DBContext.TbUserRights.RemoveRange ( oldRecords );
}
DBContext.TbUserRights.AddRange ( newRecords );
DBContext.SaveChanges ( );
return Content ( "{msg:'操作成功'}" );
}
#endregion
根据某个字段的数据集合查询出另一张表中对应的记录
//UserAuthority是用户权限表实体,它存储三个字段,主键、用户ID和用户权限ID,一个用户具有多个权限ID,结构如下:
//PrimaryID UserID AuthorityID
// 1 32 20
// 2 32 26
//Authority是权限表实体,它存储两个字段,主键和权限名称,结构如下:
//AuthorityID AuthorityName
// 32 ERP登录权限
//现在要查询出当前用户所具有的所有权限的记录
var userAuthorityID = DBContext.UserAuthority.Where ( t => t.UserID == UserId ).Select ( t => t.AuthorityID ).ToList ( ); //获取用户权限ID集合
var userInclud = DBContext.Authority.Where ( t => userAuthorityID.Contains ( t.AuthorityID ) ); //获取用户具有的权限记录
var userNotInclud = DBContext.Authority.Where ( t => !userAuthorityID.Contains ( t.AuthorityID ) ); //获取用户不具有的权限记录
C# - LINQ 语言集成查询的更多相关文章
- “标准查询运算符”是组成语言集成查询 (LINQ) 模式的方法
“标准查询运算符”是组成语言集成查询 (LINQ) 模式的方法.大多数这些方法都在序列上运行,其中的序列是一个对象,其类型实现了IEnumerable<T> 接口或 IQueryable& ...
- C#3.0新增功能09 LINQ 基础01 语言集成查询
连载目录 [已更新最新开发文章,点击查看详细] 语言集成查询 (LINQ) 是一系列直接将查询功能集成到 C# 语言的技术统称. 数据查询历来都表示为简单的字符串,没有编译时类型检查或 Inte ...
- LINQ(语言集成查询)
LINQ,语言集成查询(Language Integrated Query)是一组用于c#和Visual Basic语言的扩展.它允许编写C#或者Visual Basic代码以查询数据库相同的方式操作 ...
- C#-WebForm-LinQ(一)-LinQ:语言集成查询(Language Integrated Query)-增删改查、属性扩展
LinQ-语言集成查询(Language Integrated Query) 高集成化的数据库访问技术 LINQ 2 SQL 实际是将数据库的表映射成程序中的类 会把数据库的表名原封不动的变成类名 数 ...
- 27.7 并行语言集成查询(PLinq)
static void Main() { ObsoleteMethods(Assembly.Load("mscorlib.dll")); Console.ReadKey(); } ...
- LINQ to Entities 查询语法
转自: http://www.cnblogs.com/asingna/archive/2013/01/28/2879595.html 实体框架(Entity Framework )是 ADO.NET ...
- xBIM 使用Linq 来优化查询
目录 xBIM 应用与学习 (一) xBIM 应用与学习 (二) xBIM 基本的模型操作 xBIM 日志操作 XBIM 3D 墙壁案例 xBIM 格式之间转换 xBIM 使用Linq 来优化查询 x ...
- C#3.0新增功能09 LINQ 基础07 LINQ 中的查询语法和方法语法
连载目录 [已更新最新开发文章,点击查看详细] 介绍性的语言集成查询 (LINQ) 文档中的大多数查询是使用 LINQ 声明性查询语法编写的.但是在编译代码时,查询语法必须转换为针对 .NET ...
- LINQ——语言级集成查询入门指南(1)
本文主要是对语言级集成查询或简称为LINQ做一个介绍,包括LINQ是什么,不是什么,并对它在语言特性方面做一个简短的回顾,然后举一些使用LINQ的实际例子进行说明. 语言级集成查询是什么? 在我过去写 ...
随机推荐
- python3 pickle模块
import pickle '''将对象转化为硬盘能识别的bytes的过程被称为序列号将bytes转化为对象的过程被称为反序列化'''lst = ["苹果", "橘子&q ...
- MySQL数据库引擎类别和更换方式
MySQL数据库引擎类别 能用的数据库引擎取决于mysql在安装的时候是如何被编译的.要添加一个新的引擎,就必须重新编译MYSQL.在缺省情况下,MYSQL支持三个引擎:ISAM.MYISAM和HEA ...
- SoapUI 学习总结-02 断言
一 断言 测试指定的restful api是否正常,判断它的响应值是否符合预期标准,需要用到断言知识.在soapUI里断言使用的Groovy语言.在项目中测试起来非常简单,测试过程如下. 1,准备测试 ...
- Sqlserver查询死锁及杀死死锁的方法
-- 查询死锁 select request_session_id spid, OBJECT_NAME(resource_associated_entity_id) tableName from sy ...
- FineUIPro v5.1.0 发布了!
FineUIPro v5.1.0 已发布,这已经是自 2014 年以来的第 31 个版本,4 年来精雕细琢,只为你来! 上个大版本新增了响应式布局,而这个版本主要是BUG修正,此外还增加了树控件的级联 ...
- virtualbox 设置centos7 双网卡上网
上次用virtualbox安装centos6.6,这次装了一个centos7.0.用两个版本的配置还是大同小异的. 1.修改/etc/sysconfig/network-scripts/ifcfg-e ...
- 通过sort()方法实现升序和降序排列
数组 升序:Arrays.sort(arr); 降序: 方法一:Arrays.sort(arr,Collections.reverseOrder()); 方法二: package com.yh.sor ...
- 在pycharm中查看内建函数源码
鼠标放在内建函数上,Ctrl+B,看源码
- codeforces gym #102082C Emergency Evacuation(贪心Orz)
题目链接: https://codeforces.com/gym/102082 题意: 在一个客车里面有$r$排座位,每排座位有$2s$个座位,中间一条走廊 有$p$个人在车内,求出所有人走出客车的最 ...
- python的设计原则及设计模式
python的设计原则及设计模式 七大设计原则 单一职责原则 [SINGLE RESPONSIBILITY PRINCIPLE] 一个类负责一项职责. 里氏替换原则 [LISKOV SUBSTITUT ...