Hadoop集群管理
1.简介
Hadoop是大数据通用处理平台,提供了分布式文件存储以及分布式离线并行计算,由于Hadoop的高拓展性,在使用Hadoop时通常以集群的方式运行,集群中的节点可达上千个,能够处理PB级的数据。
Hadoop各个模块剖析:https://www.cnblogs.com/funyoung/p/9889719.html
2.Hadoop集群架构图
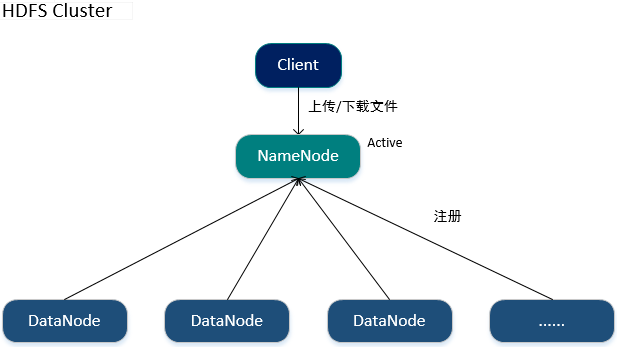
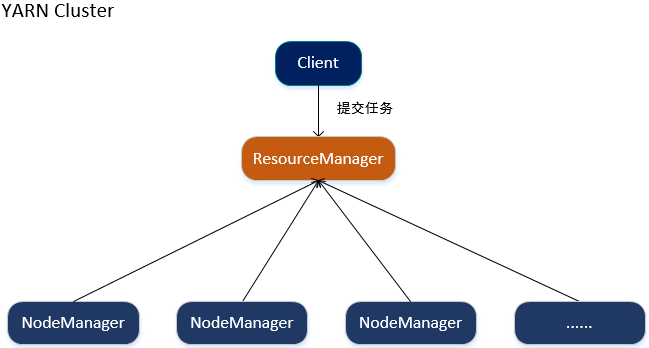
3.Hadoop集群搭建
3.1 修改配置
1.配置SSH以及hosts文件
由于在启动hdfs、yarn时都需要对用户的身份进行验证,且集群中NameNode、ResourceManager在启动时会通过SSH的形式通知其他节点,使其启动相应的进程,因此需要相互配置SSH设置免密码登录并且关闭防火墙或开启白名单。
//生成秘钥
ssh-keygen -t rsa //复制秘钥到本机和其他受信任的主机中,那么在本机可以直接通过SSH免密码登录到受信任的主机中.
ssh-copy-id 192.168.1.80 ssh-copy-id 192.168.1.81 ssh-copy-id 192.168.1.82
编辑/etc/hosts文件,添加集群中主机名与IP的映射关系。

2.配置Hadoop公共属性(core-site.xml)
<configuration>
<!-- Hadoop工作目录,用于存放Hadoop运行时NameNode、DataNode产生的数据 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-2.9.0/data</value>
</property>
<!-- 默认NameNode -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.1.80</value>
</property>
<!-- 开启Hadoop的回收站机制,当删除HDFS中的文件时,文件将会被移动到回收站(/usr/<username>/.Trash),在指定的时间过后再对其进行删除,此机制可以防止文件被误删除 -->
<property>
<name>fs.trash.interval</name>
<!-- 单位是分钟 -->
<value>1440</value>
</property>
</configuration>
*fs.defaultFS配置项用于指定HDFS集群中默认使用的NameNode。
3.配置HDFS(hdfs-site.xml)
<configuration>
<!-- 文件在HDFS中的备份数(小于等于NameNode) -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 关闭HDFS的访问权限 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 设置NameNode的Web监控页面地址(主机地址需要与core-site.xml中fs.defaultFS配置的一致) -->
<property>
<name>dfs.namenode.http-address</name>
<value>192.168.1.80:50070</value>
</property>
<!-- 设置SecondaryNameNode的HTTP访问地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.1.80:50090</value>
</property>
</configuration>
4.配置YARN(yarn-site.xml)
<configuration>
<!-- 配置Reduce取数据的方式是shuffle(随机) -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 设置ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.1.80</value>
</property>
<!-- Web Application Proxy安全任务 -->
<property>
<name>yarn.web-proxy.address</name>
<value>192.168.1.80:8089</value>
</property>
<!-- 开启日志 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志的删除时间 -1:禁用,单位为秒 -->
<property>
<name>yarn.log-aggregation。retain-seconds</name>
<value>864000</value>
</property>
<!-- 设置yarn的内存大小,单位是MB -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value>
</property>
<!-- 设置yarn的CPU核数 -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>8</value>
</property>
</configuration>
*yarn.resourcemanager.hostname配置项用于指定YARN集群中默认使用的ResourceManager。
5.配置MapReduce(mapred-site.xml)
<configuration>
<!-- 让MapReduce任务使用YARN进行调度 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 设置JobHistory的服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.1.80:10020</value>
</property>
<!-- 指定JobHistory的Web访问地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.1.80:19888</value>
</property>
<!-- 开启Uber运行模式 -->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
</configuration>
*Hadoop的JobHistory记录了已运行完的MapReduce任务信息并存放在指定的HDFS目录下,默认未开启。
*Uber运行模式对小作业进行优化,不会给每个任务分别申请分配Container资源,这些小任务将统一在一个Container中按照先执行map任务后执行reduce任务的顺序串行执行。
6.配置Slave文件
#配置要运行DataNode、NodeManager的节点,值可以是主机名或IP地址。
192.168.1.80
192.168.1.81
192.168.1.82
*slave文件可以只在NameNode以及ResourceManager所在的节点中配置。
*在服务器中各种配置尽量使用主机名来代替IP。
3.2 启动集群
启动HDFS集群
1.分别格式化NameNode



2.在任意一台Hadoop节点中启动HDFS,那么整个HDFS集群将会一起启动。

分别通过jps命令查看当前启动的进程



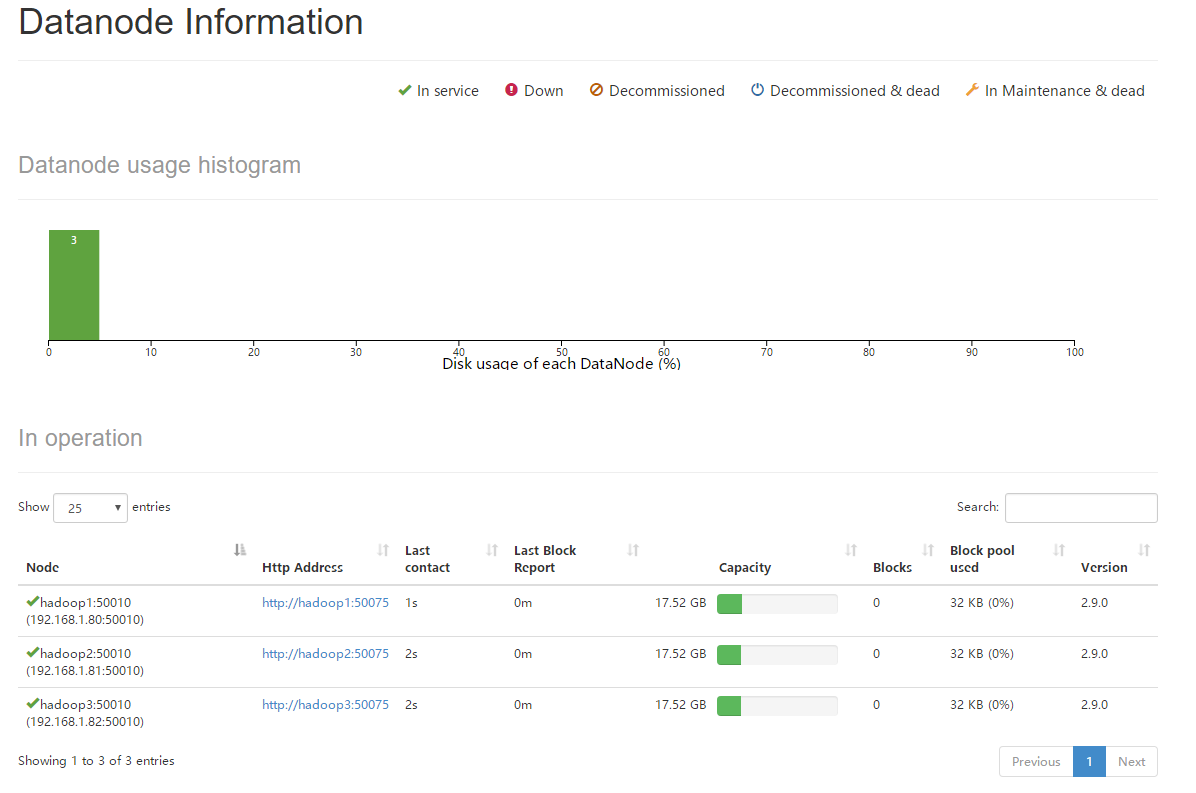
*当HDFS集群启动完毕后,由于NameNode部署在hadoop1机器上,因此可以访问http://192.168.1.80:50070进入HDFS的可视化管理界面,可以查看到当前HDFS集群中有3个存活的DataNode节点。
启动YARN集群
1.在yarn.resourcemanager.hostname配置项指定的节点中启动YARN集群。

分别通过jps命令查看当前启动的进程



*当YARN集群启动完毕后,由于ResourceManager部署在hadoop1机器上,因此可以访问http://192.168.1.80:50070进入YARN的可视化管理界面,可以查看到当前YARN集群中有3个存活的NodeManager节点。

2.在mapreduce.jobhistory.address配置项指定的节点中启动JobHistory。

*当启动JobHistory后,可以访问mapreduce.jobhistory.address配置项指定的地址进入JobHistory,默认是http://192.168.1.80:19888。
4.Hadoop集群管理
4.1 动态添加节点
1.修改各个节点的hosts文件,添加新节点的主机名与IP映射关系。

2.相互配置SSH,使可以通过SSH进行免密码登录。
3.修改NameNode和ResourceManager所在节点的Slave文件,添加新节点的主机名或IP地址。

4.单独在新节点中启动DataNode和NodeManager。

*进入HDFS管理页面,可以查看到当前HDFS集群中有4个存活的DataNode节点。
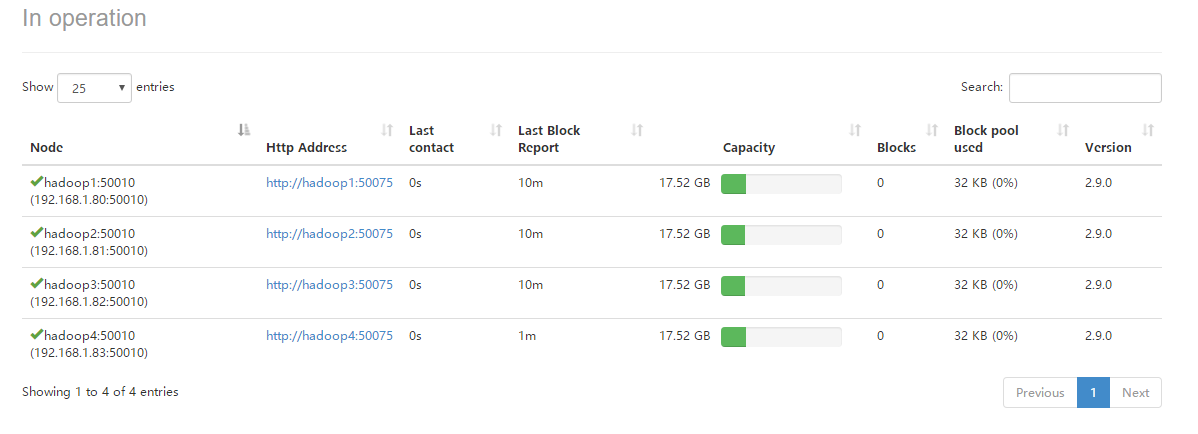
*进入YARN管理页面,可以查看到当前YARN集群中有4个存活的NodeManager节点。
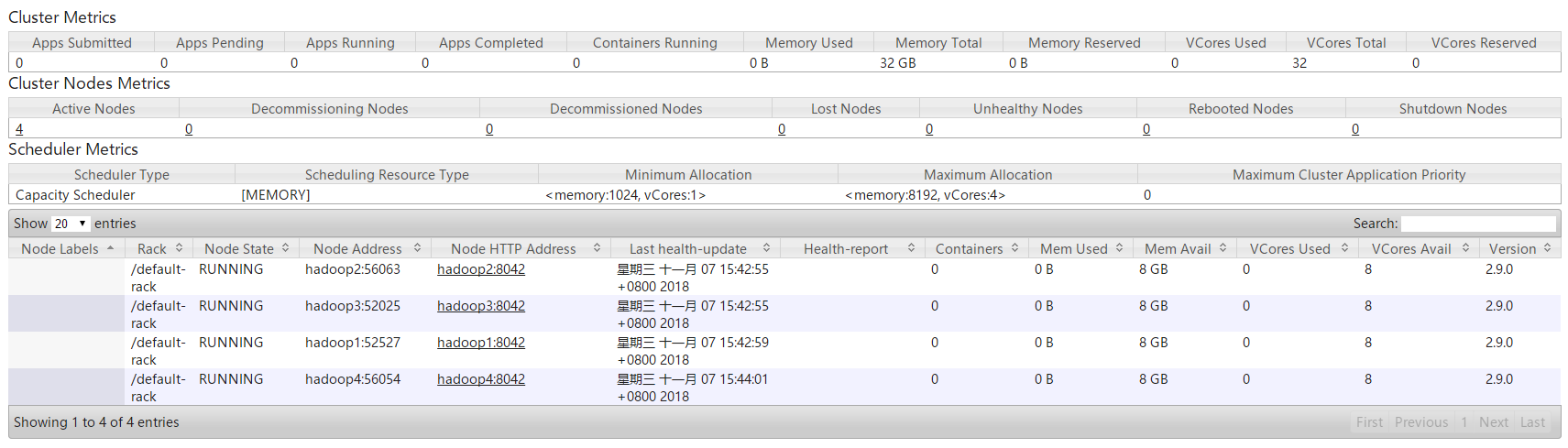
4.2 动态卸载节点
1.修改NameNode所在节点上的hdfs-site.xml配置文件。
<!-- 指定一个配置文件,使NameNode过滤配置文件中指定的host -->
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/hadoop/hadoop-2.9.0/etc/hadoop/hdfs.exclude</value>
</property>
2.修改ResourceManager所在节点上的yarn-site.xml配置文件。
<!-- 指定一个配置文件,使ResourceManager过滤配置文件中指定的host -->
<property>
<name>yarn.resourcemanager.nodes.exclude-path</name>
<value>/usr/hadoop/hadoop-2.9.0/etc/hadoop/yarn.exclude</value>
</property>
3.分别刷新HDFS和YARN集群

查看HDFS管理页面,可见hadoop4的DataNode已被动态的剔除。
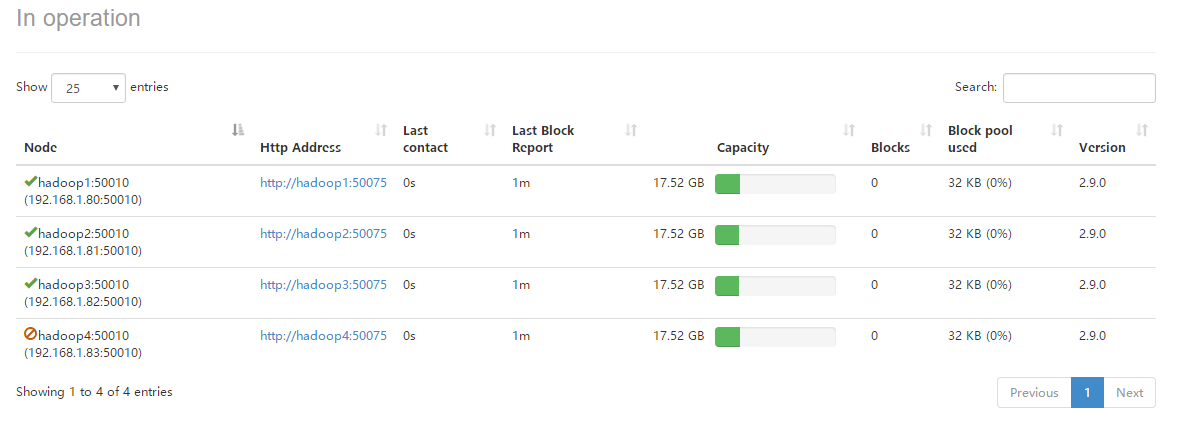
查看YARN管理页面,可见hadoop4的NodeManager已被动态的剔除。
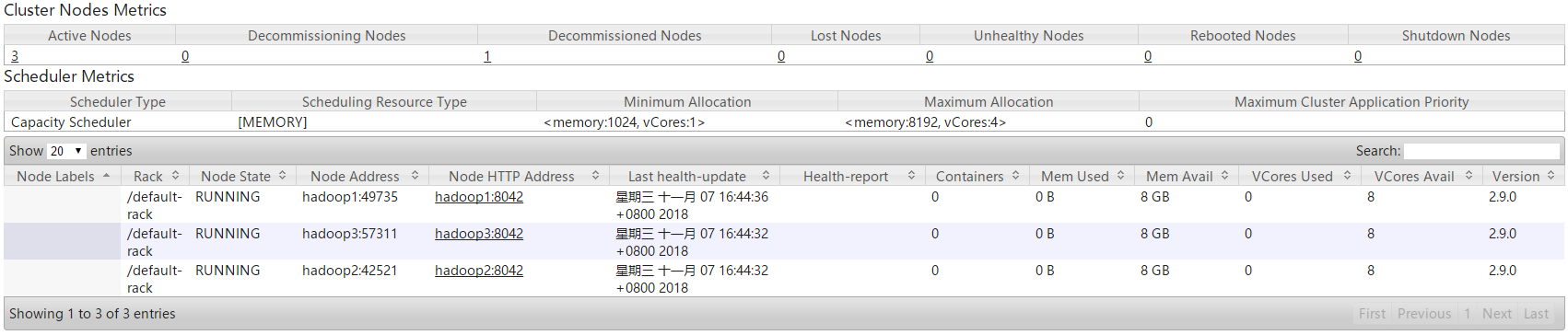
使用jps命令查看hadoop4中Hadoop进程,可以发现NodeManager进程已经被kill掉,只剩下DataNode进程,因此YARN集群在通过配置文件的形式动态过滤节点时,一旦节点被过滤,则NodeManager进程直接被杀死,不能动态的进行恢复,必须重启进程并在exclude.host文件中剔除,而HDFS集群在通过配置文件的形式动态过滤节点时可以动态的进行卸载和恢复。

*若第一次使用该配置则需要重启HDFS和YARN集群,使其重新读取配置文件,往后一旦修改过exclude.host配置文件则直接刷新集群即可。
Hadoop集群管理的更多相关文章
- Hadoop集群管理--保证集群平稳地执行
本篇介绍为了保证Hadoop集群平稳地执行.须要深入掌握的知识.以及一些管理监控的手段,日常维护的工作. HDFS 永久性数据结构 对于管理员来说.深入了解namenode,辅助namecode和da ...
- Hadoop集群管理之配置文件
一.配置文件列表如下: [hadoop@node1 conf]$ pwd /app/hadoop/conf [hadoop@node1 conf]$ echo $HADOOP_HOME /app/ha ...
- Hadoop集群管理之内存管理
1.内存 Hadoop为各个守护进程(namenode,secondarynamenode,jobtracker,datanode,tasktracker)统一分配的内存在hadoop-env.sh中 ...
- zookeeper安装和应用场合(名字,配置,锁,队列,集群管理)
安装和配置详解 本文介绍的 Zookeeper 是以 3.2.2 这个稳定版本为基础,最新的版本可以通过官网http://hadoop.apache.org/zookeeper/ 来获取,Zookee ...
- 容器、容器集群管理平台与 Kubernetes 技术漫谈
原文:https://www.kubernetes.org.cn/4786.html 我们为什么使用容器? 我们为什么使用虚拟机(云主机)? 为什么使用物理机? 这一系列的问题并没有一个统一的标准答案 ...
- 大数据开发学习之构建Hadoop集群-(0)
有多种方式来获取hadoop集群,包括从其他人获取或是自行搭建专属集群,抑或是从Cloudera Manager 或apach ambari等管理工具来构建hadoop集群等,但是由自己搭建则可以了解 ...
- 使用Cloudera部署,管理Hadoop集群
Hadoop系列之(三):使用Cloudera部署,管理Hadoop集群 http://www.cnblogs.com/ee900222/p/hadoop_3.html Hadoop系列之(一):Ha ...
- Apache Hadoop 2.9.2 的集群管理之服役和退役
Apache Hadoop 2.9.2 的集群管理之服役和退役 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 随着公司业务的发展,客户量越来越多,产生的日志自然也就越来越大来,可能 ...
- Hadoop基础-Hadoop的集群管理之服役和退役
Hadoop基础-Hadoop的集群管理之服役和退役 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在实际生产环境中,如果是上千万规模的集群,难免一个一个月会有那么几台服务器出点故 ...
随机推荐
- 【java】Freemarker 动态生成word(带图片表格)
1.添加freemarker.jar 到java项目. 2.新建word文档. 3.将文档另存为xml 格式. 4.将xml格式化后打开编辑(最好用notepad,有格式),找到需要替换的内容,将内容 ...
- 【Oracle RAC】Linux系统Oracle12c RAC安装配置详细记录过程V2.0(图文并茂)
[Oracle RAC]Linux系统Oracle12c RAC安装配置详细过程V2.0(图文并茂) 2 Oracle12c RAC数据库安装准备工作2.1 安装环境介绍2.2 数据库安装软件下载3 ...
- (二)图数据neo4j基本认识
1.neo4j介绍 Neo4j是由Java和Scala实现的开源NoSQL图数据库.自2003年开始研发,直到2007年正式发布第一版.Neo4j的源代码托管在GitHub上,技术支持托管在Stack ...
- SQLServer之删除用户定义的数据库角色
删除用户定义的数据库角色注意事项 无法从数据库删除拥有安全对象的角色. 若要删除拥有安全对象的数据库角色,必须首先转移这些安全对象的所有权,或从数据库删除它们. 无法从数据库删除拥有成员的角色. 若要 ...
- 使用Navicat快速生成MySQL数据字典
1.通过information_schema.COLUMNS表 查询该表可得到所需字段信息 SELECT * FROM information_schema.COLUMNS; 如下图所示: 2.示例 ...
- tensorflow的基本认识
版权申明:本文为博主窗户(Colin Cai)原创,欢迎转帖.如要转贴,必须注明原文网址 http://www.cnblogs.com/Colin-Cai/p/10741013.html 作者:窗户 ...
- python已经感觉到放弃接近的day08
居然能超过一个星期,我甚至都有点佩服我自己了,今天有两个新的知识点,一个简单一个难,先从简单的开始入手吧,进制,进制分为4种,2进制,8进制,10进制,16进制,一般最常用的就是10进制了,计算机用的 ...
- node js 异步运行流程控制模块Async介绍
1.Async介绍 sync是一个流程控制工具包.提供了直接而强大的异步功能.基于Javascript为Node.js设计,同一时候也能够直接在浏览器中使用. Async提供了大约20个函数,包含经常 ...
- Linux新手随手笔记1.5
FHS Linux / 代表根目录 /root 管理员的家目录 /boot 启动引导文件,以及开机菜单都会保存在里面 /bin 保存我们系统中命令的目录,不止bin,只要带bin的比如sb ...
- codeforces 1064套题
a题:题意就是问,3个数字差多少可以构成三角形 思路:两边之和大于第三遍 #include<iostream> #include<algorithm> using namesp ...