kNN算法基本原理与Python代码实践
kNN是一种常见的监督学习方法。工作机制简单:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k各训练样本,然后基于这k个“邻居”的信息来进行预测,通常,在分类任务中可使用“投票法”,即选择这k个样本中出现最多的类别标记作为预测结果;在回归任务中可以使用“平均法”,即将这k个样本的实值输出标记的平均值作为预测结果;还可以基于距离远近进行加权平均或加权投票,距离越近的样本权重越大。[1]
kNN的伪代码如下:[2]
对未知类别属性的数据集中的每个点依次执行以下操作:
(1)计算已知类别数据集中的点与当前点之间的距离;
(2)按照距离递增次序排序;
(3)选取与当前点距离最小的k个点;
(4)确定前k个点所在类别的出现频率;
(5)返回前k个点出现频率最高的类别作为当前点的预测分类。
以下通过图来进一步解释:
假定要对紫色的点进行分类,现有红绿蓝三个类别。此处以k为7举例,即找出到紫色距离最近的7个点。
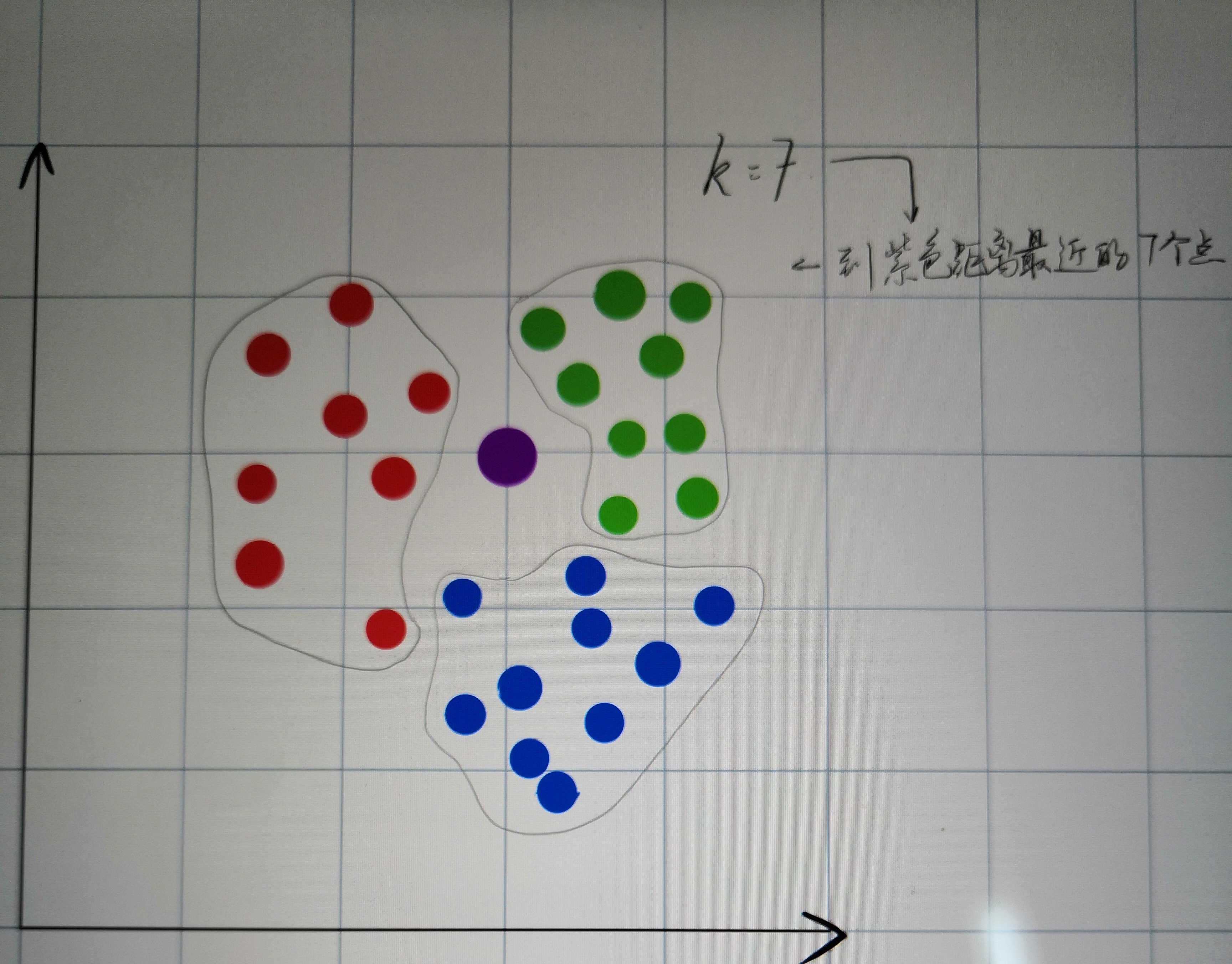
分别找出到紫色距离最近的7个点后,我们将这七个点分别称为1、2、3、4、5、6、7号小球。其中红色的有1、3两个小球,绿色有2、4、5、6四个小球,蓝色有7这一个小球。

显然,绿色小球的个数最多,则紫色小球应当归为绿色小球一类。

以下给出利用kNN进行分类任务的最基本的代码。
KNN.py文件内定义了kNN算法的主体部分
from numpy import *
import operator def createDataSet():
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0.0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels def kNN_Classify(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
#关于tile函数的用法
#>>> b=[1,3,5]
#>>> tile(b,[2,3])
#array([[1, 3, 5, 1, 3, 5, 1, 3, 5],
# [1, 3, 5, 1, 3, 5, 1, 3, 5]])
sqDiffMat = diffMat ** 2
sqDistances = sum(sqDiffMat, axis = 1)
distances = sqDistances ** 0.5# 算距离
sortedDistIndicies = argsort(distances)
#关于argsort函数的用法
#argsort函数返回的是数组值从小到大的索引值
#>>> x = np.array([3, 1, 2])
#>>> np.argsort(x)
#array([1, 2, 0])
classCount = {} # 定义一个字典
# 选择k个最近邻
for i in range(k):
voteLabel = labels[sortedDistIndicies[i]]
# 计算k个最近邻中各类别出现的次数
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1 # 返回出现次数最多的类别标签
maxCount = 0
for key, value in classCount.items():
if value > maxCount:
maxCount = value
maxIndex = key
return maxIndex
KNN_TEST.py文件中有两个样例测试。
#!/usr/bin/python
# coding=utf-8
import KNN
from numpy import *
# 生成数据集和类别标签
dataSet, labels = KNN.createDataSet()
# 定义一个未知类别的数据
testX = array([1.2, 1.0])
k = 3
# 调用分类函数对未知数据分类
outputLabel = KNN.kNN_Classify(testX, dataSet, labels, 3)
print("Your input is:", testX, "and classified to class: ", outputLabel) testX = array([0.1, 0.3])
outputLabel = KNN.kNN_Classify(testX, dataSet, labels, 3)
print("Your input is:", testX, "and classified to class: ", outputLabel)
代码输出:

画图解释一下输出结果:

参考文献:
[1]机器学习,周志华,清华大学出版社2016.
[2]机器学习实战,Peter Harrington,人民邮电出版社.
2019-03-06
01:52:08
kNN算法基本原理与Python代码实践的更多相关文章
- KNN算法原理(python代码实现)
kNN(k-nearest neighbor algorithm)算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性 ...
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- 神经网络BP算法C和python代码
上面只显示代码. 详BP原理和神经网络的相关知识,请参阅:神经网络和反向传播算法推导 首先是前向传播的计算: 输入: 首先为正整数 n.m.p.t,分别代表特征个数.训练样本个数.隐藏层神经元个数.输 ...
- tf–idf算法解释及其python代码
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- 《机器学习实战》kNN算法及约会网站代码详解
使用kNN算法进行分类的原理是:从训练集中选出离待分类点最近的kkk个点,在这kkk个点中所占比重最大的分类即为该点所在的分类.通常kkk不超过202020 kNN算法步骤: 计算数据集中的点与待分类 ...
- 光照问题之常见算法比较(附Python代码)
一.灰度世界算法 ① 算法原理 灰度世界算法以灰度世界假设为基础,该假设认为:对于一幅有着大量色彩变化的图像,R,G,B三个分量的平均值趋于同一灰度值Gray.从物理意义上讲,灰色世界法假设自然界景物 ...
- 朴素贝叶斯算法简介及python代码实现分析
概念: 贝叶斯定理:贝叶斯理论是以18世纪的一位神学家托马斯.贝叶斯(Thomas Bayes)命名.通常,事件A在事件B(发生)的条件下的概率,与事件B在事件A(发生)的条件下的概率是不一样的:然而 ...
- 【机器学习】:Kmeans均值聚类算法原理(附带Python代码实现)
这个算法中文名为k均值聚类算法,首先我们在二维的特殊条件下讨论其实现的过程,方便大家理解. 第一步.随机生成质心 由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给 ...
随机推荐
- javascript原型模式概念解读
原型模式(prototype)是指用原型实例指向创建对象的种类,并且通过拷贝这些原型创建新的对象.对于原型模式,可以利用JavaScript特有的原型继承特性去创建对象的方式,真正的原型继承是作为最新 ...
- nmap用法
Nmap 7.70SVN ( https://nmap.org ) Usage: nmap [Scan Type(s)] [Options] {target specification} TARGET ...
- 附录A application.properties配置项
摘自官网,仅作为参考用 Part X. Appendices # =================================================================== ...
- yii的数据库相关操作
获取某一列数据 self::find()->where(['pid'=>$this->id])->select('id')->column(); 更新操作 $model- ...
- web中spring框架启动流程第一发
web.xml中springmvc相关配置如下:<servlet> <servlet-name>springmvc</servlet-name> <servl ...
- mac Robotframework执行时报错Robot Framework installation not found.
虽然已经装了,但一直报错 ,版本是3.1.1 最新版 ➜ ~ pip install robotframework DEPRECATION: Python 2.7 will reach the en ...
- node+webpack+vue-cli
安装nodejs + 安装webpack + 安装vue-cli+安装脚手架模板+安装依赖+运行 1 安装nodejs 去官网安装node.js( http://www.runoob.com/nod ...
- Linux之文件权限
在Linux系统中,root用户基本对于每个文件都有可操作性,但是普通用户可能只能查看特定的文件,这是因为文件存在的权限机制,初步掌握文件的基本权限就操作可以对一些系统文件或者自定义文件有一个操作空间 ...
- Ubuntu16.04重新安装MySQL数据库
安装之前先检查mysql是否卸载干净 dpkg --list|grep mysql 如果没有卸载干净请看上篇文章将mysql卸载干净 Ubuntu16.04彻底卸载MySQL 开始安装 可以直接默认安 ...
- Fiddler抓包【4】_重定向AutoResponder
1. 文件及图片替换(Enable rules) 目的:允许从本地返回文件,代替服务器响应,而不用将文件发布到服务器[可用正式环境验证本地文件] 步骤一:抓页面http://ir.baidu.com/ ...