spring-cloud-hystrix-dasboard服务调用监控
Hystrix仪表盘:
在断路器原理的介绍中 ,我们多次提到关千请求命令的度量指标的判断。这些度量指标都是HystrixComrnand和HystrixObservableComrnand实例在执行过程中记录的重要信息, 它们除了在Hystrix断路器实现中使用之外,对千系统运维也有非常大的帮助 。这些指标信息会以“ 滚动时间窗 ”与“ 桶 ”结合的方式进行汇总,并在内存中驻留一 段时间,以供内部或外部进行查询使用,包括每秒执行多少请求,多少成功,多少失败等。Netflix通过hystrix-metrics-event-stream项目实现了对以上指标的监控。SpringCloud也提供了hystrix dashboard的整合,对监控内容转化成可视化界面。Hystrix仪表盘就是这些指标内容的消费者之 一 。通过之前的内容,我们已经体验到了Spring Cloud对Hystrix的优雅整合。除此之外,Spring Cloud还完美地整合了它的仪表盘组件Hystrix Dashboard, 它主要用来 实时监控Hystrix的各项指标信息。通过HystrixDashboard反馈的实时信息,可以帮助我们快速发现系统中存在的问题,从而及时地采取应对措施。构建一个Hystrix Dashboard 来对RIBBON-SERVER实现监控。
在 Spring Cloud 中构建 一 个 Hystrix Dashboard 非常简单, 只需要下面 4 步:
<properties>
<project.build.sourceEncoding>UTF-</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<spring-cloud.version>Finchley.SR3</spring-cloud.version>
</properties> <dependencyManagement>
<dependencies>
<dependency>
<!-- SpringCloud 所有子项目 版本集中管理. 统一所有SpringCloud依赖项目的版本依赖-->
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement> <dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix</artifactId>
<version>1.4..RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix-dashboard</artifactId>
<version>1.4..RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
</dependencies> <build>
<plugins>
<plugin><!-- SpringBoot 项目打jar包的Maven插件 -->
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
2.修改application.yml
server:
port: spring:
application:
name: hystrix-dasboard #服务注册到Eureka上使用的名称
3.修改启动类
@SpringBootApplication
@EnableHystrixDashboard //开启仪表盘图形化监控的注解
public class HystrixDasboardApp {
private final static Logger log = LoggerFactory.getLogger(HystrixDasboardApp.class); public static void main(String[] args) {
SpringApplication.run(HystrixDasboardApp.class,args);
log.info("服务启动成功");
}
}
4.启动本微服务 访问路径为 http://localhost:9005/hystrix,看到以下界面,说明仪表盘配置成功

Delay: 该参数用来控制服务器上轮询监控信息的延迟时间,默认为 2000 毫秒, 可以通过配置该属性来降低客户端的网络和CPU消耗。
Title: 该参数对应了上图头部标题 Hystrix Stream 之后的内容, 默认会使用具体监控实例的URL, 可以通过配置该信息来展示更合适的标题。
这是Hystrix Dashboard的监控首页, 该页面中并没有具体的监控信息。 从页面的文字内容中我们可以知道,Hystrix Dashboard共支持三种不同的监控方式, 如下所示。
- 默认的集群监控: 通过URL http://turbine-hostname:port/turbine.stream开启, 实现对默认集群的监控。
- 指定的集群监控: 通过URL http://turbine-hostname:port/turbine.strearn?cluster = [clusterName]开启, 实现对clusterName集群的监控。
- 单体应用的监控: 通过URL http: //hystrix-app:port/hystrix.stream开启, 实现对具体某个服务实例的监控。
单体应用的监控:
前两者都是对集群的监控,需要整合Turbine才能实现。这里我们先来实现单个服务实例的监控。既然Hystrix Dashboard监控单实例节点需要通过访间实例的/hystrix.stream接口来实现, 我们自然需要为服务实例添加这个端点, 而添加该功能的步骤也同样简单, 只需要下面两步。
- 在服务实例 pom.xml 中的 dependencies 节点中新增 spring-boot-starter-actuator 监控模块以开启监控相关的端点, 并确保已经引入断路器的依赖 spring-cloud-starter-hystrix.
- 确保在服务实例的主类中已经使用 @EnableCircuitBreaker 注解, 开启了断路器功能。
- 另外,由于版本的原因,我这里还需要在RIBBON-SERVER中添加一个Bean:
@Bean
public ServletRegistrationBean getServlet(){
HystrixMetricsStreamServlet streamServlet = new HystrixMetricsStreamServlet();
ServletRegistrationBean registrationBean = new ServletRegistrationBean(streamServlet);
registrationBean.setLoadOnStartup();
registrationBean.addUrlMappings("/actuator/hystrix.stream");
registrationBean.setName("HystrixMetricsStreamServlet");
return registrationBean;
}
在为 RIBBON-SERVER加入上面的配置之后,重启它的实例, /actuator/hystrix.stream 就是用于 Hystrix Dashboard 来展现监控信息的接口。
到这里已经完成了所有的配置,在 Hystrix Dashboard 的首页输入 http://localhost:9001/actuator/hystrix.stream, 可以看到已启动对 RIBBON-SERVER的监控,单击 MonitorStream 按钮, 可以看到如下页面。
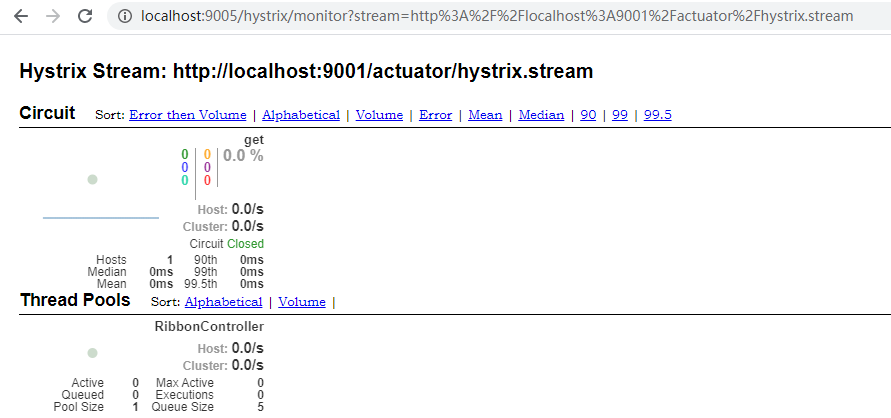
实心圆:共有两种含义,他通过颜色的变化代表了实例的健康程度,它的健康程度从绿<黄<橙<红递减,该实心圆除了颜色的变化之外,它的大小也会根据实例的请求流量发生变化。流量越大该实心圆就越大。所以通过该实心圆,就可以在大量的实例中快速发现故障实例和高压力实例
对于可视化监控界面(上图) 7 色 1 圈 1 线的含义如下图:

至此就配置好了仪表盘供用户查看服务实例的健康状况.
Turbine集群监控:
上面我们提到提到过除了可以开启单个实例的监控页面之外, 还有 一 个监控端点 /turbine.stream 是对集群使用的。 从端点的命名中, 可猜测到这里我们将引入 Turbine, 通过它来汇集监控信息,并将聚合后的信息提供给 HystrixDashboard 来集中展示和监控。
构建监控聚合服务
通过引入 Turbine 来聚合RIBBON-SERVER服务的监控信息,并输出给 Hystrix Dashboard 来进行展示。
1.创建 一 个标准的Spring Boot工程, 命名为turbine。
2.编辑porn. xml, 具体依赖内容如下所示。
<properties>
<project.build.sourceEncoding>UTF-</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties> <dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-turbine</artifactId>
<version>1.4..RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
</dependencies>
3.创建应用主类TurbineApplication, 并使用@EnableTurbine 注解开启 Turbine。
@EnableTurbine
@EnableDiscoveryClient
@SpringBootApplication
public class TurbineApp { public static void main(String[] args) {
SpringApplication.run(TurbineApp.class, args); }
}
4.在application.yml中加入Eureka和Turbine的相关配置, 具体如下:
server:
port:
spring:
application:
name: turbine #服务注册到Eureka上使用的名称
turbine:
aggregator:
cluster-config: default
app-config: RIBBON-SERVER,ribbon-server-two #指定了需要收集监 控信息的服务名
cluster-name-expression: new String("default") #参数指定了集群名称为default
combine-host-port: true
# true 同一主机上的服务通过host和port的组合来进行区分,默认为true
# false 时 在本机测试时 监控中host集群数会为1了 因为本地host是一样的
eureka:
client:
service-url: # 集群情况下如下,如果是单机版,只需要配置单机版Eureka地址
defaultZone: http://localhost:7001/eureka/,http://localhost:7002/eureka/
instance:
instance-id: hystrix-dasboard-turbine
prefer-ip-address: true #访问路径显示IP地址
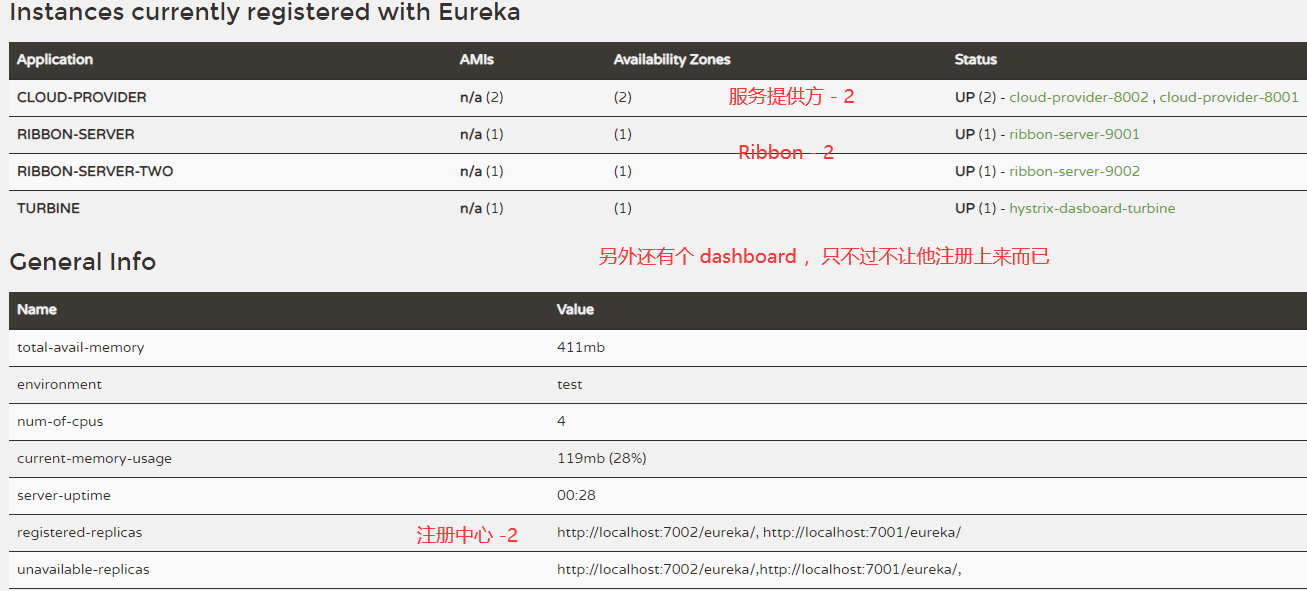
在完成了上面的内容构建之后,我们来体验 一 下Turbine对集群的监控能力。分别启动eureka-server、 cloud-provider、 RIBBON-SERVER、 Turbine 以及 HystrixDashboard。
整个架构在注册中心上的注册信息来看是这样的:
访问Hystrix Dashboard, 并开启对 http://localhost:9006/turbine.stream的监控, 我们可以看到如下页面:
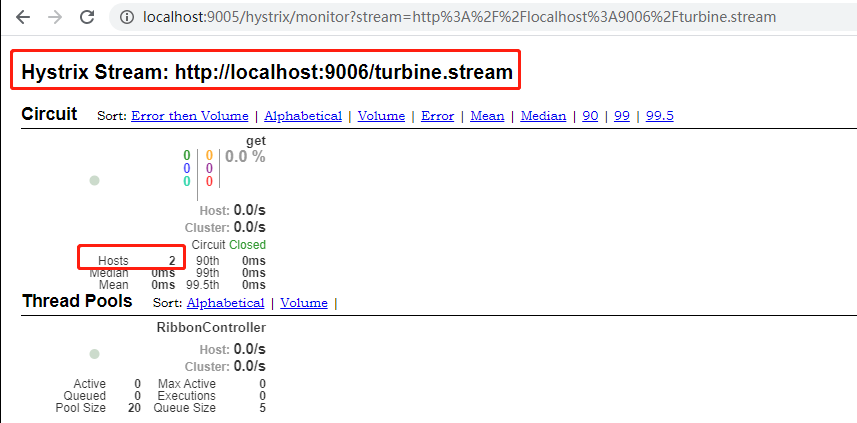
我们启动了两个Ribbon-consumer,但是在监控页面依然只是展示了一个监控图。但是可以发现集群报告区域中的Hosts属性已经变成了2个实例。由此我们知道ribbon-consumer启动了两个实例,只是展示在一个监控图中,是由于两个实例是同一个服务,而对于服务集群来说,我们关注的是服务集群的高可用,所以Turbine会将相同的服务作为整体看待,并汇总成一个监控图。
与消息代理结合:
Spring Cloud在封装Turbine的时候, 还封装了基于消息代理的收集实现。这里多了一 个重要元素RabbitMQ。 对于RabbitMQ 的安装我们可以参考 https://www.cnblogs.com/wuzhenzhao/p/10315642.html 。所以, 我们可以将所有需要收集的监控信息都输出到消息代理中,然后Turbine服务再从消息代理中异步获取这些监控信息, 最后将这些监控信息聚合并输出到Hystrix Dashboard中。
1.创建 一 个标准的Spring Boot工程, 命名为turbine-amqp。
2.编辑pom.xml, 具体依赖内容如下所示:这里我们需要使用 Java 8 来运行。
<properties>
<project.build.sourceEncoding>UTF-</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties> <dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-turbine-amqp</artifactId>
<version>1.4..RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
</dependencies>
3.在应用主类中使用@EnableTurbineStrearn注解来启用Turbine Stream的配置。
@EnableTurbineStream
@EnableDiscoveryClient
@SpringBootApplication
public class TurbineAMQPApp { public static void main(String[] args) {
SpringApplication.run(TurbineAMQPApp.class, args); }
}
4.配置application.yml文件。
server:
port:
spring:
rabbitmq:
host: 192.168.1.101
username: guest
password: guest
port:
application:
name: turbine-amqp #服务注册到Eureka上使用的名称
turbine:
aggregator:
cluster-config: default
app-config: RIBBON-SERVER,ribbon-server-two #指定了需要收集监 控信息的服务名
cluster-name-expression: new String("default") #参数指定了集群名称为default
combine-host-port: true
# true 同一主机上的服务通过host和port的组合来进行区分,默认为true
# false 时 在本机测试时 监控中host集群数会为1了 因为本地host是一样的
eureka:
client:
service-url: # 集群情况下如下,如果是单机版,只需要配置单机版Eureka地址
defaultZone: http://localhost:7001/eureka/,http://localhost:7002/eureka/
instance:
instance-id: hystrix-dasboard-turbine-amqp
prefer-ip-address: true #访问路径显示IP地址
对于Turbine的配置已经完成了, 下面需要对服务消费者RIBBON-SERVER做 一 些修改, 使其监控信息能够输出到RabbitMQ上。 这个修改也非常简单, 只需在pom.xml中
增加对spring-cloud-netflix-hystrix-amqp的依赖, 具体如下:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-netflix-hystrix-amqp</artifactId>
<version>1.4..RELEASE</version>
</dependency>
再配置相关Rabbitmq配置
spring:
rabbitmq:
host: 192.168.1.101
username: guest
password: guest
port:
重启 RIBBON-SERVER、turbine-amqp。通过引入消息代理,我们的Turbine和Hystrix Dashboard实现的监控架构在注册中心上的注册信息来看是这样的:
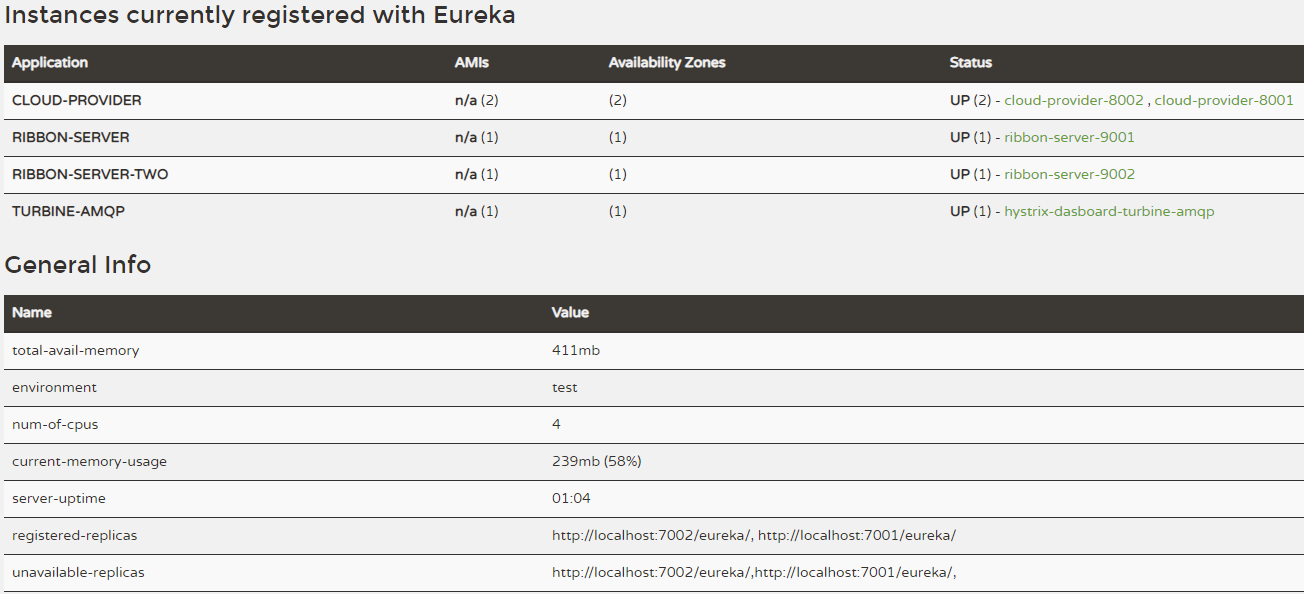
此时可以查看RabbitMQ会有对应的连接的:
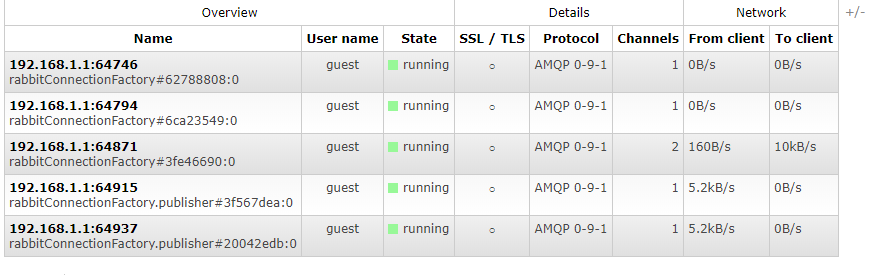
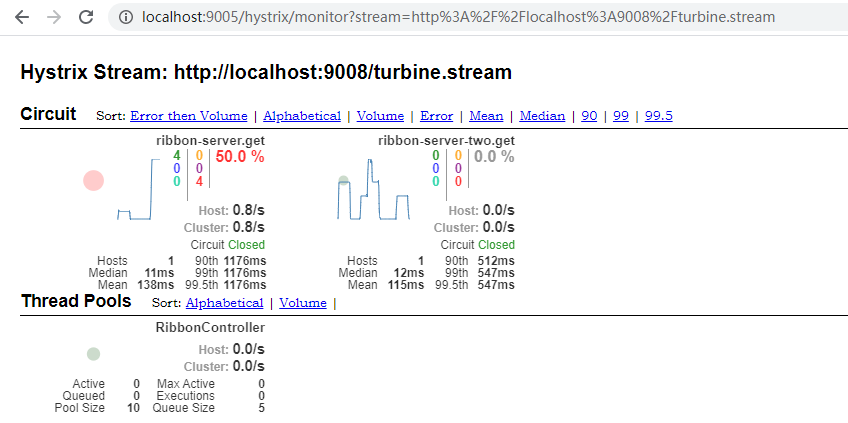
我们可以获得如之前实现的同样结果, 只是这里的监控信息收集是通过消息代理异步实现的。下图就是最终的监控效果的呈现,原来两个RIBBON-SERVER都在这里显示了。并不像 turbine 那样子合到了一起
spring-cloud-hystrix-dasboard服务调用监控的更多相关文章
- Spring Cloud 声明式服务调用 Feign
一.简介 在上一篇中,我们介绍注册中心Eureka,但是没有服务注册和服务调用,服务注册和服务调用本来应该在上一章就应该给出例子的,但是我觉得还是和Feign一起讲比较好,因为在实际项目中,都是使用声 ...
- Spring cloud 两种服务调用方式(Rest + Ribbon) 和 Fegin方式
1:Rest + Ribbon @Bean @LoadBalanced RestTemplate restTemplate() { return new RestTemplate(); } @Auto ...
- Spring Cloud Hystrix 服务容错保护 5.1
Spring Cloud Hystrix介绍 在微服务架构中,通常会存在多个服务层调用的情况,如果基础服务出现故障可能会发生级联传递,导致整个服务链上的服务不可用为了解决服务级联失败这种问题,在分布式 ...
- 笔记:Spring Cloud Hystrix 服务容错保护
由于每个单元都在不同的进程中运行,依赖通过远程调用的方式执行,这样就有可能因为网络原因或是依赖服务自身问题出现调用故障或延迟,而这些问题会直接导致调用方的对外服务也出现延迟,若此时调用方的请求不断增加 ...
- 第五章 服务容错保护:Spring Cloud Hystrix
在微服务架构中,我们将系统拆分为很多个服务,各个服务之间通过注册与订阅的方式相互依赖,由于各个服务都是在各自的进程中运行,就有可能由于网络原因或者服务自身的问题导致调用故障或延迟,随着服务的积压,可能 ...
- 微服务架构之spring cloud hystrix&hystrix dashboard
在前面介绍spring cloud feign中我们已经使用过hystrix,只是没有介绍,spring cloud hystrix在spring cloud中起到保护微服务的作用,不会让发生的异常无 ...
- 第五章 服务容错保护: Spring Cloud Hystrix
在微服务架构中, 存在着那么多的服务单元, 若一个单元出现故障, 就很容易因依赖关系而引发故障的蔓延,最终导致整个系统的瘫痪,这样的架构相较传统架构更加不稳定.为了解决这样的问题, 产生了断路器等一系 ...
- Spring Cloud 微服务四:熔断器Spring cloud hystrix
前言:在微服务架构中,一般都是进程间通信,有可能调用链都比较长,当有底层某服务出现问题时,比如宕机,会导致调用方的服务失败,这样就会发生一连串的反映,造成系统资源被阻塞,最终可能造成雪崩.在sprin ...
- Spring Cloud Hystrix理解与实践(一):搭建简单监控集群
前言 在分布式架构中,所谓的断路器模式是指当某个服务发生故障之后,通过断路器的故障监控,向调用方返回一个错误响应,这样就不会使得线程因调用故障服务被长时间占用不释放,避免故障的继续蔓延.Spring ...
- Spring Cloud Hystrix 服务容错保护
目录 一.Hystrix 是什么 二.Hystrix断路器搭建 三.断路器优化 一.Hystrix 是什么 在微服务架构中,我们将系统拆分成了若干弱小的单元,单元与单元之间通过HTTP或者TCP等 ...
随机推荐
- 第一个Appium脚本
测试环境 Win 10 64bit Python 3.5 Appium 1.7.2 Andriod 5.1.1 模拟器& Android 5.1 MX4 测试App:考研帮Android版 3 ...
- jenkins针对不同的项目组对用户进行权限分配
因jenkins上存有de(开发).te(测试)等三个不同环境的项目,同时因为项目需求,需要对不同的开发及测试人员配置不同的jenkins权限,即以项目为单位,对不同人员进行不同权限配置,要求如下: ...
- (最详细)小米Note 3的Usb调试模式在哪里打开的流程
就在我们使用安卓手机链接PC的时候,或者使用的有些应用软件比如我们单位营销部门就在使用的应用软件引号精灵,之前使用的老版本就需要开启USB开发者调试模式下使用,现就在新版本不需要了,如果手机没有开启U ...
- Day 1 上午
唉,上午就碰到一个开不了机的电脑,白白浪费了半个小时,真的难受QwQ POINT1 枚举 枚举也称作穷举,指的是从问题所有可能的解的集合中一一枚举各元素. 用题目中给定的检验条件判定哪些是无用的,哪些 ...
- vue axios使用方法
首先安装axios: cnpm install axios -save 安装成功后,在main.js页面引用: import axios from 'axios' import Qs from 'qs ...
- percona-xtrabackup快速安装及其简单使用
percona-xtrabackup快速安装及其简单使用 cd /opt/环境:centos6.x yum -y install perl-DBIyum -y install perl-DBD-MyS ...
- NameNode和SecondaryNameNode工作原理剖析
NameNode和SecondaryNameNode工作原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode中的元数据是存储在那里的? 1>.首先,我 ...
- Maven 学习总结 (五) 之 持续集成、构建web应用
持续集成的作用.过程和优势 简单说,持续集成就是快速且高频率地自动构建项目的所有源码,并为项目成员提供丰富的反馈信息. 快速:集成的速度要尽可能地快,开发人员不希望自己的代码提交半天之后才得到反馈. ...
- [源码分析]ReentrantLock & AbstractQueuedSynchronizer & Condition
首先声明一点: 我在分析源码的时候, 把jdk源码复制出来进行中文的注释, 有时还进行编译调试什么的, 为了避免和jdk原生的类混淆, 我在类前面加了"My". 比如把Reentr ...
- weblogic找不到数据源
查看weblogic日志 报错是每个数据源都找不到. 查看oracle用户状态 select username,account_status,lock_date from dba_users; 解 ...