《Pro SQL Server Internals, 2nd edition》15w
第三章 统计
SQL Server查询优化器在为查询选择执行计划时使用基于成本的模型。它估计不同执行计划的成本,并选择成本最低的一个。但是,请记住,SQL Server并不搜索可用于查询的最佳执行计划,因为评估所有可能的替代方案在CPU方面既费时又昂贵。查询优化器的目标是找到一个足够好的执行计划,足够快。
基数估计(在查询执行的每个步骤中需要处理的行数的估计)是查询优化中最重要的因素之一。这个数字会影响连接策略的选择、查询执行所需的内存量(内存授予)以及其他许多事情。
访问数据时要使用的索引的选择就是这些因素之一。正如您将记住的,键和RID查找操作在I/O方面是昂贵的,并且SQL Server在估计将需要大量这些操作时不使用非集群索引。SQL Server维护有关索引的统计信息,在某些情况下还维护有关列的统计信息,这有助于执行这样的估计。
SQL Server统计介绍
SQL Server统计信息是在索引键值中,有时在常规列值中包含关于数据分布的信息的系统对象。可以在支持比较操作的任何数据类型上创建统计信息,例如>、<、=等。
让我们检查上一章中在清单2-15中创建的dbo.Books表中的IDX_BOOKS_ISBN索引统计信息。可以使用DBCC SHOW_STATISTICS('dbo.Books',IDX_BOOKS_ISBN)命令执行此操作。结果如图3-1所示。
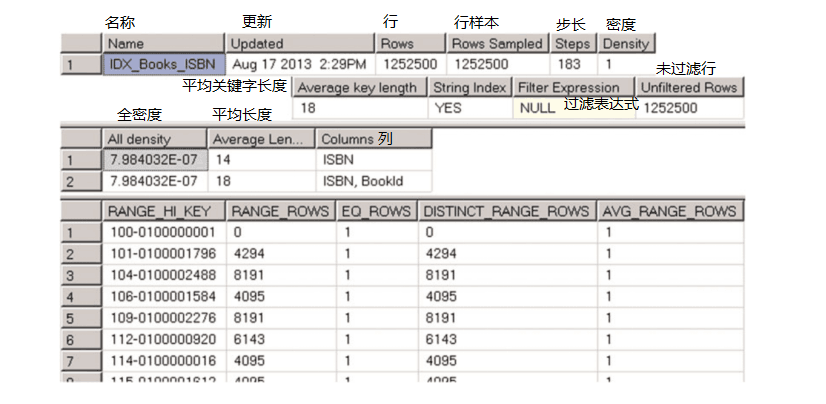
图3-1. DBCC SHOW_STATISTICS输出
如您所见,DBCC SHOW_STATISTICS命令返回三个结果集。第一个包含有关统计信息的一般元数据信息,如名称、更新日期、更新统计信息时索引中的行数等。第一结果集中的Steps列指示直方图中的步骤/值的数量(稍后详细介绍)。密度值不由查询优化器使用,并且仅出于向后兼容的目的而显示。
第二个结果集,称为密度向量,包含有关来自统计(索引)的关键值组合的密度的信息。它是根据1/3的不同值公式计算的,它表明平均每个键值组合有多少行。即使IDX_Books_ISBN索引只定义了一个键列ISBN,它还包括作为索引行的一部分的聚类索引键。我们的表有12500个唯一的ISBN值,ISBN列的密度为1.0/1252500=7.984032E-07。(ISBN,BookId)列的所有组合也是唯一的,并且具有相同的密度。
最后一个结果集称为直方图。直方图中的每条记录,称为直方图步骤,包括统计(索引)最左侧列中的示例键值以及关于从前一个值到当前RANGE_HI_KEY值范围内的数据分布的信息。让我们更深入地研究直方图列。

让我们用清单3-1所示的代码将一组重复的ISBN值插入索引中。
清单3-1.将重复的ISBN值插入索引。

现在,如果再次运行DBCC SHOW_STATISTICS(“dbo.Books”,IDX_BOOKS_ISBN)命令,您将看到图3-2所示的结果。

图3-2.DBCC SHOW_STATISTICS输出
带有前缀104的ISBN值现在有重复,这会影响直方图。还值得一提的是,第二结果集中的密度信息也发生了变化。具有重复值的ISBN s的密度高于(ISBN,BookId)列的组合,这仍然是唯一的。
让我们运行SELECT BookId,Title FROM dbo.Books WHERE ISBN LIKE'114%'语句并检查执行计划,如图3-3所示。
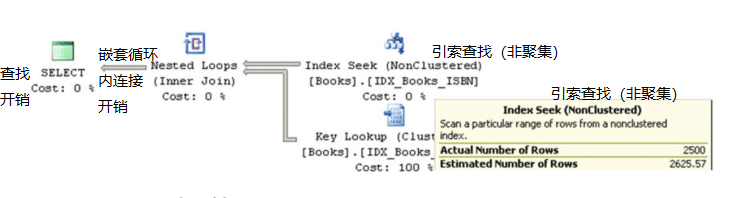
图3-3. 执行计划查询
大多数执行计划操作员都有两个重要的属性。实际行数指示运算符执行过程中处理了多少行。估计行数指示在查询优化阶段为该运算符估计的SQLServer行数。在我们的例子中,SQLServer估计有2625行ISBNs从114开始。如果您查看图3-2所示的直方图,您将看到步骤10存储ISBN区间的数据分布信息,这些信息包括所选的值。即使使用线性近似,也可以估计要接近SQL Server所确定的行数。
关于统计有两件非常重要的事情要记住。
1.直方图仅存储最左侧统计(索引)列的数据分布信息。统计学中有关于键值的多列密度的信息,但就是这样。直方图中的所有其他信息仅涉及最左边的统计列的数据分布。
2.SQL Server最多保留直方图中的200个步骤,而不管表的大小以及表是否被分区。每个直方图步骤所覆盖的间隔随着表的增长而增加。这导致对于大型表的统计信息不那么准确。
在复合索引的情况下,当索引中的所有列都用作所有查询中的谓词时,将具有较低密度/较高唯一值百分比的列定义为索引的最左侧列是有益的。这将允许SQL Server更好地利用统计数据中的数据分布信息。但是,您应该考虑谓词的SARGability(可搜索性)。例如,如果所有查询都在where子句中使用FirstName=@FirstName和LastName=@LastName谓词,那么最好将LastName作为索引中最左边的列。然而,对于
FirstName=@FirstName和LastName<>@LastName,其中LastName不可SARGable。
列级统计
除了索引级统计之外,还可以创建单独的列级统计信息。此外,在某些情况下,SQL Server会自动创建这样的统计数据。让我们看一个示例,创建一个表,并用清单3-2所示的数据填充它。
66-65页
统计及执行计划
默认情况下,SQL Server自动创建和更新统计信息。在数据库级别上有两个选项可以控制这种行为:
- “自动创建统计信息”控制优化程序是否自动创建列级统计信息。 此选项不会影响始终创建的索引级统计信息。默认情况下启用“自动创建统计数据库”选项。
- 2.启用“自动更新统计数据库”选项后,SQL Server会在每次编译或执行查询时检查统计信息是否过时,并在需要时更新它们。 默认情况下也会启用“自动更新统计数据库”选项。
■提示您可以使用STATISTICS_NORECOMPUTE索引选项控制索引级别上统计信息的自动更新行为。默认情况下,此选项设置为OFF,这意味着统计信息会自动更新。 在索引或表级别更改自动更新行为的另一种方法是使用sp_autostats系统存储过程。
SQL Server根据影响统计信息列的INSERT,UPDATE,DELETE和MERGE语句执行的更改次数确定统计信息是否已过时。SQL Server计算统计信息列的更改次数,而不是更改的行数。 例如,如果您将同一行更改100次,则将其计为100次更改而不是1次更改。
有三种不同的方案,称为统计信息更新阈值,有时也称为统计信息重新编译阈值,其中SQL Server将统计信息标记为过时。
- 当表为空时,SQL Server在向表中添加数据时会过时。
- 当表的行少于500行时,SQL Server会在统计列每500次更改后过期统计信息。
- 在SQL Server 2016和SQL Server 2016之前,数据库兼容级别<130:当一个表有500行或更多行时,SQL Server会在每500+(表中总行数的20%)更改统计信息后过期统计信息列。
在SQL Server 2016中,数据库兼容级别为130:大型表上的统计信息更新阈值将变为动态,并取决于表的大小。 表具有的行越多,阈值越低。在具有数百万甚至数十亿行的大型表上,统计信息更新阈值可能只是表中总行数的一小部分。SQL Server 2008R2 SP1及更高版本中的跟踪标志T2371也可以启用此行为。
表3-1总结了不同版本的SQL Server中的统计信息更新阈值行为
表3-1. 统计信息更新阈值和SQL Server版本

这导致我们得出一个非常重要的结论。 使用静态统计信息更新阈值,触发统计信息更新所需的统计信息列的更改次数与表大小成比例。表越大,统计信息自动更新的次数就越少。 例如,对于包含10亿行的表,您需要对统计信息列执行大约2亿次更改,以使统计信息过期。建议尽可能使用动态更新阈值。
让我们来看看这种行为如何影响我们的系统和执行计划。 此时,表dbo.Books有1,265,000行。 让我们在表中添加250,000行,前缀为999,如清单3-5所示。在此示例中,我使用的是未启用T2371的SQL Server 2012。如果在启用动态统计信息更新阈值的情况下运行它,则可以看到不同的结果。 此外,SQL Server 2014中引入的新基数估计器也可以改变行为。 我们将在本章后面讨论它。
清单3-5. 将行添加到dbo.Books

;with Postfix(Postfix)
as
(
select 100000001
union all
select Postfix + 1
from Postfix
where Postfix < 100250000
)
insert into dbo.Books(ISBN, Title)
select
'999-0' + convert(char(9),Postfix)
,'Title for ISBN 999-0' + convert(char(9),Postfix)
from Postfix
option (maxrecursion 0);
现在,让我们运行SELECT * FROM dbo.Books WHERE ISBN LIKE'999%'查询,选择具有这种前缀的所有行。
如果检查查询的执行计划(如图3-7所示),您将看到非聚集索引查找和键查找操作,即使它们在您需要从表中选择近20%的行的情况下效率低下。
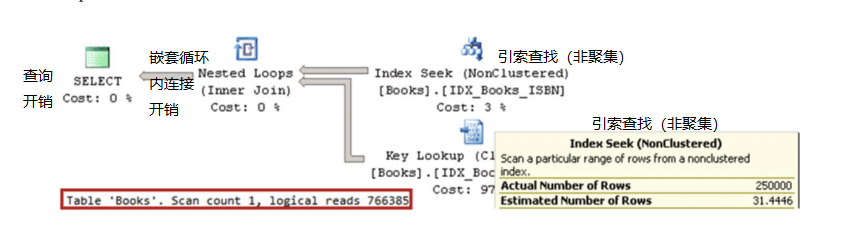
图3-7。 查询的执行计划选择具有999前缀的行
您还将在图3-7中注意到,Index Seek运算符的估计行数和实际行数之间存在巨大差异。 SQL Server估计表中只有31.4行,前缀为999,尽管有250,000行具有这样的前缀。结果,产生了非常低效的计划。
让我们通过运行DBCC SHOW_STATISTICS('dbo.Books',IDX_BOOKS_ISBN)命令来查看IDX_BOOKS_ISBN统计信息。 输出如图3-8所示。正如您所看到的,即使我们在表中插入了250,000行,统计信息也未更新,并且直方图中没有前缀999的数据。第一个结果集中的行数对应于上次统计信息更新期间表中的行数。 它不包括刚刚插入的250,000行。
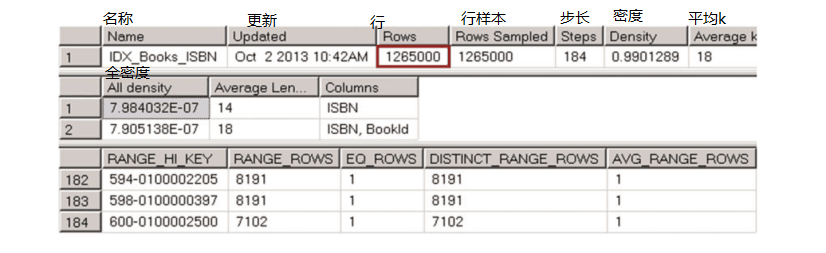
图3-8. IDX_BOOKS_ISBN统计数据
现在让我们使用UPDATE STATISTICS dbo.Books IDX_Books_ISBN WITH FULLSCAN命令更新统计信息,然后再次运行SELECT * FROM dbo.Books WHERE ISBN LIKE'990%'查询。查询的执行计划如图3-9所示。估计的行数现在是正确的,并且SQL Server最终得到了一个更有效的执行计划,该计划使用聚集索引扫描,I / O读取比以前少了大约17倍。

图3-9. 统计信息更新后查询选择具有999前缀的行的执行计划
如您所见,不正确的基数估计可能导致执行计划效率极低。 过时的统计数据可能是不正确基数估计的最常见原因之一。您可以通过检查执行计划中的估计和实际行数来查明其中一些情况。 这两个值之间的巨大差异通常表明统计数据不正确。更新统计信息可以解决此问题并生成更高效的执行计划。
68-69页
数据维护
正如我已经提到的,默认情况下SQL Server会自动更新统计信息。对于小的表,这种行为通常是可以接受的;但是,对于数百万或数十亿行的大型表,您不应该依赖自动统计更新,除非您使用数据库兼容性级别为130或启用跟踪标志T2371的SQL Server 2016。要通过20%的统计数据更新阈值触发统计数据更新,所需要的更改数量将非常高,因此,更新不会被频繁地触发。
建议在这种情况下手动更新统计信息。在选择最佳统计维护策略时,必须分析表的大小、数据修改模式和系统可用性。例如,如果系统在业务时间之外没有负载,您可以决定每晚更新关键表的统计信息。不要忘记,统计数据和/或索引维护会给SQL Server增加额外的负载。您必须分析它如何影响同一服务器和/或磁盘阵列上的其他数据库。
在设计统计维护策略时要考虑的另一个重要因素是如何修改数据。对于键值不断增加或减少的索引,您需要更频繁地更新统计信息,例如当索引中最左边的列被定义为identity或使用序列对象填充时。如您所见,如果特定键值位于直方图之外,SQL Server会大大低估行数。在SQL Server 2014到2016年间,这种行为可能有所不同,我们将在本章后面看到。
您可以使用update statistics命令更新统计信息。当SQL Server更新统计信息时,它读取数据的一个示例,而不是扫描整个索引。您可以通过使用FULLSCAN选项来更改这种行为,该选项强制SQL Server读取和分析来自索引的所有数据。正如您可能猜到的那样,该选项提供了最准确的结果,尽管在大型表的情况下,它可能引入大量I/O活动。
注意,SQL Server在重新构建索引时更新统计信息。我们将在第6章“索引碎片”中更详细地讨论索引维护。
可以使用sp_updatestats系统存储过程更新数据库中的所有统计信息。建议您使用此存储过程,并在将其升级到新版本的SQL Server后更新数据库中的所有统计信息。您应该与DBCC UPDATEUSAGE存储过程一起运行它,该存储过程将纠正目录视图中不正确的页计数和行计数信息。
系统dm_db_stats_properties DMV显示自上次统计数据更新以来对统计数据列所做的修改的数量。代码利用了DMV,如清单3-9所示。
清单3 - 9使用sys.dm_db_stats_properties
select
s.stats_id as [Stat ID], sc.name + '.' + t.name as [Table], s.name as [Statistics]
,p.last_updated, p.rows, p.rows_sampled, p.modification_counter as [Mod Count]
from
sys.stats s join sys.tables
查询结果如图3-11所示,表明自上次统计信息更新以来,对统计信息列进行了25万次修改。您可以构建一个定期检查sys的统计维护例程。使用大的modification_counter值重新构建统计信息。

图3-11.Sys.dm_db_stats_properties输出
另一个与统计信息相关的数据库选项是自动异步更新统计信息。默认情况下,当SQL Server检测到统计信息过时时,它会暂停查询执行,同步更新和统计信息,并在统计信息更新完成后生成新的执行计划。通过异步统计信息更新,SQL Server使用旧的执行计划执行查询,该执行计划基于过时的statist,同时在后台异步更新统计信息。建议您保持同步统计信息更新,除非系统有非常短的查询超时,在这种情况下,同步统计信息更新可以超时查询。
最后,在创建新索引时,SQL Server不会自动删除列级统计信息。您应该手动删除冗余的列级统计数据对象。
《Pro SQL Server Internals, 2nd edition》15w的更多相关文章
- 第十五周翻译-《Pro SQL Server Internals, 2nd edition》
<Pro SQL Server Internals, 2nd edition> 作者:Dmitri Korotkevitch 翻译:赖慧芳 译文: 55-58页 第三章 统计 SQL Se ...
- 第十四周翻译-《Pro SQL Server Internals, 2nd edition》
<Pro SQL Server Internals, 2nd edition> 作者:Dmitri Korotkevitch 翻译:赖慧芳 译文: 设计和优化索引 定义一种应用于所有地方的 ...
- 第十三周翻译-《Pro SQL Server Internals, 2nd edition》
<Pro SQL Server Internals, 2nd edition> 作者:Dmitri Korotkevitch 翻译:赖慧芳 译文: 聚集索引 聚集索引指示表中数据的物理顺序 ...
- 第十二周翻译-《Pro SQL Server Internals, 2nd edition》
<Pro SQL Server Internals, 2nd edition> 作者:Dmitri Korotkevitch 翻译:赖慧芳 译文: 专业SQL服务器内部 了解在引擎盖下发生 ...
- 《Pro SQL Server Internals, 2nd edition》的CHAPTER 3 Statistics中的Introduction to SQL Server Statistics、Statistics and Execution Plans、Statistics Maintenance(译)
<Pro SQL Server Internals> 作者: Dmitri Korotkevitch 出版社: Apress出版年: 2016-12-29页数: 804定价: USD 59 ...
- 《Pro SQL Server Internals, 2nd edition》中CHAPTER 7 Designing and Tuning the Indexes中的Clustered Index Design Considerations一节(译)
<Pro SQL Server Internals> 作者: Dmitri Korotkevitch 出版社: Apress出版年: 2016-12-29页数: 804定价: USD 59 ...
- 《Pro SQL Server Internals, 2nd edition》的CHAPTER 2 Tables and Indexes中的Clustered Indexes一节(翻译)
<Pro SQL Server Internals> 作者: Dmitri Korotkevitch 出版社: Apress出版年: 2016-12-29页数: 804定价: USD 59 ...
- 《Pro SQL Server Internals, 2nd edition》
设计和优化索引 定义一种应用于所有地方的索引策略是不可能的.每个系统都是独特的,需要基于工作,业务需求和其他一些因素的自己的索引方法.然而,有几个设计的注意事项和指导方针可以被应用到每个系统. 在我们 ...
- 《Pro SQL Server Internals, 2nd edition》的CHAPTER 1 Data Storage Internals中的Data Pages and Data Rows(翻译)
数据页和数据行 数据库中的空间被划分为逻辑8KB的页面.这些页面是以0开始的连续编号,并且可以通过指定文件ID和页号来引用它们.页面编号都是连续的,这样当SQL Server增长数据库文件时,从文件中 ...
随机推荐
- 【ybt1252】走迷宫
(还是蛮经典的一道bfs) 显然算法bfs [传送门] 算法基本上算是bfs的模板了,(模板详见[新知识]队列&bfs[洛谷p1996约瑟夫问题&洛谷p1451求细胞数量]) #inc ...
- hadoop hdfs 数据迁移到其他集群
# hadoop fs -cat /srclist Warning: $HADOOP_HOME is deprecated. hdfs://sht-sgmhadoopcm-01:9011/jdk-6u ...
- PHP的openssl_encrypt方法的Java实现
<?php class OpenSSL3DES { /*密钥,22个字符*/ const KEY='09bd821d3e764f44899a9dc6'; /*向量,8个或10个字符*/ cons ...
- TCP三次握手的思考?
大家都知道TCP有三次握手的过程,今天我就仔细想了想为什么TCP要有三次握手 先贴一张三次握手的示意图,说明一点是在三次握手中A是在第二次握手后申请缓存资源,B是在第一次握手后申请. 其实这个问题就是 ...
- java前的部分了解(计算机小白)
一.加密 对称加密: des 3des AES rc4 (数据加密) 会话密钥 非对称加密(成对:公钥/私钥(一个加密一个解密)):RSA DSA 密钥交换 / 数字签名(用私钥加密摘要算法出的一串数 ...
- nginx+tomcat 分布时服务部署
一. 工具 nginx-1.8.0 apache-tomcat-6.0.33 二. 目标 实现高性能负载均衡的Tomcat集群: 三. 步骤 1.首先下载Nginx,要下载稳定 ...
- C++学习笔记:多态篇之虚析构函数
动态多态中存在的问题:可能会产生内存泄漏! 以下通过一个例子向大家说明问什么会产生内存泄漏: class Shape//形状类 { public: Shape(); virtual double ca ...
- Android 音视频深入 十六 FFmpeg 推流手机摄像头,实现直播 (附源码下载)
源码地址https://github.com/979451341/RtmpCamera/tree/master 配置RMTP服务器,虽然之前说了,这里就直接粘贴过来吧 1.配置RTMP服务器 这个我不 ...
- 【tomcat环境搭建】Linux和Windows下tomcat开机自启动设置
目前很多项目都部署在tomcat上,频繁操作中,每次启动或关闭tomcat都稍显麻烦,那如何设置tomcat的开机自启动? Linux下tomcat的开机自启动设置 网上主要有两种方式,一种是shel ...
- RockerMQ实战之快速入门
文章目录 RocketMQ 是什么 专业术语 Producer Producer Group Consumer Consumer Group Topic Message Tag Broker Name ...