【转】Python——读取html的table内容
Python——python读取html实战,作业7(python programming)

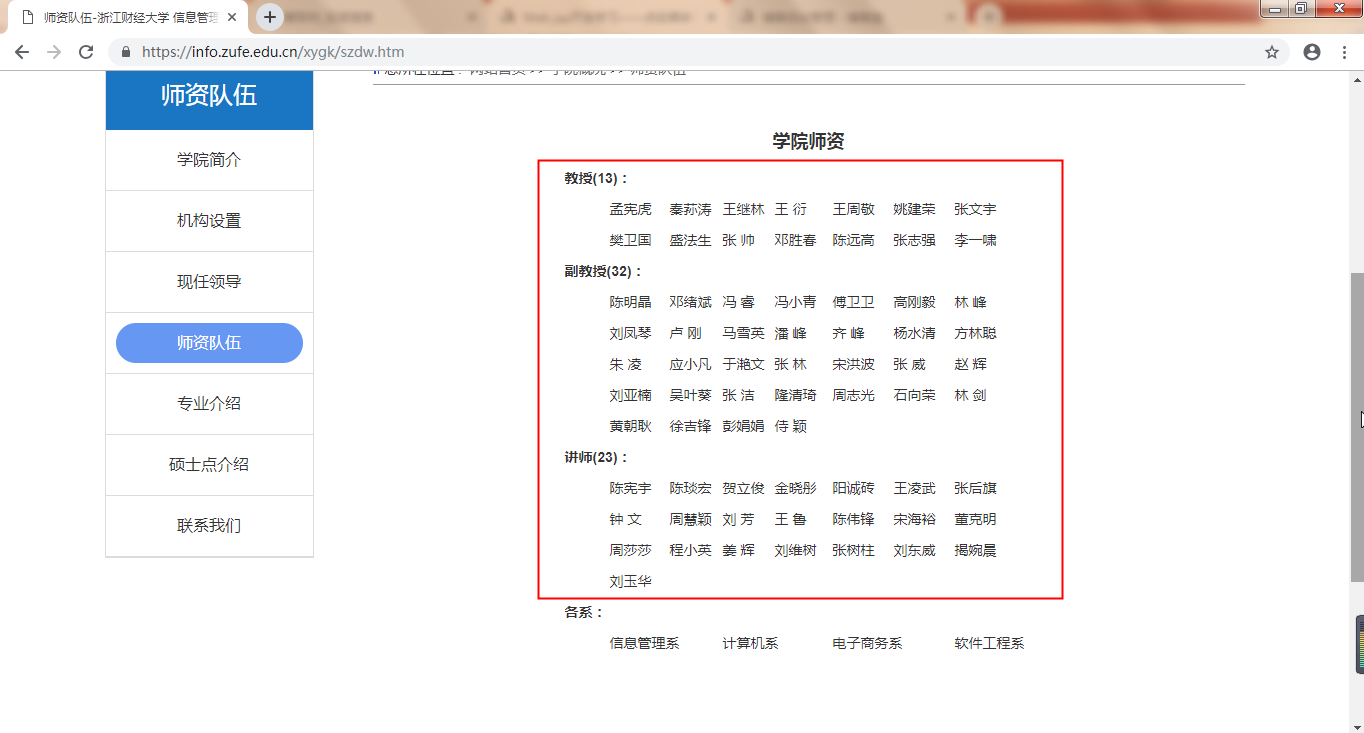
查看源码,观察html结构


# -*- coding: utf-8 -*-
from lxml.html import parse
from urllib.request import urlopen
import pandas as pd # 可能爬的这个网页比较特殊,需要写下面两句话
import ssl
ssl._create_default_https_context = ssl._create_unverified_context # 根据链接获得整个html放到doc中
parsed = parse(urlopen('https://info.zufe.edu.cn/xygk/szdw.htm'))
doc = parsed.getroot() #读取html中的table
# 用列表来存老师名字
all_teachers=[]
# 用字典保存主页链接
link_dic={}
# 用字典保存职称
zhicheng={} # 找到html中有<table></table>的所有table,以列表的形式返回给tables
tables = doc.findall('.//table')
# 我们要的是第一个table
content=tables[0].text_content()
tds = tables[0].findall('.//td') # 一条条遍历所有td里的内容
for td in tds:
# 判断当前属于哪个职称,再给zc赋值
zhi=td.findall('.//strong')
if len(zhi)!=0:
print(zhi[0].text_content())
zc=zhi[0].text_content() print(td.text_content())
link=td.findall('.//a')
if len(link)!=0:
print("link",link[0].get('href'))
# td.text_content()存的就是姓名
# 保存链接
link_dic[td.text_content()]=link[0].get('href')
# 保存老师姓名
all_teachers.append(str(td.text_content()))
# 保存职称
zhicheng[td.text_content()]=zc print("张 帅的主页链接是:",link_dic["张 帅"])
print("张 帅的职称链接是:",zhicheng["张 帅"]) # 后面的各系不属于老师去掉
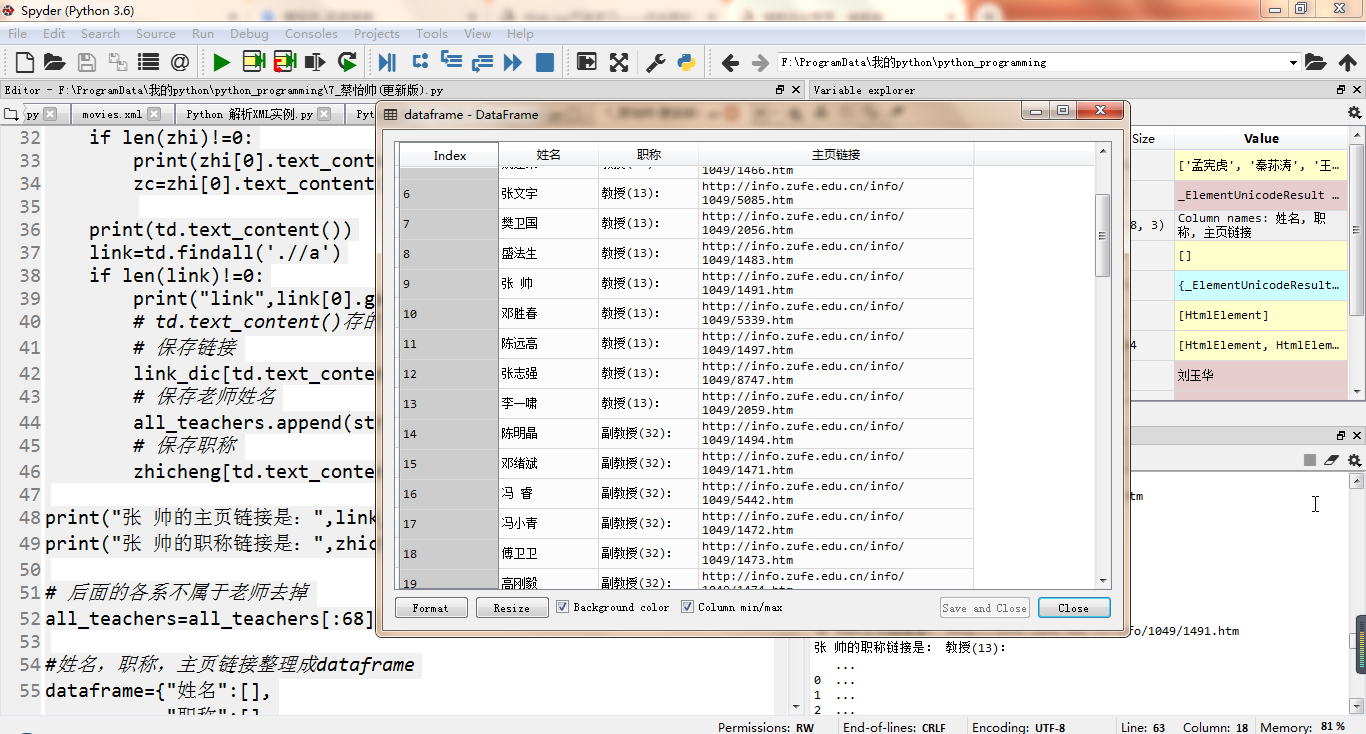
all_teachers=all_teachers[:68] #姓名,职称,主页链接整理成dataframe
dataframe={"姓名":[],
"职称":[],
"主页链接":[]}
for teacher in all_teachers:
dataframe["姓名"].append(teacher)
dataframe["职称"].append(zhicheng[teacher])
dataframe["主页链接"].append(link_dic[teacher])
dataframe=pd.DataFrame(dataframe)
print(dataframe)

【转】Python——读取html的table内容的更多相关文章
- Python读取文件编码及内容
Python读取文件编码及内容 最近做一个项目,需要读取文件内容,但是文件的编码方式有可能都不一样.有的使用GBK,有的使用UTF8.所以在不正确读取的时候会出现如下错误: UnicodeDecode ...
- python读取文件指定行内容
python读取文件指定行内容 import linecache text=linecache.getline(r'C:\Users\Administrator\Desktop\SourceCodeo ...
- Python读取word文档内容
1,利用python读取纯文字的word文档,读取段落和段落里的文字. 先读取段落,代码如下: 1 ''' 2 #利用python读取word文档,先读取段落 3 ''' 4 #导入所需库 5 fro ...
- python 读取指定div的内容
# -*- coding:utf-8 -*- from bs4 import BeautifulSoup import urllib.request import re # 如果是网址,可以用这个办法 ...
- Python读取本地文档内容并发送邮件
当需要将本地某个路径下的文档内容读取后并作为邮件正文发送的时候可以参考该文,使用到的模块包括smtplib,email. #! /usr/bin/env python3 # -*- coding:ut ...
- Python 读取文件下所有内容、获取文件名、截取字符、写回文件
# coding=gbk import os import os.path #读取目录下的所有文件,包括嵌套的文件夹 def GetFileList(dir, fileList): newDir ...
- python读取指定内存的内容
import ctypes as ct t = ct.string_at(0x211000, 20) # (addr, size) print t 最好不要用解释性语言来开发底层,一般用C.
- Python读取文件内容与存储
Python读取与存储文件内容 一..csv文件 读取: import pandas as pd souce_data = pd.read_csv(File_Path) 其中File_path是文件的 ...
- python读取excel中单元格的内容返回的5种类型
(1) 读取单个sheetname的内容. 此部分转自:https://www.cnblogs.com/xxiong1031/p/7069006.html python读取excel中单元格的内容返回 ...
随机推荐
- mysql主主配置
数据安装完成后 配置信息 开启二进制文件复制 [client]port=3306[mysqld]basedir=/usr/local/mysqldatadir=/usr/local/mysql/da ...
- idea 连接redis 出现 Caused by: java.net.SocketTimeoutException: connect timed out
Exception in thread "main" redis.clients.jedis.exceptions.JedisConnectionException: java.n ...
- mysql-SELECT子句的顺序
- 存储类&作用域&生命周期&链接属性
链接属性 (1)大家知道程序从源代码到最终可执行程序,经历的过程:编译.链接. (2)编译阶段就是把源代码搞成.o目标文件,目标文件里面有很多符号和代码段.数据段.bss段等分段.符号就是编程中的变量 ...
- 【Spring】Spring随笔索引
Spring随笔索引 [Spring]Spring bean的实例化 [Spring]手写Spring MVC [Spring]Spring Data JPA
- 不转实体直接获取Json字符串中某个字段的值
JObject jo = (JObject)JsonConvert.DeserializeObject(JsonStr);//JsonStr 为Json字符串 string lng = jo[&quo ...
- CTF--web 攻防世界web题 get_post
攻防世界web题 get_post https://adworld.xctf.org.cn/task/answer?type=web&number=3&grade=0&id=5 ...
- DirectX11--深入理解与使用2D纹理资源
前言 写教程到现在,我发现有关纹理资源的一些解说和应用都写的太过分散,导致连我自己找起来都不方便.现在决定把这部分的内容整合起来,尽可能做到一篇搞定所有2D纹理相关的内容,其中包括: DDSTextu ...
- [Android] Android 最全 Intent 传递数据姿势
我们都是用过 Intent,用它来在组件之间传递数据,所以说 Intent 是组件之间通信的使者,一般情况下,我们传递的都是一些比较简单的数据,并且都是基本的数据类型,写法也比较简单,今天我在这里说的 ...
- 【bzoj 2159】Crash 的文明世界
Description Crash小朋友最近迷上了一款游戏——文明5(Civilization V).在这个游戏中,玩家可以建立和发展自己的国家,通过外交和别的国家交流,或是通过战争征服别的国家.现在 ...