ES 01 - Elasticsearch入门 + 基础概念学习
1 Elasticsearch概述
1.1 Elasticsearch是什么
Elasticsearch(ES)是一个基于Apache的开源索引库Lucene而构建的 开源、分布式、具有RESTful接口的全文搜索引擎, 还是一个 分布式文档数据库.
ES可以轻松扩展数以百计的服务器(水平扩展), 用于存储和处理数据. 它可以在很短的时间内存储、搜索和分析海量数据, 通常被作为复杂搜索场景下的核心引擎.
由于Lucene提供的API操作起来非常繁琐, 需要编写大量的代码, Elasticsearch对Lucene进行了封装与优化, 并提供了REST风格的操作接口, 开箱即用, 很大程度上方便了开发人员的使用.
关于全文检索与Lucene方面的简介, 请参照博主的博客: Lucene 01 - 初步认识全文检索和Lucene
1.2 Elasticsearch的优点
(1) 横向可扩展性: 作为大型分布式集群, 很容易就能扩展新的服务器到ES集群中; 也可运行在单机上作为轻量级搜索引擎使用.
(2) 更丰富的功能: 与传统关系型数据库相比, ES提供了全文检索、同义词处理、相关度排名、复杂数据分析、海量数据的近实时处理等功能.
(3) 分片机制提供更好地分布性: 同一个索引被分为多个分片(Shard), 利用分而治之的思想提升处理效率.
(4) 高可用: 提供副本(Replica)机制, 一个分片可以设置多个副本, 即使在某些服务器宕机后, 集群仍能正常工作.
(5) 开箱即用: 提供简单易用的API, 服务的搭建、部署和使用都很容易操作.
1.3 Elasticsearch的相关产品
(1) Beats: 是一个代理, 将不同类型的数据发送到Elasticsearch中.
(2) Shield: 提供基于角色的访问控制与审计, 加密通信、认证保护整个ES的数据, 为ES带来企业级的安全性 --- 收费产品.
(3) Watcher: 是ES的警报和通知工具, 检测ES的状态, 在异常发生时进行提醒 --- 收费产品.
(4) Marvel: 是ES的管理和监控工具, 检测ES集群的索引和节点的活动 --- 收费产品.
1.4 Elasticsearch的使用场景
(1) 维基百科(类似百度百科): 全文检索, 高亮, 搜索推荐;
(2) The Guardian(新闻网站): 用户行为日志(点击, 浏览, 收藏, 评论) + 社交网络数据(对某某新闻的相关看法), 数据分析(将公众对文章的反馈提交至文章作者);
(3) Stack Overflow(IT技术论坛): 全文检索, 搜索相关问题和答案;
(4) GitHub(开源代码管理), 搜索管理其托管的上千亿行代码;
(5) 日志数据分析: ELK技术栈(Elasticsearch + Logstash + Kibana)对日志数据进行采集&分析;
(6) 商品价格监控网站: 用户设定某商品的价格阈值, 当价格低于该阈值时, 向用户推送降价消息;
(7) BI系统(Business Intelligence, 商业智能): 分析某区域最近3年的用户消费额的趋势、用户群体的组成结构等;
(8) 其他应用: 电商、招聘、门户等网站的内部搜索服务, IT系统(OA, CRM, ERP等)的内部搜索服务、数据分析(ES的又一热门使用场景).
2 Elasticsearch的功能概述
2.1 分布式的搜索引擎和数据分析引擎
(1) 搜索: 谷歌, 百度, 各大网站的站内搜索(如淘宝网的商品搜索), IT系统的检索(如OA内部的信息查询);
(2) 数据分析: 电商网站中, 对形如最近30天IT书籍销量排名前10的商家有哪些; 新闻网站中: 最近7天访问量排名Top 10的新闻是哪些......
—— 总结: Elasticsearch适用于 在较大用户量、较高访问量的分布式系统中, 对数据进行搜索与分析.
2.2 全文检索 结构化检索 数据分析
(1) 全文检索: 搜索商品名称包含"编程思想"的商品:
select * from products where product_name like "%编程思想%";
(2) 结构化检索: 搜索商品分类为"计算机科学"的所有商品:select * from products where category_name='计算机科学';
(3) 数据分析: 分析每一种商品分类下有多少件商品:select category_name, count(*) from products group by category_name;
(4) 其他个性化搜索需求: 部分匹配、自动完成(输入联想)、搜索纠错、搜索推荐......
2.3 海量数据的近实时处理
(1) 分布式: Elasticsearch可将海量数据自动分发到多台服务器上, 进行存储和检索;
(2) 海量数据的处理: 分布式系统构建完成后, 就可通过大规模服务器集群去存储和检索数据 —— 服务器有了处理海量数据的能力;
(3) 基于Elasticsearch的搜索和分析服务可达到秒级响应.
关于近实时:
非近实时: 检索x个数据要花费很长时间(这就不是近实时, 而是离线批处理, batch-processing).
实时: 数据的处理与响应都是立即呈现的, 几乎没有间隔, 这在大数据应用场景下是很难达到的要求.
近实时(near real-time, NRT): 对海量数据进行搜索和分析的响应耗时控制在秒级以内, 方可称为近实时.
3 Elasticsearch的架构
结合Elasticsearch架构图进行相关概念的介绍:

3.1 gateway - 门户、网关
ES索引的持久化存储方式, 也就是各类文件系统. 默认是先把索引存放到内存中, 当内存满了时再持久化到硬盘.
ES集群重新启动时就会从gateway中读取索引数据.
ES支持多种类型的gateway: 本地文件系统(默认), 分布式文件系统, Hadoop的HDFS, 以及Amazon的S3云存储服务等.
3.2 Lucene - 分布式Lucene目录
Gateway的上层是一个分布式的Lucene框架, Lucene之上是ES的模块, 包括:索引模块、搜索模块、映射解析模块等.
3.2 Discovery - 发现服务
Discovery是ES的节点发现模块, 要组成集群, 不同的节点之间就需要进行通信.
ES集群内部需要选举master节点, 这些工作都是由Discovery模块完成的.
ES支持多种发现机制, 如Zen(默认)、EC2、Gce、Azure等.
ES是一个基于p2p的系统: 先通过广播寻找存在的节点, 再通过多播协议进行节点之间的通信, 同时也支持点对点的交互.
5.x版本关闭了广播, 要开启就需要开发人员自定义.
3.3 Scripting - 脚本
ES支持在查询语句中插入JavaScript、Python等脚本 —— 由Scripting模块负责解析这些脚本.
使用脚本语句时查询性能可能会稍有降低.
3.4 3rd Plugins - 三方插件
ES对三方插件的支持非常友好, 因此其开源生态的构建也越发活跃、成熟.
3.5 Transport - 通信模块
ES内部节点或集群与客户端的交互方式, 节点间通信端口默认为:
9300 - 9400.
ES默认使用TCP协议进行交互, 同时也支持HTTP协议(JSON格式)、Thrift、Servlet、Memcached、ZeroMQ等的传输协议(通过插件方式集成).
3.6 JMX - Java管理框架
ES通过Java管理框架JMX来管理其应用.
3.7 RESTful style API - 与集群进行交互
ES最上层是提供给用户的接口, 可以通过RESTful接口与ES集群进行交互.
4 Elasticsearch索引相关概念
4.1 term(索引词)
在ES中, 索引词(term)是一个能够被索引的精确值, 可以通过
term query进行准确搜索. 比如: foo、Foo、FOO都是不同的索引词.
4.2 text(文本)
文本是一段普通的非结构化文字, 通常文本会被分析成多个Term, 存储在ES的索引库中.
文本字段一般需要先分析再存储, 查询文本中的关键词时, 需要根据搜索条件搜索出原文本.
4.3 analysis(分析)
分析是将文本转换为索引词的过程, 分析的结果依赖于分词器.
比如:FOO BAR、Foo-Bar和foo bar可能会被分析成相同的索引词foo和bar, 然后被存储到ES的索引库中. 当通过FoO:bAr进行全文搜索的时候, 搜索引擎根据匹配计算也能在索引库中查找到相关的内容.
4.4 cluster(集群)
集群由一至多个节点组成, 对外提供索引和搜索服务. 一个节点只能加入到一个集群中.
集群中有且只能有一个节点会被选举为主节点 —— 主从节点是集群内部的说法, 对用户是透明的; ES做到了去中心化: 访问任一节点等价于访问整个集群.
同一网络中, 每个ES集群都要有唯一的名称用于区分, 默认的集群名称为"elasticsearch".
水平扩展时, 只需要将新增节点的集群名称设置为要扩容的集群名称, 该节点就会自动加入集群中.
4.5 node(节点)
节点是逻辑上独立的服务, 是集群的一部分, 可以存储数据, 并参与集群的索引和检索功能.
节点也有唯一的名称, 用于集群的管理和通信, 节点名称在节点启动时自动分配一个随机的UUID的前7个字符 —— 当然可以自定义.
如果有多个节点在运行, 默认情况下, 这些节点会自动组成一个名为Elasticsearch的集群.
如果只有一个节点在运行, 该节点就会组成只有一个节点的名为Elasticsearch的集群.
每个节点属于哪个集群是通过"集群名称"来决定的.
4.6 shard(分片)
单台机器(节点)无法存储大量的索引数据, ES可以把一个完整的索引分成多个分片, 分布到不同的节点上, 从而构成分布式索引.
每个分片都是一个Lucene实例, 也就是说每个分片底层都有一个单独的Lucene提供独立的索引和检索服务, 它们可以托管在集群的任一节点上.
单个Lucene中存储的索引文档最大值为lucene-5843, 极限是2147483519(=integer.max_value - 128)个文档. 可使用_cat/shardsAPI 监控分片的大小.
(1) 分片的好处:
允许水平切分/扩展集群容量;
可在多个分片上进行分布式的、并行的操作, 提高系统的性能和吞吐量.
(2) 使用注意事项:
分片的数量只能在创建索引前指定, 创建索引后不能修改.
5.x 版本默认不能通过配置文件elasticsearch.yml定义分片个数.
4.7 replica(副本)
ES支持为每个Shard创建多个副本, 相当于索引数据的冗余备份.
分片有Primary Shard(主分片)、Replica Shard(副本分片), 建立索引时, 系统会先将索引存储在主分片中, 然后再将主分片中的索引复制到不同的副本中.
(1) 副本的重要性:
① 解决单点问题, 提高可用性和容错性: 某个节点失败时服务不受影响, 可以从副本中恢复;
② 提高查询效率和查询时的吞吐量: 搜索可以在所有的副本上并行执行, 提高了服务的并发量.
(2) 使用注意事项:
主分片在建立索引时设置, 后期不能修改;
主分片和副本分片不能存储在同一个节点中 —— 无法保证高可用.
5.x版本中, 默认主分片为5个, 默认副本分片数为1个, 即每个主分片各有1个副本分片(共5个副本分片); 可随时修改副本分片的数量.
默认情况下, 每个索引共有5 primary shard + 5 * 1 replica shard = 10 shard.
集群中至少要有2个节点, 这是最少的高可用配置.
4.8 river(数据源)
从其他存储方式 (如数据库) 中同步数据到ES的方法, 它是以插件方式存在的一个ES服务, 通过读取river中的数据并把它索引到ES中.
官方的river有CouchDB、RabbitMQ、Twitter、Wikipedia等.
4.9 index(索引)
索引是具有相似结构的文档的集合, 等同于Solr中的集合, 比如可以有一个商品分类索引, 订单索引.
每个索引都要有唯一的名称, 名称要小写, 通过索引名称来执行索引、搜索、更新和删除等操作.
一个集群中可以有任意多个索引, 只要保证名称不同即可.
4.10 type(类型)
type是index的逻辑分类, 在ES 6.x版本之前, 每个索引中可以定义一个或多个type, 而在6.X版本之后, 一个index中只能定义一个type.
一种type一般被定义为具有一组公共field的document, 比如对博客系统中的数据建立索引, 可以定义用户数据type, 博客数据type, 评论数据type, 也就是每个document都必须属于某一个具体的type, 也就是说每个document都有_type属性.
4.11 document(文档)
文档是存储在ES中的一个个JSON格式的字符串, 是ES索引中的最小数据单元, 由field(字段)构成.
一个document可以是一条商品分类数据, 一条订单数据, 例如:# book document
{
"book_id": "1",
"book_name": "Thinking in Java(Java 编程思想)",
"book_desc": "Java学习者不得不看的经典书籍",
"book_price": 108.00,
"category_id": "5"
}
4.12 mapping(映射)
类似于关系数据库中的Table结构, 每个index都有一个映射: 定义索引中每个字段的类型.
所有文档在写进索引之前都会先进行分析, 如何对文本进行分词、哪些词条又会被过滤, 这类行为叫做映射(mapping).
映射可以提前定义, 也可以在第一次存储文档时自动识别. 一般由用户自己定义规则.
类似于Solr中schema.xml约束文件的作用.
4.13 field(字段)
字段可以是一个简单的值(如字符串、数字、日期), 也可以是一个数组, 还可以嵌套一个对象或多个对象.
字段类似于关系数据库中表数据的列, 每个字段都对应一个类型.
可以指定如何分析某一字段的值, 即对field指定分词器.
ES的索引中, 各概念的关系为: Field --> Document --> Type --> Index, 索引结构图如下:
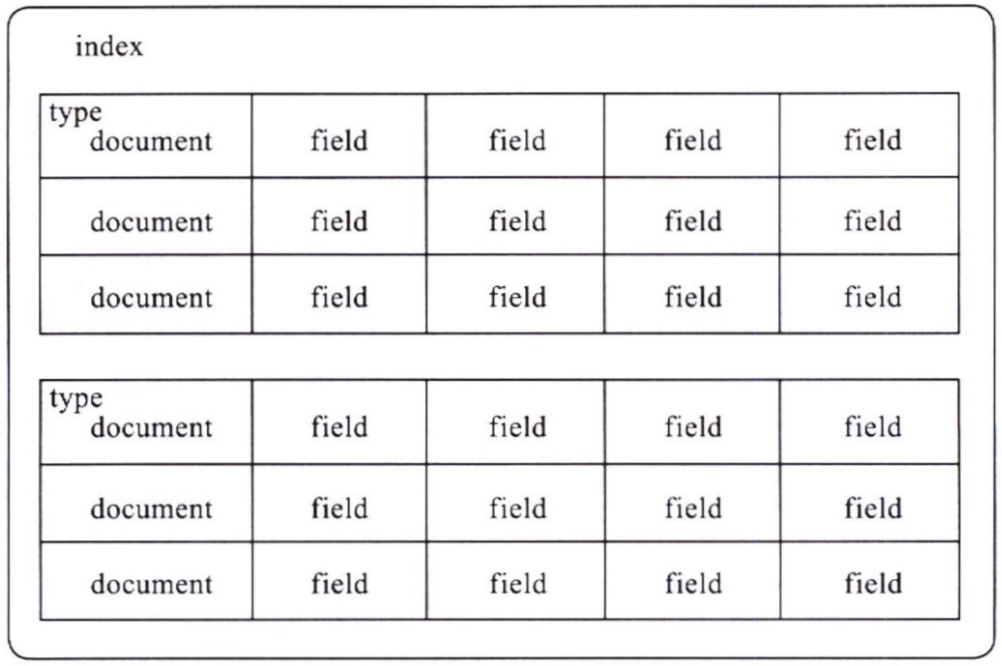
与关系型数据库的对比:
| Elasticsearch | RDBMS |
|---|---|
| Index(索引) | DataBase(数据库) |
| Type(类型) | Table(表) |
| Document(文档) | Row(行) |
| Field(字段) | Column(列) |
| Mapping(映射) | Schema(约束) |
| Everything is indexed(存储的都是索引) | Index(索引) |
| Query DSL(ES独特的查询语言) | SQL(结构化查询语言) |
4.14 recovery(数据恢复)
又叫数据重新分布: 当有节点加入或退出时, ES会根据机器的负载对索引分片进行重新分配, 挂掉的节点重新启动时也会进行数据恢复.
Kibana工具中通过GET _cat/health?v, 就可以看到集群所处的状态.
参考资料
《Elasticsearch技术解析与实战》朱林 编著, 机械工业出版社出版
版权声明
出处: 博客园 马瘦风的博客(https://www.cnblogs.com/shoufeng)
感谢阅读, 如果文章有帮助或启发到你, 点个[好文要顶
ES 01 - Elasticsearch入门 + 基础概念学习的更多相关文章
- Elasticsearch入门 + 基础概念学习
原文地址:https://www.cnblogs.com/shoufeng/p/9887327.html 目录 1 Elasticsearch概述 1.1 Elasticsearch是什么 1.2 E ...
- Elasticsearch入门基础(1)
基础概念 Elasticsearch有几个核心概念.从一开始理解这些概念会对整个学习过程有莫大的帮助. 接近实时(NRT) Elasticsearch是一个接近实时的搜索平台.这意味着 ...
- ES.01.Elasticsearch安装配置
Windows版 提纲: 1. 安装Elasticsearch 1.1. 下载Elasticsearch: https://www.elastic.co/cn/downloads/elastics ...
- # 095 01 Android 零基础入门 02 Java面向对象 02 Java封装 01 封装的实现 03 # 088 01 Android 零基础入门 02 Java面向对象 02 Java封装 03 封装总结 01 封装知识点总结
095 01 Android 零基础入门 02 Java面向对象 02 Java封装 01 封装的实现 03 # 088 01 Android 零基础入门 02 Java面向对象 02 Java封装 ...
- 094 01 Android 零基础入门 02 Java面向对象 02 Java封装 01 封装的实现 03 # 088 01 Android 零基础入门 02 Java面向对象 02 Java封装 02 static关键字 04 static关键字(续)
094 01 Android 零基础入门 02 Java面向对象 02 Java封装 01 封装的实现 03 # 088 01 Android 零基础入门 02 Java面向对象 02 Java封装 ...
- 093 01 Android 零基础入门 02 Java面向对象 02 Java封装 01 封装的实现 03 # 088 01 Android 零基础入门 02 Java面向对象 02 Java封装 02 static关键字 03 static关键字(下)
093 01 Android 零基础入门 02 Java面向对象 02 Java封装 01 封装的实现 03 # 088 01 Android 零基础入门 02 Java面向对象 02 Java封装 ...
- 092 01 Android 零基础入门 02 Java面向对象 02 Java封装 01 封装的实现 03 # 088 01 Android 零基础入门 02 Java面向对象 02 Java封装 02 static关键字 02 static关键字(中)
092 01 Android 零基础入门 02 Java面向对象 02 Java封装 01 封装的实现 03 # 088 01 Android 零基础入门 02 Java面向对象 02 Java封装 ...
- 091 01 Android 零基础入门 02 Java面向对象 02 Java封装 01 封装的实现 03 # 088 01 Android 零基础入门 02 Java面向对象 02 Java封装 02 static关键字 01 static关键字(上)
091 01 Android 零基础入门 02 Java面向对象 02 Java封装 01 封装的实现 03 # 088 01 Android 零基础入门 02 Java面向对象 02 Java封装 ...
- 090 01 Android 零基础入门 02 Java面向对象 02 Java封装 01 封装的实现 03 # 088 01 Android 零基础入门 02 Java面向对象 02 Java封装 01 封装的实现 04 使用包进行类管理(2)——导入包
090 01 Android 零基础入门 02 Java面向对象 02 Java封装 01 封装的实现 03 # 088 01 Android 零基础入门 02 Java面向对象 02 Java封装 ...
随机推荐
- Linux学习之文件系统权限及表示
三类人 用户主(user:u):文件的所有者 同组人(group:g):与文件主同组的用户 其他人(other:o):除用户主和同组人外的其他所有人 三种权限 读权限(r):指用户对文件或目录的读许可 ...
- Git 如何解决部署远程仓库出现 fatal: refusing to merge unrelated histories 问题
想把本地仓库的文件搬到Github,先将远程仓库和本地仓库关联起来: 先到Github上复制远程仓库的SSH地址: 运行 git remote add origin 你复制的地址 理论上—如果在创建 ...
- STM8L052低功耗模式
Stm8L系列单片机的低功耗有五种模式: § wait模式 § Lowpower run模式 § Lowpower wait模式 § Active-haltwith full RTC模式 § Halt ...
- 将Redhat,CentOS,Ubuntu虚拟机的IP设为静态IP的方法
一般在主机上创建的虚拟机默认是通过DHCP(Dynamic Host Configuration Protocol,动态主机配置协议)网络协议来动态生成的,这样会导致你安装的虚拟机的IP地址是动态变化 ...
- jQuery实现节点克隆
为了便于在DOM节点进行添加或者删除节点元素,使用克隆的方法比较方便,下面是js部分的主要代码 var container = $('.recordCon'); var cloneDom = cont ...
- webpack学习--安装
webpack需要在node环境运行,可以去node官网进行下载安装包:http://nodejs.cn/download/ 1.打开cmd命令窗口,运行node -v 2.全局安装webpack:n ...
- 百度网盘免VIP全速下载!
不知道大家在用百度网盘下载文件时会不会遇到这样一个问题: 过分! 太过分了! 100M的宽带你就给我限速到20KB/s... 当然 解决办法有很多 1.充钱(这辈子都不可能的) ······ 百度上有 ...
- SpringBoot 中 @RestController 和 @Controller 的区别
1 - 在springboot中,@RestController 相当于 @Controller + @ResponseBody;2 - 即在Controller类中,若想返回jsp或html页面,则 ...
- 约瑟夫环问题 --链表 C语言
总共有m个人在圆桌上,依次报名,数到第n个数的人退出圆桌,下一个由退出人下一个开始继续报名,循环直到最后一个停止将编号输出 #include <stdio.h>#include <s ...
- 开发自定义ScriptableRenderPipeline,将DrawCall降低180倍
0x00 前言 大家都知道,Unity在2018版本中正式推出了Scriptable Render Pipeline.我们既可以通过Package Manager下载使用Unity预先创建好的Ligh ...