Python第三天 序列 5种数据类型 数值 字符串 列表 元组 字典 各种数据类型的的xx重写xx表达式
Python第三天 序列 5种数据类型 数值 字符串 列表 元组 字典 各种数据类型的的xx重写xx表达式
目录
Python第二天 变量 运算符与表达式 input()与raw_input()区别 字符编码 python转义符 字符串格式化
Python第三天 序列 5种数据类型 数值 字符串 列表 元组 字典
Python第四天 流程控制 if else条件判断 for循环 while循环
Python第五天 文件访问 for循环访问文件 while循环访问文件 字符串的startswith函数和split函数
Python第七天 函数 函数参数 函数变量 函数返回值 多类型传值 冗余参数 函数递归调用 匿名函数 内置函数 列表表达式/列表重写
Python第八天 模块 包 全局变量和内置变量__name__ Python path
Python第九天 面向对象 类定义 类的属性 类的方法 内部类 垃圾回收机制 类的继承 装饰器
Python第十天 print >> f,和fd.write()的区别 stdout的buffer 标准输入 标准输出 标准错误 重定向 输出流和输入流
Python第十二天 收集主机信息 正则表达式 无名分组 有名分组
Python第十四天 序列化 pickle模块 cPickle模块 JSON模块 API的两种格式
Python第十五天 datetime模块 time模块 thread模块 threading模块 Queue队列模块 multiprocessing模块 paramiko模块 fabric模块
5种数据类型
数值
字符串 (序列)
列表(序列 可迭代对象)
元组(序列 可迭代对象)
字典(可迭代对象)
序列
序列:字符串、列表、元组
序列的两个主要特点是索引操作符和切片操作符
- 索引操作符让我们可以从序列中抓取一个特定项目
- 切片操作符让我们能够获取序列的一个切片,即一部分序列,切片操作实际会重新生成一个对象,切片操作相当于浅拷贝,切片后的值赋值给新变量跟原来的变量地址不同

序列的基本操作
1. len(): 求序列的长度
2. +: 连接2个序列
3. *: 重复序列元素
4. in/not in: 判断元素是否在序列中
5. max(): 返回最大值
6. min(): 返回最小值
7. sum(): 返回求和
8. cmp(x, y):比较两个序列是否相等 返回值大于0 ,等于0,小于0
cmp:按照字符串比较,字符串比较的原则就是一个字符一个字符的比较,字符按照ASCII码来比较,字符1比字符2小,所以gene1001小于gene2
------------------------------------------------------------
数值类型
- 整型 2^32个数字,范围-2,147,483,648到2147483647
- 长整型 区分普通整型,需要在整数后加L或l。2345L,0x34al
- 浮点型 0.0,12.0,-18.8,3e+7
- 复数型 - 3.14j,8.32e-36j
-------------------------------------------------------------
字符串''类型
字符串是不可变数据类型
有三种方法定义字符串类型
str = 'this is a string'
str = "this is a string"
str = '''this is a string''' 或 """this is a string"""
三重引号(docstring)除了能定义字符串还可以用作注释
python里面单引号和双引号没有任何区别,而三引号可以转义,单引号和双引号不能转义
\n:换行
str = "this is a \nstring"
字符串前加 u
例:u"我是含有中文字符组成的字符串。"
作用:后面字符串以 Unicode 格式 进行编码,一般用在中文字符串前面,防止因为源码储存格式问题,导致再次使用时出现乱码。
python3.x里,默认的str是(py2.x里的)unicode,u前缀没什么具体意义,(py3不用u)
字符串前加 b
例: b'\r\n'
作用:python3.x里默认bytes是(py2.x)的str, b""前缀代表的就是bytes
python2.x里, b前缀没什么具体意义(py2不用b)
Python 3 有两种表示字符序列的类型,分别是bytes 和str。前者的实例包含原始的8位值, 后者的实例包含Unicode字符。
Python 2 也有两种表示字符序列的类型,分别叫作str 和Unicode 。与Python 3 不同的是, str 的实例包含原始的8位值(utf8,utf16等等),而Unicode 的实例包含Unicode 字符。
也就是说,在Python 3 中,字符串默认为Unicode 。但如果在Python 2中需要使用Unicode ,则必须在字符串前面显示地加上一个“ u ”前缀
字符串索引
字符串是序列,可以通过索引取每个字符
加号 :字符串连接符
str = 'abcde'
str[0] + str[1]
字符串切片
str[start:end:step]
step:为负数表示从右向左,步长为正数,start那个数字的值不要,步长为负数,end那个数字的值不要
>>> str[1:3]
'bc'
>>> str[:3]
'abc'
>>> str[3:]
'de'
>>> str[::1]
'abcde'
>>> str[::2]
'ace'
>>> str[-1]
'e'
>>> str[-4:-1]
'bcd'
>>> str[-2:-4:-1]
'dc'
字符串相关函数
replace()
split()
join()
strip()
format() :'{0},I\'m {1},my E-mail is {2}'.format('Hello','Hongten','hongtenzone@foxmail.com')
find()
import string
string.digits:返回数字0123456789
大小写相关方法
upper :将字符串转换为大写
lower :将字符串转换为小写
isupper :判断字符串是否都为大写
islower :判断字符串是否都为小写
swapcase :将字符串中的大写转换为小写、小写转换为大写
capitalize :将首字母转换为大写
istitle :判断字符串是不是一个标题
注意:字符串是不可变的,因此,这里的方法并没有改变原来的字符串, 而是产生了一个新的字符串。
如果需要修改字符串,则可以将修改过后的字符串赋值给原来的变量。
判断类方法
s.isalpha :如果字符串只包含字母,并且非空, 则返回True , 否则返回False
s.isalnum :如果字符串值包含字母和数字,并且非空, 则返回True ,否则返回False
s.isspace :如果字符串值包含空格、制表符、换行符,并且非空,则返回True ,否则返回False
s.isdecimal :如果字符串只包含数字字符,并且非空, 则返回True , 否则返回False
s.isdigit:如果字符串是数字,并且非空,, 则返回True , 否则返回False
startwith :是否为字符串的前缀或后缀
endswith:是否为字符串的前缀或后缀
查找类函数
它们之间的区别可能是查找的方向不同,也可能是以不同的方式处理异常情况
find :查找子串出现在字符串中的位置,如果查找失败,返回-1,也可以指定查找开始的下标,从第19个字符开始查找s.find('IN',19),可以用in代替
index : 与find 函数类似,如果查找失败,抛出ValueError 异常
rfind : 与find 函数类似,区别在于rfind 是从后向前查找
rindex :与index 函数类似,区别在于rindex 是从后向前查找
拼接和分割
join
split
去除空白字符
strip :给strip 函数传递参数,参数中的所有字符都可以被裁剪
rstrip
lstrip
s ="##Hello, world## "
s.strip("#")
"Hello, world"
替换
replace
---------------------------------------------------------------------------
元组()类型
元组和列表十分相似
元组和字符串一样是不可变的,不可变的意思是元组里面的元素不能修改,比如a[-1] = xx 会报错
- 元组可以存储一系列的值
- 元组通常用在用户定义的函数能够安全地采用一组值的时候,即被使用的元组的值不会改变。
创建元组
t= ()
t= (2,) 一定要加逗号才是元组,否则会当普通字符串对待
t = ('james', 'M')
t = ('james', 'M',(1,)) 元组里面包含元组
j = 'sd'
t = (j, 'M') 包含变量
print t
('sd', 'M')
print t[0] 返回第一个元素
元组操作
- 元组和字符串一样属于序列类型,可以通过索引和切片操作
- 元组值不可变
元组的拆分
t = (1,2,3) a, b, c = t a 1 b 2 c 3
M=2
t = ('james', M,'gg','cc')
for a in t:
print a
james
2
gg
cc
b=('a','b','a','d','a')
print(b.count('a')) 统计'a'这个元素一共有多少个
---------------------------------------------------
列表[]类型
列表(list)是处理一组有序项目的数据结构,即可以在列表中存储一个序列的项目。
列表是可变类型的数据类型
创建列表
list1 = []
list2 = list() list()函数
list3 = ['a',1,2]
list4 = ['a',1,(1,),['sdf','sww]]
对某项目赋值,下标从0开始
list3[0] = 'b'
列表操作
- 取值
切片和索引
切片 l = list(range(10)) l [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] l[5:0:-1] 输出:[5, 4, 3, 2, 1] l[5:4:-1] 输出:[5] l[:3:-1] 输出:[9, 8, 7, 6, 5, 4] l[0:3:-1] 输出:[] l[9::-1] 输出:[9, 8, 7, 6, 5, 4, 3, 2, 1, 0] l[-2:]( l[-2:10:1]) 输出:[8, 9] l[2:]( l[2:10:1]) 输出:[2, 3, 4, 5, 6, 7, 8, 9] l[:-2]( l[0:-2:1]) 输出:[0, 1, 2, 3, 4, 5, 6, 7] l[0] 输出:0 l[列表最小值:列表最大值:步进] 步长为正数情况下输出不包含列表最大值 列表最小值下标从0开始 -1:9 -2:8
- 添加
list.append()
list1[2].append('abc') 如果列表里面又有列表使用下标来访问
添加 list= list +[6] ,list2 =[1,2] list = list + list2
- 删除
del list[x] 删除某个元素 del list 删除整个列表
list.remove(列表里面实际的值)
- 修改
list[] = x
- 查找
var in list
- 插入
list.insert(list[x],object) 在下标前插入一个对象
- 排序
list.sort()
- 反转
list.reverse()
- 弹出
list.pop([index]) 返回一个元素并删除这个元素,参数是下标,没有参数会删除最后一个元素
- 扩展
list.extend(iterable) 可迭代的,相比append()方法可以追加多个值,l.extend(range(10))
- 统计
a = ['s','c','c']
a.count('c') 统计'c'这个元素一共有多少个
https://www.cnblogs.com/meitian/p/4649173.html
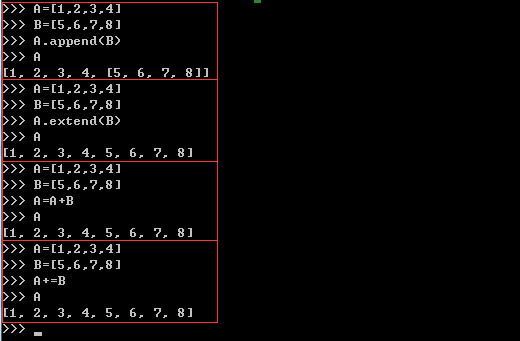
Python合并列表,append()、extend()、+、+=
1.append() 向列表尾部追加一个新元素,列表只占一个索引位,在原有列表上增加
2.extend() 向列表尾部追加一个列表,将列表中的每个元素都追加进来,在原有列表上增加
3.+ 直接用+号看上去与用extend()一样的效果,但是实际上是生成了一个新的列表存这两个列表的和,只能用在两个列表相加上
4.+= 效果与extend()一样,向原列表追加一个新元素,在原有列表上增加
---------------------------------------------------------
字典{}类型
字典是python中的唯一的映射类型(哈希表)
字典对象是可变的,但是字典的键必须使用不可变对象,一个字典中可以使用不同类型的键值。
跟redis的set类型一样,字典里的key不能重复,赋值的时候如果发现已有key则替换
访问字典的常用方法:
items() 返回一个元组列表,key和value在一个元组里
iteritems() 返回一个元组列表,类似items(),不过一次只返回一个值
iterkeys() 返回一个key迭代器,用for循环读取这个迭代器
itervalues() 返回一个value迭代器,用for循环读取这个迭代器
keys() 返回一个key的列表
values() 返回一个value的列表
创建字典
dic = {}
dic = dict()
dict()函数
help(dict)
字典创建
第一种
dict((['a',1],['b',2])) #dict()函数方式1
aa=dict((['a',1],['b',2]))
print aa
{'a': 1, 'b': 2}
第二种
dict(a=1, b=2) #dict()函数方式2
bb=dict(a=1, b=2)
print bb
{'a': 1, 'b': 2}
第三种
dd = {'line':1,'char':2,'word':3} 或dd = {1:1,2:2,3:3}
print dd
{'char': 2, 'line': 1, 'word': 3}
第四种
info = {} #创建一个空字典
info['name'] = 'name'
info['age'] = 'age'
info['gender'] = 'gender'
print info
{'gender': 'gender', 'age': 'age', 'name': 'name'}
fromkeys()函数
fromkeys(S[,v]) S指定一个序列,v指定value的值,默认为None。
dic.fromkeys(range(3),100)
In [4]: dic.fromkeys(range(3),100)
Out[4]: {0: 100, 1: 100, 2: 100}
fromkeys函数创建的字典需要赋值到另一个字典才能保存
ddict = {}.fromkeys(('x','y'), 100)
update()函数
将一个字典添加到另一个字典
dict1 = {'Name': 'Zara', 'Age': 7}
dict2 = {'Sex': 'female' }
dict1.update(dict2)
print "dict1 : %s" % dict1
get(key,default)函数
将代入key,返回value
dict1 = {'Name': 'Zara', 'Age': 7}
dict1.get('Age',‘111’) 如果没有age这个key,就返回111
print "dict1 : %s" % dict1 返回7
pop函数/del函数 删除字典里某个key值
dict1 = {'Name': 'Zara', 'Age': 7}
dict1.pop('Age')
print dict1
del dict1['Age']
print dict1
zip函数 dict函数 接受任意多个(包括0个和1个)序列作为参数,返回一个tuple列表
x = [1, 2, 3]
y = ['a', 'b', 'c']
xyz = zip(x, y,)
print xyz
print dict(xyz)
字典合并,重写,复制
字典合并,重写,复制
一个字典转储到一个新字典,相当于update()函数
dic = {'a': 1, 'b': 2, 'c': 3}
dic2 = {'e': "Python", 'f': 'everyday'}
all_dic = {**dic, **dic2}
all_dic
{'a': 1, 'b': 2, 'c': 3, 'e': 'Python', 'f': 'everyday'}
复制一个字典,同时添加一个新的值
add_dic = {**dic, 'g': 4}
add_dic
{'a': 1, 'b': 2, 'c': 3, 'g': 4}
复制/合并字典,同时重写特定的值
new_dic = {**dic, 'a': 111}
new_dic
{'a': 111, 'b': 2, 'c': 3}
https://mp.weixin.qq.com/s/_ThZ34hGtcOEqTeLgDO7bQ
访问字典
直接使用key访问:key不存在会报错,可以使用has_key()或者in和not in判断。
循环遍历 items() ,iteritems()函数
例:
for i in dic.keys():
for i in dic:
print i 读取的是key
print dic[i] 读取的是value
for i, o in dic.items():
print i, o
建议使用iteritems函数,items函数会一次性把字典的所有键值全部取出来,而iteritems函数只会一次取出一个
dict1 = {'Name': 'Zara', 'Age': 7}
for i, o in dict1.iteritems():
print i, o
#!/usr/bin/python
info = {} 创建一个空字典
name = raw_input("Please input name: ")
age = raw_input("Please input age: ")
gender = raw_input('Please input (M/F): ')
info['name'] = name
info['age'] = age
info['gender'] = gender
for k, v in info.items():
print "%s: %s" % (k, v)
print 'main end'
递归删除嵌套字典里某个key
https://stackoverflow.com/questions/45335445/recursively-replace-dictionary-values-with-matching-key
https://stackoverflow.com/questions/10179033/how-to-recursively-remove-certain-keys-from-a-multi-dimensionaldepth-not-known
def remove_keys(obj, rubbish):
if isinstance(obj, dict):
obj = {
key: remove_keys(value, rubbish)
for key, value in obj.iteritems()
if key not in rubbish}
return obj
dicttest = {", "msg": "设备设备序列号或验证码错误"}}
aa=remove_keys(dicttest,'msg')
print(aa)
设置嵌套字典某个key的value
dicccc['config']['settings']['getLastErrorDefaults']['wtimeout'] = 2000
dicccc= {u'ok': 1.0,
u'config':
{u'settings':
{u'getLastErrorDefaults':{u'wtimeout': 2000, u'w': u'majority'},
u'heartbeatIntervalMillis': 2000,
u'getLastErrorModes': {},
u'replicaSetId': 'xx',
u'heartbeatTimeoutSecs': 10,
u'chainingAllowed': True,
u'catchUpTakeoverDelayMillis': 30000,
u'catchUpTimeoutMillis': -1,
u'electionTimeoutMillis': 10000
},
u'version': 2,
u'members': [{u'votes': 1, u'tags': {}, u'arbiterOnly': False, u'slaveDelay': 0L, u'priority': 1.0, u'host': u'192.168.15.15:7666', u'buildIndexes': True, u'hidden': False, u'_id': 0}],
u'protocolVersion': 1L,
u'_id': u'rpl',
u'writeConcernMajorityJournalDefault': False
},
u'operationTime': 'xx',
u'$clusterTime': {
u'clusterTime': 'xx',
u'signature': {u'keyId': 6623797459808157697L,u'hash': 'xx'}
}
}
集合
sets模块
python2.6或以上已经默认导入sets模块,集合内部实现是一个hash表,set集合是通过hash算法实现的无序不重复元素集
set(iterable)类
参数:传入可迭代对象
set中的元素不能重复
集合添加
add:是把要传入的元素做为一个整个添加到集合中,例如:
>>> a = set('boy')
>>> a.add('python')
>>> a
set(['y', 'python', 'b', 'o'])
update:是把要传入的元素拆分,做为个体传入到集合中,例如:
>>> a = set('boy')
>>> a.update('python')
>>> a
set(['b', 'h', 'o', 'n', 'p', 't', 'y'])
集合删除
discard:元素不存在不会抛出异常
remove:元素不存在会抛出异常
set(['y', 'python', 'b', 'o'])
>>> a.remove('python')
>>> a
set(['y', 'b', 'o'])
集合清空
clear()
set(['y', 'python', 'b', 'o'])
>>> a.clear()
集合的运算
-或set.difference(s):差集
&或set.intersection(s):交集
|或set.union(s):并集、合集
!=:不等于
==:等于
in:成员关系
not in:不是成员关系
a=set('abc')
b=set('adcjj')
print a - b
set(['b'])
print a & b
set(['a', 'c'])
print a | b
set(['a', 'c', 'b', 'd', 'j'])
print a in b
False
print a != b
True
isdisjoint:判断没有交集,返回True,否则,返回False
li = {'s', 'd'}
name = {'sd', 'd', 's'}
name.isdisjoint(li)
issubset:判断是否是子集
li = {'s', 'd'}
name = {'sd', 'd', 's'}
name.issubset(li)
issuperset:判断是否是父集
li = {'s', 'd'}
name = {'sd', 'd', 's'}
name.issuperset(li)
不变集合
Python提供了不能改变元素的集合的实现版本,即不能增加或删除元素,类型名叫frozenset
>>> a = frozenset("hello")
>>> a
frozenset({'l', 'h', 'e', 'o'})
需要注意的是frozenset仍然可以进行集合操作,只是不能用带有update的方法。
如果要一个有frozenset中的所有元素的普通集合,只需把它当作参数传入集合的构造函数中即可:
>>> a = frozenset("hello")
>>> a = set(a)
>>> a.add(12)
>>> a
{'l', 12, 'h', 'e', 'o'}
set和list转换
list转set
m = ['] print set(m) # set(['11', '33', '44', '22'])
set转list
s = set(')
print list(s)
各种数据类型的xx重写,xx表达式,
列表,列表重写,列表表达式
[expr for iter_item in iterable if cond_expr]
b = ['A','B','C']
cc = [aa+'p' for aa in b]
print cc
元组(借用生成器表达式),元组重写,生成器表达式
(expr for iter_item in iterable if cond_expr)
b = ('A','B','C',)
cc = (aa+'p' for aa in b)
for i in cc:
print i
b = ('A', 'B', 'C',)
aa = (x for x in b)
print aa
<generator object <genexpr> at 0x00000000028F5E58>
集合set,集合重写,集合表达式
{expr for iter_item in iterable if cond_expr}
b = set('adcjj')
cc = {aa+'p' for aa in b}
print ccset(['ap', 'cp', 'jp', 'dp'])
字典,字典重写,字典表达式
{expr1,expr2 for iter_item in iterable if cond_expr}
f
Python第三天 序列 5种数据类型 数值 字符串 列表 元组 字典 各种数据类型的的xx重写xx表达式的更多相关文章
- Python第三天 序列 数据类型 数值 字符串 列表 元组 字典
Python第三天 序列 数据类型 数值 字符串 列表 元组 字典 数据类型数值字符串列表元组字典 序列序列:字符串.列表.元组序列的两个主要特点是索引操作符和切片操作符- 索引操作符让我 ...
- python字符串/列表/元组/字典之间的相互转换(5)
一.字符串str与列表list 1.字符串转列表 字符串转为列表list,可以使用str.split()方法,split方法是在字符串中对指定字符进行切片,并返回一个列表,示例代码如下: # !usr ...
- python字符串 列表 元组 字典相关操作函数总结
1.字符串操作函数 find 在字符串中查找子串,找到首次出现的位置,返回下标,找不到返回-1 rfind 从右边查找 join 连接字符串数组 replace 用指定内容替换指定内容,可以指定次数 ...
- Python数据类型-布尔/数字/字符串/列表/元组/字典/集合
代码 bol = True # 布尔 num = 100000000; # 数字 str = "fangbei"; # 字符串 str_cn = u"你好,方倍" ...
- Python自动化开发 - 字符串, 列表, 元组, 字典和和文件操作
一.字符串 特性:字符串本身不可修改,除非字符串变量重新赋值.Python3中所有字符串都是Unicode字符串,支持中文. >>> name = "Jonathan&q ...
- Python笔记【5】_字符串&列表&元组&字典之间转换学习
#!/usr/bin/env/python #-*-coding:utf-8-*- #Author:LingChongShi #查看源码Ctrl+左键 #数据类型之间的转换 Str='www.baid ...
- Python 整数 长整数 浮点数 字符串 列表 元组 字典的各种方法
对于Python, 一切事物都是对象,对象基于类创建!! 注:查看对象相关成员var,type, dir 一.整数 如: 18.73.84 每一个整数都具备如下需要知道的功能: def bit_len ...
- python 字符串,列表,元组,字典相互转换
1.字典 dict = {'name': 'Zara', 'age': 7, 'class': 'First'} 字典转为字符串,返回:<type 'str'> {'age': 7, 'n ...
- PYDay4-基本数据类型、字符串、元组、列表、字典
1.关于编码: utf-8 与gbk都是对Unicode 编码的简化,utf-8是针对所有语言的精简,gbk是针对中文的精简 py3默认字符集为UTF-8,取消了Unicode字符集,如后面的编程过程 ...
随机推荐
- [Swift]LeetCode406. 根据身高重建队列 | Queue Reconstruction by Height
Suppose you have a random list of people standing in a queue. Each person is described by a pair of ...
- [Swift]LeetCode353. 设计贪吃蛇游戏 $ Design Snake Game
Design a Snake game that is played on a device with screen size = width x height. Play the game onli ...
- Mysql优化之索引和字段
Mysql优化是一个老生常谈的问题, 优化的方向也优化很多:从架构层;从设计层;从存储层;从SQL语句层; 今天讲解一下从索引和字段: 字段优化: ① 尽量使用TINYINT.SMALLINT.ME ...
- Python—day18 dandom、shutil、shelve、系统标准流、logging
一.dandom模块 (0, 1) 小数:random.random() [1, 10] 整数:random.randint(1, 10) [1, 10) 整数:random.randrange(1, ...
- Docker系列教程02-MongoDB默认开启鉴权
说明,我这里使用的是compose的版本的1.17.0格式是3,但是这和compose版本无关,你只需要添加MONGO_INITDB_ROOT_USERNAME和MONGO_INITDB_ROOT_P ...
- [Abp 源码分析]十四、DTO 自动验证
0.简介 在平时开发 API 接口的时候需要对前端传入的参数进行校验之后才能进入业务逻辑进行处理,否则一旦前端传入一些非法/无效数据到 API 当中,轻则导致程序报错,重则导致整个业务流程出现问题. ...
- Python内置函数(46)——oct
英文文档: oct(x) Convert an integer number to an octal string. The result is a valid Python expression. ...
- Python内置函数(14)——delattr
英文文档: delattr(object, name) This is a relative of setattr(). The arguments are an object and a strin ...
- WebSocket(3)---实现一对一聊天功能
实现一对一聊天功能 功能介绍:实现A和B单独聊天功能,即A发消息给B只能B接收,同样B向A发消息只能A接收. 本篇博客是在上一遍基础上搭建,上一篇博客地址:[WebSocket]---实现游戏公告功能 ...
- SQLServer特殊字符/生僻字与varchar
对于中文版的SQL SERVER,默认安装后使用的默认排序规则为Chinese_PRC_CI_AS,在此排序规则下,使用varchar类型来可以“正常存取”存放中文字符以及一些东南亚国家的字符,同时v ...