LeetCode编程训练 - 合并查找(Union Find)
Union Find算法基础
Union Find算法用于处理集合的合并和查询问题,其定义了两个用于并查集的操作:
- Find: 确定元素属于哪一个子集,或判断两个元素是否属于同一子集
- Union: 将两个子集合并为一个子集
并查集是一种树形的数据结构,其可用数组或unordered_map表示:

Find操作即查找元素的root,当两元素root相同时判定他们属于同一个子集;Union操作即通过修改元素的root(或修改parent)合并子集,下面两个图展示了id[6]由6修改为9的变化:
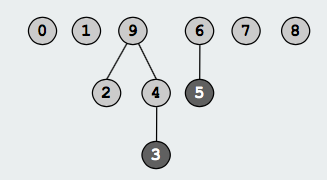
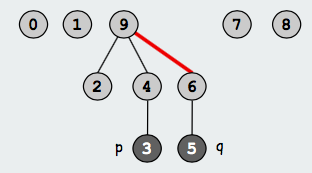
图片来源 这里
Union Find算法应用
Union Find可用于解决集合相关问题,如判断某元素是否属于集合、两个元素是否属同一集合、求解集合个数等,算法框架如下:
//261. Graph Valid Tree
bool validTree(int n, vector<pair<int, int>>& edges) {
vector<int> num(n,-);
for(auto edge:edges){
//find查看两点是否已在同一集合
int x=find(num,edge.first);
int y=find(num,edge.second);
if(x==y) return false; //两点已在同一集合情况下则出现环
//union让两点加入同一集合
num[x]=y;
}
return n-==edges.size();
}
int find(vector<int>&num,int i){
if(num[i]==-) return i;
return find(num,num[i]); //id[id[...id[i]...]]
}
一些情况下为清晰和解偶会将Uinon Find实现为一个类,独立出明显的Union和Find两个操作。
相关LeetCode题:
947. Most Stones Removed with Same Row or Column 题解
算法优化
有两种常用的方法用来降低并查集树形结构的高度、以减少Uinon Find算法的时间复杂度,这两种方法是:
Weighting(或称作Ranking): 使用多一个数组记录每个集合的size,Uinon时将size小的集合挂到size大的集合下,例如:
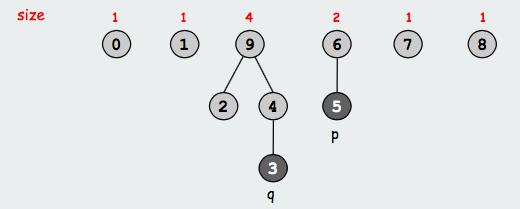
对3、5 Uinon,因3所在集合元素size 4大于5所在集合元素size 2,将6挂到9下而不是将9挂到6下。
Path compression: 对一个集合下的元素直接挂到root之下,而不是挂到其parent,path compression实现很简单只需在Find中加一行代码:
string find(unordered_map<string,string>& root,string s){
if(root[s]!=s)
root[s]=find(root,root[s]);
return root[s];
}
加入path compression也能实现减少并查集树高度的效果,图示如下:
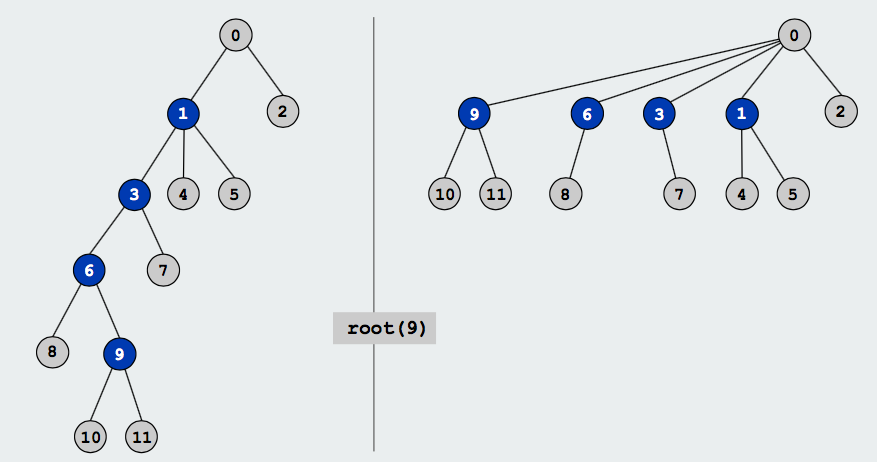
Weighting和Path compression两种方法可以同时使用,这样使得对N个元素进行M次Union Find操作的时间复杂度可以减少到 (M+N)lgN。因lgN随N的增长变化很小,所以整体算法时间复杂度接近于线性的时间复杂度。
相关LeetCode题:
924. Minimize Malware Spread 题解
LeetCode编程训练 - 合并查找(Union Find)的更多相关文章
- LeetCode编程训练 - 折半查找(Binary Search)
Binary Search基础 应用于已排序的数据查找其中特定值,是折半查找最常的应用场景.相比线性查找(Linear Search),其时间复杂度减少到O(lgn).算法基本框架如下: //704. ...
- Leetcode 编程训练
Leetcode这个网站上的题都是一些经典的公司用来面试应聘者的面试题,很多人通过刷这些题来应聘一些喜欢面试算法的公司,比如:Google.微软.Facebook.Amazon之类的这些公司,基本上是 ...
- Leetcode 编程训练(转载)
Leetcode这个网站上的题都是一些经典的公司用来面试应聘者的面试题,很多人通过刷这些题来应聘一些喜欢面试算法的公司,比如:Google.微软.Facebook.Amazon之类的这些公司,基本上是 ...
- 算法与数据结构基础 - 合并查找(Union Find)
Union Find算法基础 Union Find算法用于处理集合的合并和查询问题,其定义了两个用于并查集的操作: Find: 确定元素属于哪一个子集,或判断两个元素是否属于同一子集 Union: 将 ...
- LeetCode编程训练 - 滑动窗口(Sliding Window)
滑动窗口基础 滑动窗口常用来解决求字符串子串问题,借助map和计数器,其能在O(n)时间复杂度求子串问题.滑动窗口和双指针(Two pointers)有些类似,可以理解为往同一个方向走的双指针.常用滑 ...
- LeetCode编程训练 - 拓扑排序(Topological Sort)
拓扑排序基础 拓扑排序用于解决有向无环图(DAG,Directed Acyclic Graph)按依赖关系排线性序列问题,直白地说解决这样的问题:有一组数据,其中一些数据依赖其他,问能否按依赖关系排序 ...
- LeetCode编程训练 - 位运算(Bit Manipulation)
位运算基础 说到与(&).或(|).非(~).异或(^).位移等位运算,就得说到位运算的各种奇淫巧技,下面分运算符说明. 1. 与(&) 计算式 a&b,a.b各位中同为 1 ...
- LeetCode编程训练 - 回溯(Backtracking)
回溯基础 先看一个使用回溯方法求集合子集的例子(78. Subsets),以下代码基本说明了回溯使用的基本框架: //78. Subsets class Solution { private: voi ...
- 每日一道 LeetCode (19):合并两个有序数组
每天 3 分钟,走上算法的逆袭之路. 前文合集 每日一道 LeetCode 前文合集 代码仓库 GitHub: https://github.com/meteor1993/LeetCode Gitee ...
随机推荐
- python正则表达式--split、sub、escape方法
1.re.split 语法: re.split(pattern, string[, maxsplit=0, flags=0]) 参数: pattern 匹配的正则表达式 string ...
- eclipse导入maven时,pom文件的project一直报错(Failure to transfer org.apache.maven.plugins:maven-surefire-plugin:pom:2.12.)
这里有两种解决办法. 一:右键项目->maven->update project勾选上Force Update of Snapshots/Releases然后ok就可以了. 二:如果第一种 ...
- 《剑指offer》平衡二叉树
本题来自<剑指offer> 反转链表 题目: 思路: C++ Code: Python Code: 总结:
- Calendar日历工具类
这个工具类有效的避免跨年的问题 先定义一个日期格式类型: SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:s ...
- java微信获取经纬度转换为高德坐标小结
https://blog.csdn.net/dragon974539495/article/details/78894499
- 《ServerSuperIO Designer IDE使用教程》- 6.增加与阿里云物联网(IOT)对接服务,实现数据交互。发布:v4.2.4 版本
v4.2.4 更新内容:1.增加了对接阿里物联网平台的服务.下载地址:官方下载 6. 增加与阿里云物联网(IOT)对接服务,实现数据交互 6.1 概述 为了满足业务系统数据上云的要求,Se ...
- Python2.7和3.7区别
区别一:print语法使用 Python2.7 print语法使用 >>> print "Hello Python" Python3.7 print语 ...
- 16 道嵌入式C语言面试题
1. 用预处理指令#define 声明一个常数,用以表明 1 年中有多少秒(忽略闰年问题) #define SECONDS_PER_YEAR (60 * 60 * 24 * 365)UL 我在这想看到 ...
- SQL反模式学习笔记3 单纯的树
2014-10-11 在树形结构中,实例被称为节点.每个节点都有多个子节点与一个父节点. 最上层的节点叫做根(root)节点,它没有父节点. 最底层的没有子节点的节点叫做叶(leaf). 中间的节点简 ...
- python第六天(元组、字典、集合)
一.元组(tuple) 作用:存多个值,对比列表来说,元组不可变(是可以当做字典的key的),主要用来读 定义:与列表类型相比,只不过把[ ]换成() age=(11,22,33,44,55)prin ...