用python做一个搜索引擎(Pylucene)
- 什么是搜索引擎?
搜索引擎是“对网络信息资源进行搜集整理并提供信息查询服务的系统,包括信息搜集、信息整理和用户查询三部分”。如图1是搜索引擎的一般结构,信息搜集模块从网络采集信息到网络信息库之中(一般使用爬虫);然后信息整理模块对采集的信息进行分词、去停用词、赋权重等操作后建立索引表(一般是倒排索引)构成索引库;最后用户查询模块就可以识别用户的检索需求并提供检索服务啦。

图1 搜索引擎的一般结构
2. 使用python实现一个简单搜索引擎
2.1 问题分析
从图1看,一个完整的搜索引擎架构从互联网搜集信息开始,可以使用python编写一个爬虫,这是python的强项。
接着,信息处理模块。分词?停用词?倒排表?what?什么乱七八糟的?不用管它,我们有前辈们造好的轮子---Pylucene(lucene的python封装版本,Lucene能够帮助开发者为软件、系统增添检索功能。Lucene是一套用于全文检索和搜寻的开源程序库)。使用Pylucene可以简单的帮助我们完成对采集到的信息进行处理,包括索引的建立和搜索。
最后,为了能在网页上使用我们的搜索引擎,我们使用flask这个轻量级 Web 应用框架做一个小网页获取搜索语句并反馈搜索结果。
2.2 爬虫设计
主要搜集以下内容:目标网页的标题、目标网页的主要文字内容、目标网页指向其他页面的URL地址。网络爬虫的工作流程如图2所。爬虫的主要数据结构是队列。首先,起始的种子节点进入队列,然后从队列中取出一个节点访问,抓取该节点页面上的目标信息,再将该节点页面指向其他页面的URL链接放进队列,再从队列中取出新的节点进行访问,直至队列为空。通过队列“先进先出”的特点实现广度优先的遍历算法,逐个访问站点的每一页面。
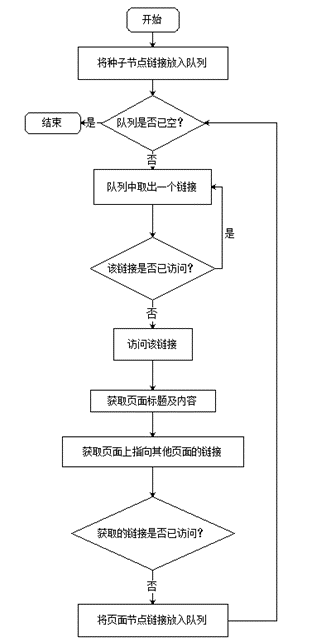
图2
2.3 pylucene的使用
Pylucene中关于建立索引的类主要有Directory、Analyzer、IndexWriter、Document、Filed。
Directory是Pylucene中关于文件操作的类。它有SimpleFSDirectory和RAMDirectory、CompoundFileDirectory、FileSwitchDirectory等11个子类,列举的四个是与索引目录的保存相关的子类,SimpleFSDirectory是将构建的索引保存至文件系统之中;RAMDirectory是将索引保存至RAM内存之中;CompoundFileDirectory是一种复合的索引保存方式;而FileSwitchDirectory允许临时切换索引的保存方式以发挥各种索引保存方式的优点。
Analyzer,分析器。它是对爬虫获得的将要进行构建索引的文本进行处理的类。包括了文本进行分词操作、去掉停用词、转换大小写等操作。Pylucene自带了若干分析器,构建索引时也可使用第三方分析器或者自写分析器。分析器的好坏关系到构建索引的质量与搜索服务的所能提供的精准度与速度。
IndexWriter,索引写入类。在Directory开辟的储存空间中IndexWriter可以进行索引的写入、修改、增添、删除等操作,但不可进行索引的读取也不能搜索索引。
Document,文档类。在Pylucene中建立索引的基本单位是“文档”(Document),一个Document可能是一个网页、一篇文章、一封邮件。Document是用以构建索引的单位同时也是进行搜索时的结果单位,对它进行合理的设计能够提供个性化的搜索服务。
Filed,域类。一个Document之中可以包含多个域(Field)。Filed是Document的组成部分,就如一篇文章的组成可能是文章标题、文章主体、作者、发表日期等多个Filed。
将一个页面作为一个Document,包含三个Field分别是页面的URL地址(url)、页面的标题(title)、页面的主要文字内容(content)。对于索引的储存方式选择使用SimpleFSDirectory类,将索引保存至文件之中。分析器选择Pylucene自带的CJKAnalyzer,该分析器对中文支持较好,适用于中文内容的文本处理。
使用Pylucene构建索引的具体操作步骤如下:
lucene.initVM()
INDEXIDR = self.__index_dir
indexdir = SimpleFSDirectory(File(INDEXIDR))①
analyzer = CJKAnalyzer(Version.LUCENE_30)②
index_writer = IndexWriter(indexdir, analyzer, True, IndexWriter.MaxFieldLength(512))③
document = Document()④
document.add(Field("content", str(page_info["content"]), Field.Store.NOT, Field.Index.ANALYZED))⑤
document.add(Field("url", visiting, Field.Store.YES, Field.Index.NOT_ANALYZED))⑥
document.add(Field("title", str(page_info["title"]), Field.Store.YES, Field.Index.ANALYZED))⑦
index_writer.addDocument(document)⑧
index_writer.optimize()⑨
index_writer.close()⑩
索引的构建有10个主要的步骤:
①实例化一个SimpleFSDirectory对象,将索引保存至本地文件之中,保存的路径为自定义的路径“INDEXIDR”。
②实例化一个CJKAnalyzer分析器,实例化时的参数Version.LUCENE_30为Pylucene的版本号。
③实例化一个IndexWriter对象,所携带的四个参数分是前面的实例化的SimpleFSDirectory对象和CJKAnalyzer分析器,布尔型的变量true表示创建一个新的索引,IndexWriter.MaxFieldLength指定了一个索引最大的域(Filed)数量。
④实例化一个Document对象,取名为document。
⑤为document添加名称为“content”的域。该域的内容为爬虫获取的某一网页页面的主要文字内容。该操作的参数是实例化并马上使用的Field对象;Field对象的四个参数分别是:
(1)“content”,域的名称。
(2)page_info["content"],爬虫搜集到的网页页面的主要文字内容。
(3)Field.Store是用于表示该域的值是否可以恢复原始字符的变量,Field.Store.YES表示存储在该域中的内容可以恢复至原始文本内容,Field. Store.NOT表示不可恢复。
(4)Field.Index变量表示该域的内容是否应用分析器处理,Field. Index.ANALYZED表示对该域字符处理使用分析器,Field. Index. NOT_ANALYZED则表示不对该域使用分析器处理字符。
⑥添加名称为“url”的域用以保存该页面地址。
⑦添加名称为“title”的域用以保存该页面的标题。
⑧实例化IndexWriter对像将文档document写入索引文件。
⑨优化索引库文件,合并索引库中的小文件为大文件。
⑩单个周期内构建索引操作完成后关闭IndexWriter对像。
Pylucene关于建立索引的搜索的类主要有IndexSearcher、Query、QueryParser[16]。
IndexSearcher,索引搜索类。用于在IndexWriter构建的索引库中进行搜索操作。
Query,描述查询请求的类。它将查询请求递交给IndexSearcher完成搜索操作。Query拥有许多子类以完成不同的查询请求。例如TermQuery是按词条搜索,它是最基本最简单的查询类型,用来在指定域中匹配特定项的文档;RangeQuery,指定范围内搜索,用于在指定域中匹配特定范围内的文档;FuzzyQuery,一种模糊查询,能够简单地识别近义词匹配与查询关键字语义相近的项。
QueryParser,Query解析器。需要实现不同的查询需求时必须使用Query提供的不同子类,导致Query使用起来容易造成混乱。因而Pylucene还提供了Query语法解析器QueryParser。QueryParser能够解析提交的Query语句,根据Query语法挑选合适Query子类完成相应的查询,开发者不必关心底层使用的是什么Query实现类。例如Query语句“关键字1 and 关键字2” QueryParser解析为查询同时匹配关键字1和关键字2的文档;Query语句“id[123 to 456]” QueryParser解析成为查询名称为“id”的域中的值在指定范围“123”到“456”之间的文档;Query语句“关键字 site:www.web.com”QueryParser解析成为查询同时满足名称为“site”的域中值为“www.web.com” 和匹配“关键字”两个查询条件的文档。
索引的搜索是Pylucene所专注的领域之一,为实现索引的搜索编写了一个名为query的类,query实现索引的搜索有以下主要步骤:
lucene.initVM()
if query_str.find(":") ==-1 and query_str.find(":") ==-1:
query_str="title:"+query_str+" OR content:"+query_str①
indir= SimpleFSDirectory(File(self.__indexDir))②
lucene_analyzer= CJKAnalyzer(Version.LUCENE_CURRENT)③
lucene_searcher= IndexSearcher(indir)④
my_query = QueryParser(Version.LUCENE_CURRENT,"title",lucene_analyzer).parse(query_str)⑤
total_hits = lucene_searcher.search(my_query, MAX)⑥
for hit in total_hits.scoreDocs:⑦
print"Hit Score: ", hit.score
doc = lucene_searcher.doc(hit.doc)
result_urls.append(doc.get("url").encode("utf-8"))
result_titles.append(doc.get("title").encode("utf-8"))
print doc.get("title").encode("utf-8")
result = {"Hits": total_hits.totalHits, "url":tuple(result_urls), "title":tuple(result_titles)}
return result
索引的搜索有7个主要的步骤:
①首先对搜索语句进行判断,若语句不是针对标题或文章内容进行单一域的查询,即不包含关键词“title:”或“content:”时默认搜索title和content两个域。
②实例化一个SimpleFSDirectory对象,指定它的工作路径为先前创建索引的路径。
③实例化一个CJKAnalyzer分析器,搜索时使用的分析器应与索引构建时使用的分析器在类型版本上均一致。
④实例化一个IndexSearcher对象lucene_searcher,它的参数为第○2步的SimpleFSDirectory对象。
⑤实例化一个QueryParser对象my_query,它描述查询请求,解析Query查询语句。参数Version.LUCENE_CURRENT为pylucene的版本号,“title”指默认的搜索域,lucene_analyzer指定了使用的分析器,query_str是Query查询语句。在实例化QueryParser前会对用户搜索请求作简单处理,若用户指定了搜索某个域就搜索该域,若用户未指定则同时搜索“title”和“content”两个域。
⑥lucene_searcher进行搜索操作,返回结果集total_hits。total_hits中包含结果总数totalHits,搜索结果的文档集scoreDocs,scoreDocs中包括搜索出的文档以及每篇文档与搜索语句相关度的得分。
⑦lucene_searcher搜索出的结果集不能直接被Python处理,因而在搜索操作返回结果之前应将结果由Pylucene转为普通的Python数据结构。使用For循环依次处理每个结果,将结果文档按相关度得分高低依次将它们的地址域“url”的值放入Python列表result_urls,将标题域“title”的值放入列表result_titles。最后将包含地址、标题的列表和结果总数组合成一个Python“字典”,将最后处理的结果作为整个搜索操作的返回值。
用户在浏览器搜索框输入搜索词并点击搜索,浏览器发起一个GET请求,Flask的路由route设置了由result函数响应该请求。result函数先实例化一个搜索类query的对象infoso,将搜索词传递给该对象,infoso完成搜索将结果返回给函数result。函数result将搜索出来的页面和结果总数等传递给模板result.html,模板result.html用于呈现结果
如下是Python使用flask模块处理搜索请求的代码:
app = Flask(__name__)#创建Flask实例
@app.route('/')#设置搜索默认主页
def index():
html="<h1>title这是标题</h1>"
return render_template('index.html')
@app.route("/result",methods=['GET', 'POST'])#注册路由,并指定HTTP方法为GET、POST
def result(): #resul函数
if request.method=="GET":#响应GET请求
key_word=request.args.get('word')#获取搜索语句
if len(key_word)!=0:
infoso = query("./glxy") #创建查询类query的实例
re = infoso.search(key_word)#进行搜索,返回结果集
so_result=[]
n=0
for item in re["url"]:
temp_result={"url":item,"title":re["title"][n]}#将结果集传递给模板
so_result.append(temp_result)
n=n+1
return render_template('result.html', key_word=key_word, result_sum=re["Hits"],result=so_result)
else:
key_word=""
return render_template('result.html')
if __name__ == '__main__':
app.debug = True
app.run()#运行web服务
原文:https://www.cnblogs.com/lucky-pin/p/7117182.html
用python做一个搜索引擎(Pylucene)的更多相关文章
- 用Python做一个知乎沙雕问题总结
用Python做一个知乎沙雕问题总结 松鼠爱吃饼干2020-04-01 13:40 前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以 ...
- 使用python做一个IRC在线下载器
使用python做一个IRC在线下载器 1.开发流程 2.软件流程 3.开始 3.0 准备工作 3.1寻找API接口 3.2 文件模块 3.2.1 选择文件弹窗 3.2.2 提取文件名 3.2.2.1 ...
- 在树莓派上用 python 做一个炫酷的天气预报
教大家如何在树莓派上自己动手做一个天气预报.此次教程需要大家有一定的python 基础,没有也没关系,文末我会放出我已写好的代码供大家下载. 首先在开始之前 需要申请高德地图API,去高德地图官网注册 ...
- 媳妇儿喜欢玩某音中的动漫特效,那我就用python做一个图片转化软件。
最近某音上的动漫特效特别火,很多人都玩着动漫肖像,我媳妇儿也不例外.看着她这么喜欢这个特效,我决定做一个图片处理工具,这样媳妇儿的动漫头像就有着落了.编码 为了快速实现我们的目标,我们 ...
- 用Python做一个简单的翻译工具
编程本身是跟年龄无关的一件事,不论你现在是十四五岁,还是四五十岁,如果你热爱它,并且愿意持续投入其中,必定会有所收获. 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过 ...
- Python做一个计时器的动画
一.问题在做连连看的时候需要加一个计时器的动画,这样就完成了计时功能的设计. 二.解决主要思路: 1.先产生一个画布,用深颜色填充满. 2.产生一个新的矩阵用来覆盖画布,背景用白色,就可以渲染出来递减 ...
- [Python] 用python做一个游戏辅助脚本,完整思路
一.说明 简述:本文将以4399小游戏<宠物连连看经典版2>作为测试案例,通过识别小图标,模拟鼠标点击,快速完成配对.对于有兴趣学习游戏脚本的同学有一定的帮助. 运行环境:Win10/Py ...
- 一听就懂:用Python做一个超简单的小游戏
写它会用到 while 循环random 模块if 语句输入输出函数
- 用Python做一个翻译软件
前两天吃了平哥的一波狗粮,他给女朋友写了一个翻译软件,自己真真切切的感受到了程序员的浪漫.在学习requests请求的时候做过类似的Demo,给百度翻译发送一个post请求可以实现任意词组的翻译,利用 ...
随机推荐
- 非阻塞connect:Web客户程序
一.web.h #include <stdio.h> #include <netdb.h> #include <errno.h> #include <fc ...
- java HttpClient设置代理
HttpClient client = new HttpClient(); UsernamePasswordCredentials creds = new UsernamePasswordCreden ...
- centos7安装mongodb3.4
先下载安装包,OS选择RHEL 7.0 Linux 64-bit x64,package选择Server. 这里OS选6.2应该也行,没试过,如果linux版本是6.*的话注意选这个,如果选择7.0安 ...
- jQuery mouse and lunbo
自动轮播 和 鼠标事件var arr = ["images/d.jpg", "images/q.jpg", "images/c.jpg", ...
- 使用 “mini-css-extract-plugin” 提取css到单独的文件
一.前言 我们在使用webpack构建工具的时候,通过style-loader,可以把解析出来的css通过js插入内部样式表的方式到页面中,插入的结果如下: <style> .wrappe ...
- 记录一个使用HttpClient过程中的一个bug
最近用HttpClient进行链接请求,开了多线程之后发现经常有线程hang住,查看线程dump java.lang.Thread.State: RUNNABLE at java.net.Socket ...
- 单机多es容器服务部署的网络模式
3.1 Bridge模式的拓扑 当Docker server启动时,会在主机上创建一个名为docker0的虚拟网桥,此主机上启动的Docker容器会连接到这个虚拟网桥上.虚拟网桥的工作方式和物理交换机 ...
- Rollup.js 实践
音乐分享: B.o.B Ft. Marko Penn - <Roll up> ——————————————————————————————————————————————————————— ...
- 十个推荐使用的 Laravel 的辅助函数
壹. array_dot() array_dot () 辅助函数允许你将多维数组转换为使用点符号的一维数组. $array = [ 'user' => ['username' => 'so ...
- 创建Git 仓库及 克隆、拉取、和推送操作
打开网址: https://github.com/ 登录上自己创建的 Git账号 一. 创建Git 仓库 start a project---> 输入仓库 ...