Linux内存模型
http://blog.csdn.net/sunyubo458/article/details/6090946
了解linux的内存模型,或许不能让你大幅度提高编程能力,但是作为一个基本知识点应该熟悉。坐火车外出旅行时,即时你对沿途的地方一无所知,仍然可以到达目标地。但是你对整个路途都很比较清楚的话,每到一个站都知道自己在哪里,知道当地的风土人情,对比一下所见所想,旅程可能更有趣一些。
类似的,了解linux的内存模型,你知道每块内存,每个变量,在系统中处于什么样的位置。这同样会让你心情愉快,知道这些,有时还会让你的生活轻更松些。看看变量的地址,你可以大致断定这是否是一个有效的地址。一个变量被破坏了,你可以大致推断谁是犯罪嫌疑人。
Linux的内存模型,一般为:
|
地址 |
作用 |
说明 |
|
>=0xc000 0000 |
内核虚拟存储器 |
用户代码不可见区域 |
|
<0xc000 0000 |
Stack(用户栈) |
ESP指向栈顶 |
|
↓ ↑ |
空闲内存 |
|
|
>=0x4000 0000 |
文件映射区 |
|
|
<0x4000 0000 |
↑ |
空闲内存 |
|
Heap(运行时堆) |
通过brk/sbrk系统调用扩大堆,向上增长。 |
|
|
.data、.bss(读写段) |
从可执行文件中加载 |
|
|
>=0x0804 8000 |
.init、.text、.rodata(只读段) |
从可执行文件中加载 |
|
<0x0804 8000 |
保留区域 |
很多书上都有类似的描述,本图取自于《深入理解计算机系统》p603,略做修改。本图比较清析,很容易理解,但仍然有两点不足。下面补充说明一下:
1. 第一点是关于运行时堆的。
为说明这个问题,我们先运行一个测试程序,并观察其结果:
- #include <stdio.h>
- intmain(intargc, char* argv[])
- {
- int first = 0;
- int* p0 = malloc(1024);
- int* p1 = malloc(1024 * 1024);
- int* p2 = malloc(512 * 1024 * 1024 );
- int* p3 = malloc(1024 * 1024 * 1024 );
- printf("main=%p print=%p/n", main, printf);
- printf("first=%p/n", &first);
- printf("p0=%p p1=%p p2=%p p3=%p/n", p0, p1, p2, p3);
- getchar();
- return 0;
- }
运行后,输出结果为:
main=0x8048404 print=0x8048324
first=0xbfcd1264
p0=0x9253008 p1=0xb7ec0008 p2=0x97ebf008 p3=0x57ebe008
main和print两个函数是代码段(.text)的,其地址符合表一的描述。
l first是第一个临时变量,由于在first之前还有一些环境变量,它的值并非0xbfffffff,而是0xbfcd1264,这是正常的。
l p0是在堆中分配的,其地址小于0x4000 0000,这也是正常的。
l 但p1和p2也是在堆中分配的,而其地址竟大于0x4000 0000,与表一描述不符。
原因在于:运行时堆的位置与内存管理算法相关,也就是与malloc的实现相关。关于内存管理算法的问题,我们在后继文章中有详细描述,这里只作简要说明。在glibc实现的内存管理算法中,Malloc小块内存是在小于0x4000 0000的内存中分配的,通过brk/sbrk不断向上扩展,而分配大块内存,malloc直接通过系统调用mmap实现,分配得到的地址在文件映射区,所以其地址大于0x4000 0000。
从maps文件中可以清楚的看到一点:
|
00514000-00515000 r-xp 00514000 00:00 0 00624000-0063e000 r-xp 00000000 03:01 718192 /lib/ld-2.3.5.so 0063e000-0063f000 r-xp 00019000 03:01 718192 /lib/ld-2.3.5.so 0063f000-00640000 rwxp 0001a000 03:01 718192 /lib/ld-2.3.5.so 00642000-00766000 r-xp 00000000 03:01 718193 /lib/libc-2.3.5.so 00766000-00768000 r-xp 00124000 03:01 718193 /lib/libc-2.3.5.so 00768000-0076a000 rwxp 00126000 03:01 718193 /lib/libc-2.3.5.so 0076a000-0076c000 rwxp 0076a000 00:00 0 08048000-08049000 r-xp 00000000 03:01 1307138 /root/test/mem/t.exe 08049000-0804a000 rw-p 00000000 03:01 1307138 /root/test/mem/t.exe 09f5d000-09f7e000 rw-p 09f5d000 00:00 0 [heap] 57e2f000-b7f35000 rw-p 57e2f000 00:00 0 b7f44000-b7f45000 rw-p b7f44000 00:00 0 bfb2f000-bfb45000 rw-p bfb2f000 00:00 0 [stack] |
2. 第二是关于多线程的。
现在的应用程序,多线程的居多。表一所描述的模型无法适用于多线程环境。按表一所述,程序最多拥有上G的栈空间,事实上,在多线程情况下,能用的栈空间是非常有限的。为了说明这个问题,我们再看另外一个测试:
- #include <stdio.h>
- #include <pthread.h>
- void* thread_proc(void* param)
- {
- int first = 0;
- int* p0 = malloc(1024);
- int* p1 = malloc(1024 * 1024);
- printf("(0x%x): first=%p/n", pthread_self(), &first);
- printf("(0x%x): p0=%p p1=%p /n", pthread_self(), p0, p1);
- return 0;
- }
- #define N 5
- intmain(intargc, char* argv[])
- {
- intfirst = 0;
- inti= 0;
- void* ret = NULL;
- pthread_t tid[N] = {0};
- printf("first=%p/n", &first);
- for(i = 0; i < N; i++)
- {
- pthread_create(tid+i, NULL, thread_proc, NULL);
- }
- for(i = 0; i < N; i++)
- {
- pthread_join(tid[i], &ret);
- }
- return 0;
- }
运行后,输出结果为:
first=0xbfd3d35c
(0xb7f2cbb0): first=0xb7f2c454
(0xb7f2cbb0): p0=0x84d52d8 p1=0xb4c27008
(0xb752bbb0): first=0xb752b454
(0xb752bbb0): p0=0x84d56e0 p1=0xb4b26008
(0xb6b2abb0): first=0xb6b2a454
(0xb6b2abb0): p0=0x84d5ae8 p1=0xb4a25008
(0xb6129bb0): first=0xb6129454
(0xb6129bb0): p0=0x84d5ef0 p1=0xb4924008
(0xb5728bb0): first=0xb5728454
(0xb5728bb0): p0=0x84d62f8 p1=0xb7e2c008
我们看一下:
主线程与第一个线程的栈之间的距离:0xbfd3d35c - 0xb7f2c454=0x7e10f08=126M
第一个线程与第二个线程的栈之间的距离:0xb7f2c454 - 0xb752b454=0xa01000=10M
其它几个线程的栈之间距离均为10M。
也就是说,主线程的栈空间最大为126M,而普通线程的栈空间仅为10M,超这个范围就会造成栈溢出。
系统为进程分配数据空间有三种形式。
静态分配
整块静态分配空间,包括其中的所有数据实体,都是在进程创建时由系统一次性分配的(同时为UNIX称为Text的代码分配空间)。这块空间在进程运行期间保持不变。
初始化的和未初始化的实体分别放在初始化数据段和未初始化数据段(BSS)。后者和前者不同,在.o文件a.out文件里都不存在(只有构架信息),在进程的虚拟空间里才展开。
extern变量和static变量采用静态分配。
在进程创建时做静态分配,分配正文(text)段、数据段和栈空间。
正文和初始化数据是按a.out照样复制过来;未初始化数据按构架信息展开,填以0或空;栈空间的大小由链接器开关(具体哪个开关忘了)决定。
栈分配
整个栈空间已在进程创建时分配好。栈指针SP的初值的设定,确定了栈空间的大小。链接器的某个开关可以设定栈空间的大小。在进程运行期间,栈空间的大小不变。但是,在进程刚启动时,栈空间是空的,里面没有实体。在进程运行期间,对具体实体的栈分配是进程自行生成(压栈)和释放(弹出)实体,系统并不参与。
auto变量和函数参数采用栈分配。
只要压入的实体的总长度不超过栈空间尺寸,栈分配就与系统无关。如果超过了,就会引发栈溢出错误。
堆分配
当进程需要生成实体时,向系统申请分配空间;不再需要该实体时,可以向系统申请回收这块空间。
堆分配使用特定的函数(如malloc()等)或操作符(new)。所生成的实体都是匿名的,只能通过指针去访问。
对实体来说,栈分配和堆分配都是动态分配:实体都是在进程运行中生成和消失。而静态分配的所有实体都是在进程创建时全部分配好的,在运行中一直存在。
同为动态分配,栈分配与堆分配是很不相同的。前者是在进程创建时由系统分配整块栈空间,以后实体通过压栈的方式产生,并通过弹出的方式取消。不管是否产生实体,产生多少实体,栈空间总是保持原来的大小。后者并没有预设的空间,当需要产生实体时,才向系统申请正好能容纳这个实体的空间。当不再需要该实体时,可以向系统申请回收这块空间。因此,堆分配是真正的动态分配。
显然,堆分配的空间利用率最高。
栈分配和静态分配也有共性:整块空间是在进程创建时由系统分配的。但是,后者同时分配了所有实体的空间,而前者在进程启动时是空的。另外,栈上的实体和数据段里的实体都是有名实体,可以通过标识符来访问。
|
静态分配 |
栈分配 |
堆分配 |
|
|
整块空间生成 |
进程创建时 |
进程创建时 |
用一点分配一点 |
|
实体生成时间 |
进程创建时 |
进程运行时 |
进程运行时 |
|
实体生成者 |
操作系统 |
进程 |
进程申请/系统实施 |
|
生命期 |
永久 |
临时 |
完全可控 |
|
有名/匿名 |
有名 |
有名 |
匿名 |
|
访问方式 |
能以标识访问 |
能以标识访问 |
只能通过指针访问 |
|
空间可否回收 |
不可 |
不可 |
可以 |
栈溢出的后果是比较严重的,或者出现Segmentation fault错误,或者出现莫名其妙的错误。
http://blog.csdn.net/bullbat/article/details/7166736
linux使用于广泛的体系结构,因此需要用一种与体系结构无关的方式来描述内存。linux用VM描述和管理内存。在VM中兽药的普遍概念就是非一致内存访问。对于大型机器而言,内存会分成许多簇,依据簇与处理器“距离”的不同,访问不同的簇会有不同的代价。
每个簇都被认为是一个节点(pg_data_t),每个节点被分成很多的成为管理区(zone)的块,用于表示内存中的某个范围。除了ZONE_DMA,ZONE_NORMAL,ZONE_HIGHMEM以外,linux2.6.32中引入了ZONE_MOVABLE,用于适应大块连续内存的分配。
每个物理页面由一个page结构体描述,所有的结构都存储在一个全局的mem_map数组中(非平板模式),该数组通常存放在ZONE_NORMAL的首部,或者就在校内存系统中为装入内核映像而预留的区域之后。
节点
内存的每个节点都有pg_data_t描述,在分配一个页面时,linux采用节点局部分配的策略,从最靠近运行中的CPU的节点分配内存。由于进程往往是在同一个CPU上运行,因此从当前节点得到的内存很可能被用到。
- /*
- * The pg_data_t structure is used in machines with CONFIG_DISCONTIGMEM
- * (mostly NUMA machines?) to denote a higher-level memory zone than the
- * zone denotes.
- *
- * On NUMA machines, each NUMA node would have a pg_data_t to describe
- * it's memory layout.
- *
- * Memory statistics and page replacement data structures are maintained on a
- * per-zone basis.
- */
- struct bootmem_data;
- typedef struct pglist_data {
- /*该节点内的内存区。可能的区域类型用zone_type表示。 */
- struct zone node_zones[MAX_NR_ZONES];
- /* 该节点的备用内存区。当节点没有可用内存时,就从备用区中分配内存。*/
- struct zonelist node_zonelists[MAX_ZONELISTS];
- /*可用内存区数目,即node_zones数据中保存的最后一个有效区域的索引*/
- int nr_zones;
- #ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */
- /* 在平坦型的内存模型中,它指向本节点第一个页面的描述符。 */
- struct page *node_mem_map;
- #ifdef CONFIG_CGROUP_MEM_RES_CTLR
- /*cgroup相关*/
- struct page_cgroup *node_page_cgroup;
- #endif
- #endif
- /**
- * 在内存子系统初始化以前,即boot阶段也需要进行内存管理。
- * 此结构用于这个阶段的内存管理。
- */
- struct bootmem_data *bdata;
- #ifdef CONFIG_MEMORY_HOTPLUG
- /*
- * Must be held any time you expect node_start_pfn, node_present_pages
- * or node_spanned_pages stay constant. Holding this will also
- * guarantee that any pfn_valid() stays that way.
- *
- * Nests above zone->lock and zone->size_seqlock.
- */
- /*当系统支持内存热插拨时,用于保护本结构中的与节点大小相关的字段。
- 哪调用node_start_pfn,node_present_pages,node_spanned_pages相关的代码时,需要使用该锁。
- */
- spinlock_t node_size_lock;
- #endif
- /*起始页面帧号,指出该节点在全局mem_map中
- 的偏移*/
- unsigned long node_start_pfn;
- unsigned long node_present_pages; /* total number of physical pages */
- unsigned long node_spanned_pages; /* total size of physical page range, including holes */
- /*节点编号*/
- int node_id;
- /*等待该节点内的交换守护进程的等待队列。将节点中的页帧换出时会用到。*/
- wait_queue_head_t kswapd_wait;
- /*负责该节点的交换守护进程。*/
- struct task_struct *kswapd;
- /*由页交换子系统使用,定义要释放的区域大小。*/
- int kswapd_max_order;
- } pg_data_t;
管理区
每个管理区由一个zone结构体描述,对于管理区的类型描述如下
- enum zone_type {
- #ifdef CONFIG_ZONE_DMA
- /*
- * ZONE_DMA is used when there are devices that are not able
- * to do DMA to all of addressable memory (ZONE_NORMAL). Then we
- * carve out the portion of memory that is needed for these devices.
- * The range is arch specific.
- *
- * Some examples
- *
- * Architecture Limit
- * ---------------------------
- * parisc, ia64, sparc <4G
- * s390 <2G
- * arm Various
- * alpha Unlimited or 0-16MB.
- *
- * i386, x86_64 and multiple other arches
- * <16M.
- */
- ZONE_DMA,
- #endif
- #ifdef CONFIG_ZONE_DMA32
- /*
- * x86_64 needs two ZONE_DMAs because it supports devices that are
- * only able to do DMA to the lower 16M but also 32 bit devices that
- * can only do DMA areas below 4G.
- */
- ZONE_DMA32,
- #endif
- /*
- * Normal addressable memory is in ZONE_NORMAL. DMA operations can be
- * performed on pages in ZONE_NORMAL if the DMA devices support
- * transfers to all addressable memory.
- */
- ZONE_NORMAL,
- #ifdef CONFIG_HIGHMEM
- /*
- * A memory area that is only addressable by the kernel through
- * mapping portions into its own address space. This is for example
- * used by i386 to allow the kernel to address the memory beyond
- * 900MB. The kernel will set up special mappings (page
- * table entries on i386) for each page that the kernel needs to
- * access.
- */
- ZONE_HIGHMEM,
- #endif
- /*
- 这是一个伪内存段。为了防止形成物理内存碎片,
- 可以将虚拟地址对应的物理地址进行迁移。
- */
- ZONE_MOVABLE,
- __MAX_NR_ZONES
- };
里面的英文注释已经写的很详细了。
管理区用于跟踪诸如页面使用情况统计数,空闲区域信息和锁信息等。
- struct zone {
- /* Fields commonly accessed by the page allocator */
- /* zone watermarks, access with *_wmark_pages(zone) macros */
- /*本管理区的三个水线值:高水线(比较充足)、低水线、MIN水线。*/
- unsigned long watermark[NR_WMARK];
- /*
- * We don't know if the memory that we're going to allocate will be freeable
- * or/and it will be released eventually, so to avoid totally wasting several
- * GB of ram we must reserve some of the lower zone memory (otherwise we risk
- * to run OOM on the lower zones despite there's tons of freeable ram
- * on the higher zones). This array is recalculated at runtime if the
- * sysctl_lowmem_reserve_ratio sysctl changes.
- */
- /**
- * 当高端内存、normal内存区域中无法分配到内存时,需要从normal、DMA区域中分配内存。
- * 为了避免DMA区域被消耗光,需要额外保留一些内存供驱动使用。
- * 该字段就是指从上级内存区退到回内存区时,需要额外保留的内存数量。
- */
- unsigned long lowmem_reserve[MAX_NR_ZONES];
- #ifdef CONFIG_NUMA
- /*所属的NUMA节点。*/
- int node;
- /*
- * zone reclaim becomes active if more unmapped pages exist.
- */
- /*当可回收的页超过此值时,将进行页面回收。*/
- unsigned long min_unmapped_pages;
- /*当管理区中,用于slab的可回收页大于此值时,将回收slab中的缓存页。*/
- unsigned long min_slab_pages;
- /*
- * 每CPU的页面缓存。
- * 当分配单个页面时,首先从该缓存中分配页面。这样可以:
- *避免使用全局的锁
- * 避免同一个页面反复被不同的CPU分配,引起缓存行的失效。
- * 避免将管理区中的大块分割成碎片。
- */
- struct per_cpu_pageset *pageset[NR_CPUS];
- #else
- struct per_cpu_pageset pageset[NR_CPUS];
- #endif
- /*
- * free areas of different sizes
- */
- /*该锁用于保护伙伴系统数据结构。即保护free_area相关数据。*/
- spinlock_t lock;
- #ifdef CONFIG_MEMORY_HOTPLUG
- /* see spanned/present_pages for more description */
- /*用于保护spanned/present_pages等变量。这些变量几乎不会发生变化,除非发生了内存热插拨操作。
- 这几个变量并不被lock字段保护。并且主要用于读,因此使用读写锁。*/
- seqlock_t span_seqlock;
- #endif
- /*伙伴系统的主要变量。这个数组定义了11个队列,每个队列中的元素都是大小为2^n的页面*/
- struct free_area free_area[MAX_ORDER];
- #ifndef CONFIG_SPARSEMEM
- /*
- * Flags for a pageblock_nr_pages block. See pageblock-flags.h.
- * In SPARSEMEM, this map is stored in struct mem_section
- */
- /*本管理区里的页面标志数组*/
- unsigned long *pageblock_flags;
- #endif /* CONFIG_SPARSEMEM */
- /*填充的未用字段,确保后面的字段是缓存行对齐的*/
- ZONE_PADDING(_pad1_)
- /* Fields commonly accessed by the page reclaim scanner */
- /*
- * lru相关的字段用于内存回收。这个字段用于保护这几个回收相关的字段。
- * lru用于确定哪些字段是活跃的,哪些不是活跃的,并据此确定应当被写回到磁盘以释放内存。
- */
- spinlock_t lru_lock;
- /* 匿名活动页、匿名不活动页、文件活动页、文件不活动页链表头*/
- struct zone_lru {
- struct list_head list;
- } lru[NR_LRU_LISTS];
- /*页面回收状态*/
- struct zone_reclaim_stat reclaim_stat;
- /*自从最后一次回收页面以来,扫过的页面数*/
- unsigned long pages_scanned; /* since last reclaim */
- unsigned long flags; /* zone flags, see below */
- /* Zone statistics */
- atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
- /*
- * prev_priority holds the scanning priority for this zone. It is
- * defined as the scanning priority at which we achieved our reclaim
- * target at the previous try_to_free_pages() or balance_pgdat()
- * invokation.
- *
- * We use prev_priority as a measure of how much stress page reclaim is
- * under - it drives the swappiness decision: whether to unmap mapped
- * pages.
- *
- * Access to both this field is quite racy even on uniprocessor. But
- * it is expected to average out OK.
- */
- int prev_priority;
- /*
- * The target ratio of ACTIVE_ANON to INACTIVE_ANON pages on
- * this zone's LRU. Maintained by the pageout code.
- */
- unsigned int inactive_ratio;
- /*为cache对齐*/
- ZONE_PADDING(_pad2_)
- /* Rarely used or read-mostly fields */
- /*
- * wait_table -- the array holding the hash table
- * wait_table_hash_nr_entries -- the size of the hash table array
- * wait_table_bits -- wait_table_size == (1 << wait_table_bits)
- *
- * The purpose of all these is to keep track of the people
- * waiting for a page to become available and make them
- * runnable again when possible. The trouble is that this
- * consumes a lot of space, especially when so few things
- * wait on pages at a given time. So instead of using
- * per-page waitqueues, we use a waitqueue hash table.
- *
- * The bucket discipline is to sleep on the same queue when
- * colliding and wake all in that wait queue when removing.
- * When something wakes, it must check to be sure its page is
- * truly available, a la thundering herd. The cost of a
- * collision is great, but given the expected load of the
- * table, they should be so rare as to be outweighed by the
- * benefits from the saved space.
- *
- * __wait_on_page_locked() and unlock_page() in mm/filemap.c, are the
- * primary users of these fields, and in mm/page_alloc.c
- * free_area_init_core() performs the initialization of them.
- */
- wait_queue_head_t * wait_table;
- unsigned long wait_table_hash_nr_entries;
- unsigned long wait_table_bits;
- /*
- * Discontig memory support fields.
- */
- /*管理区属于的节点*/
- struct pglist_data *zone_pgdat;
- /* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
- /*管理区的页面在mem_map中的偏移*/
- unsigned long zone_start_pfn;
- /*
- * zone_start_pfn, spanned_pages and present_pages are all
- * protected by span_seqlock. It is a seqlock because it has
- * to be read outside of zone->lock, and it is done in the main
- * allocator path. But, it is written quite infrequently.
- *
- * The lock is declared along with zone->lock because it is
- * frequently read in proximity to zone->lock. It's good to
- * give them a chance of being in the same cacheline.
- */
- unsigned long spanned_pages; /* total size, including holes */
- unsigned long present_pages; /* amount of memory (excluding holes) */
- /*
- * rarely used fields:
- */
- const char *name;
- } ____cacheline_internodealigned_in_smp;
没有说明的地方,内核中的英文注释已经写得很清楚了。
页面
系统中每个物理页面都有一个相关联的page用于记录该页面的状态。
- /*
- * Each physical page in the system has a struct page associated with
- * it to keep track of whatever it is we are using the page for at the
- * moment. Note that we have no way to track which tasks are using
- * a page, though if it is a pagecache page, rmap structures can tell us
- * who is mapping it.
- */
- struct page {
- unsigned long flags; /* Atomic flags, some possibly
- * updated asynchronously */
- atomic_t _count; /* Usage count, see below. */
- union {
- atomic_t _mapcount; /* Count of ptes mapped in mms,
- * to show when page is mapped
- * & limit reverse map searches.
- */
- struct { /* SLUB */
- u16 inuse;
- u16 objects;
- };
- };
- union {
- struct {
- unsigned long private; /* Mapping-private opaque data:
- * usually used for buffer_heads
- * if PagePrivate set; used for
- * swp_entry_t if PageSwapCache;
- * indicates order in the buddy
- * system if PG_buddy is set.
- */
- struct address_space *mapping; /* If low bit clear, points to
- * inode address_space, or NULL.
- * If page mapped as anonymous
- * memory, low bit is set, and
- * it points to anon_vma object:
- * see PAGE_MAPPING_ANON below.
- */
- };
- #if USE_SPLIT_PTLOCKS
- spinlock_t ptl;
- #endif
- struct kmem_cache *slab; /* SLUB: Pointer to slab */
- /* 如果属于伙伴系统,并且不是伙伴系统中的第一个页
- 则指向第一个页*/
- struct page *first_page; /* Compound tail pages */
- };
- union {/*如果是文件映射,那么表示本页面在文件中的位置(偏移)*/
- pgoff_t index; /* Our offset within mapping. */
- void *freelist; /* SLUB: freelist req. slab lock */
- };
- struct list_head lru; /* Pageout list, eg. active_list
- * protected by zone->lru_lock !
- */
- /*
- * On machines where all RAM is mapped into kernel address space,
- * we can simply calculate the virtual address. On machines with
- * highmem some memory is mapped into kernel virtual memory
- * dynamically, so we need a place to store that address.
- * Note that this field could be 16 bits on x86 ... ;)
- *
- * Architectures with slow multiplication can define
- * WANT_PAGE_VIRTUAL in asm/page.h
- */
- #if defined(WANT_PAGE_VIRTUAL)
- void *virtual; /* Kernel virtual address (NULL if
- not kmapped, ie. highmem) */
- #endif /* WANT_PAGE_VIRTUAL */
- #ifdef CONFIG_WANT_PAGE_DEBUG_FLAGS
- unsigned long debug_flags; /* Use atomic bitops on this */
- #endif
- #ifdef CONFIG_KMEMCHECK
- /*
- * kmemcheck wants to track the status of each byte in a page; this
- * is a pointer to such a status block. NULL if not tracked.
- */
- void *shadow;
- #endif
- };
linux中主要的结构描述体现了linux物理内存管理的设计。后面会介绍linux内存管理的各个细节。
版权声明:本文为博主原创文章,未经博主允许不得转载。
linux内存管理建立在基本的分页机制基础上,在linux内核中RAM的某些部分将会永久的分配给内核,并用来存放内核代码以及静态内核数据结构。RAM的其余部分称为动态内存,这不仅是进程所需的宝贵资源,也是内核本身所需的宝贵资源。实际上,整个系统的性能取决于如何有效地管理动态内存。因此,现在所有多任务操作系统都在经历优化对动态内存的使用,也就是说,尽可能做到当要时分配,不需要时释放。
内存管理是os中最复杂的管理机制之一。linux中采用了很多有效的管理方法,包括页表管理、高端内存(临时映射区、固定映射区、永久映射区、非连续内存区)管理、为减小外部碎片的伙伴系统、为减小内部碎片的slab机制、伙伴系统未建立之前的页面分配制度以及紧急内存管理等等。这些在后面的具体部分会详细进行分析总结。
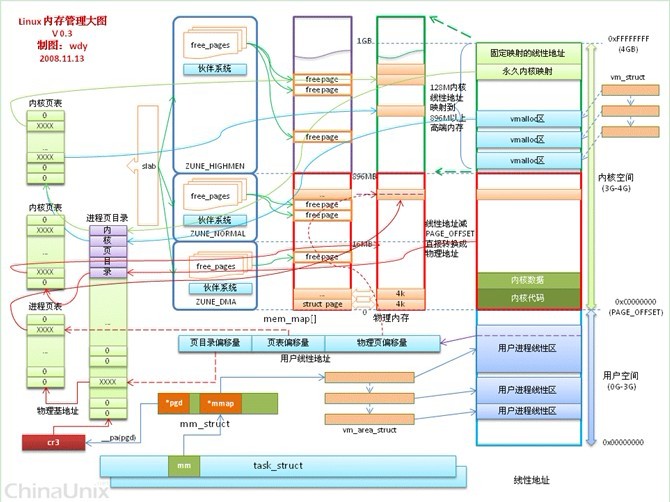
本来想自己画张图,但当我看到这张图,我决定不画了。这张图来自http://bbs.chinaunix.net/thread-2018659-2-1.html,画的很好,基本上说明了linux内存概况。
版权声明:本文为博主原创文章,未经博主允许不得转载。
http://blog.csdn.net/bullbat/article/details/7167870
linux在被bootloader加载到内存后, cpu最初执行的linux内核代码是/header.S文件中的start_of_setup函数,这个函数在做了一些准备工作后会跳转到boot目下文件main.c的main函数执行,在这个main函数中我们可以第一次看到与内存管理相关的代码,这段代码调用detect_memeory()函数检测系统物理内存
在header.S中执行下面汇编代码:
- start_of_setup:
- .....
- # Jump to C code (should not return)
- calll main
- .....
跳到boot目录下的main.c文件中
- void main(void)
- {
- ......
- /* Detect memory layout */
- detect_memory();/*内存探测函数*/
- ......
- }
- int detect_memory(void)
- {
- int err = -1;
- if (detect_memory_e820() > 0)
- err = 0;
- if (!detect_memory_e801())
- err = 0;
- if (!detect_memory_88())
- err = 0;
- return err;
- }
由上面的代码可知,linux内核会分别尝试调用detect_memory_e820()、detcct_memory_e801()、detect_memory_88()获得系统物理内存布局,这3个函数内部其实都会以内联汇编的形式调用bios中断以取得内存信息,该中断调用形式为int 0x15,同时调用前分别把AX寄存器设置为0xe820h、0xe801h、0x88h,关于0x15号中断有兴趣的可以去查询相关手册。下面分析detect_memory_e820()的代码,其它代码基本一样。
- #define SMAP 0x534d4150 /* ASCII "SMAP" */
- /*由于历史原因,一些i/o设备也会占据一部分内存
- 物理地址空间,因此系统可以使用的物理内存空
- 间是不连续的,系统内存被分成了很多段,每个段
- 的属性也是不一样的。int 0x15 查询物理内存时每次
- 返回一个内存段的信息,因此要想返回系统中所有
- 的物理内存,我们必须以迭代的方式去查询。
- detect_memory_e820()函数把int 0x15放到一个do-while循环里,
- 每次得到的一个内存段放到struct e820entry里,而
- struct e820entry的结构正是e820返回结果的结构!而像
- 其它启动时获得的结果一样,最终都会被放到
- boot_params里,e820被放到了 boot_params.e820_map。
- */
- static int detect_memory_e820(void)
- {
- int count = 0;/*用于记录已检测到的物理内存数目*/
- struct biosregs ireg, oreg;
- struct e820entry *desc = boot_params.e820_map;
- static struct e820entry buf; /* static so it is zeroed */
- initregs(&ireg);/*初始化ireg中的相关寄存器*/
- ireg.ax = 0xe820;
- ireg.cx = sizeof buf;/*e820entry数据结构大小*/
- ireg.edx = SMAP;/*标识*/
- ireg.di = (size_t)&buf;/*int15返回值的存放处*/
- /*
- * Note: at least one BIOS is known which assumes that the
- * buffer pointed to by one e820 call is the same one as
- * the previous call, and only changes modified fields. Therefore,
- * we use a temporary buffer and copy the results entry by entry.
- *
- * This routine deliberately does not try to account for
- * ACPI 3+ extended attributes. This is because there are
- * BIOSes in the field which report zero for the valid bit for
- * all ranges, and we don't currently make any use of the
- * other attribute bits. Revisit this if we see the extended
- * attribute bits deployed in a meaningful way in the future.
- */
- do {
- /*在执行这条内联汇编语句时输入的参数有:
- eax寄存器=0xe820
- dx寄存器=’SMAP’
- edi寄存器=desc
- ebx寄存器=next
- ecx寄存器=size
- 返回给c语言代码的参数有:
- id=eax寄存器
- rr=edx寄存器
- ext=ebx寄存器
- size=ecx寄存器
- desc指向的内存地址在执行0x15中断调用时被设置
- */
- intcall(0x15, &ireg, &oreg);
- /*选择下一个*/
- ireg.ebx = oreg.ebx; /* for next iteration... */
- /* BIOSes which terminate the chain with CF = 1 as opposed
- to %ebx = 0 don't always report the SMAP signature on
- the final, failing, probe. */
- if (oreg.eflags & X86_EFLAGS_CF)
- break;
- /* Some BIOSes stop returning SMAP in the middle of
- the search loop. We don't know exactly how the BIOS
- screwed up the map at that point, we might have a
- partial map, the full map, or complete garbage, so
- just return failure. */
- if (oreg.eax != SMAP) {
- count = 0;
- break;
- }
- *desc++ = buf;/*将buf赋值给desc*/
- count++;/*探测数加一*/
- }
- while (ireg.ebx && count < ARRAY_SIZE(boot_params.e820_map));
- /*将内存块数保持到变量中*/
- return boot_params.e820_entries = count;
- }
其中存放中断返回值得结构如下
- struct e820entry {
- __u64 addr; /* start of memory segment */
- __u64 size; /* size of memory segment */
- __u32 type; /* type of memory segment */
- } __attribute__((packed));
在内核初始化跳入start_kernel函数后执行以下初始化
start_kernel()->setup_arch()->setup_memory_map()
- /*调用x86_init.resources.memory_setup()实现对e820内存图的优化,
- 将e820中得值保存在e820_saved中,打印内存图
- */
- void __init setup_memory_map(void)
- {
- char *who;
- /*调用x86体系下的memory_setup函数*/
- who = x86_init.resources.memory_setup();
- /*保存到e820_saved中*/
- memcpy(&e820_saved, &e820, sizeof(struct e820map));
- printk(KERN_INFO "BIOS-provided physical RAM map:\n");
- /*打印输出*/
- e820_print_map(who);
- }
在x86_init.c中定义了x86下的memory_setup函数
- struct x86_init_ops x86_init __initdata = {
- .resources = {
- ……
- .memory_setup = default_machine_specific_memory_setup,
- },
- ……
- };
- char *__init default_machine_specific_memory_setup(void)
- {
- char *who = "BIOS-e820";
- u32 new_nr;
- /*
- * Try to copy the BIOS-supplied E820-map.
- *
- * Otherwise fake a memory map; one section from 0k->640k,
- * the next section from 1mb->appropriate_mem_k
- */
- new_nr = boot_params.e820_entries;
- /*将重叠的去除*/
- sanitize_e820_map(boot_params.e820_map,
- ARRAY_SIZE(boot_params.e820_map),
- &new_nr);
- /*去掉重叠的部分后得到的内存个数*/
- boot_params.e820_entries = new_nr;
- /*将其赋值到全局变量e820中,小于0时,为出错处理*/
- if (append_e820_map(boot_params.e820_map, boot_params.e820_entries)
- < 0) {
- ……
- }
- /* In case someone cares... */
- return who;
- }
append_e820_map调用__append_e820_map实现
- static int __init __append_e820_map(struct e820entry *biosmap, int nr_map)
- {
- while (nr_map) {/*循环nr_map次调用,添加内存块到e820*/
- u64 start = biosmap->addr;
- u64 size = biosmap->size;
- u64 end = start + size;
- u32 type = biosmap->type;
- /* Overflow in 64 bits? Ignore the memory map. */
- if (start > end)
- return -1;
- /*添加函数*/
- e820_add_region(start, size, type);
- biosmap++;
- nr_map--;
- }
- return 0;
- }
- void __init e820_add_region(u64 start, u64 size, int type)
- {
- __e820_add_region(&e820, start, size, type);
- }
e820为e820map结构
- struct e820map {
- __u32 nr_map;
- struct e820entry map[E820_X_MAX];
- };
其中E820_X_MAX大小为128.
- tatic void __init __e820_add_region(struct e820map *e820x, u64 start, u64 size,
- int type)
- {
- int x = e820x->nr_map;
- if (x >= ARRAY_SIZE(e820x->map)) {
- printk(KERN_ERR "Ooops! Too many entries in the memory map!\n");
- return;
- }
到这里,物理内存就已经从BIOS中读出来存放到全局变量e820中,e820是linux内核中用于建立内存管理框架的基础。在后面我们会看到,建立初始化节点、管理区会用到他。
Linux内存模型的更多相关文章
- 探索 Linux 内存模型--转
引用:http://www.ibm.com/developerworks/cn/linux/l-memmod/index.html 理解 Linux 使用的内存模型是从更大程度上掌握 Linux 设计 ...
- 【原创】(四)Linux内存模型之Sparse Memory Model
背景 Read the fucking source code! --By 鲁迅 A picture is worth a thousand words. --By 高尔基 说明: Kernel版本: ...
- 【转】浅析linux内存模型
转自:http://pengpeng.iteye.com/blog/875521 0. 内存基本知识 我们通常称 linux的内存子系统为:虚拟内存子系统(virtual memory system) ...
- linux内存
在Linux的世界中,从大的方面来讲,有两块内存,一块叫做内存空间,Kernel Space,另一块叫做用户空间,即User Space.它们是相互独立的,Kernel对它们的管理方式也完全不同 驱动 ...
- 转 Linux内存管理原理
Linux内存管理原理 在用户态,内核态逻辑地址专指下文说的线性偏移前的地址Linux内核虚拟3.伙伴算法和slab分配器 16个页面RAM因为最大连续内存大小为16个页面 页面最多16个页面,所以1 ...
- (五)Linux内存管理zone_sizes_init
背景 Read the fucking source code! --By 鲁迅 A picture is worth a thousand words. --By 高尔基 说明: Kernel版本: ...
- Linux和进程内存模型
一.Linux和进程内存模型 jvm是一个进程的身份运行在linux系统上,了解linux和进程的内存关系,是理解jvm和Linux内存关系的基础. 硬件.系统.进程三个层面的内存之间的概要关系 1. ...
- Linux的Application 内存模型---
Linux的内存模型,一般为: 现在的每个进程使用了全部4G线性空间.在加载程序时内核把程序加载到线性地址0x08048000开始的位置.这个位置当然>128MB.2G开始是共享库,3G开始是内 ...
- 从linux进程角度看JVM内存模型
普通进程栈区,在JVM一般仅仅用做线程栈,如下图所示 首先是永久代.永久代本质上是Java程序的代码区和数据区.Java程序中类(class),会被加载到整个区域的不同数据结构中去,包括常量池.域.方 ...
随机推荐
- C++Primer 第十八章
//1.异常:待研究 //2.命名空间: // A:多个库将名字放置在全局命名空间中将引发命名空间污染. // B:命名空间为防止名字冲突提供了更加可控的机制.命名空间分割了全局命名空间,其中每个命名 ...
- Redis分布式
昨天公司技术大牛做了一个Redis分布式的技术分享: Redis分布式资源: http://redis.io/topics/cluster-tutorialhttp://redis.io/topics ...
- hduoj 4715 Difference Between Primes 2013 ACM/ICPC Asia Regional Online —— Warmup
http://acm.hdu.edu.cn/showproblem.php?pid=4715 Difference Between Primes Time Limit: 2000/1000 MS (J ...
- [原创]java WEB学习笔记81:Hibernate学习之路--- 对象关系映射文件(.hbm.xml):hibernate-mapping 节点,class节点,id节点(主键生成策略),property节点,在hibernate 中 java类型 与sql类型之间的对应关系,Java 时间和日期类型的映射,Java 大对象类型 的 映射 (了解),映射组成关系
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
- Android--HTTP协议
1 package com.http.get; 2 3 import java.io.FileOutputStream; 4 import java.io.IOException; 5 import ...
- java 字符串转json,json转对象等等...
@RequestMapping(value = "updateInvestorApplyAccountNo", method = RequestMethod.POST) @Resp ...
- nginx在windwos中的使用
本文章参考了 nginx for windows的介绍:http://nginx.org/en/docs/windows.html 你从官网上下载到的是一个 zip 格式的压缩包,首先要把压缩包解压. ...
- 通过restore database时重命名数据库rename database
backup database testdb to disk='c:\testdb_ful.bak' with compression backup log testdb to disk='c:\te ...
- SslUtil
package com.eaju.util; import java.io.OutputStreamWriter;import java.net.URL;import java.net.URLConn ...
- api-ms-win-crt-runtimel1-1-0.dll缺失的解决方案
api-ms-win-crt-runtime就是MFC的运行时环境的库, 在windows上编译也是用微软的visual studio C++编译的软件, 底层也会用到微软提供的C++库和runtim ...