hadoop入门之设置datanode的心跳时间的方法
做作业的过程中发现,把一节点停掉,dfsadmin和50070都无法马上感知到一个data node已经死掉
HDFS默认的超时时间为10分钟+30秒。
这里暂且定义超时时间为timeout
计算公式为:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval
而默认的heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认的大小为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒
所以,举个例子,如果heartbeat.recheck.interval设置为5000(毫秒),dfs.heartbeat.interval设置为3(秒,默认),则总的超时时间为40秒
<property>
<name>heartbeat.recheck.interval</name>
<value>5000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>
参考 http://f.dataguru.cn/thread-128378-1-1.html
--------------------------
Linux环境:CentOs6.4
Hadoop版本:Hadoop-1.1.2
master: 192.168.1.241 NameNode JobTracker DataNode TaskTracker
slave:192.168.1.242 DataNode TaskTracker
内容:设置DataNode的心跳,当某一个节点失去连接之后,在超过设置的时间,看hadoop能否正常工作。
设置时间:
代码如下:
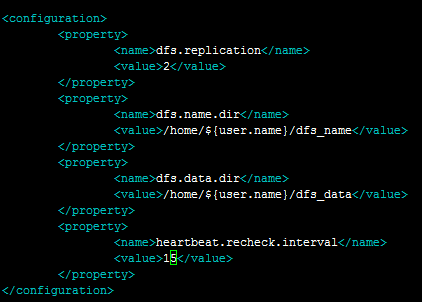
<name>heartbeat.recheck.interval</name>
<value>15</value>
</property>
第一步: 配置hdfs-site.xml
第二步:重启Hadoop
第三步:通过网页浏览两个节点的状态。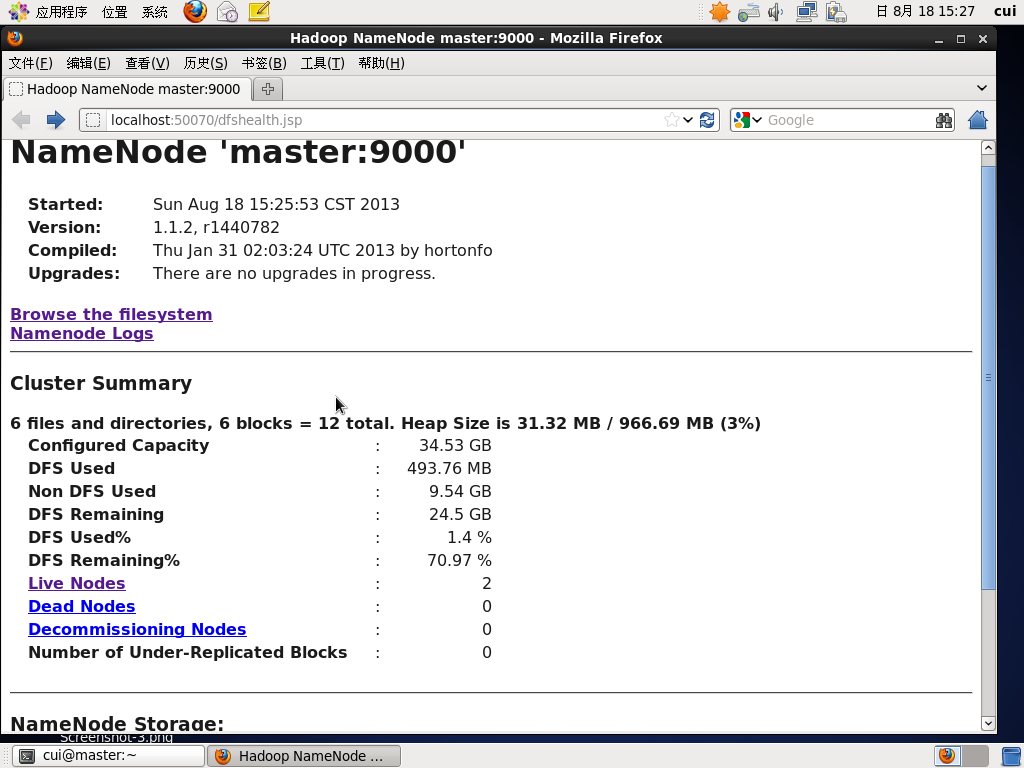
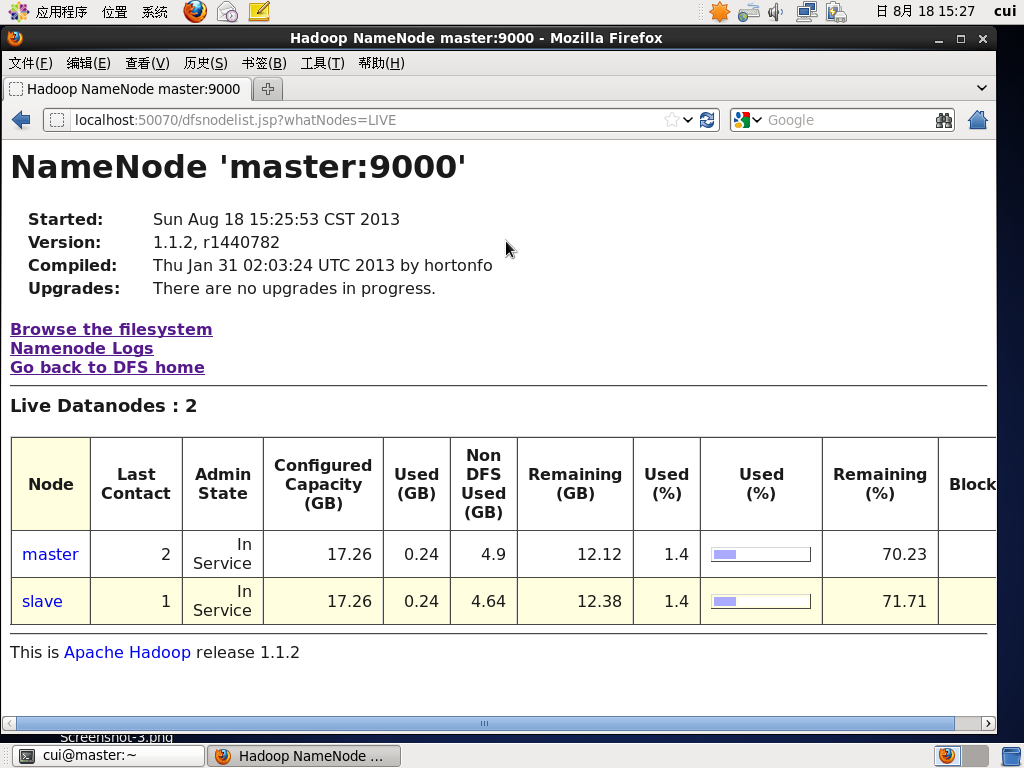
hadoop两个节点都已正常运行。
第三步:杀死主节点的进程,等待15秒。
通过kill命令杀死master上的DataNode节点。
第四步:查看节点状态
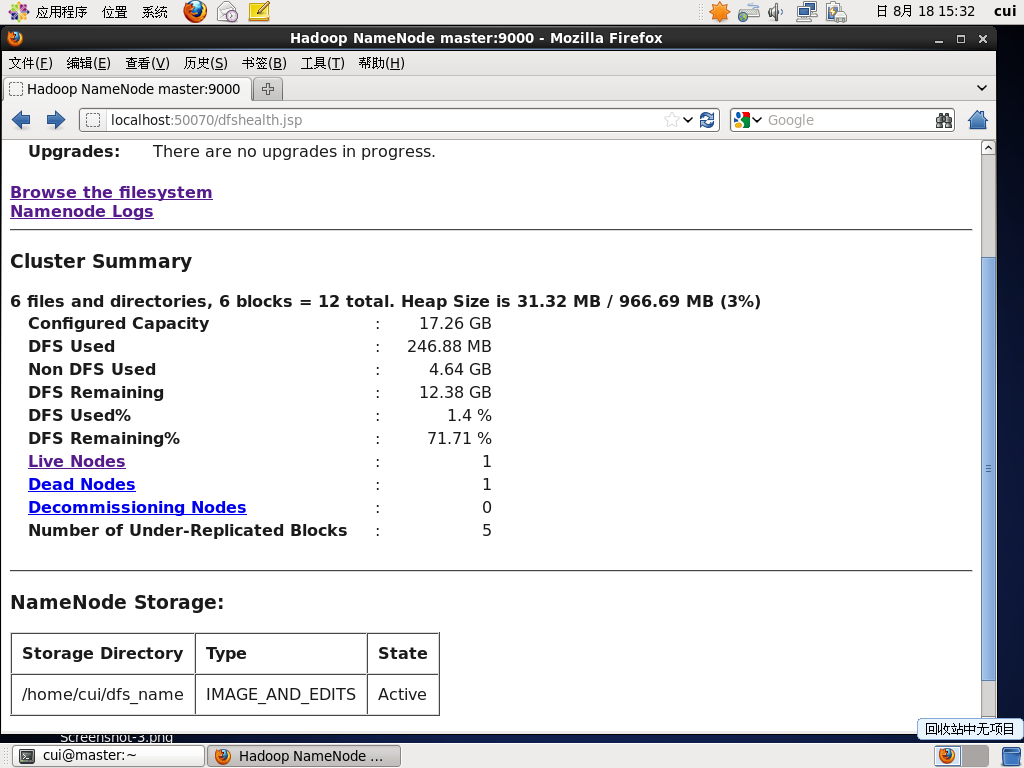
活着的DataNode还有1个,死亡的DataNode一个
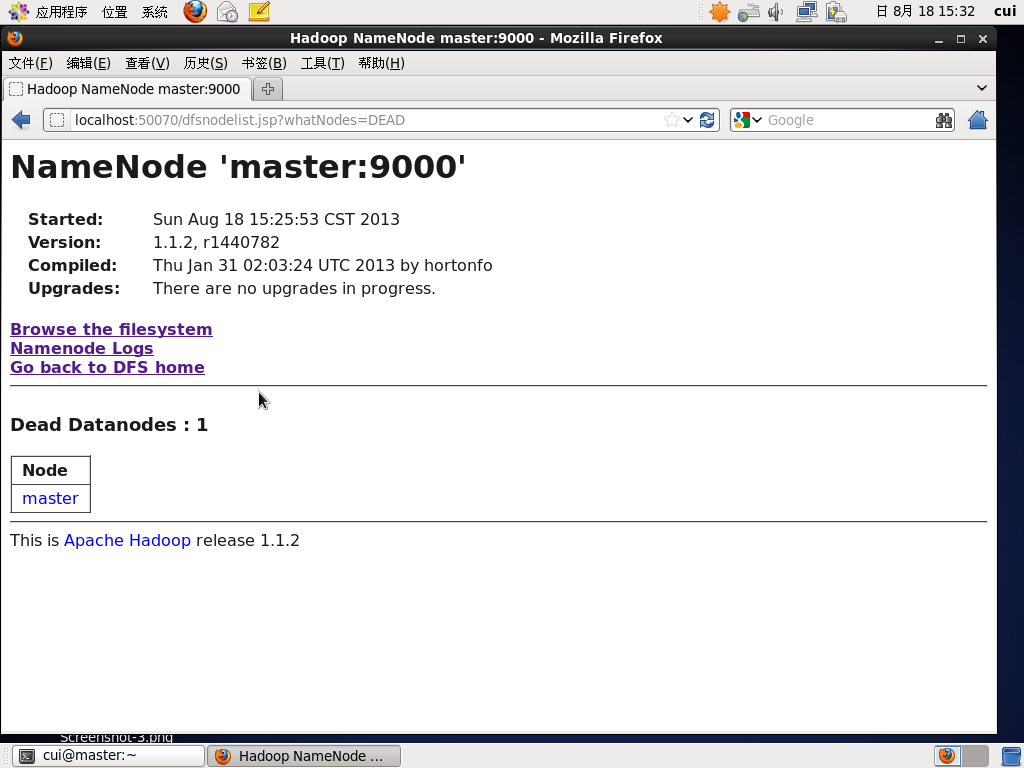
master上的DataNode节点已经标识为Dead

只剩下slave节点,其最后连接时间是2秒(Last Contact 2)
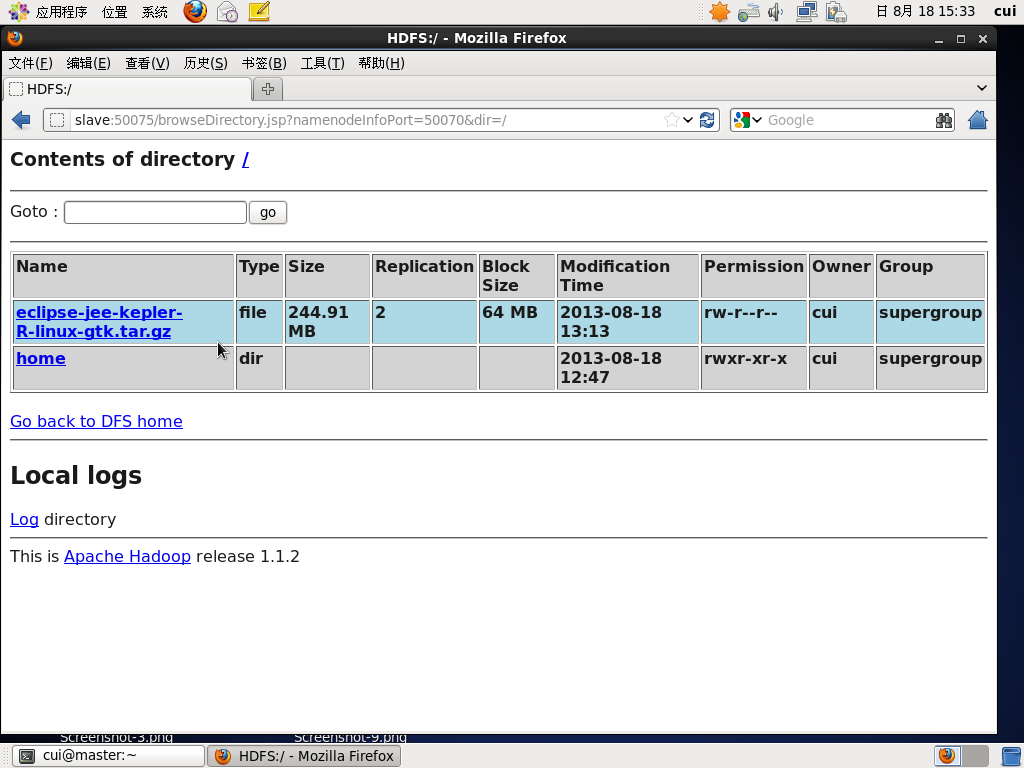
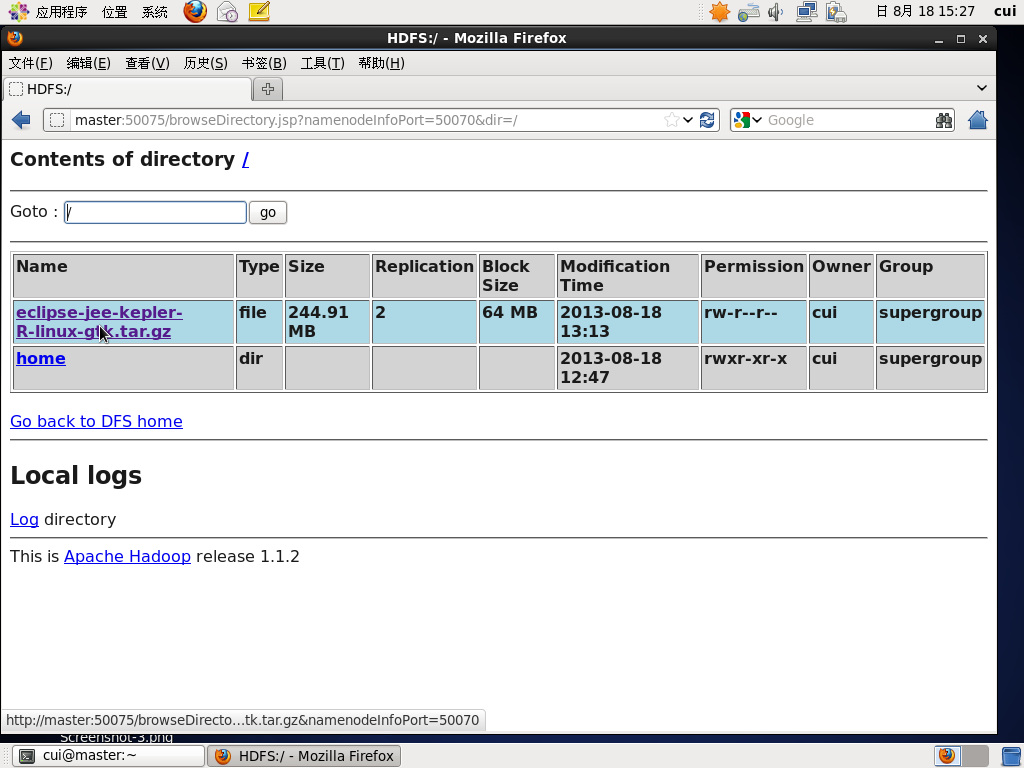
杀死一个节点,两一个节点仍能够正常查看文件信息。

只有slave节点在运行。
http://www.jb51.net/softjc/137250.html
hadoop入门之设置datanode的心跳时间的方法的更多相关文章
- Android 通过应用设置系统日期和时间的方法
Android 通过应用设置系统日期和时间的方法 android 2.3 android 4.0 测试可行,不过需要ROOT权限. ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ...
- java设置配置session过期时间的方法
1) Timeout in the deployment descriptor (web.xml)以分钟为单位 代码如下 复制代码 <web-app ...> <session-co ...
- 【Hadoop】Hadoop DataNode节点超时时间设置
hadoop datanode节点超时时间设置 datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间 ...
- hadoop之 心跳时间与冗余快清除
1.Hadoop datanode节点超时时间设置 datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段 ...
- hadoop入门手册1:hadoop【2.7.1】【多节点】集群配置【必知配置知识1】
问题导读 1.说说你对集群配置的认识?2.集群配置的配置项你了解多少?3.下面内容让你对集群的配置有了什么新的认识? 目的 目的1:这个文档描述了如何安装配置hadoop集群,从几个节点到上千节点.为 ...
- 大数据初级笔记二:Hadoop入门之Hadoop集群搭建
Hadoop集群搭建 把环境全部准备好,包括编程环境. JDK安装 版本要求: 强烈建议使用64位的JDK版本,这样的优势在于JVM的能够访问到的最大内存就不受限制,基于后期可能会学习到Spark技术 ...
- Hadoop入门之hdfs
大数据技术开篇之Hadoop入门[hdfs] 学习都是从了解到熟悉的过程,而学习一项新的技术的时候都是从这个技术是什么?可以干什么?怎么用?如何优化?这几点开始.今天这篇文章分为两个部分.一. ...
- Hadoop入门学习笔记---part3
2015年元旦,好好学习,天天向上.良好的开端是成功的一半,任何学习都不能中断,只有坚持才会出结果.继续学习Hadoop.冰冻三尺,非一日之寒! 经过Hadoop的伪分布集群环境的搭建,基本对Hado ...
- Hadoop入门学习笔记---part2
在<Hadoop入门学习笔记---part1>中感觉自己虽然总结的比较详细,但是始终感觉有点凌乱.不够系统化,不够简洁.经过自己的推敲和总结,现在在此处概括性的总结一下,认为在准备搭建ha ...
随机推荐
- Vmware10.0 安装系统以及使用笔记
1.安装教程参考 大致分为:vmware10.0安装-------建立虚拟机---------设置虚拟机---------启动虚拟机(IOS安装)---------安装系统---------安装vmt ...
- Beaglebone Black– 智能家居控制系统 LAS - 网页服务器 Node.js 、Web Service、页面 和 TCP 请求转 UDP 发送
上一篇,纯粹玩 ESP8266,写入了 init.lua 能收发 UDP.这次拿 BBB 开刀,用 BBB host 一个 web server ,用于与用户交互,数据来自 ESP8266 的 UDP ...
- [SAP ABAP开发技术总结]列表屏幕
声明:原创作品,转载时请注明文章来自SAP师太技术博客( 博/客/园www.cnblogs.com):www.cnblogs.com/jiangzhengjun,并以超链接形式标明文章原始出处,否则将 ...
- Socket&GCDAsyncSocket(异步Socket)
Socket ********************************************* 简单理解Socket 就是网络连接,可以实现两个点之间的数据通讯. •Socket允许使用长连 ...
- 随机内容生成(random模块)
摘抄于: 低调的python小子 当梦想照进现实 幸福近在咫尺 [jpg]http://ip.ipwind.cn/msn.png[/jpg] Python中的random模块用于生成随机数.下面介绍 ...
- unity3d中asset store 的资源下载到本地的目录位置
来源:http://blog.csdn.net/fzhlee/article/details/8613688 C:/Users/[当前用户]/AppData/Roaming/Unity/Asset S ...
- Send to Kindle :一键推送网页内容到多看
http://site.douban.com/129629/widget/notes/7074800/note/207072907/ 注意:增加配置信息,一键发送,方便及时分享网页.
- chubu
python解释型语言,不需要编译成机器认可的二进制码,而是直接从源代码运行程序. python是基于c语言开发的. python很容易嵌入到其他语言. 中文注释,必须在前边加上注释说明 : #_*_ ...
- 如何写好CSS?(OOCSS\DRY\SMACSS)
我现在面对的CSS基本上就是一个三头六臂的怪物,一点不夸张,因为真的是三头六臂,同一个样式在同一个element上作用了好几遍,而同一个样式又分散在4,5个class上,优先级有很多层.可以看得出这个 ...
- Monkey学习(2)简单命令合集
Monkey命令的简单帮助 执行所有命令的前提是,必须先链接模拟器或者实体机,否则会报如下错误信息: 打开命令行窗口,WIN+R,输入CMD 在命令行窗口执行:adb shell monkey –he ...