MySQL用B+树(而不是B树)做索引的原因
众所周知,MySQL的索引使用了B+树的数据结构。那么为什么不用B树呢?
先看一下B树和B+树的区别。
B树
维基百科对B树的定义为“在计算机科学中,B树(B-tree)是一种树状数据结构,它能够存储数据、对其进行排序并允许以O(log n)的时间复杂度运行进行查找、顺序读取、插入和删除的数据结构。B树,概括来说是一个节点可以拥有多于2个子节点的二叉查找树。与自平衡二叉查找树不同,B-树为系统最优化大块数据的读和写操作。B-tree算法减少定位记录时所经历的中间过程,从而加快存取速度。普遍运用在数据库和文件系统。”
B 树可以看作是对2-3查找树的一种扩展,即他允许每个节点有M-1个子节点。
定义
- 根节点至少有两个子节点
- 每个节点有M-1个key,并且以升序排列
- 位于M-1和M key的子节点的值位于M-1 和M key对应的Value之间
- 其它节点至少有M/2个子节点
下图是一个M=4 阶的B树:
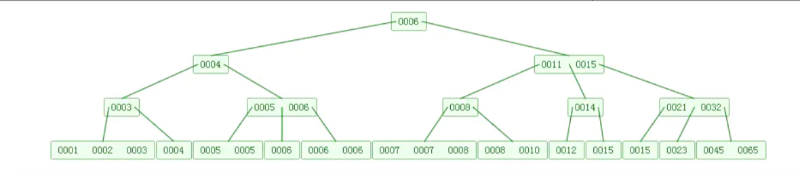
可以看到B树是2-3树的一种扩展,他允许一个节点有多于2个的元素。
B树的插入及平衡化操作和2-3树很相似,这里就不介绍了。
B+树
B+树是对B树的一种变形树,它与B树的差异在于:
- 有k个子结点的结点必然有k个关键码。
- 非叶结点仅具有索引作用,跟记录有关的信息均存放在叶结点中。
- 树的所有叶结点构成一个有序链表,可以按照关键码排序的次序遍历全部记录。
如下图是一个B+树:
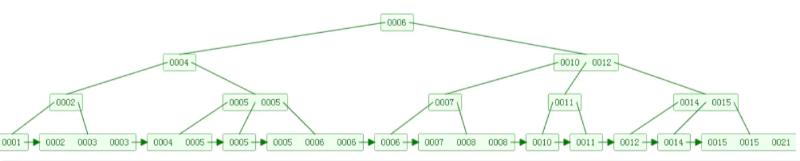
B+树和B树的区别
B+树的非叶子结点只包含导航信息,不包含实际的值,所有的叶子结点和相连的节点使用链表相连,便于区间查找和遍历。
B+ 树的优点在于:
- IO次数更少:由于B+树在内部节点上不包含数据信息,因此在内存页中能够存放更多的key。 数据存放的更加紧密,具有更好的空间局部性。因此访问叶子节点上关联的数据也具有更好的缓存命中率。
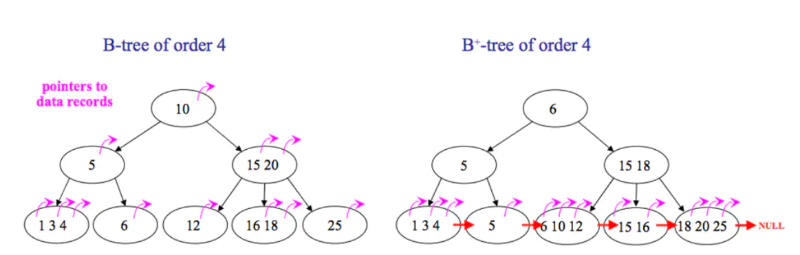
- 遍历更加方便:B+树的叶子结点都是相链的,因此对整棵树的遍历只需要一次线性遍历叶子结点即可。而且由于数据顺序排列并且相连,所以便于区间查找和搜索。而B树则需要进行每一层的递归遍历。相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好。
但是B树也有优点,其优点在于,由于B树的每一个节点都包含key和value,因此经常访问的元素可能离根节点更近,因此访问也更迅速。
下面是B 树和B+树的区别图:
为什么MySQL选择B+树做索引
B+树的磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了。
B+树的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
B+树更便于遍历:由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引。
B+树更适合基于范围的查询:B树在提高了IO性能的同时并没有解决元素遍历的我效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低。
MySQL用B+树(而不是B树)做索引的原因的更多相关文章
- 数据库为什么使用B+树而不是B树
B树和B+树的区别主要有两点: 在B树中,你可以将键和值存放在内部节点和叶子节点,但在B+树中,内部节点都是键,没有值.叶子节点同时存放键和值 B+树的叶子节点有一条链相连,而B+树的叶子节点各自独立 ...
- mysql的索引为什么要使用B+树而不是其他树?
总结 1.InnoDB存储引擎的最小存储单元是页,页可以用于存放数据也可以用于存放键值+指针,在B+树中叶子节点存放数据,非叶子节点存放键值+指针. 2.索引组织表通过非叶子节点的二分查找法以及指针确 ...
- 为什么用B+树做索引&MySQL存储引擎简介
索引的数据结构 为什么不是二叉树,红黑树什么的呢? 首先,一般来说,索引本身也很大,不可能全部存在内存中,因此索引往往以索引文件的方式存在磁盘上.然后一般一个结点一个磁盘块,也就是读一个结点要进行一次 ...
- 为什么 MySQL 索引要使用 B+树而不是其它树形结构?比如 B 树?
一个问题? InnoDB一棵B+树可以存放多少行数据?这个问题的简单回答是:约2千万 为什么是这么多呢? 因为这是可以算出来的,要搞清楚这个问题,我们先从InnoDB索引数据结构.数据组织方式说起. ...
- 面试官:为什么MySQL的索引要使用B+树,而不是其它树?比如B树?
InnoDB的一棵B+树可以存放多少行数据? 答案:约2千万 为什么是这么多? 因为这是可以算出来的,要搞清楚这个问题,先从InnoDB索引数据结构.数据组织方式说起. 计算机在存储数据的时候,有最小 ...
- MySQL存储索引InnoDB数据结构为什么使用B+树,而不是其他树呢?
InnoDB的一棵B+树可以存放多少行数据? 答案:约2千万 为什么是这么多? 因为这是可以算出来的,要搞清楚这个问题,先从InnoDB索引数据结构.数据组织方式说起. 计算机在存储数据的时候,有最小 ...
- 为什么MySQL要用B+树?聊聊B+树与硬盘的前世今生【宇哥带你玩转MySQL 索引篇(二)】
为什么MySQL要用B+树?聊聊B+树与硬盘的前世今生 在上一节,我们聊到数据库为了让我们的查询加速,通过索引方式对数据进行冗余并排序,这样我们在使用时就可以在排好序的数据里进行快速的二分查找,使得查 ...
- Elasticsearch 中为什么选择倒排索引而不选择 B 树索引
目录 前言 为什么全文索引不使用 B+ 树进行存储 全文检索 正排索引 倒排索引 倒排索引如何存储数据 FOR 压缩 RBM 压缩 倒排索引如何存储 字典树(Tria Tree) FST FSM 构建 ...
- MySQL用B+树做索引
索引这个词,相信大多数人已经相当熟悉了,很多人都知道MySQL的索引主要以B+树为主,但是要问到为什么用B+树,恐怕很少有人能把前因后果讲述的很完整.本文就来从头到尾介绍下数据库的索引. 索引是一种数 ...
随机推荐
- 自定义 DataLoader
自定义 DataLoader 如 数据输入 一文所介绍,OneFlow 支持两种数据加载方式:直接使用 NumPy 数据或者使用 DataLoader 及其相关算子. 在大型工业场景下,数据加载容易成 ...
- 保姆级尚硅谷SpringCloud学习笔记(更新中)
目录 前言 正文内容 001_课程说明 002_零基础微服务架构理论入门 微服务优缺点[^1] SpringCloud与微服务的关系 SpringCloud技术栈 003_第二季Boot和Cloud版 ...
- iSCSI网络磁盘
一.fdisk 划分 分区 [root@server0 ~]# lsblk [root@server0 ~]# fdisk /dev/vdb 三个主分区 , 分别2个G大小 两个逻辑分区 , 分别1个 ...
- 基于Typescript的Vue项目配置国际化
基于Typescript的Vue项目配置国际化 简介 使用vue-i18n插件对基于Typescript的vue项目配置国际化,切换多种语言, 配合element-ui或者其他UI库 本文以配置中英文 ...
- Mybatis 中经典的 9 种设计模式!面试可以吹牛了
虽然我们都知道有23个设计模式,但是大多停留在概念层面,真实开发中很少遇到.Mybatis源码中使用了大量的设计模式,阅读源码并观察设计模式在其中的应用,能够更深入的理解设计模式. Mybatis至少 ...
- 一次性搞清Java中的类加载问题
摘要:很多时候提到类加载,大家总是没法马上回忆起顺序,这篇文章会用一个例子为你把类加载的诸多问题一次性澄清. 本文分享自华为云社区<用1个例子加5个问题,一次性搞清java中的类加载问题[奔跑吧 ...
- Qt实现基于多线程的文件传输(服务端,客户端)
1. 效果 先看看效果图 这是传输文件完成的界面 客户端 服务端 2. 知识准备 其实文件传输和聊天室十分相似,只不过一个传输的是文字,一个传输的是文件,而这方面的知识,我已经在前面的博客写过了,不了 ...
- Vue(9)购物车练习
购物车案例 经过一系列的学习,我们这里来练习一个购物车的案例 需求:使用vue写一个表单页面,页面上有购买的数量,点击按钮+或者-,可以增加或减少购物车的数量,数量最少不得少于0,点击移除按钮,会 ...
- 动态路由协议与RIP配置
一.动态路由的概述 二.RIP路由协议工作原理 三.水平分割 四.RIP路由协议v1与v2的区别 五.实验配置 一.动态路由的概述 1.定义 动态路由是指利用路由器上运行的动态路由协议定期和其他路由器 ...
- 3、oracle表空间及索引操作
3.1.创建表空间和用户授权: 1.创建表空间: CREATE TABLESPACE <表空间名> LOGGING DATAFILE '<存放路径>' SIZE 50M AUT ...