c++11 线程间同步---利用std::condition_variable实现
1.前言
很多时候,我们在写程序的时候,多多少少会遇到下面种需求
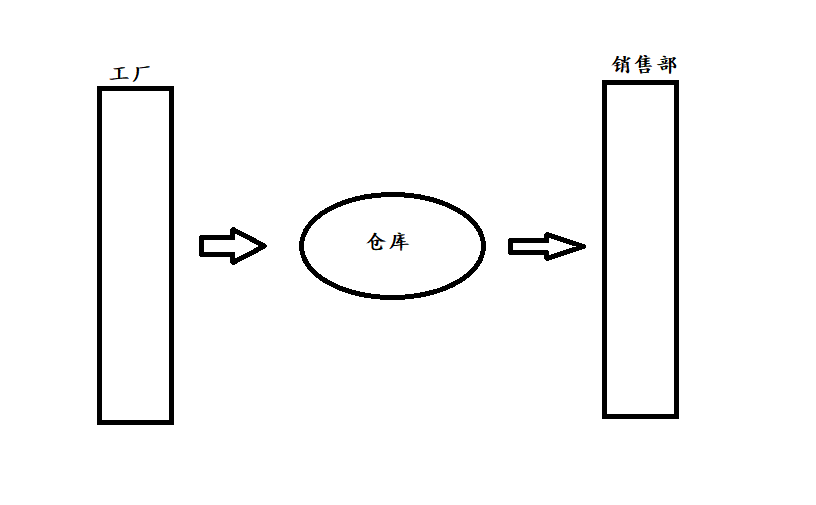
一个产品的大致部分流程,由工厂生产,然后放入仓库,最后由销售员提单卖出去这样。
在实际中,仓库的容量的有限的,也就是说,工厂不能一直生产产品,如果生产太多就会导致仓库满了没地方存放。
为了达到生产效率最大化,就会这样做,只要仓库空了一点位置,工厂就开始生产,等仓库满了以后,工厂就停止生产。
在这过程中,工厂生产产品的速度是销售部卖出产品的速度快很多的。
回到编程中,工厂就是一个单独子线程, 销售部也是一个单独子线程
要想模拟达到上边想要的需求,这就需要用线程间同步啦。
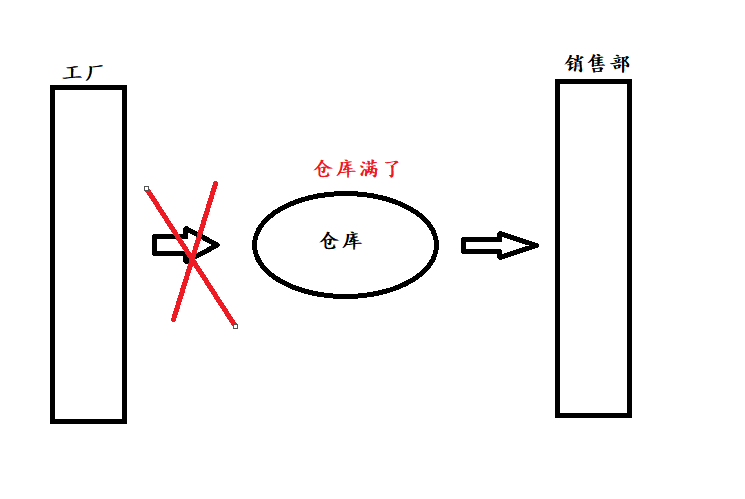
情形1

情形2
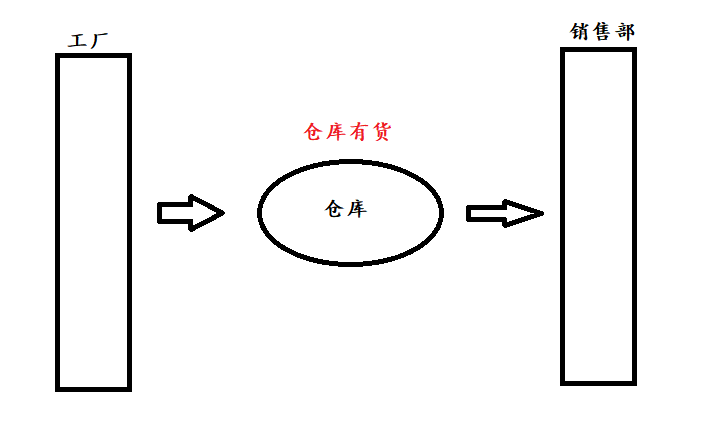
情形3
2.准备工作
| 演示环境 | 解决方式 |
|---|---|
| vs2017 | c++11 条件变量 |
线程间同步机制,有很多的实现方式,这里采用了条件变量的方式。
c++11 把线程thread添加到了标准库,我们可以很方便的使用多线程和进行移植。
只需要引入thread头文件即可使用。
#include <thread>
此次我们需要用到的头文件
#include <iostream>
#include <atomic>
#include <thread> /*线程类*/
#include <condition_variable> /*条件变量*/
#include <mutex> /*线程锁*/
前提: 在使用 std::condition_variable 时,需要配合 mutex 来使用std::unique_lock进行上锁/解锁。
3.代码演示
#include <iostream>
#include <thread>
#include <atomic>
#include <condition_variable>
#include <mutex>
std::mutex _mutex; /*线程锁*/
std::condition_variable cv; /*条件变量*/
std::atomic_int productCnt = 0; /*公共变量,产品库存数量*/
std::atomic_bool isReady = false; /*公共变量,防止假性唤醒线程*/
/*生产产品*/
void Fun1()
{
while (true)
{
std::unique_lock<std::mutex> lock(_mutex);
std::cout << "+++生产了产品, 库存剩余:" << ++productCnt << std::endl;
isReady = true; /*产品生产好了*/
cv.notify_all(); /*唤醒线程,通知Fun2()产品可以卖了*/
cv.wait(lock); /*睡眠线程,Fun1()在等待Fun2()把产品卖出去再生产*/
}
}
/*销售产品*/
void Fun2()
{
while (true)
{
std::unique_lock<std::mutex> lock(_mutex);
/*Fun1()产品还没生产好,Fun2()在这睡大觉*/
if (!isReady) {
cv.wait(lock);
}
std::cout << "---卖出了产品, 库存剩余:" << --productCnt << std::endl;
isReady = false;/*Fun2()把产品买出去啦*/
cv.notify_all();/*Fun2()告诉Fun1()产品已经卖了,可以继续生产了*/
}
}
/*主函数*/
int main(int argc, char **argv)
{
std::thread t1(Fun1);/*声明线程1*/
std::thread t2(Fun2);/*声明线程2*/
t1.join();/*开启线程1*/
t2.join();/*开启线程2*/
return 0;
}
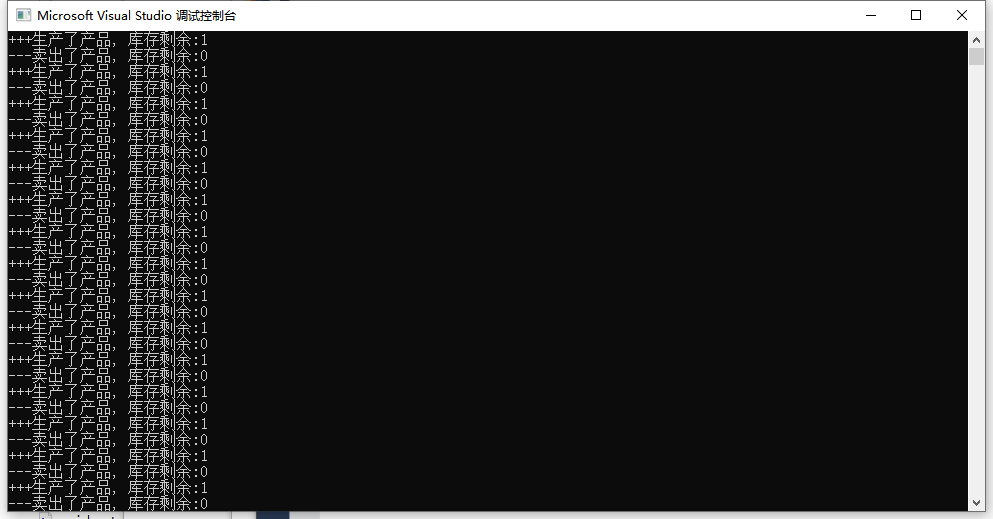
调试结果
c++11 线程间同步---利用std::condition_variable实现的更多相关文章
- C++11并发——多线程条件变量std::condition_variable(四)
https://www.jianshu.com/p/a31d4fb5594f https://blog.csdn.net/y396397735/article/details/81272752 htt ...
- conditon_variable(条件变量)用于线程间同步
conditon_variable(条件变量)用于线程间同步 condition_variable有5个函数,函数名及对应的功能如下: wait阻塞自己,等待唤醒 wait_for阻塞自己,等待唤醒, ...
- C#线程间同步无法关闭
用C#做了个线程间同步的小程序,但每次关闭窗口后进程仍然在,是什么原因? 解决方法: 要加一句 线程.IsBackground = true; 否则退出的只是窗体 上面的方法没看懂... MSDN上说 ...
- Linux系统编程(29)——线程间同步(续篇)
线程间的同步还有这样一种情况:线程A需要等某个条件成立才能继续往下执行,现在这个条件不成立,线程A就阻塞等待,而线程B在执行过程中使这个条件成立了,就唤醒线程A继续执行.在pthread库中通过条件变 ...
- linux线程间同步方式汇总
抽空做了下linux所有线程间同步方式的汇总(原生的),包含以下几个: 1, mutex 2, condition variable 3, reader-writer lock 4, spin loc ...
- rtt学习之线程间同步与通信
一 线程间的同步与互斥:信号量.互斥量.实践集 线程互斥是指对于临界区资源访问的排它性,如多个线程对共享内存资源的访问,生产消费型对产品的操作.临界区操作操作方法有: rt_hw_interrupt_ ...
- Linux进程间通信与线程间同步详解(全面详细)
引用:http://community.csdn.net/Expert/TopicView3.asp?id=4374496linux下进程间通信的几种主要手段简介: 1. 管道(Pipe)及有名管道( ...
- C++ 11 线程的同步与互斥
这次写的线程的同步与互斥,不依赖于任何系统,完全使用了C++11标准的新特性来写的,就连线程函数都用了C++11标准的lambda表达式. /* * thread_test.cpp * * Copyr ...
- 线程间同步之 semaphore(信号量)
原文地址:http://www.cnblogs.com/yuqilin/archive/2011/10/16/2214429.html semaphore 可用于进程间同步也可用于同一个进程间的线程同 ...
随机推荐
- OpenStack Rally 性能测试
注意点:在测试nova,在配置文件里面如果不指定网络id,那么默认是外网的网络(该网络是共享的),如果想要指定网络,那么该网络必须是共享的状态,否则将会报错:无法发现网络.如果测试多于50台的虚拟机需 ...
- JQuery Ajax 请求参数 List 集合处理
引言 JQuery Ajax 发送请求参数一般都是基本类型,比如 String.int:那么,请求参数如果是 List 集合应该如何处理呢? 情况一:Aajx 发送 List 类型请求参数 举例如下: ...
- Lua中的面向对象编程详解
简单说说Lua中的面向对象 Lua中的table就是一种对象,看以下一段简单的代码: 复制代码代码如下: local tb1 = {a = 1, b = 2}local tb2 = {a = 1, b ...
- 将.netcore5.0(.net5)部署在Ubuntu的docker容器中
环境: 宿主机:winows 10 家庭版 虚拟机管理软件:Hyper-V 虚拟机系统:Ubuntu 20.10 Docker版本:Docker CE 20.10.2 ...
- STM32低功耗总结
之前自己做过一个项目的低功耗大约11ua,那时总结下有几点: 1.外设时钟必须切换为内部时钟: 2.不用的外设全部关闭,要用再开就是了: 3.浮空引脚必须配置为下拉: 4.硬件上的上拉.下拉电阻切记不 ...
- .NET Core中插件式开发实现
前言: 之前在文章- AppDomain实现[插件式]开发 中介绍了在 .NET Framework 中,通过AppDomain实现动态加载和卸载程序集的效果. 但是.NET Core 仅支持单个默认 ...
- unity项目字符串转为Vector3和Quaternion
运用环境:一般在读取csv表格的数据时是string类型转为Vector3或者Quaternion类型 字符串格式:x,x,x /x,x,x,x (英文逗号) 方法: /// <summary& ...
- 如何设计 API 接口,实现统一格式返回?
文章目录: 目录 前后端接口交互 接口返回值约定 返回值规范 正确返回 错误返回 统一定义错误码 错误码规范 Controller 层如何用? 正确返回 错误返回 详细代码实现 错误码 Control ...
- BurpSuite安装与sqlmap联动
这是我新建的一台虚拟机,还没有安装java运行环境. 这是我的[burpsuite2.0](https://pan.baidu.com/s/1uGn4IE6_6Xn4cwj_Vo5BBg),现在我们去 ...
- 【接口测试】-1.常用的接口测试工具(Postman、soupUI、Jemeter)
1) Postman 1.get/post请求-- postman获取用户信息1 get方式:可以直接在url中写入参数 Post方式:请求体可以写到URL或Body的form-data中写参 ...