Redis之阻塞分析
Redis是典型的单线程架构,所有的读写操作都是在一条主线程中完成的。当Redis用于高并发场景时,这条线程就变成了它的生命线。如果出现阻塞,哪怕是很短时间,对于我们的应用来说都是噩梦。导致阻塞问题的场景大致分为内在原因和外在原因:
□ 内在原因包括: 不合理地使用API或数据结构、CPU饱和、持久化阻塞等。
□ 外在原因包括: CPU竞争、内存交换、网络问题等。
1.发现阻塞
当Redis阻塞时,线上应用服务应该最先感知到,这时应用方会收到大量Redis超时异常,比如Jedis客户端会抛出JedisConnectionException异常。常见的做法是在应用方加入异常统计并通过邮件/短信/微信报警,以便及时发现通知问题。开发人员需要处理如何统计异常以及触发报警的时机。何时触发报警一般根据应用的并发量决定,如1分钟内超过10个异常触发报警。在实现异常统计时要注意,由于Redis调用API会分散在项目的多个地方,每个地方都监听异常并加入监控代码必然难以维护。这时可以借助于日志系统,如Java语言可以使用logback或log4j。当异常发生时,异常信息最终会被日志系统收集到Appender (输出目的地),默认的Appender—般是具体的日志文件,开发人员可以自定义一个 Appender,用于专门统计异常和触发报警逻辑。(根据使用的程序语言或者工具去完善)
应用方加人异常监控之后还存在一个问题,当开发人员接到异常报警后,通常会去线上服务器査看错误日志细节。这时如果应用操作的是多个Redis节点 (比如使用Redis集群),如何决定是哪一个节点超时还是所有的节点都有超时呢?这是线上很常见的需求,但绝大多数的客户端类库并没有在异常信息中打印ip和port信息,导致无法快速定位是哪个Redis节点超时。不过修改Redis客户端成本很低,比如Jedis只需要修改Connection类下的connect、 sendCommand、readProtocolWithCheckingBroken方法专门捕获连接,发送命令,协议读取事件的异常。由于客户端类库都会保存ip和port信息,当异常发生时很容易打印出对应节点的ip和port,辅助我们快速定位问题节点。
除了在应用方加人统计报警逻辑之外,还可以借助Redis监控系统发现阻塞问题,当监控系统检测到Redis运行期的一些关键指标出现不正常时会触发报警。Redis相关的监控系统开源的方案有很多,一些公司内部也会自己开发监控系统。一个可靠的Redis监控系统首先需要做到对关键指标全方位监控和异常识别,辅助开发运维人员发现定位问题。如果Redis服务没有引入监控系统作辅助支撑,对于线上的服务是非常不负责任和危险的。这里推荐开源的CacheCloud系统,它内部的统计监控模块能够很好地辅助工程师发现定位问题。
监控系统所监控的关键指标有很多,如命令耗时、慢查询、持久化阻塞、连接拒绝、CPU/内存/网络/磁盘使用过载等。当出现阻塞时如果相关人员不能深刻理解这些关键指标的含义和背后的原理,会严重影响解决问题的速度。后面的内容将围绕引起Redis阻塞的原因做重点说明。
2.内在原因
定位到具体的Redis节点异常后,首先应该排查是否是Redis自身原因导致,围绕以下几个方面排查:
□ API或数据结构使用不合理。
□ CPU饱和的问题。
□ 持久化相关的阻塞。
2.1 API或数据结构使用不合理
通常Redis执行命令速度非常快,但也存在例外,如对一个包含上万个元素的hash结构执行hgetall操作,由于数据量比较大且命令算法复杂度是O(n),这条命令执行速度必然很慢。这个问题就是典型的不合理使用API和数据结构。对于高并发的场景我们应该尽量避免在大对象上执行算法复杂度超过O(n)的命令。
1.如何发现慢查询
Redis原生提供慢查询统计功能,执行slow log get {n}命令可以获取最近的n条慢查询命令,默认对于执行超过10毫秒的命令都会记录到一个定长队列中,线上实例建议设置为1毫秒便于及时发现毫秒级以上的命令。如果命令执行时间在毫秒级,则实例实际OPS只有1000左右。慢查询队列长度默认128,可适当调大。慢查询本身只记录了命令执行时间,不包括数据网络传输时间和命令排队时间,因此客户端发生阻塞异常后,可能不是当前命令缓慢,而是在等待其他命令执行。需要重点比对异常和慢查询发生的时间点,确认是否有慢查询造成的命令阻塞排队。
发现慢查询后,开发人员需要作出及时调整。可以按照以下两个方向去调整:
1) 修改为低算法度的命令,如 hgetall改为hmget等,禁用keys、sort等命令。
2) 调整大对象: 缩减大对象数据或把大对象拆分为多个小对象,防止一次命令操作过多的数据。大对象拆分过程需要视具体的业务决定,如用户好友集合存储在Redis中,有些热点用户会关注大量好友,这时可以按时间或其他维度拆分到多个集合中。
2.如何发现大对象
Redis本身提供发现大对象的工具,对应命令: redis -cli -h {ip} -p {port} bigkeys。内部原理采用分段进行scan 操作,把历史扫描过的最大对象统计出来便于分析优化,运行效果如下:
# redis-cli --bigkeys
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type . You can use - i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed ).
[00.00%] Biggest string found so far 'ptc:-571805194744395733' with 17 bytes
[00.00%] Biggest string found so far 'RVF#2570599,1' with 3881 bytes
[00.01%] Biggest hash found so far 'pci:8752795333786343845' with 208 fields
[00.37%] Biggest string found so far 'RVF#1224557,1' with 3882 bytes
[00.75%] Biggest string found so far 'ptc:2404721392920303995' with 4791 bytes
[04.64%] Biggest string found so far 'pcltm:614' with 5176729 bytes
[08.08%] Biggest string found so far 'pcltm:8561' with 11669889 bytes
[21.08%] Biggest string found so far 'pcltm:8598' with 12300864 bytes
...忽略更多输出 ...
------------- summary --------------
Sampled 3192437 keys in the keyspace!
Total key length in bytes is 78299956 (avg len 24.53)
Biggest string found 'pcltm:121' has 17735928 bytes
Biggest hash found 'pci:3650040409957394505' has 209 fields
2526878 strings with 954999242 bytes (79.15% of keys, avg size 377.94)
0 lists with 0 items (00.00% of keys, avg size 0.00)
0 sets with 0 members (00.00% of keys, avg size 0.00)
665559 hashs with 19013973 field s (20.85% of keys, avg size 28.57)
0 zsets with 0 members (00.00% of keys, avg size 0.00)
根据结果汇总信息能非常方便地获取到大对象的键,以及不同类型数据结构的使用情况。
2.2 CPU饱和
单线程的Redis处理命令时只能使用一个CPU。而 CPU饱和是指Redis把单核CPU使用率跑到接近100%。使用top命令很容易识别出对应Redis进程的CPU使用率。CPU饱和是非常危险的,将导致Redis无法处理更多的命令,严重影响吞吐量和应用方的稳定性。对于这种情况,首先判断当前Redis的并发量是否达到极限,建议使用统计命令redis -cli -h {ip} -p {port} --stat获取当前Redis使用情况,该命令每秒输出一行统计信息,运行效果如下:
# redis-cli --stat
----------- data --------------------------------------------- load -------------------------------------- child-keys
mem clients blocked requests connections
3789785 3.20G 507 0 8867955607(+0) 555894
3789813 3.20G 507 0 8867959511 (+63904) 555894
3789822 3.20G 507 0 8867961602 (+62091) 555894
3789831 3.20G 507 0 8867965049 (+63447) 555894
3789842 3.20G 507 0 8867969520 (+62675) 555894
3789845 3.20G 507 0 8867971943 (+62423) 555894
以上输出是一个接近饱和的Redis实例的统计信息,它每秒平均处理6万+的请求。对于这种情况,垂直层面的命令优化很难达到效果,这时就需要做集群化水平扩展来分摊OPS压力。如果只有几百或几千OPS的Redis实例就接近CPU饱和是很不正常的,有可能使用了高算法复杂度的命令。还有一种情况是过度的内存优化,这种情况有些隐蔽,需要我们根据info commandstats统计信息分析出命令不合理开销时间,例如下面的耗时统计:
cmdstat_hset:calls=198757512,usec=27021957243,usec_per_call=135.95
査看这个统计可以发现一个问题,hset命令算法复杂度只有0(1)但平均耗时却达到135微秒,显然不合理,正常情况耗时应该在10微秒以下。这是因为上面的Redis实例为了追求低内存使用量,过度放宽ziplist使用条件(修改了hash-max-ziplist-entries和 hash-max-ziplist-value配置)。进程内的hash对象平均存储着上万个元素,而针对ziplist 的操作算法复杂度在0(n)到0(n2)之间。虽然采用ziplist编码后hash结构内存占用会变小,但是操作变得更慢且更消耗CPU。ziplist压缩编码是Redis用来平衡空间和效率的优化手段,不可过度使用。
2.3 持久化阻塞
对于开启了持久化功能的Redis节点,需要排查是否是持久化导致的阻塞。持久化引起主线程阻塞的操作主要有: fork阻塞、AOF刷盘阻塞、HugePage写操作阻塞。
1.fork 阻塞
fork操作发生在RDB和AOF重写时,Redis主线程调用fork操作产生共享内存的子进程,由子进程完成持久化文件重写工作。如果fork操作本身耗时过长,必然会导致主线程的阻塞。
可以执行info stats命令获取到latest_fork_usec指标,表示Redis最近一次fork操作耗时,如果耗时很大,比如超过1秒,则需要做出优化调整,如避免使用过大的内存实例和规避fork缓慢的操作系统等。
2.AOF刷盘阻塞
当我们开启AOF持久化功能时,文件刷盘的方式一般采用每秒一次,后台线程每秒对A OF文件做fsync操作。当硬盘压力过大时,fsync操作需要等待,直到写入完成。如果主线程发现距离上一次的fsync成功超过2秒,为了数据安全性它会阻塞直到后台线程执行 fsync操作完成。这种阻塞行为主要是硬盘压力引起,可以查看Redis日志识别出这种情况,当发生这种阻塞行为时,会打印如下日志:
Asynchronous AOF fsync is taking too long (disk is busy? ). Writing the AOF
buffer without waiting for fsync to complete, this may slow down Redis.
也可以查看info persistence统计中的aof_delayed_fsync指标,每次发生fdatasync阻塞主线程时会累加。定位阻塞问题后具体优化方法见AOF追加阻塞部分。
硬盘压力可能是Redis进程引起的,也可能是其他进程引起的,可以使用iotop,查看具体是哪个进程消耗过多的硬盘资源。
3.HugePage 写操作阻塞
子进程在执行重写期间利用Linux写时复制技术降低内存开销,因此只有写操作时Redis才复制要修改的内存页。对于开启Transparent HugePages的操作系统,每次写命令引起的复制内存页单位由4K 变为2MB, 放大了 512倍,会拖慢写操作的执行时间,导致大量写操作慢查询。例如简单的incr命令也会出现在慢查询中。关于Transparent HugePages的细节见第12节的12.1节“Linux配置优化”
Redis 官方文档中针对绝大多数的阻塞问题进行了分类说明,这里不再详细介绍,细节请见: http://www.redis.io/topics/latencyo
3.外在原因
排查Redis自身原因引起的阻塞原因之后,如果还没有定位问题,需要排查是否由外部原因引起。围绕以下三个方面进行排查:
□ CPU竞争
□ 内存交换
□ 网络问题
3.1 CPU 竞争
CPU竞争问题如下:
□ 进程竞争:Redis 是典型的 CPU 密集型应用,不建议和其他多核 CPU 密集型服务部署在一起。当其他进程过度消耗 CPU 时,将严重影响 Redis 吞吐量。可以通过top 、sar 等命令定位到 CPU 消耗的时间点和具体进程,这个问题比较容易发现,需要调整服务之间部署结构。
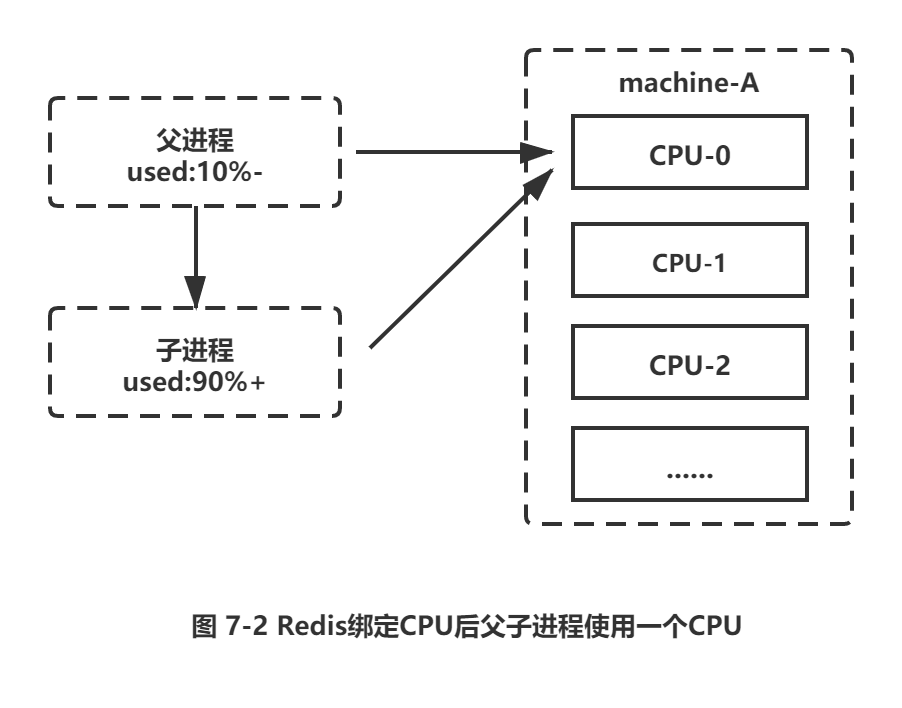
□ 绑定CPU: 部署 Redis 时为了充分利用多核CPU,通常一台机器部署多个实例。常见的一种优化是把 Redis 进程绑定到 CPU 上,用于降低 CPU 频繁上下文切换的开销。这个优化技巧正常情况下没有问题,但是存在例外情况,如图7-2所示。
当Redis父进程创建子进程进行RDB/A0F重写时,如果做了CPU绑定,会与父进程共享使用一个CPU。子进程重写时对单核CPU使用率通常在90% 以上,父进程与子进程将产生激烈CPU竞争,极大影响Redis稳定性。因此对于开启了持久化或参与复制的主节点不建议绑定CPU。
3.2 内存交换
内存交换(swap) 对于Redis来说是非常致命的,Redis保证高性能的一个重要前提是所有的数据在内存中。如果操作系统把Redis使用的部分内存换出到硬盘,由于内存与硬盘读写速度差几个数量级,会导致发生交换后的Redis性能急剧下降。识别Redis内存交换的检查方法如下:
1) 查询Redis进程号:
# redis-cli -p 6383 info server | grep process_id
process_id: 4476
2) 根据进程号查询内存交换信息:
# cat /proc/4476/smaps | grep Swap
Swap: 0 kB
Swap: 0 kB
Swap: 4 kB
Swap: 0 kB
Swap: 0 kB
如果交换量都是OKB或者个别的是4KB,则是正常现象,说明Redis进程内存没有被交换。预防内存交换的方法有:
□ 保证机器充足的可用内存。
□ 确保所有Redis实例设置最大可用内存(maxmemory),防止极端情况下Redis内存不可控的增长。
□ 降低系统使用 swap 优先级,如 echo 10 > /proc/sys/vm/swappiness。
3.3 网络问题
网络问题经常是引起Redis阻塞的问题点。常见的网络问题主要有:连接拒绝、网络延迟、网卡软中断等。
1.连接拒绝
当出现网络闪断或者连接数溢出时,客户端会出现无法连接Redis的情况。我们需要区分这三种情况:网络闪断、Redis连接拒绝、连接溢出。
第一种情况:网络闪断。一般发生在网络割接或者带宽耗尽的情况,对于网络闪断的识别比较困难,常见的做法可以通过sar -n DEV查看本机历史流量是否正常,或者借助外部系统监控工具(如 Ganglia) 进行识别。具体问题定位需要更上层的运维支持,对于重要的Redis服务需要充分考虑部署架构的优化,尽量避免客户端与Redis之间异地跨机房调用。
第二种情况:Redis连接拒绝。Redis通过maxclients参数控制客户端最大连接数,默 认10000。当 Redis 连接数大于maxclients时会拒绝新的连接进入,info stats的rejected _connections统计指标记录所有被拒绝连接的数量:
# redis-cli -p 6384 info Stats | grep rejected_connections
rejected_connections:0
Redis使用多路复用IO模型可支撑大量连接,但是不代表可以无限连接。客户端访问Redis时尽量采用NIO长连接或者连接池的方式。
当Redis用于大量分布式节点访问且生命周期比较短的场景时,如比较典型的在Map/Reduce中使用Redis。因为客户端服务存在频繁启动和销毁的情况且默认Redis不会主动关闭长时间闲置连接或检查关闭无效的TCP连接,因此会导致Redis 连接数快速消耗且无法释放的问题。这种场景下建议设置tcp-keepalive和timeout参数让Redis主动检查和关闭无效连接。
第三种情况:连接溢出。这是指操作系统或者Redis客户端在连接时的问题。这个问题的原因比较多,下面就分别介绍两种原因: 进程限制、backlog队列溢出。
(1) 进程限制
客户端想成功连接上Redis服务需要操作系统和Redis的限制都通过才可以,如图7-3所示。
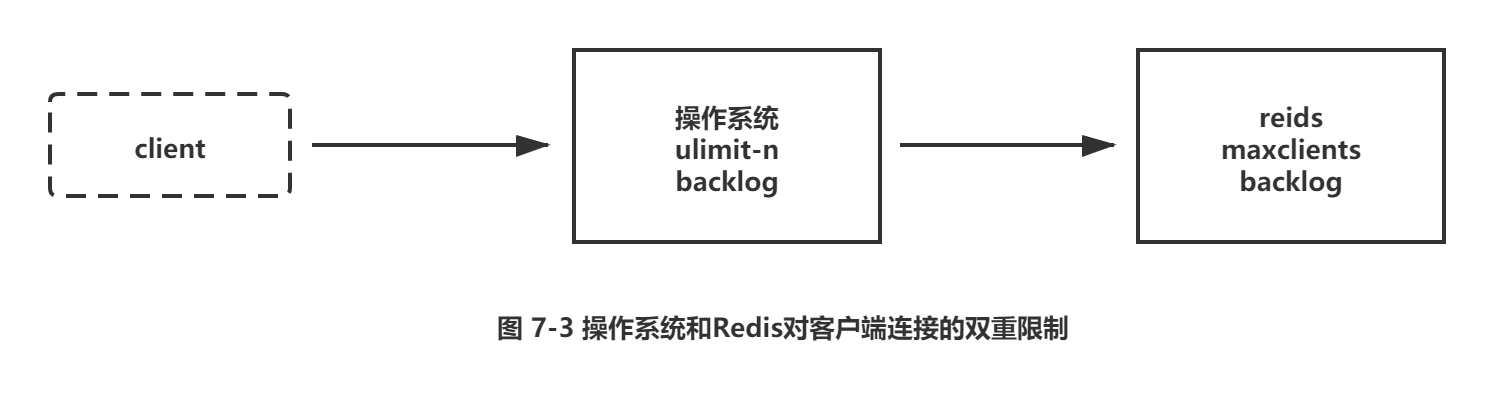
操作系统一般会对进程使用的资源做限制,其中一项是对进程可打开最大文件数控制,通过ulimit -n 查看,通常默认1024。由于Linux系统对TCP连接也定义为一个文件句柄,因此对于支撑大量连接的Redis来说需要增大这个值,如设置ulimit -n 65535,防止Too many open files错误。
(2) backlog队列溢出
系统对于特定端口的TCP连接使用backlog队列保存。Redis默认的长度为511,通过tcp-backlog参数设置。如果Redis用于高并发场景为了防止缓慢连接占用,可适当增大这个设置,但必须大于操作系统允许值才能生效。当Redis启动时如果tcp-backlog设置大于系统允许值将以系统值为准,Redis打印如下警告日志:
# WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
系统的backlog 默认值为128,使用 echo 511 > /proc/sys/net/core/somaxconn命令进行修改。可以通过netstat -s 命令获取因back log队列溢出造成的连接拒绝统计,如下:
# netstat -s 丨 grep overflowed
663 times the listen queue of a socket overflowed
如果怀疑是backlog队列溢出,线上可以使用cron定时执行netstat -s | grep overflowed统计,查看是否有持续增长的连接拒绝情况。
2.网络延迟
网络延迟取决于客户端到Redis服务器之间的网络环境。主要包括它们之间的物理拓扑和带宽占用情况。常见的物理拓扑按网络延迟由快到慢可分为:同物理机 > 同机架 > 跨机架>同机房> 同城机房>异地机房。但它们容灾性正好相反,同物理机容灾性最低而异地机房容灾性最高。Redis提供了测量机器之间网络延迟的工具,在 redis-cli -h {host} -p {port}命令后面加人如下参数进行延迟测试:
□ --latency: 持续进行延迟测试,分别统计:最小值、最大值、平均值、采样次数。
□ --latency-history:统计结果同--latency,但默认每15秒完成一行统计,可通过-i参数控制采样时间。
□ --latency-dist: 使用统计图的形式展示延迟统计,每 1秒采样一次。
网络延迟问题经常出现在跨机房的部署结构上,对于机房之间延迟比较严重的场景需要调整拓扑结构,如把客户端和Redis部署在同机房或同城机房等。
带宽瓶颈通常出现在以下几个方面:
□ 机器网卡带宽。
□ 机架交换机带宽。
□ 机房之间专线带宽。
带宽占用主要根据当时使用率是否达到瓶颈有关,如频繁操作Redis的大对象对于千兆网卡的机器很容易达到网卡瓶颈,因此需要重点监控机器流量,及时发现网卡打满产生的网络延迟或通信中断等情况,而机房专线和交换机带宽一般由上层运维监控支持,通常出现瓶颈的概率较小。
3.网卡软中断
网卡软中断是指由于单个网卡队列只能使用一个CPU,高并发下网卡数据交互都集中在同一个CPU,导致无法充分利用多核CPU的情况。网卡软中断瓶颈一般出现在网络高流量吞吐的场景,如下使用“top + 数字1”命令可以很明显看到CPU1 的软中断指标(si)过高:
# top
Cpu0: 15.3%us, 0.3%sy,0.0%ni, 84.4%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu1 : 16.6%us, 2.0%sy,0.0%ni, 47.1%id, 3.3%wa, 0.0%hi, 31.0%si, 0.0%st
Cpu2 : 13.3%us, 0.7%sy,0.0%ni, 86.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu3 : 14.3%us, 1.7%sy,0.0%ni, 82.4%id, 1.0%wa, 0.0%hi, 0.7%si, 0.0%st
Cpul5 : 10.3%us, 8.0%sy,0.0%ni, 78.7%id, 1.7%wa, 0.3%hi, 1.0%si, 0.0%st
Linux在内核2.6.35以后支持Receive Packet Steering ( RPS),实现了在软件层面模拟硬件的多队列网卡功能。如何配置多CPU分摊软中断已超出范畴,具体配置见Torvalds的 GitHub 文档:https://github.com/torvalds/linux/blob/master/Documentation/networking/scaling.txt。
4.总结
1. 客户端最先感知阻塞等Redis超时行为,加入日志监控报警工具可快速定位阻塞问题,同时需要对Redis进程和机器做全面监控。
2. 阻塞的内在原因:确认主线程是否存在阻塞,检查慢查询等信息,发现不合理使用API或数据结构的情况,如 keys、sort、hgetall等。关注CPU使用率防止单核跑满。当硬盘IO资源紧张时,AOF追加也会阻塞主线程。
3. 阻塞的外在原因:从CPU竞争、内存交换、网络问题等方面入手排查是否因为系统层面问题引起阻塞。
Redis之阻塞分析的更多相关文章
- Redis时延问题分析及应对
Redis时延问题分析及应对 Redis的事件循环在一个线程中处理,作为一个单线程程序,重要的是要保证事件处理的时延短,这样,事件循环中的后续任务才不会阻塞: 当redis的数据量达到一定级别后(比如 ...
- Redis事务的分析及改进
Redis事务的分析及改进 Redis的事务特性 数据ACID特性满足了几条? 为了保持简单,redis事务保证了其中的一致性和隔离性: 不满足原子性和持久性: 原子性 redis事务在执行的中途遇到 ...
- MongoDB、Hbase、Redis等NoSQL分析
NoSQL的四大种类 NoSQL数据库在整个数据库领域的江湖地位已经不言而喻.在大数据时代,虽然RDBMS很优秀,但是面对快速增长的数据规模和日渐复杂的数据模型,RDBMS渐渐力不从心,无法应对很多数 ...
- Redis源码分析:serverCron - redis源码笔记
[redis源码分析]http://blog.csdn.net/column/details/redis-source.html Redis源代码重要目录 dict.c:也是很重要的两个文件,主要 ...
- Redis内部阻塞式操作有哪些?
Redis实例在运行的时候,要和许多对象进行交互,这些不同的交互对象会有不同的操作.下面我们来看看,这些不同的交互对象以及相应的主要操作有哪些. 客户端:键值对的增删改查操作. 磁盘:生成RDB快照. ...
- ELK_elk+redis 搭建日志分析平台
这个是最新的elk+redis搭建日志分析平台,今年时间是2015年9月11日. Elk分别为 elasticsearch,logstash, kibana 官网为:https://www.elast ...
- linux下利用elk+redis 搭建日志分析平台教程
linux下利用elk+redis 搭建日志分析平台教程 http://www.alliedjeep.com/18084.htm elk 日志分析+redis数据库可以创建一个不错的日志分析平台了 ...
- redis超时问题分析
redis超时问题分析 06/04. 2014 Redis在分布式应用中占据着越来越重要的地位,短短的几万行代码,实现了一个高性能的数据存储服务.最近dump中心的cm8集群出现过 几次redis超时 ...
- Redis事务原理分析
Redis事务原理分析 基本应用 在Redis的事务里面,采用的是乐观锁,主要是为了提高性能,减少客户端的等待.由几个命令构成:WATCH, UNWATCH, MULTI, EXEC, DISCARD ...
随机推荐
- [bug] logback error FileNotFoundException
问题 在gitee上下载的项目,运行报错 原因 原程序中设置了日志保存路径,我的电脑没有,需要手动创建 参考 https://blog.csdn.net/danchaofan0534/article/ ...
- 使用 MegaCLI 检测磁盘状态并更换磁盘
专栏首页阿dai_linux使用 MegaCLI 检测磁盘状态并更换磁盘 原 10
- ssh无法启动 (code=exited, status=255)
ssh无法启动 (code=exited, status=255) 2019年1月30日ssh 服务器运行了一些脚本后,突然发现无法ssh了. root@X61T:/home/liang# servi ...
- VMware vCenter重置web console SSO登录密码
On a Windows Platform Services Controller or vCenter Server with Embedded Platform Services Controll ...
- Flume 常用配置项
注:以下配置项均为常见配置项,查询详细配置项可以访问 flume 官网 Source 常见配置项 Avro Source 配置项名称 默认值 描述 Channel – type – 组件类型名称,必须 ...
- shell进阶之tree、pstree、lsof命令详解
一.tree命令详解: 主要功能是创建文件列表,将所有文件以树的形式列出来 -a 显示所有文件和目录. -A 使用ASNI绘图字符显示树状图而非以ASCII字符组合. -C 在文件和目录清单加上色彩, ...
- Java 值类型和引用类型
现实世界中的值和引用 假定你在读一份非常棒的东西,希望一个朋友也去读它.为了避免被人投诉支持盗版,进一步假定它是公共领域中的一份文档.那么,需要为朋友提供什么才能让他读到文档呢? 这完全取决于阅读的内 ...
- 1.5linux用户权限相关命令
用户权限相关命令 目标 用户 和 权限 的基本概念 用户管理 终端命令 组管理 终端命令 修改权限 终端命令 01. 用户 和 权限 的基本概念 1.1 基本概念 用户 是 Linux 系统工作中重要 ...
- 10.13 nc:多功能网络工具
nc命令 是一个简单.可靠.强大的网络工具,它可以建立TCP连接,发送UDP数据包,监听任意的TCP和UDP端口,进行端口扫描,处理IPv4和IPv6数据包. 如果系统没有nc命令,那么可以手 ...
- 小程序webview涉及的支付能力、选用绑定多商户支付
小程序webview涉及的支付能力.选用绑定多商户支付 webview承接页面涉及的支付能力: 仅支持小程序本身支付能力,不支持承接页面内的原支付功能(譬如,webview中嵌入了h5官方商城,经过配 ...