zookeeper之二:zookeeper3.7.0安装过程实操
前面分享了zookeeper的基本知识,下面分享有关zookeeper安装的知识。
1、下载
zookeeper的官网是:https://zookeeper.apache.org/
在官网上找到下载链接,
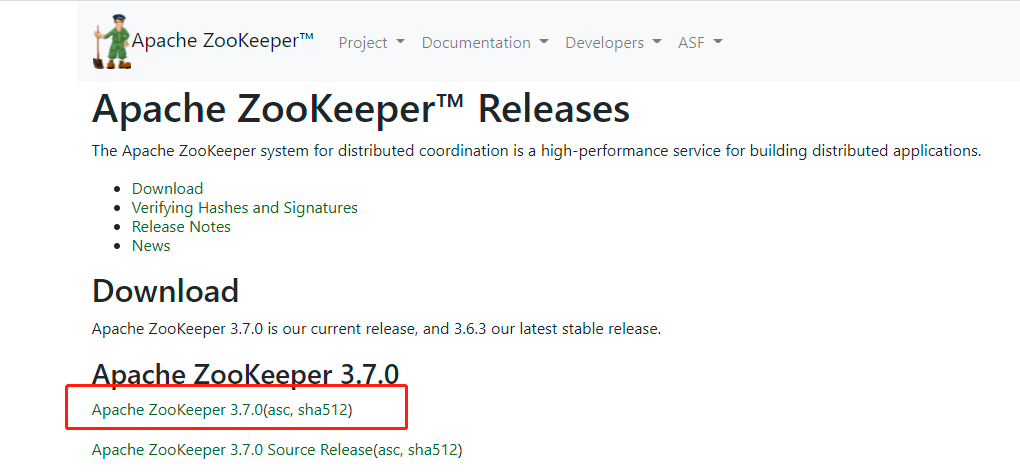
这里使用的是二进制安装包,使用的是3.7.0的版本。
2、安装
2.1、环境
os:我这里是在虚拟机环境中的centos7-64进行安装。
JDK:zookeeper需要JDK的支持,需要事先配置好java的环境变量。
2.2、安装
zookeeper的安装可以分为单机版和集群版,单机版是只有一个节点,集群版使用三个节点。
2.2.1、单机版
2.2.1.1、修改配置
单机版是只有一个节点的zookeeper进程,把下载好的安装包上传到对应得linux服务器目录上,对文件进行解压,解压后的文件如下,
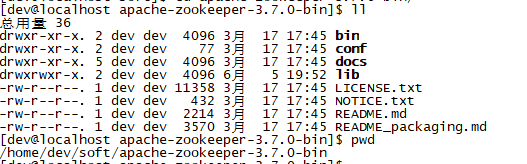
这里有两个比较重要的目录bin和conf,bin目录存放的是zookeeper启动脚本,conf下存放的是配置文件。首先修改配置文件,在conf下有三个文件,

zoo_sample.cfg是一个样例文件,zookeeper启动的时候默认使用的是zoo.cfg,这里从zoo_sample.cfg复制一个名为zoo.cfg即可,然后修改zoo.cfg文件,整个zoo.cfg文件是这样的
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
#http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1 ## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
我这里仅修改了下面的配置,
dataDir=/home/dev/datas/zookeeper3.7.0/single
2.2.1.2、启动
在zookeeper的目录下,执行下面的命令
bin/zkServer.sh start
看到下面的内容,说明已经启动成功

2.2.2、集群版
2.2.2.1、修改配置
由于我这里没有多余的物理机,所以在一台虚拟机上部署多个zk进程,配置如下,
| 地址 | myid | 对外端口 | 通信端口 | 选举端口 | dataDir |
| 本机 | 1 | 2182 | 2382 | 2482 |
/home/dev/datas/zookeeper3.7.0/cluster/node1 |
| 本机 | 2 | 2183 | 2383 | 2483 |
/home/dev/datas/zookeeper3.7.0/cluster/node2 |
| 本机 | 3 | 2184 | 2384 | 2484 |
/home/dev/datas/zookeeper3.7.0/cluster/node3 |
有了上面的配置,只需要在conf文件夹下,分别创建3个配置文件夹,然后放置zoo.cfg文件即可,分别按照上面的配置进行修改,在启动的时候分别制定不同的配置文件,

然后分别修改node1、node2、node3中的zoo.cfg文件,修改的配置项如下,node1
dataDir=/home/dev/datas/zookeeper3.7.0/cluster/node1
clientPort=2182
initLimit=5
syncLimit=2
server.1=127.0.0.1:2382:2482
server.2=127.0.0.1:2383:2483
server.3=127.0.0.1:2384:2484
node2
dataDir=/home/dev/datas/zookeeper3.7.0/cluster/node2
clientPort=2183
initLimit=5
syncLimit=2
server.1=127.0.0.1:2382:2482
server.2=127.0.0.1:2383:2483
server.3=127.0.0.1:2384:2484
node3
dataDir=/home/dev/datas/zookeeper3.7.0/cluster/node3
clientPort=2184
initLimit=5
syncLimit=2
server.1=127.0.0.1:2382:2482
server.2=127.0.0.1:2383:2483
server.3=127.0.0.1:2384:2484
之后再dataDir目录下还要建立一个myid的文本文件,文件的内容分别为node1下为1、node2下为2、node3下为3
2.2.2.2、启动
经过了上面对集群模式下的配置,下面启动集群中的3个节点,方式如下
bin/zkServer.sh --config conf/node1 start
看下面的图片,

按照上面的方式分别启动node1、node2、node3节点。
3、测试
上面,我们分别使用单机版和集群版按照了zookeeper,那么怎么测试是否安装成功
3.1、单机版
在单机版下,如果没有改端口直接使用即可,
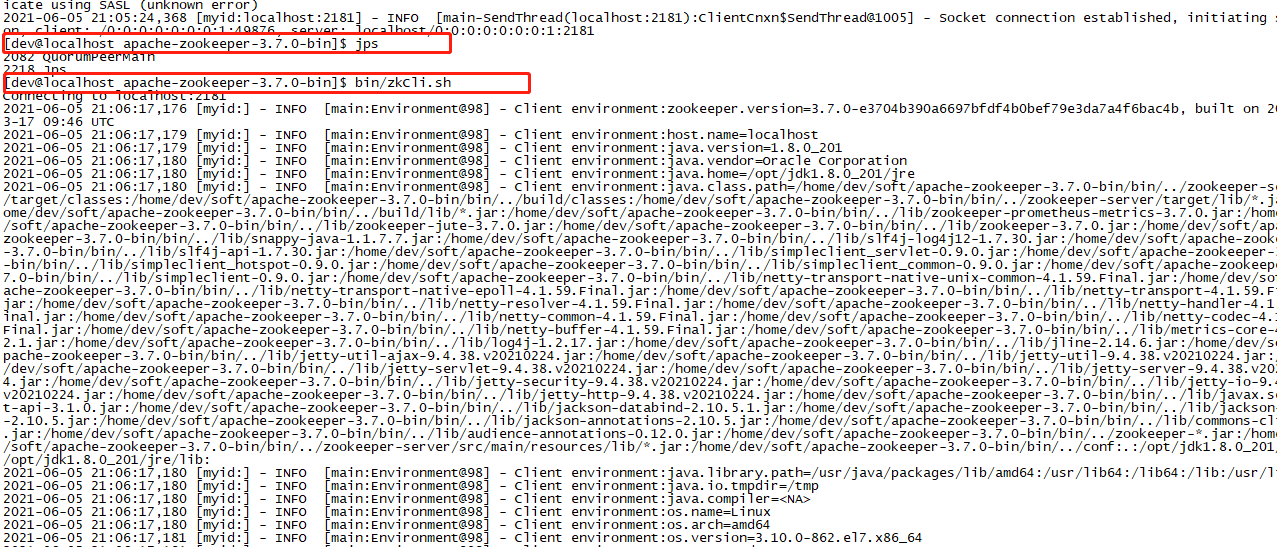
bin/zkCli.sh
出现下面的画面说明启动成功
3.2、集群版
3.2.1、验证单节点是否启动成功
在集群模式下,由于没有使用默认的端口,这里需要使用下面的命令,
#登录node3节点
bin/zkCli.sh -server 127.0.0.1:2183

3.2.2、验证集群是否正常同步数据
对于集群测试,还可以在node1上新建目录,然后在node3上检查是否存在该目录
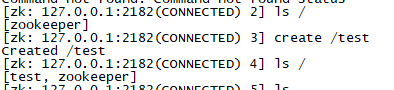
看node3下的目录
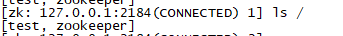
这样就可以看出zookeeper集群是正常的。
3.2.3、验证集群状态
可以通过查看集群的命令查看整个集群的状态
bin/zkServer.sh --config conf/node1 status

看下node2的状态

以上几种方式说明zookeeper集群正常。
有不正之处,欢迎指正。参考:
https://blog.csdn.net/dandandeshangni/article/details/80558383
https://www.cnblogs.com/8899man/p/5710191.html

zookeeper之二:zookeeper3.7.0安装过程实操的更多相关文章
- VMware VCSA 6.0安装过程 (转)
VMware VCSA 6.0安装过程(专版) 一.环境准备 VMware vCenter Server Appliance(VCSA)6.0的部署和之前的版本不同,在5.5及之前的版本可以通过 ...
- Oracle Data Integrator 12cR1 (12.1.3.0.0)安装过程
Oracle Data Integrator 12cR1 (12.1.3.0.0)安装过程 下载安装文件 Oracle Data Integrator 12cR1 (12.1.3.0.0) http: ...
- Nebula 2.5.0安装过程及遇到的坑
2021年8月23日,Nebula 发布了最新版本:2.5.0,正好赶上新环境部署,记录一下安装过程及遇到的坑: 一.准备工作 以下安装使用nebula用户,搭建集群模式,一共三台机器:192.168 ...
- VMware workstation16 中Centos7下MySQL8.0安装过程+Navicat远程连接
1.MySQL yum源安装 2.安装后,首次登录mysql以及密码配置3.远程登录问题(Navicat15为例) 一.CentOS7+MySQL8.0,yum源安装1.安装mysql前应卸载原有my ...
- Mysql 6.0安装过程(截图放不上去)
由于免费,MySQL数据库在项目中用的越来越广泛,而且它的安全性能也特别高,不亚于oracle这样的大型数据库软件.可以简单的说,在一些中小型的项目中,使用MySQL ,PostgreSQL是最佳 ...
- 百度NLP预训练模型ERNIE2.0最强实操课程来袭!【附教程】
2019年3月,百度正式发布NLP模型ERNIE,其在中文任务中全面超越BERT一度引发业界广泛关注和探讨.经过短短几个月时间,百度ERNIE再升级,发布持续学习的语义理解框架ERNIE 2.0,及基 ...
- GitBook安装部署实操手册
前言 GitBook是一个基于Node.js的命令行工具,可使用Git和Markdown来编写文档,赞誉太多,不再赘述. Node.js 下载安装包 cd /tmp wget https://node ...
- Hadoop2.2.0安装过程记录
1 安装环境1.1 客户端1.2 服务端1.3 安装准备 2 操作系统安装2.1.1 BIOS打开虚拟化支持2.1.2 关闭防火墙2.1.3 安装 ...
- 【Zookeeper学习】Zookeeper-3.4.6安装部署
[时间]2014年11月19日 [平台]Centos 6.5 [工具] [软件]jdk-7u67-linux-x64.rpm zookeeper-3.4.6.tar.gz [步骤] 1. 准备条件 ( ...
随机推荐
- 【ElasticSearch】文档路由的原理
ElasticSearch集群环境下新增文档如何确认该文档被分配到哪个分片中? 路由算法: ⾸先这肯定不会是随机的,否则将来要获取⽂档的时候我们就不知道从何处寻找了.实际上,这个过程是根据下⾯这个公式 ...
- 【JVM】空间分配担保机制
抛几个问题: 1.谁进行空间担保? JVM使用分代收集算法,将堆内存划分为年轻代和老年代,两块内存分别采用不同的垃圾回收算法,空间担保指的是老年代进行空间分配担保 2.什么是空间分配担保? 在发生Mi ...
- hdu4494
题意: 给你一些任务,每个任务有自己的开始时间和需要多久能干完,还有就是每个任务都需要一些人,这些人有最多五个种类,各种类之间的人不能相互替换,但是某些工人干完这个活后如果可以在另一个任务 ...
- C#中的元组(Tuple)和结构体(struct)
在正常的函数调用中,一个函数只能返回一个类型的值,但在某些特殊情况下,我们可能需要一个方法返回多个类型的值,除了通过ref,out或者泛型集合可以实现这种需求外,今天,讲一下元组和结构体在这一方面的应 ...
- Java安全之Fastjson反序列化漏洞分析
Java安全之Fastjson反序列化漏洞分析 首发:先知论坛 0x00 前言 在前面的RMI和JNDI注入学习里面为本次的Fastjson打了一个比较好的基础.利于后面的漏洞分析. 0x01 Fas ...
- class的大小
3个问题: sizeof一个空类是多大?为什么?编译器为什么这么做? 在这个类中添加一个virtual函数后再sizeof,这时是多大?为什么? 将这个类再virtual继承一个其它的空类,这是多大? ...
- input type
input的type有: text 文本输入 password密码输入 file选择文件 radio单选按钮 checkbox复选按钮 submit对应form的action按钮 button 普通按 ...
- docker容器与容器的关联
可以通过docker run -it -d --link 容器id 镜像id 方式关联 例如,将springboot项目容器与mysql容器相互关联,让springboot容器可以访问到mysql ...
- Docker------阿里云部署私有镜像仓库
Docker------阿里云部署私有镜像仓库 前言 公共镜像仓库 官方:https://hub.docker.com/ 基于各个软件开发或者软件提供方开发的 非官方:其它组织或公司开发的镜像,供 ...
- Unix下 压缩和解压缩命令
范例: .tar 解包:tar -xvf FileName.tar 打包:tar -cvf FileName.tar DirName (注:tar是打包,不是压缩!) ---------------- ...