大数据学习day11------hbase_day01----1. zk的监控机制,2动态感知服务上下线案例 3.HDFS-HA的高可用基本的工作原理 4. HDFS-HA的配置详解 5. HBASE(简介,安装,shell客户端,java客户端)
1. ZK的监控机制
1.1 监听数据的变化
(1)监听一次
public class ChangeDataWacher {
public static void main(String[] args) throws Exception {
// 连接并获取zk客户端的对象
ZooKeeper zk = new ZooKeeper("feng01:2181,feng02:2181,feng03:2181", 2000, null);
zk.getData("/user", new Watcher() {
// 当事件触发时会执行这个方法
@Override
public void process(WatchedEvent event) {
System.out.println("事件的类型:"+"路径"+event.getPath());
}
}, null);
Thread.sleep(Integer.MAX_VALUE);
}
}
当在服务器上set /user hang(改变节点数据)会出现如下变化(只能监听一次,再次改变节点数据,监听不到)

(2)多次监听
public class ChangeDataWacher {
public static void main(String[] args) throws Exception {
// 连接并获取zk客户端的对象
ZooKeeper zk = new ZooKeeper("feng01:2181,feng02:2181,feng03:2181", 2000, null);
zk.getData("/user", new Watcher() {
// 当事件触发时会执行这个方法
@Override
public void process(WatchedEvent event) {
try {
System.out.println("事件的类型:"+"路径"+event.getPath());
byte[] data = zk.getData("/user", this, null);
System.out.println(new String(data));
} catch (KeeperException | InterruptedException e) {
e.printStackTrace();
}
}
}, null);
Thread.sleep(Integer.MAX_VALUE);
}
}
1.2 监听节点的变化(getChildren)
public class ChangeNodeWacher {
public static void main(String[] args) throws Exception {
// 连接并获取zk客户端对象
ZooKeeper zk = new ZooKeeper("feng01:2181,feng02:2181,feng03:2181", 2000, null);
zk.getChildren("/user", new Watcher() {
// 当事件触发时,会执行此方法
@Override
public void process(WatchedEvent event) {
System.out.println("事件的类型是:"+event.getType()+"路径"+event.getPath());
try {
List<String> children = zk.getChildren("/user",this, null);
for (String node : children) {
System.out.println(node);
}
} catch (KeeperException | InterruptedException e) {
e.printStackTrace();
}
}
}, null);
Thread.sleep(Integer.MAX_VALUE);
}
}
当在zookeeper服务端增删节点时,如下

会出现如下监听情况

2. 动态感知服务上下线案例
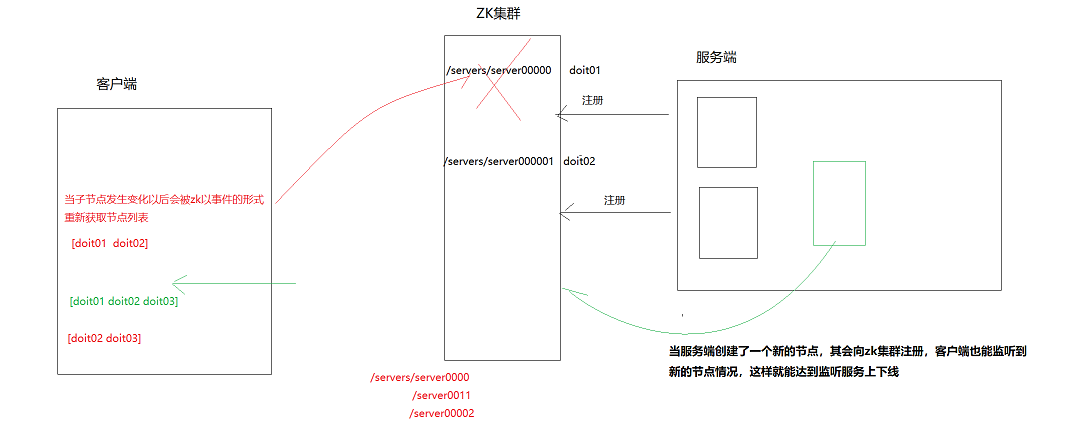
分布式服务端:
public class DistributeServer {
ZooKeeper zk = null;
// 所有server节点的父节点,要监控的节点
String parentPath = "/servers" ;
/**
* 初始化zk客户端对象
* @throws Exception
*/
public void init() throws Exception{
zk = new ZooKeeper("feng01:2181,feng02:2181,feng03:2181", 2000, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("zk客户端连接成功");
}
});
}
/**
* 向zk集群注册服务
* @param hostName
* @throws Exception
* @throws InterruptedException
*/
public void registerServer(String hostName) throws Exception, InterruptedException {
zk.create(parentPath+"/server", hostName.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT_SEQUENTIAL);
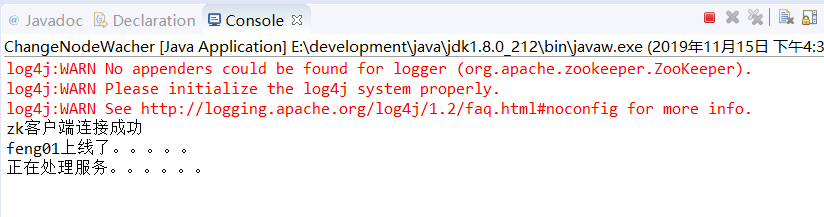
System.out.println(hostName+"上线了。。。。。");
}
/**
* 正在进行的服务任务
* @throws Exception
*/
public void service() throws Exception {
System.out.println("正在处理服务。。。。。。");
Thread.sleep(Integer.MAX_VALUE);
}
public static void main(String[] args) throws Exception {
DistributeServer ds = new DistributeServer() ;
ds.init();
ds.registerServer(args[0]);
ds.service();
}
}
运行Run as----->Run Configuration。。。。(输入参数feng01),运行结果如下:
分布式客户端
public class DistributeClient {
ZooKeeper zk = null;
String parentPath = "/servers" ;
/**
* 初始化zk客户端对象
* @throws Exception
*/
public void init() throws Exception {
zk = new ZooKeeper("feng01:2181,feng02:2181,feng03:2181", 2000, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("zk客户端连接成功");
}
});
}
public void getHost() throws Exception, InterruptedException {
zk.getChildren(parentPath, new Watcher() {
@Override
public void process(WatchedEvent event) {
List<String> list = new ArrayList<>();
try {
// 当节点发生变化时,重新获取子节点,并将子节点的值放入list
List<String> children = zk.getChildren(parentPath, this);
for (String node : children) {
byte[] data = zk.getData(parentPath+"/"+node, null, null);
list.add(new String(data));
}
// 获取子节点的值
System.out.println("正在服务的机器有:"+list);
} catch (KeeperException | InterruptedException e) {
e.printStackTrace();
}
}
});
Thread.sleep(Integer.MAX_VALUE);
}
public static void main(String[] args) throws Exception {
DistributeClient client = new DistributeClient();
client.init();
client.getHost();
}
}
3.hdp的高可用基本原理的工作流程
原理图
可看博客 https://www.cnblogs.com/zsql/p/11560372.html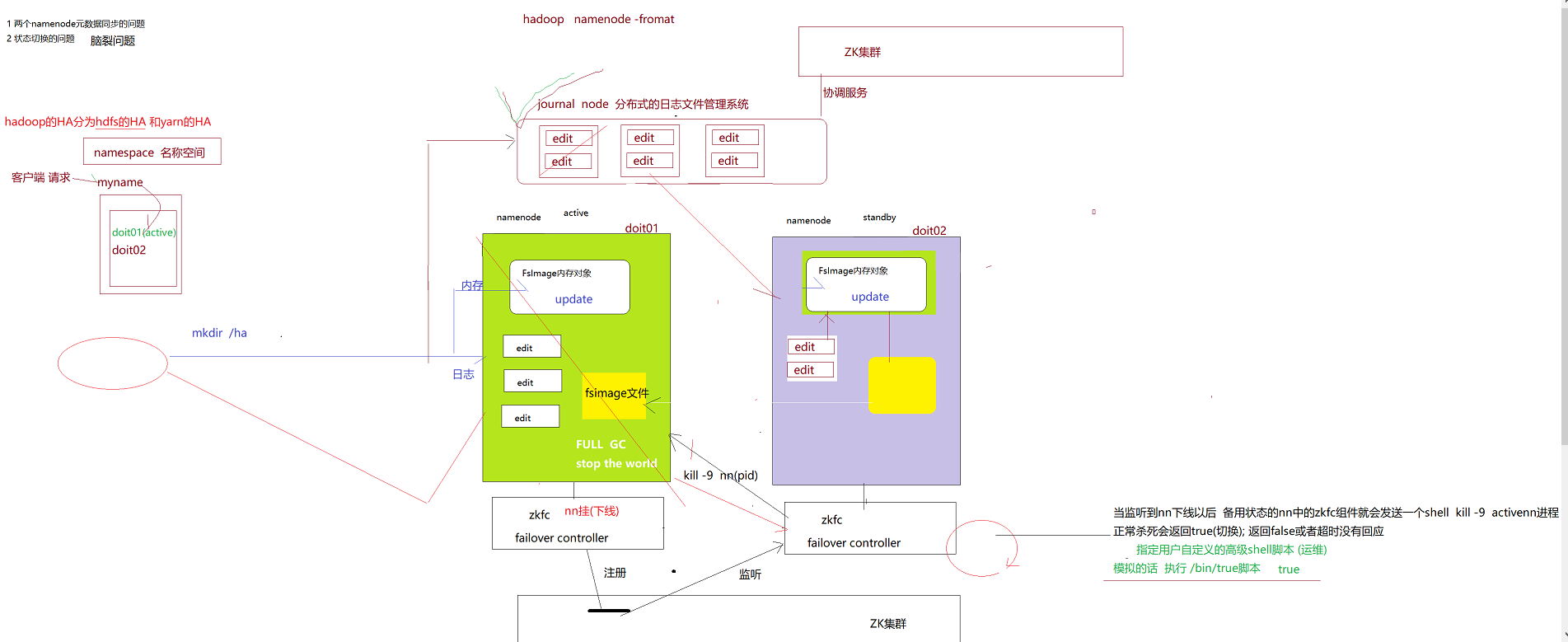
在hadoop2.0中(在2.0以下是由一个namenode)通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步active namenode的状态,以便能够在它失败时快速进行切换。
namenode是整个hdfs的核心,如果namenode出现单点故障了,那么整个hdfs文件系统也不能提供服务,所以hadoop2.x对hdfs提供了高可用的方案,即Hadoop HA。hdfs的高可用提供了两种方案,一种是基于QJM(Quorum Journal Manager)的,一种是基于NFS的,我们用的一般都是基于QJM的,所以这里也是讲基于QJM的高可用,高可用用来解决NameNode单点故障的问题。解决的方法是在HDFS集群中设置多个NameNode节点,但是多个namenode会产生如下问题:
(1)如何保证多个namenode的元数据一致
这里以两台namenode机器为例,一台状态为active(活跃状态),另一台为standby状态(备用状态)。DataNode只会将心跳信息和Block汇报信息发给活跃的NameNode。为了保证两个namenode的数据同步,hadoop中引入了journalNode(JN, 日志管理系统)。若是直接在活跃的namenode中记录日志文件,其就必须提供下载服务,供standby状态的namenode进行下载,然后进行信息的同步,但这样无疑增加了active状态的namenode的工作压力,所以就有了JN。为了防止JN出现单点故障问题,其也是一个集群,当客户端进行相关操作时(如mkdir),该操作就会被记录到该日志文件管理系统中,处于standby状态的datanode就会将之下载下来,下载得到日志信息会被FsImage对象读取并序列化得到image文件,同时该镜像(image)文件会被定期发送给active的namenode,从而实现两者的元数据一致
注意:有关JN
journal系统和namenode的本地磁盘都会记录日志信息,因为写journal是网络传输,而本地磁盘更快更安全。namenode重启时,加载本地日志回复元数据也更快,JN主要是为了提供一个可靠的元数据同步渠道,好让standby namenode囊在active namenode在挂掉后,也能成功取到元数据(standby只从JN中获取日志信息,原因主要是缓解namenode工作压力,如上所说)
(2)多个namenode如何进行状态切换(ZKFC)
ZKFC(zk Failover Controller)是一个新组件,它是一个ZooKeeper客户端,其能监视和管理NameNode的状态。运行NameNode的每台机器也运行ZKFC
- 运行状况监视 :
ZKFC定期使用运行状况检查命令对其本地NameNode进行ping操作。只要NameNode及时响应健康状态,ZKFC就认为该节点是健康的。如果节点已崩溃,冻结或以其他方式进入不健康状态,则运行状况监视器会将其标记为运行状况不佳。
- ZooKeeper会话管理 :
当本地NameNode运行正常时,ZKFC在ZooKeeper中保持会话打开。如果本地NameNode处于活动状态,它还拥有一个特殊的“锁定”znode。此锁使用ZooKeeper对“临时”节点的支持; 如果会话过期,将自动删除锁定节点。
- 基于ZooKeeper的选举 :
如果本地NameNode是健康的,并且ZKFC发现没有其他节点当前持有锁znode,它将自己尝试获取锁。如果成功,那么它“赢得了选举”,并负责运行故障转移以使其本地NameNode处于活动状态。故障转移过程类似于上述手动故障转移:首先,需对先前的活跃namenode进行隔离(防止出现脑裂的情况),然后本地NameNode转换为活动状态。
此处基于Zookeeper的选举需注意: 若将standby状态的namenode切换为活跃的namenode时,需要确保先前的活跃的namenode被杀死,在将standby状态的namenode切换为active前,其会向原先的机器发送kill 命令(kill -9 namenode(Pid)),确保原先活跃的namenode没在工作,否则两个namenode都处于活跃状态的话就会出现争抢共享资源的情况(脑裂)
4. HDFS-HA的配置详解
4.0 说明:
自己总共使用虚拟机创建了4台机器feng01,feng02,feng03,feng04,各个机器的组件有无如下表(下面自己只配置HDFS HA)
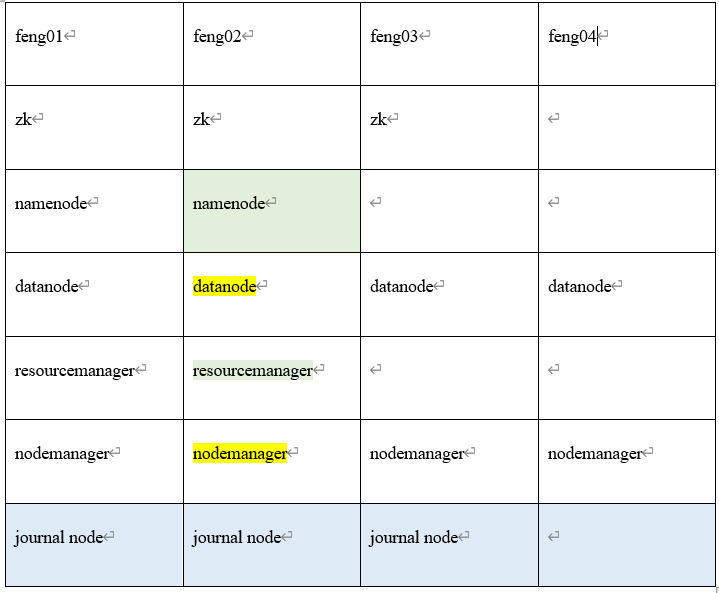
注意: Datanode和nodemanage尽量配置在同一台机器(Nodemanage是用来处理任务(Task)的,而Task是用来处理的数据的,若是nodemanage需要处理的数据就在本地的datamanage中,本地处理效率高)
4.1 前期准备(前面笔记有讲以下这些配置)
- linux主机名 域名映射
- ip配置 防火墙关闭
- 集群的免密配置
- 每个机器的免密配置
- zk集群正常启动
- hadoop的安装
4.2 修改hadoop中的core-site.xml文件
<configuration>
<!-- 指定hdfs的nameservice为doit11 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://doit11/</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/myha/hdpdata/</value>
</property> <!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>doit01:2181,doit02:2181,doit03:2181</value>
</property>
</configuration>
4.3 修改hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为doit11,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>doit11</value>
</property>
<!-- doit11下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.doit11</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.doit11.nn1</name>
<value>doit01:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.doit11.nn1</name>
<value>doit01:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.doit11.nn2</name>
<value>doit02:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.doit11.nn2</name>
<value>doit02:50070</value>
</property>
<!-- 指定NameNode的edits元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://doit01:8485;doit02:8485;doit03:8485/doit11</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/myha/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.doit11</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
4.4 将配置好的hadoop拷贝到其他节点中去
scp -r /usr/apps/hadoop-2.8.5 feng02:/usr/apps/
4.5 启动zookeeper集群
zkServer.sh start(分别在feng01,feng02,feng03上启动)
查看状态(zkServer.sh status):一个leader,两个follower
4.6 手动启动journalnode(分别在feng01,feng02,feng03)
hadoop-daemon.sh start journalnode
运行jps命令检验,feng01、feng02、feng03上多了JournalNode进程
4.7 格式化namenode
在feng01上执行命令:hdfs namenode -formatc
格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里自己配置的是/myha/hdpdata,同时将这个文件拷贝至另一台namenode机器上(feng02)
4.8 格式化ZKFC(在feng01上进行)
hdfs zkfc -formatZK
4.9 启动HDFS(在deng01上执行)
start-dfs.sh
到此为止HDFS HA就算配置完成了,接下来是验证配置是否成功
(1)访问http://feng01:50070,可得NameNode 'feng01:9000' (active)
访问http://feng02:50070 , 可得NameNode 'feng02:9000' (standby)
(2)向hdfs上传一个文件
hadoop fs -put /etc/profile /profile
(3)kill掉active的NameNode
(4)这个时候访问http://feng02:50070 ,会发现,namenode编程active。同时在hdfs的根目录下能发现profile文件
(5)手动启动刚才kill掉的namenode
hadoop-daemon.sh start namenode
(6)继续访问http://feng01:50070,可得NameNode 'feng01:9000' (standby)
这样就表示HDFS HA配置成功
5. Hbase(具体见HBASE教程)
5.1 简介
(1)mysql 关系型数据库等传统数据库有如下瓶颈
- 并发量有限, 当并发量大的时候,简单的单表查询就有可能很慢
- 存储的数据条数有限, 如果数据量非常大 查询很慢
(2)HBase是一个分布式数据库系统(在关系型和菲关系型数据库nosql之间),其特点是高可靠性、高性能、面向列、可伸缩
- 高可靠性:数据的可靠和服务(集群)的可靠性。原因:hbase4是基于HDFS存储数据的(hdfs会有多个数据副本)
- 高性能:在上亿条数据中查询结果控制在几十或者几百毫秒以内(分布式存储和分布式运算) , 将数据上亿条数据存储在不同的机器上 , 在查找额时候快速的找到元数据 找到对应的这条数据所在的机器节点 (快速定位)
- 可伸缩:存储的伸缩性 分布式的数据库系统 基于hdfs(横向扩容) 运算机器(为我们提供服务的机器可以添加或者减少)
(3)存储的方式:
本质:数据在磁盘中存储大量的key-value数据
一个完整的ket由三段组成:行键:列族名:列明(rowkey:columnFamily:qualifier),如下

RowKey:用来表示唯一一行记录的主键,HBase的数据是按照RowKey的字典顺序进行全局排序的,所有的查询都只能依赖于这一个排序维度。
Hbase中的数据没有类型约束的(所谓没有类型,其实就是byte[])
f 在物理上,hbase的这些key-value是按“完整key”的字典顺序有序存储的
(4)面向列,如下图
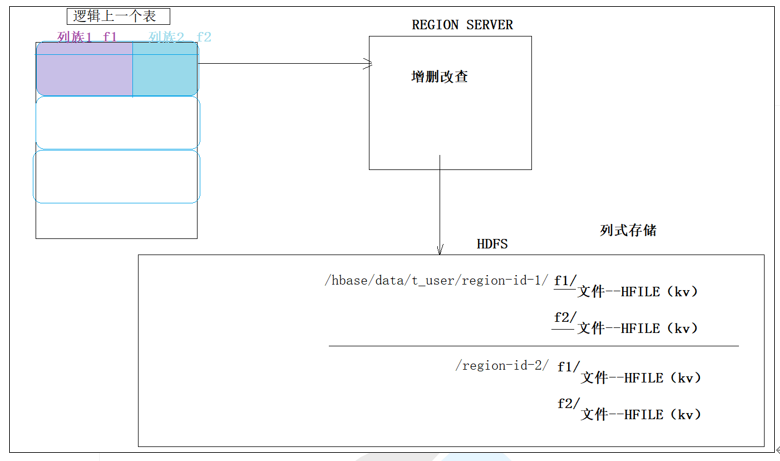
HBASE的物理数据存储是按列族分开存储的,所以hbase被称之为列式存储数据库。在对应的HDFS中,一张表对应一个文件夹,下面有表的列族的子文件夹(如上图的f1,f2)
注意:列族不要定的太多(若按region来查询数据的话,就需要跨多个子文件夹来查询数据),列族名尽可能短
5.2 安装
5.2.1 前提:
- HDFS可以启动
- zk集群启动
- 时间同步
(1)连接时间服务器,自动同步时间,需要安装ntpdata(yum -y install ntpdate.x86_64),安装前检查本地yum源(yum list | grep ntpdate)
连接时间服务器: ntpdate 0.asia.pool.ntp.org
(2)手动设置
date -s ‘2019-10-11 16:00:00’
5.2.2 安装过程:
(1)上传解压:
tar -zxvf hbase-2.0.4-bin.tar.gz -C /usr/apps/
(2)hbase配置
- 修改如下内容(vi /usr/apps/hbase-2.0.4/conf/hbase-env.sh)
export JAVA_HOME=/usr/apps/jdk1.8.0_141/
export HBASE_MANAGES_ZK=false // 表示禁用hbase自带的zk
- hbase-site.xml修改内容:
<configuration>
<!-- 指定hbase在HDFS上存储的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://linux01:9000/hbase</value>
</property>
<!-- 指定hbase是分布式的 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zk的地址,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>linux91:2181,linux02:2181,linux03:2181</value>
</property>
</configuration>
regionservers 配置,表示启动机器的regionserver的设置(注:通常应该将regionserver配置为datanode相同的server上以实现本地存储,提升性能)
linux01
linux02
linux03
(3)集群分发
scp -r hbase-2.0.4/ linux02:/usr/apps
scp -r hbase-2.0.4/ linux03:/usr/apps
(4)环境变量配置(vi /etc/profile)

(4)启动
- 启动方式一:
hbase-daemon.sh start master
hbase-daemon.sh start regionserver
- 启动方式:二:
start-hbase.sh 一键启动
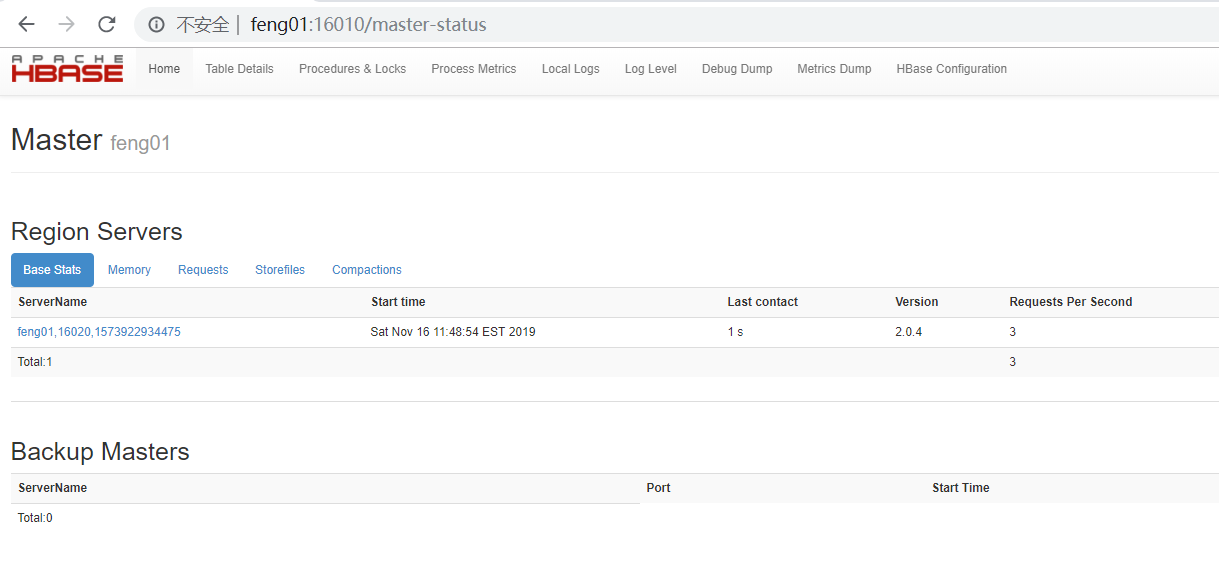
(5)页面访问
启动成功后,可以通过“host:port”的方式来访问HBase管理页面,例如:
5.3 shell客户端
见文档
5.4 java客户端
见文档
大数据学习day11------hbase_day01----1. zk的监控机制,2动态感知服务上下线案例 3.HDFS-HA的高可用基本的工作原理 4. HDFS-HA的配置详解 5. HBASE(简介,安装,shell客户端,java客户端)的更多相关文章
- logback常用配置详解及logback简介
logback 简介(一) Ceki Gülcü在Java日志领域世界知名.他创造了Log4J ,这个最早的Java日志框架即便在JRE内置日志功能的竞争下仍然非常流行.随后他又着手实现SLF4J 这 ...
- 大数据学习--day11(抽象类、接口、equals、compareTo)
抽象类.接口.equals.compareTo 什么是抽象方法 ? 区分于正常的方法 1.使用了 abstract 修饰符 该修饰符修饰方法 则该方法就是抽象方 ...
- 大数据学习——点击流日志每天都10T,在业务应用服务器上,需要准实时上传至(Hadoop HDFS)上
点击流日志每天都10T,在业务应用服务器上,需要准实时上传至(Hadoop HDFS)上 1需求说明 点击流日志每天都10T,在业务应用服务器上,需要准实时上传至(Hadoop HDFS)上 2需求分 ...
- Java从入门到精通——数据库篇Mongo DB 安装启动及配置详解
一.概述 Mongo DB 下载下来以后我们应该如何去安装启动和配置才能使用Mongo DB,本篇博客就给大家讲述一下Mongo DB的安装启动及配置详解. 二.安装 1.下载Mongo DB ...
- 基于 CentOS Mysql 安装与主从同步配置详解
CentOS Mysql 安装 Mysql (Master/Slave) 主从同步 1.为什么要使用主从同步 1.如果主服务器出现问题,可以快速切换到从服务器提供的服务 2.可以在从服务器上执行查询操 ...
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
- 大数据学习day31------spark11-------1. Redis的安装和启动,2 redis客户端 3.Redis的数据类型 4. kafka(安装和常用命令)5.kafka java客户端
1. Redis Redis是目前一个非常优秀的key-value存储系统(内存的NoSQL数据库).和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list ...
- 大数据学习(16)—— HBase环境搭建和基本操作
部署规划 HBase全称叫Hadoop Database,它的数据存储在HDFS上.我们的实验环境依然基于上个主题Hive的配置,参考大数据学习(11)-- Hive元数据服务模式搭建. 在此基础上, ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
随机推荐
- Go语言核心36讲(Go语言进阶技术十三)--学习笔记
19 | 错误处理(上) 提到 Go 语言中的错误处理,我们其实已经在前面接触过几次了. 比如,我们声明过error类型的变量err,也调用过errors包中的New函数. 我们说过error类型其实 ...
- 编译安装mysql和zabbix,xtrabackup数据库备份
xtrabackup参考文章 https://www.cnblogs.com/linuxk/p/9372990.html 下载5.7的mysql 社区版包 https://cdn.mysql.com/ ...
- 第40篇-JNIEnv和JavaVM
下面介绍2个与JNI机制相关的类型JNIEnv和JavaVM. 1.JNIEnv JNIEnv一般是是由虚拟机传入,而且与线程相关的变量,也就说线程A不能使用线程B的JNIEnv.而作为一个结构体,它 ...
- 学习JS的第四天
一.循环 1.循环嵌套 1.一个循环内包含完整的另一个循环语句. 2.被包含的循环语句叫内循环,包含别的循环的循环语句叫外循环. 3.外循环每执行一次循环,内循环都会完全执行所有循环次数. 4.循环嵌 ...
- grep命令详解与正则表达式
grep命令主要是做什么的呢 ?下面我们就来研究下. grep命令简单来说就是"过滤".就是把想看的数据通过grep过滤出来,把不想看的通过grep过滤掉. 它是一种强大的文本搜索 ...
- 设计模式学习-使用go实现适配器模式
适配器模式 定义 代码实现 优点 缺点 适用范围 代理.桥接.装饰器.适配器4种设计模式的区别 参考 适配器模式 定义 适配器模式的英文翻译是Adapter Design Pattern.顾名思义,这 ...
- GO语言数据结构之链表
链表是一种物理存储单元上非连续.非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的.链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成.每个结点包括两个部分: ...
- php 变量和数据类型
$ 定义变量: 变量来源数学是计算机语言中能存储计算结果或能表示值抽象概念.变量可以通过变量名访问.在指令式语言中,变量通常是可变的. php 中不需要任何关键字定义变量(赋值,跟Java不同,Jav ...
- CTF入门学习4->前端HTML基础
Web安全基础 02 前端开发-HTML基础 浏览器对于上网者来说是一种直观.可视化的呈现.服务器发送数据到客户端,客户端需要处理这些数据,互联网就造就了这种数据语言--HTML. 02-00 概述 ...
- Hi3516开发笔记(四):Hi3516虚拟机编译uboot、kernel、roofts和userdata以及分区表
若该文为原创文章,转载请注明原文出处本文章博客地址:https://hpzwl.blog.csdn.net/article/details/121572767红胖子(红模仿)的博文大全:开发技术集合( ...