Oracle之数据库浅谈
前言
1970年的6月,IBM 公司的研究员埃德加·考特 (Edgar Frank Codd) 在 Communications of ACM 上发表了那篇著名的《大型共享数据库数据的关系模型》(A Relational Model of Data for Large Shared Data Banks)的论文。这是数据库发展史上的一个转折。当时还是层次模型和网状模型的数据库产品在市场上占主要位置。所以从这篇论文开始,便拉开了关系型数据库(RDBMS)软件革命的序幕。
什么是数据?
我们生活的这个世界就是一个充满着数据的互联网世界,充斥着大量的数据。也可以说这个互联网世界就是数据世界。数据的来源有很多,比如:人的身份证号码、消费记录、姓名等等都是数据。
什么是数据库?
概念上讲数据库是以一定方式储存在一起、能与多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合,用户可以对文件中的数据进行创建(Create)、更新(Update)、读取(Retrieve)和删除(Delete)等操作,简称:“CURD”。简单来讲,数据库(Database)就是按照数据结构来组织、存储和管理数据的,建立在计算机存储设备上的仓库。它的存储空间很大,可以存放百万条、千万条、上亿条数据。
为什么要使用数据库?
可能有人会想:数据存在文件里不行吗,为什么非要存放在数据库里面。没错,一般的文件里面是可以存放数据,但是在文件中存放的数据有很多缺点(例如:数据的安全性、数据的永久性、数据的易查询性等都是问题)。面对着这么多的问题,数据库就诞生了,光看名字就知道它的功能就是用来存放数据的,它可以很好的保管数据(比如:能存档海量信息,历史数据随时都可查看、提高记录和检索信息的效率、减少重复工作,管理方便、数据库加密管理等等),所以,一般企业或是机构在存数据的时候都会用数据库来存储数据。
数据库如何分类?
数据库通常分为层次式数据库、网络式数据库和关系式数据库三种。而不同的数据库是按不同的数据结构来联系和组织的。在当今的互联网中,最常见的数据库模型主要是两种,即关系型数据库和非关系型数据库。
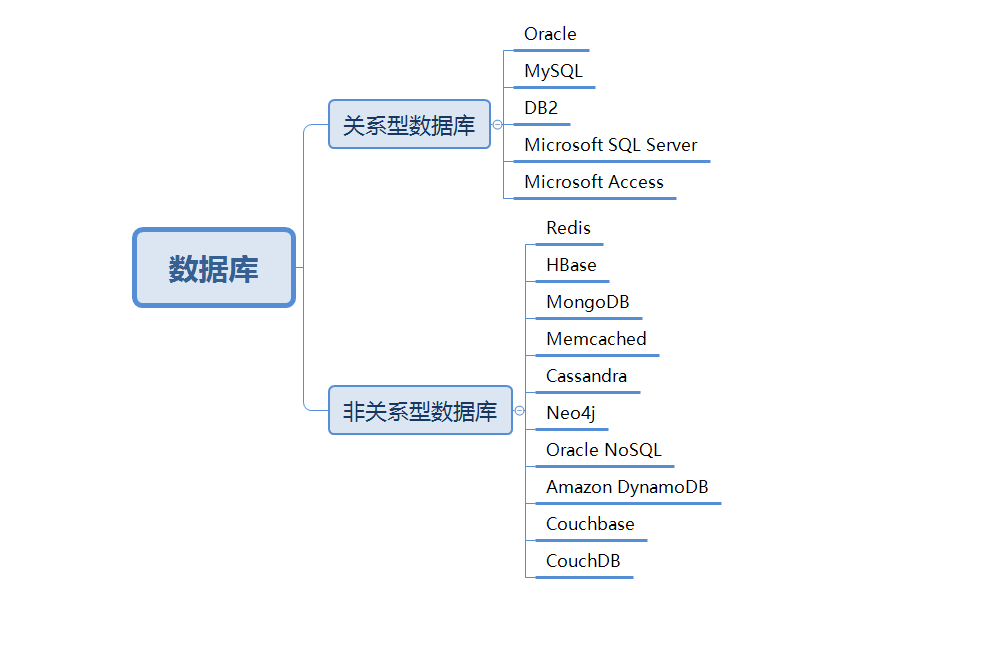
数据库的分类:
(1)关系型数据库(SQL):指数据存储的格式可以直观地反映实体之间的关系的数据存储系统。关系型数据库和常见的表格比较相似,关系型数据库中表与表之间是有很多复杂的关联关系的,关系型数据库遵循SQL(结构化查询语言,Structured Query Language)标准。 常见的主要操作有CURD、求和与排序等。关系型数据库对于结构化数据的处理更合适(例如:学生信息、考试成绩、地址等),这样的情况下,关系型数据库就会比NoSQL数据库性能更优,而且精确度更高。由于结构化数据的规模不算太大,数据规模的增长通常也是可预期的,所以针对结构化数据使用关系型数据库更好。关系型数据库十分注意数据操作的事务性、一致性,所以对此方面有要求的使用关系型数据库无疑是很好的选择。
常见主要代表:Oracle、MySQL、DB2、SQLServer。
(2)非关系型数据库(NoSQL):指的是分布式的、非关系型的、不保证遵循ACID原则的数据存储系统。NoSQL数据库技术与CAP理论(简单来说就是一个分布式系统不可能满足可用性、一致性与分区容错性这三个要求,一次性满足两种要求是该系统的上限)、一致性哈希算法(指的是NoSQL数据库在应用过程中,为满足工作需求而在通常情况下产生的一种数据算法)有密切关系。NoSQL数据库适合追求速度和可扩展性、业务多变的应用场景。对于非结构化数据的处理更合适,如文章、评论,这些数据如全文搜索、机器学习通常只用于模糊处理,并不需要像结构化数据一样,进行精确查询,而且这类数据的数据规模往往是海量的,数据规模的增长往往也是不可能预期的,而NoSQL数据库的扩展能力几乎也是无限的,所以NoSQL数据库可以很好的满足这一类数据的存储。NoSQL数据库利用key-value可以大量的获取大量的非结构化数据,并且数据的获取效率很高,但用它查询结构化数据效果就比较差。
常见主要代表:Redis、HBase、MongoDB、Memcached、Cassandra、Neo4j、Oracle NoSQL、Amazon DynamoDB、Couchbase、CouchDB
关系型数据库(SQL)与非关系型数据库(NoSQL)的区别:
存储方式不同:
关系型数据库采用表格的储存方式, 数据以行和列的方式进行存储,要读取和查询都十分方便。
非关系型数据不适合这样的表格存储方式,通常以数据集的方式,大量的数据集中存储在一起,类似于键值对、图结构或者文档。
存储结构不同:
关系型数据库按照结构化的方法存储数据, 每个数据表都必须对各个字段定义好(也就是先定义好表的结构,再根据表的结构存入数据),这样做的好处就是由于数据的形式和内容在存入数据之前就已经定义好了,所以整个数据表的可靠性和稳定性都比较高,但带来的问题就是一旦存入数据后,如果需要修改数据表的结构就会十分困难。
非关系型数据库由于面对的是大量非结构化的数据的存储,它采用的是动态结构,对于数据类型和结构的改变非常的适应,可以根据数据存储的需要灵活的改变数据库的结构。
存储规范不同:
关系型数据库为了避免重复、规范化数据以及充分利用好存储空间,把数据按照最小关系表的形式进行存储,这样数据管理的就可以变得很清晰、一目了然,当然这主要只是一张数据表的情况。如果是多张表情况就不一样了,因为这时的数据涉及到多张数据表。
非关系型数据库就像我们刚才说到的那样,对于非结构化数据的处理更合适,如文章、评论,这些数据不像关系型数据那样,每个都是唯一的、独立的,数据与数据之间不存在联系。所以在存储规范自然就不像关系数据那样需要很多规范。
扩展方式不同:
关系型数据库将数据存储在数据表中,数据操作的瓶颈出现在多张数据表的操作中,而且数据表越多这个问题越严重,如果要缓解这个问题,只能提高处理能力,也就是选择速度更快性能更高的计算机,这样的方法虽然可以一定的拓展空间,但这样的拓展空间一定有非常有限的,也就是关系型数据库只具备纵向扩展能力。
非关系型数据库由于使用的是数据集的存储方式,它的存储方式一定是分布式的,它可以采用横向的方式来开展数据库,也就是可以添加更多数据库服务器到资源池,然后由这些增加的服务器来负担数据量增加的开销。
查询方式不同:
关系型数据库采用结构化查询语言(SQL)来对数据库进行查询,SQL早已获得了各个数据库厂商的支持,成为数据库行业的标准,它能够支持数据库的CURD(增加,更新,查询,删除)操作,具有非常强大的功能,SQL可以采用类似索引的方法来加快查询操作。
非关系型数据库使用的是非结构化查询语言(NoSQL),它以数据集为单位来管理和操作数据,由于它没有一个统一的标准,所以每个数据库厂商提供产品标准是不一样的,NoSQL中的文档Id与关系型表中主键的概念类似,NoSQL数据库采用的数据访问模式相对SQL更简单而精确。
规范化:
在数据库的设计开发过程中开发人员通常会面对同时需要对一个或者多个数据实体(包括数组、列表和嵌套数据)进行操作,这样在关系型数据库中,一个数据实体一般首先要分割成多个部分,然后再对分割的部分进行规范化,规范化以后再分别存入到多张关系型数据表中,这是一个复杂的过程。但是目前有相当多的软件开发平台都提供一些简单的解决方法,例如:可以利用ORM层(也就是对象关系映射)来将数据库中对象模型映射到基于SQL的关系型数据库中去以及进行不同类型系统的数据之间的转换。对于NoSQL数据库则没有这方面的问题,它不需要规范化数据,它通常是在一个单独的存储单元中存入一个复杂的数据实体。
事务性:
关系型数据库强调ACID规则(原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)),可以满足对事务性要求较高或者需要进行复杂数据查询的数据操作,而且可以充分满足数据库操作的高性能和操作稳定性的要求。并且关系型数据库十分强调数据的强一致性,对于事务的操作有很好的支持。关系型数据库可以控制事务原子性细粒度,并且一旦操作有误或者有需要,可以马上回滚事务。
非关系型数据库强调BASE原则(基本可用(Basically Availble)、软状态(Soft-state)、最终一致性(Eventual Consistency)),它减少了对数据的强一致性支持,从而获得了基本一致性和柔性可靠性,并且利用以上的特性达到了高可靠性和高性能,最终达到了数据的最终一致性。NoSQL数据库虽然对于事务操作也可以使用,但由于它是一种基于节点的分布式数据库,对于事务的操作不能很好的支持,也很难满足其全部的需求,所以NoSQL数据库的性能和优点更多的体现在大数据的处理和数据库的扩展方面。
读写性能:
关系型数据库十分强调数据的一致性,并为此降低读写性能付出了巨大的代价,虽然关系型数据库存储数据和处理数据的可靠性很不错,但一旦面对海量数据的处理的时候效率就会变得很差,特别是遇到高并发读写的时候性能就会下降的非常厉害。
非关系型数据库相对关系型数据库优势最大的恰恰是应对大数据方面,也就是对于大量的每天都产生非结构化的数据能够高性能的读写,这是因为NoSQL数据库是按key-value类型进行存储的,以数据集的方式存储的,因此无论是扩展还是读写都非常容易,并且NoSQL数据库不需要关系型数据库繁琐的解析,所以NoSQL数据库大数据管理、检索、读写、分析以及可视化方面具有关系型数据库不可比拟的优势。
Oracle之数据库浅谈的更多相关文章
- 浅谈Oracle事务【转载竹沥半夏】
浅谈Oracle事务[转载竹沥半夏] 所谓事务,他是一个操作序列,这些操作要么都执行,要么都不执行,是一个不可分割的工作单元.通俗解释就是事务是把很多事情当成一件事情来完成,也就是大家都在一条船上,要 ...
- 数据库的编码浅谈(ZHS16GBK与US7ASCII)
数据库的编码浅谈(ZHS16GBK与US7ASCII) 2007-11-15 17:14:18 分类: Oracle SQL> SELECT RAWTOHEX('郭A军') from dual ...
- 浅谈一下SSI+Oracle框架的整合搭建
浅谈一下SSI+Oracle框架的整合搭建 最近换了一家公司,公司几乎所有的项目都采用的是Struts2+Spring+Ibatis+Oracle的架构,上一个东家一般用的就是JSF+Spring,所 ...
- 浅谈oracle树状结构层级查询之start with ....connect by prior、level及order by
浅谈oracle树状结构层级查询 oracle树状结构查询即层次递归查询,是sql语句经常用到的,在实际开发中组织结构实现及其层次化实现功能也是经常遇到的,虽然我是一个java程序开发者,我一直觉得只 ...
- 浅谈oracle树状结构层级查询测试数据
浅谈oracle树状结构层级查询 oracle树状结构查询即层次递归查询,是sql语句经常用到的,在实际开发中组织结构实现及其层次化实现功能也是经常遇到的,虽然我是一个java程序开发者,我一直觉得只 ...
- oracle树形结构层级查询之start with ....connect by prior、level、order by以及sys_connect_by_path之浅谈
浅谈oracle树状结构层级查询 oracle树状结构查询即层次递归查询,是sql语句经常用到的,在实际开发中组织结构实现及其层次化实现功能也是经常遇到的,虽然我是一个java程序开发者,我一直觉得只 ...
- 浅谈.net中数据库操作事务
.net中的事务 关键几点 概念:1:什么是事务 2:什么时候用事务 3:基本的语法 (1): 事务(Transaction)是访问并可能更新数据库中各种数据项的一个程序执行单元(unit).事务通常 ...
- Python 基于python+mysql浅谈redis缓存设计与数据库关联数据处理
基于python+mysql浅谈redis缓存设计与数据库关联数据处理 by:授客 QQ:1033553122 测试环境 redis-3.0.7 CentOS 6.5-x86_64 python 3 ...
- 重新学习MySQL数据库6:浅谈MySQL的中事务与锁
『浅入深出』MySQL 中事务的实现 在关系型数据库中,事务的重要性不言而喻,只要对数据库稍有了解的人都知道事务具有 ACID 四个基本属性,而我们不知道的可能就是数据库是如何实现这四个属性的:在这篇 ...
随机推荐
- golang中数组指针与指针数组的区别实现
指针数组和数组的指针,指的是两个不同的东西. 指针数组是有指针组成的数组,数组的指针是一个数组的指针. package main import "fmt" const MAX ...
- java多态成员变量、成员函数(非静态)、静态函数特点
1 package face_09; 2 3 /* 4 * 多态时, 5 * 成员的特点: 6 * 1,成员变量. 7 * 编译时:参考引用型变量所属类中的是否有调用的成员变量,有,编译通过:没有,编 ...
- 多线程-线程间通信-多生产者多消费者问题解决(notifyAll)
1 package multithread4; 2 3 /* 4 * 生产者,消费者. 5 * 6 * 多生产者,多消费者的问题. 7 * 8 * if判断标记,只有一次,会导致不该运行的线程运行了. ...
- Android开发----RecyclerView视图的学习
RecyclerView RecyclerView是什么? RecyclerView是如今Android开发中最常用的控件,其相较于ListView和GridView的功能更为强大,优化了两者的各种不 ...
- python函数关键字实参传参
#!/usr/bin/python #coding=utf-8 #好好学习,天天向上 def describe_pet(type,name): print(f"i have a {type} ...
- AQS源码一窥-JUC系列
AQS源码一窥 考虑到AQS的代码量较大,涉及信息量也较多,计划是先使用较常用的ReentrantLock使用代码对AQS源码进行一个分析,一窥内部实现,然后再全面分析完AQS,最后把以它为基础的同步 ...
- textarea自适应高(宽)度
转载请注明来源:https://www.cnblogs.com/hookjc/ 方法一: <textarea rows=1 cols=40 style='overflow:scroll;over ...
- Serializable接口中serialVersionUID字段的作用
序列化运行时使用一个称为 serialVersionUID 的版本号与每个可序列化类相关联,该序列号在反序列化过程中用于验证序列化对象的发送者和接收者是否为该对象加载了与序列化兼容的类. 如果接收者加 ...
- iOS App 架构文章推荐
iOS应用开发架构 iOS应用架构谈系列 阿里技术沙龙 2.2.1. Hybrid App 2.2.2. taobao 客户端架构 2.2.3. alipay 客户端架构 iOS APP 架构漫谈 ...
- JMeter使用流程
JMeter使用流程 首先我们要新建一个线程组,线程组的作用模拟多个访问对象,对系统可以进行压力测试 添加"HTTP Cookie管理器": 添加"Http请求默认值&q ...