Java:并发笔记-08
Java:并发笔记-08
7. 共享模型之工具-1
7.1 线程池
1. 自定义线程池
步骤1:自定义拒绝策略接口
// 拒绝策略
@FunctionalInterface
interface RejectPolicy<T>{
void reject(BlockingQueue<T> queue, T task);
}
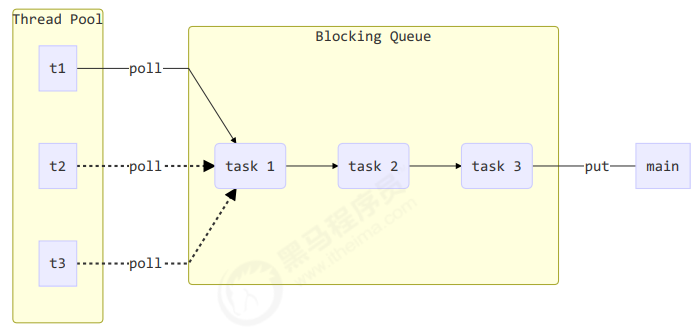
步骤2:自定义任务队列
// 自定义任务队列
class BlockingQueue<T>{
// 1. 任务队列
private Deque<T> queue = new ArrayDeque<>();
// 2. 锁
private ReentrantLock lock = new ReentrantLock();
// 3. 生产者条件变量--主线程生产任务
private Condition fullWaitSet = lock.newCondition();
// 4. 消费者条件变量--线程池中的线程消费任务
private Condition emptyWatiSet = lock.newCondition();
// 5. 容量
private int capacity;
public BlockingQueue(int capacity) {
this.capacity = capacity;
}
// 阻塞获取
public T take(){
lock.lock();
try {
while (queue.isEmpty()){
try {
// 当队列中没有任务时,则进入等待
emptyWatiSet.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 获取队列头部元素
T t = queue.removeFirst();
// 队列不满了,可以唤醒生产者线程往队列中添加线程
fullWaitSet.signal();
return t;
}finally {
lock.unlock();
}
}
// 带超时阻塞获取
public T poll(long timeout, TimeUnit unit){
lock.lock();
try {
// 将 timeout 统一转换为 纳秒
long nanos = unit.toNanos(timeout);
while (queue.isEmpty()){
try {
// 当队列中没有任务时,则进入等待
// 防止虚假唤醒
if(nanos <= 0){
return null;
}
// awaitNanos返回的是剩余时间
nanos = emptyWatiSet.awaitNanos(nanos);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 获取队列头部元素
T t = queue.removeFirst();
// 队列不满了,可以唤醒生产者线程往队列中添加线程
fullWaitSet.signal();
return t;
}finally {
lock.unlock();
}
}
// 阻塞添加
public void put(T task){
lock.lock();
try {
while (queue.size() == capacity){
// 当队列满时,进入等待,等待消费者消费线程
LoggerUtils.LOGGER.debug("等待加入任务队列 {} ...", task);
try {
fullWaitSet.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
LoggerUtils.LOGGER.debug("加入任务队列 {}", task);
queue.addLast(task);
// 队列中有任务了,唤醒消费者线程
emptyWatiSet.signal();
}finally {
lock.unlock();
}
}
// 带超时时间阻塞添加
public boolean offer(T task, long timeout, TimeUnit unit){
lock.lock();
try {
long nanos = unit.toNanos(timeout);
while (queue.size() == capacity){
// 当队列满时,进入等待,等待消费者消费线程
// 防止虚假唤醒
try {
if(nanos <= 0){
return false;
}
LoggerUtils.LOGGER.debug("等待加入任务队列 {} ...", task);
nanos = fullWaitSet.awaitNanos(nanos);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
LoggerUtils.LOGGER.debug("加入任务队列 {}", task);
queue.addLast(task);
// 队列中有任务了,唤醒消费者线程
emptyWatiSet.signal();
return true;
}finally {
lock.unlock();
}
}
public void tryPut(RejectPolicy<T> rejectPolicy, T task){
lock.lock();
try {
// 判断队列是否已满
if(queue.size() == capacity){
rejectPolicy.reject(this, task);
}else{
LoggerUtils.LOGGER.debug("加入任务队列 {}", task);
queue.addLast(task);
// 队列中有任务了,唤醒消费者线程
emptyWatiSet.signal();
}
}finally {
lock.unlock();
}
}
// 获取大小
public int size(){
lock.lock();
try {
return queue.size();
}finally {
lock.unlock();
}
}
}
步骤3:自定义线程池
class ThreadPool{
// 任务队列
private BlockingQueue<Runnable> taskQueue;
// 线程集合
private HashSet<Worker> workers = new HashSet<Worker>();
// 核心线程数
private int coreSize;
// 获取任务时的超时时间
private long timeout;
private TimeUnit timeUnit;
private RejectPolicy<Runnable> rejectPolicy;
public ThreadPool(int coreSize, long timeout, TimeUnit timeUnit, int queueCapacity, RejectPolicy<Runnable> rejectPolicy) {
this.coreSize = coreSize;
this.timeout = timeout;
this.timeUnit = timeUnit;
this.rejectPolicy = rejectPolicy;
this.taskQueue = new BlockingQueue<>(queueCapacity); // 指定队列大小
}
class Worker extends Thread{
private Runnable task;
public Worker(Runnable task) {
this.task = task;
}
@Override
public void run() {
// 执行任务
// 1) 当 task 不为空,执行任务
// 2) 当 task 执行完毕,再接着从任务队列获取任务并执行
// while (task != null || (task = taskQueue.take()) != null){ // 无超时时间等待
while (task != null || (task = taskQueue.poll(timeout, timeUnit)) != null){ // 有超时时间等待
try {
LoggerUtils.LOGGER.debug("正在执行...{}", task);
// 执行任务
task.run();
}catch (Exception e){
e.printStackTrace();
}finally {
task = null;
}
}
// 执行完任何后,在workers中移除当前的task
synchronized (workers){
LoggerUtils.LOGGER.debug("worker 被移除{}", this);
workers.remove(this);
}
}
}
// 执行任务
public void execute(Runnable task){
// 当任务数没有超过 coreSize 时,直接交给 worker 对象执行
// 如果任务数超过 coreSize 时,加入任务队列暂存
synchronized (workers){ // workers非线程安全
if(workers.size() < coreSize){
Worker worker = new Worker(task);
LoggerUtils.LOGGER.debug("新增 worker{}, {}", worker, task);
workers.add(worker);
worker.start();
}else{ // 将线程加入任务队列
// 1)死等
// taskQueue.put(task);
// 2)带超时等待
// taskQueue.offer(task, 1000, TimeUnit.MILLISECONDS);
// 3) 让调用者放弃任务执行
// 4) 让调用者抛出异常
// 5) 让调用者自己执行任务
// 将上述情况抽象成一个接口
taskQueue.tryPut(rejectPolicy, task);
}
}
}
}
步骤4:测试
public static void main(String[] args) {
// 任务数超过任务队列
ThreadPool threadPool = new ThreadPool(2, 1000, TimeUnit.MILLISECONDS, 10, (queue, task)->{
// queue.put(task); // 死等
// queue.offer(task, 1000, TimeUnit.MILLISECONDS); // 有时限等待
// LoggerUtils.LOGGER.debug("放弃 {} 任务", task);// 放弃
// throw new RuntimeException("执行任务失败" + task); // 抛出异常
task.run(); //让调用者自己执行任务
});
for (int i = 0; i < 15; i++) {
int j = i;
threadPool.execute(() -> {
LoggerUtils.LOGGER.debug("线程:{}, 正在被执行", j);
Sleeper.sleep(10000);
});
}
}
2. ThreadPoolExecutor

1) 线程池状态
ThreadPoolExecutor 使用 int 的高 3 位来表示线程池状态,低 29 位表示线程数量
| 状态名 | 高 3 位 | 接收新任务 | 处理阻塞队列任务 | 说明 |
|---|---|---|---|---|
| RUNNING | 111 | Y | Y | |
| SHUTDOWN | 000 | N | Y | 不会接收新任务,但会处理阻塞队列剩余任务 |
| STOP | 001 | N | N | 会中断正在执行的任务,并抛弃阻塞队列任务 |
| TIDYING | 010 | - | - | 任务全执行完毕,活动线程为 0 即将进入终结 |
| TERMINATED | 011 | - | - | 终结状态 |
从数字上比较,TERMINATED > TIDYING > STOP > SHUTDOWN > RUNNING
最高位表示符号位,因此RUNNING最小
这些信息存储在一个原子变量 ctl 中,目的是将线程池状态与线程个数合二为一,这样就可以用一次 cas 原子操作进行赋值
// c 为旧值, ctlOf 返回结果为新值
ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c))));
// rs 为高3位代表线程池状态, wc 为低29位代表线程个数,ctl 是合并它们
private static int ctlOf(int rs, int wc) { return rs | wc; }
2) 构造方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
}
- corePoolSize 核心线程数目 (最多保留的线程数)
- maximumPoolSize 最大线程数目
- keepAliveTime 生存时间 - 针对救急线程,救急线程有生存时间,而核心线程被创建后是没有的
- unit 时间单位 - 针对救急线程
- workQueue 阻塞队列
- threadFactory 线程工厂 - 可以为线程创建时起个好名字
- handler 拒绝策略
工作方式:
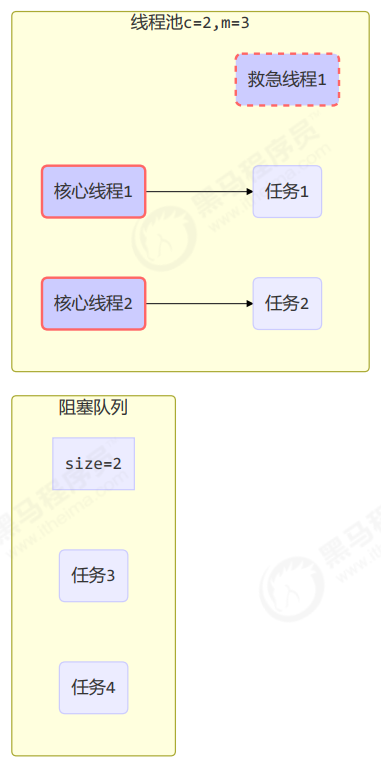
线程池中刚开始没有线程,当一个任务提交给线程池后,线程池会创建一个新线程来执行任务。
当线程数达到 corePoolSize 并没有线程空闲,这时再加入任务,新加的任务会被加入workQueue 队列排队,直到有空闲的线程。
如果队列选择了有界队列,那么任务超过了队列大小时,会创建 maximumPoolSize - corePoolSize 数目的线程来救急。
如果线程到达 maximumPoolSize 仍然有新任务这时会执行拒绝策略。拒绝策略 jdk 提供了 4 种实现,其它著名框架也提供了实现
- AbortPolicy 让调用者抛出 RejectedExecutionException 异常,这是默认策略
- CallerRunsPolicy 让调用者运行任务
- DiscardPolicy 放弃本次任务
- DiscardOldestPolicy 放弃队列中最早的任务,本任务取而代之
- Dubbo 的实现:在抛出 RejectedExecutionException 异常之前会记录日志,并 dump 线程栈信息,方便定位问题
- Netty 的实现:是创建一个新线程来执行任务
- ActiveMQ 的实现:带超时等待(60s)尝试放入队列,类似我们之前自定义的拒绝策略
- PinPoint 的实现:它使用了一个拒绝策略链,会逐一尝试策略链中每种拒绝策略

当高峰过去后,超过corePoolSize 的救急线程如果一段时间没有任务做,需要结束节省资源,这个时间由keepAliveTime 和 unit 来控制。
根据这个构造方法,JDK Executors 类中提供了众多工厂方法来创建各种用途的线程池
3) newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
特点
- 核心线程数 == 最大线程数(没有救急线程被创建),因此也无需超时时间
- 阻塞队列是无界的,可以放任意数量的任务
评价 适用于任务量已知,相对耗时的任务
使用案例:
ExecutorService pool = Executors.newFixedThreadPool(2);
for (int i = 0; i < 3; i++) {
int j = i;
pool.execute(new Runnable() {
@Override
public void run() {
LoggerUtils.LOGGER.debug("{} threads", j);
}
});
}
// 输出:
// 21:29:14.000 cn.util.LoggerUtils [pool-1-thread-1] - 0 threads
// 21:29:14.000 cn.util.LoggerUtils [pool-1-thread-2] - 1 threads
// 21:29:14.003 cn.util.LoggerUtils [pool-1-thread-1] - 2 threads
// 自定义ThreadFactory, 给线程起个名字
ExecutorService pool = Executors.newFixedThreadPool(2, new ThreadFactory() {
private AtomicInteger t = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "my-pool-thread-" + t.getAndIncrement());
}
});
for (int i = 0; i < 3; i++) {
int j = i;
pool.execute(() -> LoggerUtils.LOGGER.debug("{} threads", j));
}
// 输出:通过ThreadFactory自定义了线程的名字
// 21:34:10.290 cn.util.LoggerUtils [my-pool-thread-1] - 0 threads
// 21:34:10.294 cn.util.LoggerUtils [my-pool-thread-1] - 2 threads
// 21:34:10.290 cn.util.LoggerUtils [my-pool-thread-2] - 1 threads
4) newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
特点
- 核心线程数是 0, 最大线程数是 Integer.MAX_VALUE,救急线程的空闲生存时间是 60s,意味着
- 全部都是救急线程(60s 后可以回收)
- 救急线程可以无限创建
- 队列采用了 SynchronousQueue 实现特点是,它没有容量,没有线程来取是放不进去的(一手交钱、一手交货)
SynchronousQueue<Integer> integers = new SynchronousQueue<>();
new Thread(()->{
try {
LoggerUtils.LOGGER.debug("putting {}", 1);
integers.put(1);
LoggerUtils.LOGGER.debug("{} putted", 1);
LoggerUtils.LOGGER.debug("putting {}", 2);
integers.put(2);
LoggerUtils.LOGGER.debug("{} putted", 2);
}catch (InterruptedException e) {
e.printStackTrace();
}
}, "t1").start();
Sleeper.sleep(1);
new Thread(()->{
try {
LoggerUtils.LOGGER.debug("taking {}", 1);
integers.take();
}catch (InterruptedException e) {
e.printStackTrace();
}
}, "t2").start();
Sleeper.sleep(1);
new Thread(()->{
try {
LoggerUtils.LOGGER.debug("taking {}", 2);
integers.take();
}catch (InterruptedException e) {
e.printStackTrace();
}
}, "t3").start();
输出:
21:40:46.427 cn.util.LoggerUtils [t1] - putting 1
21:40:47.193 cn.util.LoggerUtils [t2] - taking 1
21:40:47.193 cn.util.LoggerUtils [t1] - 1 putted
21:40:47.193 cn.util.LoggerUtils [t1] - putting 2
21:40:48.196 cn.util.LoggerUtils [t3] - taking 2
21:40:48.196 cn.util.LoggerUtils [t1] - 2 putted
评价 整个线程池表现为线程数会根据任务量不断增长,没有上限,当任务执行完毕,空闲 1分钟后释放线程。 适合任务数比较密集,但每个任务执行时间较短的情况
5) newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}
使用场景:
希望多个任务排队执行。线程数固定为 1,任务数多于 1 时,会放入无界队列排队。任务执行完毕,这唯一的线程也不会被释放。
区别:
自己创建一个单线程串行执行任务,如果任务执行失败而终止那么没有任何补救措施;而线程池还会新建一个线程,保证池的正常工作
ExecutorService pool = Executors.newSingleThreadExecutor();
pool.execute(() -> {
LoggerUtils.LOGGER.debug("{} threads", 1);
int i = 1/0; // exception 出异常后,还会创建线程继续执行后面的线程任务
});
pool.execute(() -> LoggerUtils.LOGGER.debug("{} threads", 2));
pool.execute(() -> LoggerUtils.LOGGER.debug("{} threads", 3));
Executors.newSingleThreadExecutor()线程个数始终为1,不能修改- FinalizableDelegatedExecutorService 应用的是装饰器模式,只对外暴露了 ExecutorService 接口,因此不能调用 ThreadPoolExecutor 中特有的方法
Executors.newFixedThreadPool(1)初始时为1,以后还可以修改- 对外暴露的是 ThreadPoolExecutor 对象,可以强转后调用 setCorePoolSize 等方法进行修改
6) 提交任务
// 执行任务
void execute(Runnable command);
// 提交任务 task,用返回值 Future 获得任务执行结果
<T> Future<T> submit(Callable<T> task);
// 提交 tasks 中所有任务
public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException;
// 提交 tasks 中所有任务,带超时时间,若超时会将超时的任务取消
public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException;
// 提交 tasks 中所有任务,哪个任务先成功执行完毕,返回此任务执行结果,其它任务取消
public <T> T invokeAny(Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException;
// 提交 tasks 中所有任务,哪个任务先成功执行完毕,返回此任务执行结果,其它任务取消,带超时时间
public <T> T invokeAny(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException;
submit 调用示例:
ExecutorService pool = Executors.newFixedThreadPool(2);
Future<String> future = pool.submit(new Callable<String>() {
@Override
public String call() throws Exception {
LoggerUtils.LOGGER.debug("running...");
Sleeper.sleep(1);
return "ok";
}
});
LoggerUtils.LOGGER.debug("{}", future.get());
// 结果:
// 21:57:48.013 cn.util.LoggerUtils [pool-1-thread-1] - running...
// 21:57:49.018 cn.util.LoggerUtils [main] - ok
invokeAll 调用示例:
ExecutorService pool = Executors.newFixedThreadPool(2);
List<Future<String>> futures = pool.invokeAll(Arrays.asList(
() -> {
LoggerUtils.LOGGER.debug("begin");
Sleeper.sleep(1);
return "1";
},
() -> {
LoggerUtils.LOGGER.debug("begin");
Sleeper.sleep(0.5);
return "2";
},
() -> {
LoggerUtils.LOGGER.debug("begin");
Sleeper.sleep(2);
return "3";
}
));
futures.forEach(f->{
try {
LoggerUtils.LOGGER.debug("{}", f.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
});
// 输出:
// 22:06:07.676 cn.util.LoggerUtils [pool-1-thread-1] - begin
// 22:06:07.676 cn.util.LoggerUtils [pool-1-thread-2] - begin
// 22:06:08.186 cn.util.LoggerUtils [pool-1-thread-2] - begin
// 22:06:10.187 cn.util.LoggerUtils [main] - 1
// 22:06:10.189 cn.util.LoggerUtils [main] - 2
// 22:06:10.189 cn.util.LoggerUtils [main] - 3
invokeAny 调用示例:
ExecutorService pool = Executors.newFixedThreadPool(2);
String result = pool.invokeAny(Arrays.asList(
() -> {
LoggerUtils.LOGGER.debug("begin");
Sleeper.sleep(1);
return "1";
},
() -> {
LoggerUtils.LOGGER.debug("begin");
Sleeper.sleep(0.5);
return "2";
},
() -> {
LoggerUtils.LOGGER.debug("begin");
Sleeper.sleep(2);
return "3";
}
));
LoggerUtils.LOGGER.debug("{}", result);
// 结果:
// 22:09:37.217 cn.util.LoggerUtils [pool-1-thread-1] - begin
// 22:09:37.217 cn.util.LoggerUtils [pool-1-thread-2] - begin
// java.lang.InterruptedException: sleep interrupted
// 22:09:37.755 cn.util.LoggerUtils [main] - 2
7) 关闭线程池
shutdown
/*
线程池状态变为 SHUTDOWN
- 不会接收新任务
- 但已提交任务会执行完
- 此方法不会阻塞调用线程的执行
*/
void shutdown();
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 修改线程池状态
advanceRunState(SHUTDOWN);
// 仅会打断空闲线程
interruptIdleWorkers();
onShutdown(); // 扩展点 ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
// 尝试终结(没有运行的线程可以立刻终结,如果还有运行的线程也不会等)
tryTerminate();
}
shutdownNow
/*
线程池状态变为 STOP
- 不会接收新任务
- 会将队列中的任务返回
- 并用 interrupt 的方式中断正在执行的任务
*/
List<Runnable> shutdownNow();
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 修改线程池状态
advanceRunState(STOP);
// 打断所有线程
interruptWorkers();
// 获取队列中剩余任务
tasks = drainQueue();
} finally {
mainLock.unlock();
}
// 尝试终结
tryTerminate();
return tasks;
}
其它方法
// 不在 RUNNING 状态的线程池,此方法就返回 true
boolean isShutdown();
// 线程池状态是否是 TERMINATED
boolean isTerminated();
// 调用 shutdown 后,由于调用线程并不会等待所有任务运行结束,因此如果它想在线程池TERMINATED 后做些事情,可以利用此方法等待
boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
调用:shutdown
ExecutorService pool = Executors.newFixedThreadPool(2);
Future<Integer> result1 = pool.submit(() -> {
LoggerUtils.LOGGER.debug("task 1 running...");
Sleeper.sleep(1);
LoggerUtils.LOGGER.debug("task 1 finish...");
return 1;
});
Future<Integer> result2 = pool.submit(() -> {
LoggerUtils.LOGGER.debug("task 2 running...");
Sleeper.sleep(2);
LoggerUtils.LOGGER.debug("task 2 finish...");
return 2;
});
Future<Integer> result3 = pool.submit(() -> {
LoggerUtils.LOGGER.debug("task 3 running...");
Sleeper.sleep(3);
LoggerUtils.LOGGER.debug("task 3 finish...");
return 3;
});
LoggerUtils.LOGGER.debug("shutdown...");
pool.shutdown();
// 调用 shutdown 后,由于调用线程并不会等待所有任务运行结束
// 若想在线程池TERMINATED 后做些事情,可以利用awaitTermination等待
LoggerUtils.LOGGER.debug("other...");
// 结果:
// 22:55:26.686 cn.util.LoggerUtils [main] - shutdown...
// 22:55:26.686 cn.util.LoggerUtils [pool-1-thread-1] - task 1 running...
// 22:55:26.686 cn.util.LoggerUtils [pool-1-thread-2] - task 2 running...
// 22:55:26.688 cn.util.LoggerUtils [main] - other...
// 22:55:27.690 cn.util.LoggerUtils [pool-1-thread-1] - task 1 finish...
// 22:55:27.690 cn.util.LoggerUtils [pool-1-thread-1] - task 3 running...
// 22:55:28.690 cn.util.LoggerUtils [pool-1-thread-2] - task 2 finish...
// 22:55:30.691 cn.util.LoggerUtils [pool-1-thread-1] - task 3 finish...
调用:shutdownNow
...
List<Runnable> runnables = pool.shutdownNow();
LoggerUtils.LOGGER.debug("other... {}", runnables);
...
// 结果
// 23:00:08.993 cn.util.LoggerUtils [pool-1-thread-1] - task 1 running...
// 23:00:08.993 cn.util.LoggerUtils [pool-1-thread-2] - task 2 running...
// java.lang.InterruptedException: sleep interrupted
// 23:00:08.993 cn.util.LoggerUtils [main] - shutdown...
// 23:00:08.995 cn.util.LoggerUtils [main] - other... [java.util.concurrent.FutureTask@6ad5c04e]
// 23:00:08.997 cn.util.LoggerUtils [pool-1-thread-2] - task 2 finish...
// 23:00:08.997 cn.util.LoggerUtils [pool-1-thread-1] - task 1 finish...
// java.lang.InterruptedException: sleep interrupted
8) 任务调度线程池
在『任务调度线程池』功能加入之前,可以使用 java.util.Timer 来实现定时功能,Timer 的优点在于简单易用,但由于所有任务都是由同一个线程来调度,因此所有任务都是串行执行的,同一时间只能有一个任务在执行,前一个任务的延迟或异常都将会影响到之后的任务
Timer timer = new Timer();
TimerTask task1 = new TimerTask() {
@Override
public void run() {
LoggerUtils.LOGGER.debug("task 1...");
Sleeper.sleep(2);
}
};
TimerTask task2 = new TimerTask() {
@Override
public void run() {
LoggerUtils.LOGGER.debug("task 2...");
}
};
// 使用 timer 添加两个任务,希望它们都在 1s 后执行
// 但由于 timer 内只有一个线程来顺序执行队列中的任务,因此『任务1』的延时,影响了『任务2』的执行
LoggerUtils.LOGGER.debug("main start...");
timer.schedule(task1, 1000);
timer.schedule(task2, 1000);
输出:
21:16:33.235 cn.util.LoggerUtils [main] - main start...
21:16:34.238 cn.util.LoggerUtils [Timer-0] - task 1...
21:16:36.247 cn.util.LoggerUtils [Timer-0] - task 2...
使用 ScheduledExecutorService 改写:
ScheduledExecutorService executor = Executors.newScheduledThreadPool(1);
// 添加两个任务,希望它们都在 1s 后执行
executor.schedule(()->{
LoggerUtils.LOGGER.debug("task 1...");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, 1000, TimeUnit.MILLISECONDS);
executor.schedule(()->{
LoggerUtils.LOGGER.debug("task 2...");
}, 1000, TimeUnit.MILLISECONDS);
LoggerUtils.LOGGER.debug("main start...");
输出:
21:21:09.902 cn.util.LoggerUtils [main] - main start...
21:21:10.637 cn.util.LoggerUtils [pool-1-thread-1] - task 1...
21:21:12.638 cn.util.LoggerUtils [pool-1-thread-1] - task 2...
scheduleAtFixedRate 例子:
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
LoggerUtils.LOGGER.debug("main start...");
pool.scheduleAtFixedRate(()->{
LoggerUtils.LOGGER.debug("running");
}, 1, 1,TimeUnit.SECONDS);
输出:
21:26:11.029 cn.util.LoggerUtils [main] - main start...
21:26:12.069 cn.util.LoggerUtils [pool-1-thread-1] - running
21:26:13.070 cn.util.LoggerUtils [pool-1-thread-1] - running
21:26:14.070 cn.util.LoggerUtils [pool-1-thread-1] - running
21:26:15.071 cn.util.LoggerUtils [pool-1-thread-1] - running
21:26:16.071 cn.util.LoggerUtils [pool-1-thread-1] - running
21:26:17.071 cn.util.LoggerUtils [pool-1-thread-1] - running
scheduleAtFixedRate 例子(任务执行时间超过了间隔时间):
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
LoggerUtils.LOGGER.debug("main start...");
pool.scheduleAtFixedRate(()->{
LoggerUtils.LOGGER.debug("running");
Sleeper.sleep(2);
}, 1, 1,TimeUnit.SECONDS);
输出分析:一开始,延时 1s,接下来,由于任务执行时间 > 间隔时间,间隔被『撑』到了 2s
21:26:44.124 cn.util.LoggerUtils [main] - main start...
21:26:45.177 cn.util.LoggerUtils [pool-1-thread-1] - running
21:26:47.180 cn.util.LoggerUtils [pool-1-thread-1] - running
21:26:49.180 cn.util.LoggerUtils [pool-1-thread-1] - running
21:26:51.180 cn.util.LoggerUtils [pool-1-thread-1] - running
21:26:53.181 cn.util.LoggerUtils [pool-1-thread-1] - running
scheduleWithFixedDelay 例子:
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
LoggerUtils.LOGGER.debug("main start...");
pool.scheduleWithFixedDelay(()->{
LoggerUtils.LOGGER.debug("running");
Sleeper.sleep(2);
}, 1, 1,TimeUnit.SECONDS);
输出分析:一开始,延时 1s,scheduleWithFixedDelay 的间隔是 上一个任务结束 <-> 延时 <-> 下一个任务开始 所以间隔都是 3s
21:27:31.206 cn.util.LoggerUtils [main] - main start...
21:27:32.260 cn.util.LoggerUtils [pool-1-thread-1] - running
21:27:35.263 cn.util.LoggerUtils [pool-1-thread-1] - running
21:27:38.266 cn.util.LoggerUtils [pool-1-thread-1] - running
21:27:41.266 cn.util.LoggerUtils [pool-1-thread-1] - running
21:27:44.267 cn.util.LoggerUtils [pool-1-thread-1] - running
评价 整个线程池表现为:线程数固定,任务数多于线程数时,会放入无界队列排队。任务执行完毕,这些线程也不会被释放。用来执行延迟或反复执行的任务
9) 正确处理执行任务异常
不做处理,会连个提示也没有....
方法1:主动捉异常
ExecutorService pool = Executors.newFixedThreadPool(1);
pool.submit(()->{
try {
LoggerUtils.LOGGER.debug("task");
int i = 1/0;
}catch (Exception e){
LoggerUtils.LOGGER.debug("error:{}", e);
}
});
输出
21:30:41.767 cn.util.LoggerUtils [pool-1-thread-1] - task
21:30:41.770 cn.util.LoggerUtils [pool-1-thread-1] - error:{}
java.lang.ArithmeticException: / by zero
方法2:使用 Future
ExecutorService pool = Executors.newFixedThreadPool(1);
Future<Boolean> task = pool.submit(() -> {
LoggerUtils.LOGGER.debug("task");
int i = 1 / 0;
return true;
});
LoggerUtils.LOGGER.debug("result:{}", task.get());
输出:
21:32:53.881 cn.util.LoggerUtils [pool-1-thread-1] - task
Exception in thread "main" java.util.concurrent.ExecutionException: java.lang.ArithmeticException: / by zero
Caused by: java.lang.ArithmeticException: / by zero
10) Tomcat 线程池
Tomcat 在哪里用到了线程池呢

- LimitLatch 用来限流,可以控制最大连接个数,类似 J.U.C 中的 Semaphore 后面再讲
- Acceptor 只负责【接收新的 socket 连接】
- Poller 只负责监听 socket channel 是否有【可读的 I/O 事件】
- 一旦可读,封装一个任务对象(socketProcessor),提交给 Executor 线程池处理
- Executor 线程池中的工作线程最终负责【处理请求】
Tomcat 线程池扩展了 ThreadPoolExecutor,行为稍有不同
- 如果总线程数达到 maximumPoolSize
- 这时不会立刻抛 RejectedExecutionException 异常
- 而是再次尝试将任务放入队列,如果还失败,才抛出 RejectedExecutionException 异常
源码 tomcat-7.0.42
public void execute(Runnable command, long timeout, TimeUnit unit) {
submittedCount.incrementAndGet();
try {
super.execute(command);
} catch (RejectedExecutionException rx) {
if (super.getQueue() instanceof TaskQueue) {
final TaskQueue queue = (TaskQueue)super.getQueue();
try {
if (!queue.force(command, timeout, unit)) {
submittedCount.decrementAndGet();
throw new RejectedExecutionException("Queue capacity is full.");
}
} catch (InterruptedException x) {
submittedCount.decrementAndGet();
Thread.interrupted();
throw new RejectedExecutionException(x);
}
} else {
submittedCount.decrementAndGet();
throw rx;
}
}
}
TaskQueue.java
public boolean force(Runnable o, long timeout, TimeUnit unit) throws InterruptedException {
if ( parent.isShutdown() )
throw new RejectedExecutionException(
"Executor not running, can't force a command into the queue"
);
return super.offer(o,timeout,unit); //forces the item onto the queue, to be used if the task is rejected
}
Connector 配置
| 配置项 | 默认值 | 说明 |
|---|---|---|
| acceptorThreadCount | 1 | acceptor 线程数量 |
| pollerThreadCount | 1 | poller 线程数量 |
| minSpareThreads | 10 | 核心线程数,即 corePoolSize |
| maxThreads | 200 | 最大线程数,即 maximumPoolSize |
| executor | - | Executor 名称,用来引用下面的 Executor |
Executor 线程配置
| 配置项 | 默认值 | 说明 |
|---|---|---|
| threadPriority | 5 | 线程优先级 |
| daemon | true | 是否守护线程 |
| minSpareThreads | 25 | 核心线程数,即 corePoolSize |
| maxThreads | 200 | 最大线程数,即 maximumPoolSize |
| maxIdleTime | 60000 | 线程生存时间,单位是毫秒,默认值即 1 分钟 |
| maxQueueSize | Integer.MAX_VALUE | 队列长度 |
| prestartminSpareThreads | false | 核心线程是否在服务器启动时启动 |
3. Fork/Join
1) 概念
Fork/Join 是 JDK 1.7 加入的新的线程池实现,它体现的是一种分治思想,适用于能够进行任务拆分的 cpu 密集型运算
所谓的任务拆分,是将一个大任务拆分为算法上相同的小任务,直至不能拆分可以直接求解。跟递归相关的一些计算,如归并排序、斐波那契数列、都可以用分治思想进行求解
Fork/Join 在分治的基础上加入了多线程,可以把每个任务的分解和合并交给不同的线程来完成,进一步提升了运算效率
Fork/Join 默认会创建与 cpu 核心数大小相同的线程池
2) 使用
提交给 Fork/Join 线程池的任务需要继承 RecursiveTask(有返回值)或 RecursiveAction(没有返回值),例如下面定义了一个对 1~n 之间的整数求和的任务
class AddTask1 extends RecursiveTask<Integer>{
int n;
public AddTask1(int n) {
this.n = n;
}
@Override
public String toString() {
return "{" + n + '}';
}
@Override
protected Integer compute() {
// 如果 n 已经为 1,可以求得结果了
if(n==1){
LoggerUtils.LOGGER.debug("join {}", n);
return n;
}
// 将任务进行拆分(fork)
AddTask1 t1 = new AddTask1(n-1);
t1.fork();
LoggerUtils.LOGGER.debug("fork() {} + {}", n, t1);
// 合并(join)结果
int result = n + t1.join();
LoggerUtils.LOGGER.debug("join() {} + {} = {}", n, t1, result);
return result;
}
}
然后提交给 ForkJoinPool 来执行
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool(4);
System.out.println(pool.invoke(new AddTask1(5)));
}
结果:
22:55:26.737 cn.util.LoggerUtils [ForkJoinPool-1-worker-1] - fork() 5 + {4}
22:55:26.737 cn.util.LoggerUtils [ForkJoinPool-1-worker-2] - fork() 4 + {3}
22:55:26.737 cn.util.LoggerUtils [ForkJoinPool-1-worker-3] - fork() 3 + {2}
22:55:26.737 cn.util.LoggerUtils [ForkJoinPool-1-worker-0] - fork() 2 + {1}
22:55:26.742 cn.util.LoggerUtils [ForkJoinPool-1-worker-3] - join 1
22:55:26.742 cn.util.LoggerUtils [ForkJoinPool-1-worker-0] - join() 2 + {1} = 3
22:55:26.742 cn.util.LoggerUtils [ForkJoinPool-1-worker-3] - join() 3 + {2} = 6
22:55:26.742 cn.util.LoggerUtils [ForkJoinPool-1-worker-2] - join() 4 + {3} = 10
22:55:26.742 cn.util.LoggerUtils [ForkJoinPool-1-worker-1] - join() 5 + {4} = 15
15
用图来表示

改进
class AddTask2 extends RecursiveTask<Integer>{
int begin;
int end;
public AddTask2(int begin, int end) {
this.begin = begin;
this.end = end;
}
@Override
public String toString() {
return "{" + begin + "," + end + '}';
}
@Override
protected Integer compute() {
// 5, 5 不需再拆分
if(begin==end){
LoggerUtils.LOGGER.debug("join {}", begin);
return begin;
}
// 4, 5 不需再拆分
if(end-begin==1){
LoggerUtils.LOGGER.debug("join() {} + {} = {}", begin, end, end + begin);
return end+begin;
}
int mid = (end + begin)/2;
AddTask2 t2 = new AddTask2(begin, mid);
t2.fork();
AddTask2 t3 = new AddTask2(mid+1, end);
t3.fork();
LoggerUtils.LOGGER.debug("fork() {} + {} = ?", t2, t3);
int result = t2.join() + t3.join();
LoggerUtils.LOGGER.debug("join() {} + {} = {}", t2, t3, result);
return result;
}
}
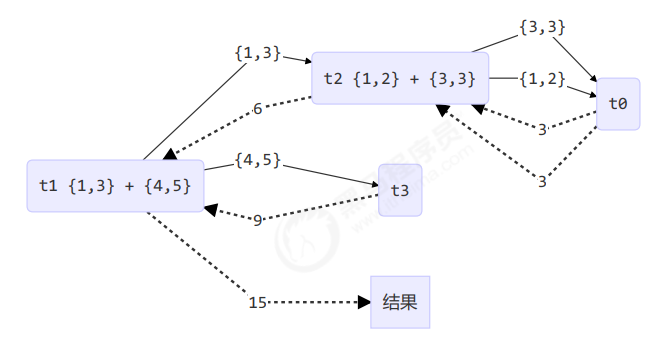
然后提交给 ForkJoinPool 来执行
ForkJoinPool pool = new ForkJoinPool(4);
System.out.println(pool.invoke(new AddTask2(1, 5)));
结果
23:02:21.295 cn.util.LoggerUtils [ForkJoinPool-1-worker-0] - join() 1 + 2 = 3
23:02:21.295 cn.util.LoggerUtils [ForkJoinPool-1-worker-3] - join() 4 + 5 = 9
23:02:21.295 cn.util.LoggerUtils [ForkJoinPool-1-worker-1] - fork() {1,3} + {4,5} = ?
23:02:21.295 cn.util.LoggerUtils [ForkJoinPool-1-worker-2] - fork() {1,2} + {3,3} = ?
23:02:21.299 cn.util.LoggerUtils [ForkJoinPool-1-worker-3] - join 3
23:02:21.299 cn.util.LoggerUtils [ForkJoinPool-1-worker-2] - join() {1,2} + {3,3} = 6
23:02:21.299 cn.util.LoggerUtils [ForkJoinPool-1-worker-1] - join() {1,3} + {4,5} = 15
15
用图来表示:
模式:工作线程-Worker Thread
1. 定义
让有限的工作线程(Worker Thread)来轮流异步处理无限多的任务。也可以将其归类为分工模式,它的典型实现就是线程池,也体现了经典设计模式中的享元模式。
例如,海底捞的服务员(线程),轮流处理每位客人的点餐(任务),如果为每位客人都配一名专属的服务员,那么成本就太高了(对比另一种多线程设计模式:Thread-Per-Message)
注意,不同任务类型应该使用不同的线程池,这样能够避免饥饿,并能提升效率
例如,如果一个餐馆的工人既要招呼客人(任务类型A),又要到后厨做菜(任务类型B)显然效率不咋地,分成服务员(线程池A)与厨师(线程池B)更为合理,当然你能想到更细致的分工
2. 饥饿
固定大小线程池会有饥饿现象
- 两个工人是同一个线程池中的两个线程
- 他们要做的事情是:为客人点餐和到后厨做菜,这是两个阶段的工作
- 客人点餐:必须先点完餐,等菜做好,上菜,在此期间处理点餐的工人必须等待
- 后厨做菜:没啥说的,做就是了
- 比如工人A 处理了点餐任务,接下来它要等着 工人B 把菜做好,然后上菜,他俩也配合的蛮好
- 但现在同时来了两个客人,这个时候工人A 和工人B 都去处理点餐了,这时没人做饭了,饥饿
public class TestDeadLock {
static final List<String> MENU = Arrays.asList("地三鲜", "宫保鸡丁", "辣子鸡丁", "烤鸡翅");
static Random RANDOM = new Random();
static String cooking(){
return MENU.get(RANDOM.nextInt(MENU.size()));
}
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(2);
executorService.execute(()->{
LoggerUtils.LOGGER.debug("处理点餐...");
Future<String> f = executorService.submit(()->{
LoggerUtils.LOGGER.debug("做菜...");
return cooking();
});
try {
LoggerUtils.LOGGER.debug("上菜:{}", f.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
});
/*executorService.execute(()->{
LoggerUtils.LOGGER.debug("处理点餐...");
Future<String> f = executorService.submit(()->{
LoggerUtils.LOGGER.debug("做菜...");
return cooking();
});
try {
LoggerUtils.LOGGER.debug("上菜:{}", f.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
});*/
}
}
输出
20:41:43.715 cn.util.LoggerUtils [pool-1-thread-1] - 处理点餐...
20:41:43.718 cn.util.LoggerUtils [pool-1-thread-2] - 做菜...
20:41:43.718 cn.util.LoggerUtils [pool-1-thread-1] - 上菜:烤鸡翅
当注释取消后,可能的输出
20:42:05.519 cn.util.LoggerUtils [pool-1-thread-2] - 处理点餐...
20:42:05.519 cn.util.LoggerUtils [pool-1-thread-1] - 处理点餐...
解决方法可以增加线程池的大小,不过不是根本解决方案,还是前面提到的,不同的任务类型,采用不同的线程池,例如:
public class TestDeadLock {
static final List<String> MENU = Arrays.asList("地三鲜", "宫保鸡丁", "辣子鸡丁", "烤鸡翅");
static Random RANDOM = new Random();
static String cooking(){
return MENU.get(RANDOM.nextInt(MENU.size()));
}
public static void main(String[] args) {
ExecutorService waiterPool = Executors.newFixedThreadPool(2);
ExecutorService cookPool = Executors.newFixedThreadPool(2);
waiterPool.execute(()->{
LoggerUtils.LOGGER.debug("处理点餐...");
Future<String> f = cookPool.submit(()->{
LoggerUtils.LOGGER.debug("做菜...");
return cooking();
});
try {
LoggerUtils.LOGGER.debug("上菜:{}", f.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
});
waiterPool.execute(()->{
LoggerUtils.LOGGER.debug("处理点餐...");
Future<String> f = cookPool.submit(()->{
LoggerUtils.LOGGER.debug("做菜...");
return cooking();
});
try {
LoggerUtils.LOGGER.debug("上菜:{}", f.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
});
}
}
输出
20:43:32.248 cn.util.LoggerUtils [pool-1-thread-1] - 处理点餐...
20:43:32.248 cn.util.LoggerUtils [pool-1-thread-2] - 处理点餐...
20:43:32.252 cn.util.LoggerUtils [pool-2-thread-1] - 做菜...
20:43:32.253 cn.util.LoggerUtils [pool-2-thread-2] - 做菜...
20:43:32.252 cn.util.LoggerUtils [pool-1-thread-1] - 上菜:地三鲜
20:43:32.253 cn.util.LoggerUtils [pool-1-thread-2] - 上菜:地三鲜
3. 创建多少线程池合适
- 过小会导致程序不能充分地利用系统资源、容易导致饥饿
- 过大会导致更多的线程上下文切换,占用更多内存
CPU 密集型运算
通常采用 cpu 核数 + 1 能够实现最优的 CPU 利用率,+1 是保证当线程由于页缺失故障(操作系统)或其它原因导致暂停时,额外的这个线程就能顶上去,保证 CPU 时钟周期不被浪费
I/O 密集型运算
CPU 不总是处于繁忙状态,例如,当你执行业务计算时,这时候会使用 CPU 资源,但当你执行 I/O 操作时、远程 RPC 调用时,包括进行数据库操作时,这时候 CPU 就闲下来了,你可以利用多线程提高它的利用率。
经验公式如下
线程数 = 核数 * 期望 CPU 利用率 * 总时间(CPU计算时间+等待时间) / CPU 计算时间例如 4 核 CPU 计算时间是 50% ,其它等待时间是 50%,期望 cpu 被 100% 利用,套用公式
4 * 100% * 100% / 50% = 8例如 4 核 CPU 计算时间是 10% ,其它等待时间是 90%,期望 cpu 被 100% 利用,套用公式
4 * 100% * 100% / 10% = 40
4. 自定义线程池
在7.1部分已经实现了
应用:定时任务
需求描述:如何让每周四 18:00:00 定时执行任务?
// 获得当前时间
LocalDateTime now = LocalDateTime.now();
// 获取本周四 18:00:00.000
LocalDateTime thursday =
now.with(DayOfWeek.THURSDAY).withHour(18).withMinute(0).withSecond(0).withNano(0);
// 如果当前时间已经超过 本周四 18:00:00.000, 那么找下周四 18:00:00.000
if(now.compareTo(thursday) > 0){
thursday = thursday.plusWeeks(1);
}
// 计算时间差,即延时执行时间
long initialDelay = Duration.between(now, thursday).toMillis();
// 计算间隔时间,即 1 周的毫秒值
long oneWeek = 7 * 24 * 3600 * 1000;
ScheduledExecutorService executor = Executors.newScheduledThreadPool(2);
LoggerUtils.LOGGER.debug("start...");
executor.scheduleAtFixedRate(()->{
LoggerUtils.LOGGER.debug("execute...");
}, initialDelay, oneWeek, TimeUnit.MILLISECONDS);
Java:并发笔记-08的更多相关文章
- java并发笔记之四synchronized 锁的膨胀过程(锁的升级过程)深入剖析
警告⚠️:本文耗时很长,先做好心理准备,建议PC端浏览器浏览效果更佳. 本篇我们讲通过大量实例代码及hotspot源码分析偏向锁(批量重偏向.批量撤销).轻量级锁.重量级锁及锁的膨胀过程(也就是锁的升 ...
- JAVA自学笔记08
JAVA自学笔记08 1.构造方法私有,外界就不能再创建对象 2.说明书的制作过程 1)写一个工具类,在同一文件夹下,测试类需要用到工具类,系统将自动编译工具类:工具类的成员方法一般是静态的,因此在测 ...
- java并发笔记之证明 synchronized锁 是否真实存在
警告⚠️:本文耗时很长,先做好心理准备 证明:偏向锁.轻量级锁.重量级锁真实存在 由[java并发笔记之java线程模型]链接: https://www.cnblogs.com/yuhangwang/ ...
- Java并发笔记——单例与双重检测
单例模式可以使得一个类只有一个对象实例,能够减少频繁创建对象的时间和空间开销.单线程模式下一个典型的单例模式代码如下: ① class Singleton{ private static Single ...
- Java并发编程(08):Executor线程池框架
本文源码:GitHub·点这里 || GitEE·点这里 一.Executor框架简介 1.基础简介 Executor系统中,将线程任务提交和任务执行进行了解耦的设计,Executor有各种功能强大的 ...
- Java并发笔记-未完待续待详解
为什么需要并行? – 业务要求 – 性能 并行计算还出于业务模型的需要 – 并不是为了提高系统性能,而是确实在业务上需要多个执行单元. – 比如HTTP服务器,为每一个Socket连接新建一个处理线程 ...
- Java并发笔记(二)
1. 活跃性危险 死锁(最常见) 饥饿 当线程由于无法访问它所需的资源而不能继续执行时,就发生了饥饿.引发饥饿最常见资源就是CPU时钟周期. 活锁 活锁指的是任务或者执行者没有被阻塞,由于某些条件没有 ...
- Java并发笔记(一)
1. lock (todo) 2. 写时复制容器 CopyOnWrite容器即写时复制的容器.通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个 ...
- java并发笔记之synchronized 偏向锁 轻量级锁 重量级锁证明
警告⚠️:本文耗时很长,先做好心理准备 本篇将从hotspot源码(64 bits)入手,通过分析java对象头引申出锁的状态:本文采用大量实例及分析,请耐心看完,谢谢 先来看一下hotspot的 ...
随机推荐
- Xshell破~~解和SecureCRT破~~解办法,亲测可行
解决办法很简单,那就是安装MobaXterm, 安装上即可使用,无需破击,免费,功能同样强大,不比xshell, SecureCRT功能差.它是集万千功能于一身的全能型终端神器. 听名字就不会太差,看 ...
- 只需3步,快来用AI预测你爱的球队下一场能赢吗?
摘要:作为球迷,我们有时候希望自己拥有预测未来的能力. 本文分享自华为云社区<用 AI 预测球赛结果只需三步,看看你爱的球队下一场能赢吗?>,作者:HWCloudAI. 还记得今年夏天的欧 ...
- vue-cli3 项目中通过 CDN方式 使用 echarts
1.html 中引入 echarts html中添加script标签如下: <script src="//cdn.bootcss.com/echarts ...
- VS Code + WSL 搭建 RaspberryPi Pico 开发环境
前面老周写一堆 .NET 与树莓派相关的水文.其实使用的是.net的 IOT 库,并不只是树莓派,其他运行 Linux 的开发板都适用,只要有 GPIO 就行.老周好像在哪看到过,有 USB 转GPI ...
- c++ undefined reference
记录一次c++编程时发现的问题 报错 undefined reference undefined reference to `Student::~Student()' 下面还有类似的好几行,翻译过来就 ...
- 用Python实现童年的21款小游戏,有你玩过的吗?(不要错过哦)
Python为什么能这么火热,Python相对于其他语言来说比较简单,即使是零基础的普通人也能很快的掌握,在其他方面比如,处于灰色界的爬虫,要VIP的视频,小说,歌,没有爬虫解决不了的:数据挖掘及分析 ...
- CURL的模拟登录和抓取页面
<?php $curl = curl_init();// 初始化 // 准备提交的表单数据之账号和密码.(这个是根据表单选项来的) $data = "_username=6049892 ...
- Java基础系列(2)- Java开发环境搭建
JDK下载与安装 安装JDK 1.百度搜素JDK8,找到下载地址 2.下载电脑对应的版本 3.双击安装JDK 4.记住安装的路径,可以自定义,默认路径如图 卸载JDK 删除Java安装目录 删除环境变 ...
- javascript 享元模式 flyweight
* 适应条件 ** 一个程序中使用了大量的相似对象 造成大的内存开销 ** 对象的大多数状态都可以变为外部状态 ** 剥离出对象的外部状态之后, 可以使用相对较少的共享对象取代大量对象 * 上传文件的 ...
- python学习笔记(十四)python实现发邮件
import smtplib from email.mime.text import MIMEText from email.mime.multipart import MIMEMultipart u ...