一文彻底理解Apache Hudi的多版本清理服务
Apache Hudi提供了MVCC并发模型,保证写入端和读取端之间快照级别隔离。在本篇博客中我们将介绍如何配置来管理多个文件版本,此外还将讨论用户可使用的清理机制,以了解如何维护所需数量的旧文件版本,以使长时间运行的读取端不会失败。
1. 回收空间以控制存储成本
Hudi 提供不同的表管理服务来管理数据湖上表的数据,其中一项服务称为Cleaner(清理服务)。 随着用户向表中写入更多数据,对于每次更新,Hudi会生成一个新版本的数据文件用于保存更新后的记录(COPY_ON_WRITE) 或将这些增量更新写入日志文件以避免重写更新版本的数据文件 (MERGE_ON_READ)。 在这种情况下,根据更新频率,文件版本数可能会无限增长,但如果不需要保留无限的历史记录,则必须有一个流程(服务)来回收旧版本的数据,这就是 Hudi 的清理服务。
2. 问题描述
在数据湖架构中,读取端和写入端同时访问同一张表是非常常见的场景。由于 Hudi 清理服务会定期回收较旧的文件版本,因此可能会出现长时间运行的查询访问到被清理服务回收的文件版本的情况,因此需要使用正确的配置来确保查询不会失败。
3. 深入了解 Hudi清理服务
针对上述场景,我们先了解一下 Hudi 提供的不同清理策略以及需要配置的相应属性,Hudi提供了异步或同步清理两种方式。在详细介绍之前我们先解释一些基本概念:
- Hudi 基础文件(HoodieBaseFile):由压缩后的最终数据组成的列式文件,基本文件的名称遵循以下命名约定:
<fileId>_<writeToken>_<instantTime>.parquet。在此文件的后续写入中文件 ID 保持不变,并且提交时间会更新以显示最新版本。这也意味着记录的任何特定版本,给定其分区路径,都可以使用文件 ID 和 instantTime进行唯一定位。 - 文件切片(FileSlice):在 MERGE_ON_READ 表类型的情况下,文件切片由基本文件和由多个增量日志文件组成。
- Hudi 文件组(FileGroup):Hudi 中的任何文件组都由分区路径和文件ID 唯一标识,该组中的文件作为其名称的一部分。文件组由特定分区路径中的所有文件片组成。此外任何分区路径都可以有多个文件组。
4. 清理服务
Hudi 清理服务目前支持以下清理策略:
- KEEP_LATEST_COMMITS:这是默认策略。该清理策略可确保回溯前X次提交中发生的所有更改。假设每 30 分钟将数据摄取到 Hudi 数据集,并且最长的运行查询可能需要 5 小时才能完成,那么用户应该至少保留最后 10 次提交。通过这样的配置,我们确保文件的最旧版本在磁盘上保留至少 5 小时,从而防止运行时间最长的查询在任何时间点失败,使用此策略也可以进行增量清理。
- KEEP_LATEST_FILE_VERSIONS:此策略具有保持 N 个文件版本而不受时间限制的效果。当知道在任何给定时间想要保留多少个 MAX 版本的文件时,此策略很有用,为了实现与以前相同的防止长时间运行的查询失败的行为,应该根据数据模式进行计算,或者如果用户只想维护文件的 1 个最新版本,此策略也很有用。
5. 例子
假设用户每 30 分钟将数据摄取到 COPY_ON_WRITE 类型的 Hudi 数据集,如下所示:
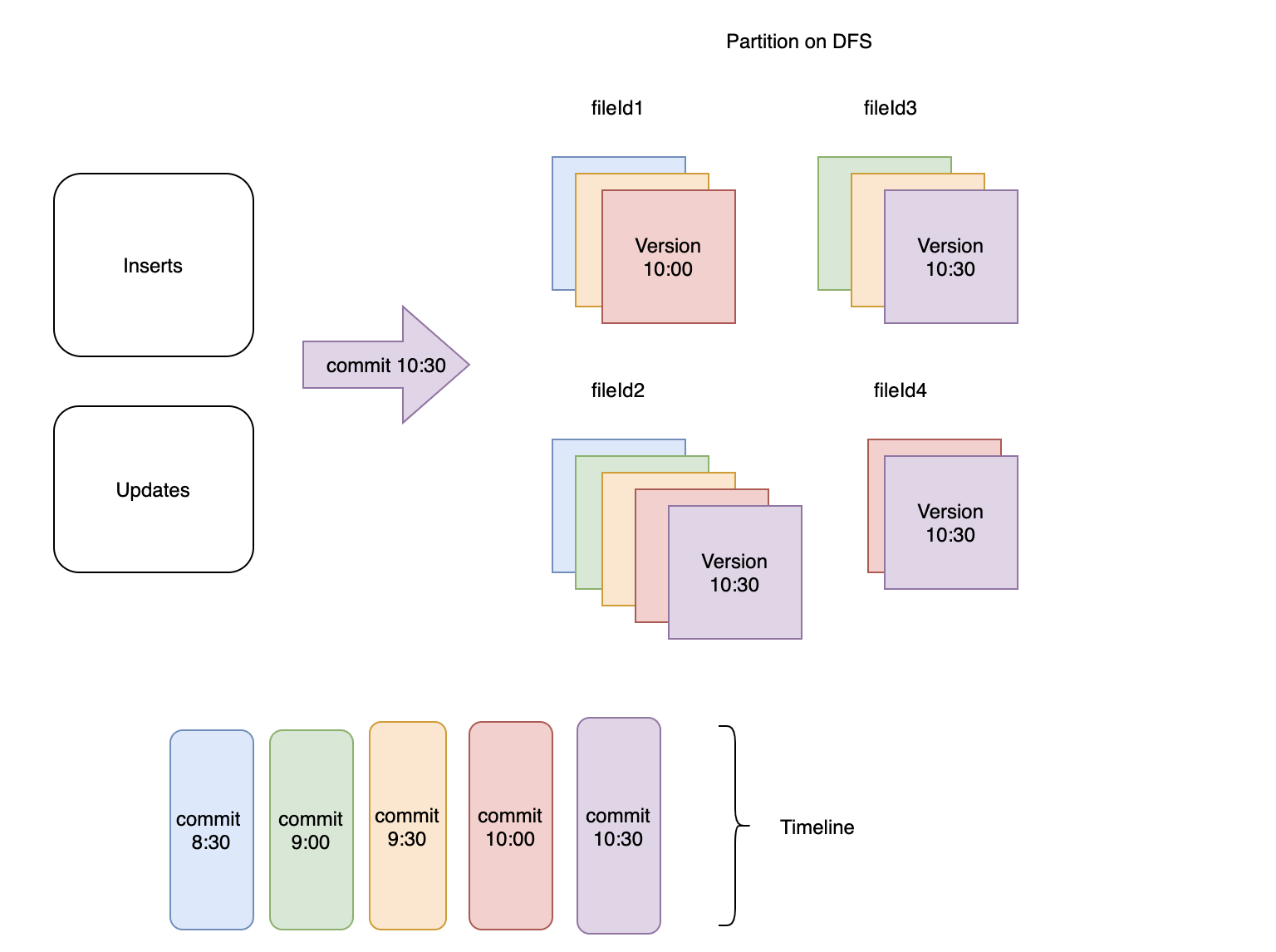
图1:每30分钟将传入的记录提取到hudi数据集中
该图显示了 DFS 上的一个特定分区,其中提交和相应的文件版本是彩色编码的。在该分区中创建了 4 个不同的文件组,如 fileId1、fileId2、fileId3 和 fileId4 所示。 fileId2 对应的文件组包含所有 5 次提交的记录,而 fileId4 对应的组仅包含最近 2 次提交的记录。
假设使用以下配置进行清理:
hoodie.cleaner.policy=KEEP_LATEST_COMMITS
hoodie.cleaner.commits.retained=2
Cleaner 通过处理以下事项来选择要清理的文件版本:
- 不应清理文件的最新版本。
- 确定最后 2 次(已配置)+ 1 次提交的提交时间。在图 1 中,
commit 10:30和commit 10:00对应于时间线中最新的 2 个提交。包含一个额外的提交,因为保留提交的时间窗口本质上等于最长的查询运行时间。因此如果最长的查询需要 1 小时才能完成,并且每 30 分钟发生一次摄取,则您需要保留自 2*30 = 60(1 小时)以来的最后 2 次提交。此时最长的查询仍然可以使用以相反顺序在第 3 次提交中写入的文件。这意味着如果一个查询在commit 9:30之后开始执行,当在commit 10:30之后触发清理操作时,它仍然会运行,如图 2 所示。 - 现在对于任何文件组,只有那些没有保存点(另一个 Hudi 表服务)且提交时间小于第 3 次提交(下图中的“提交 9:30”)的文件切片被清理。
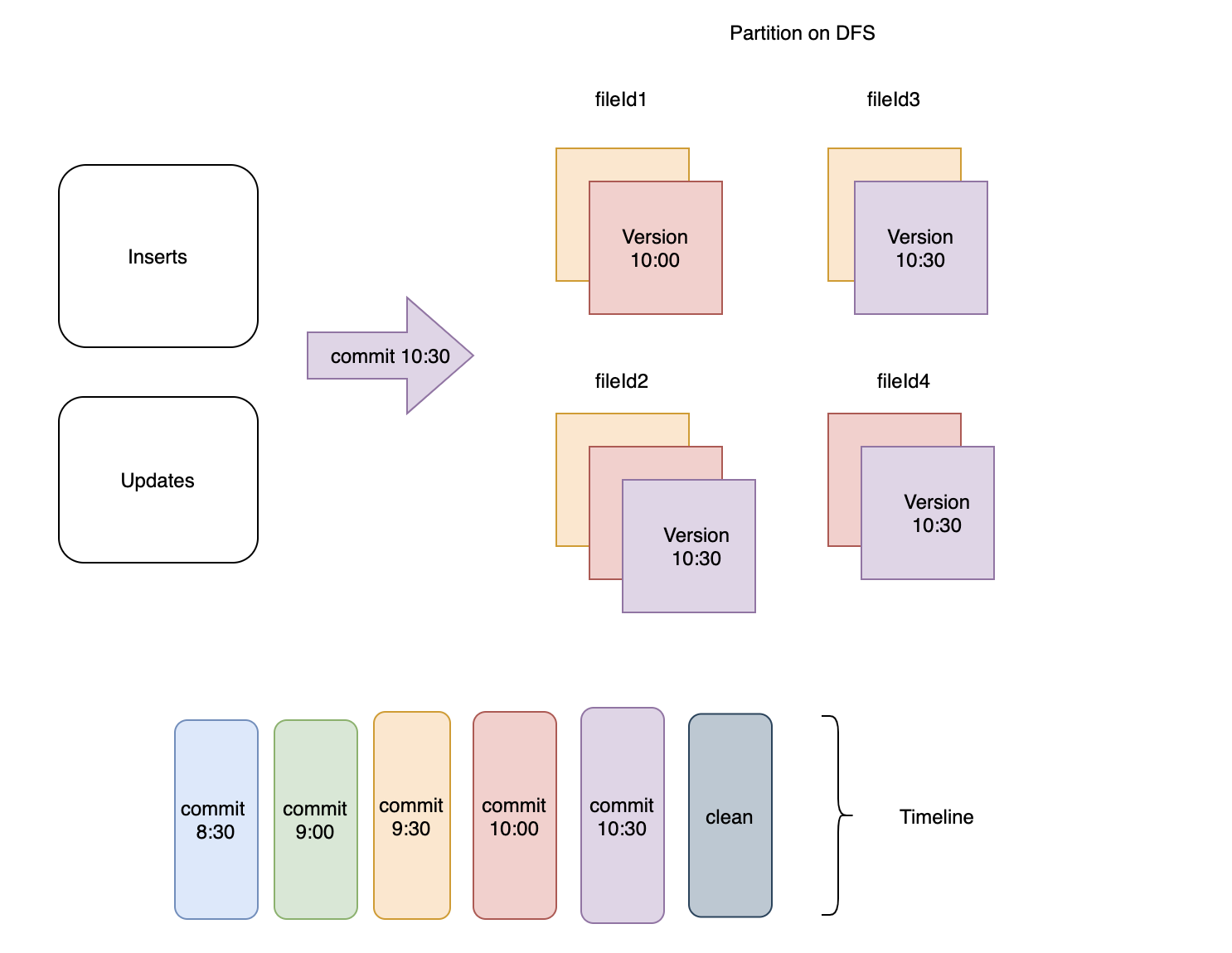
图2:保留最近3次提交对应的文件
假设使用以下配置进行清理:
hoodie.cleaner.policy=KEEP_LATEST_FILE_VERSIONS
hoodie.cleaner.fileversions.retained=1
清理服务执行以下操作:
- 对于任何文件组,文件切片的最新版本(包括任何待压缩的)被保留,其余的清理掉。 如图 3 所示,如果在
commit 10:30之后立即触发清理操作,清理服务将简单地保留每个文件组中的最新版本并删除其余的。

图3:保留每个文件组中的最新文件版本
6. 配置
可以在 此处 中找到有关所有可能配置的详细信息以及默认值。
7. 运行命令
Hudi 的清理表服务可以作为单独的进程运行,可以与数据摄取一起运行。正如前面提到的,它会清除了任何陈旧文件。如果您想将它与摄取数据一起运行,可以使用配置同步或异步运行。或者可以使用以下命令独立运行清理服务:
[hoodie]$ spark-submit --class org.apache.hudi.utilities.HoodieCleaner \
--props s3:///temp/hudi-ingestion-config/config.properties \
--target-base-path s3:///temp/hudi \
--spark-master yarn-cluster
如果您希望与写入异步运行清理服务,可以配置如下内容:
hoodie.clean.automatic=true
hoodie.clean.async=true
此外还可以使用 Hudi CLI 来管理 Hudi 数据集。CLI 为清理服务提供了以下命令:
cleans showclean showpartitionsclean run
可以在 org.apache.hudi.cli.commands.CleansCommand 类 中找到这些命令的更多详细信息和相关代码。
8. 未来计划
目前正在进行根据已流逝的时间间隔引入新的清理策略,即无论摄取发生的频率如何,都可以保留想要的文件版本,可以在 此处 跟踪进度。
我们希望这篇博客能让您了解如何配置 Hudi 清理服务和支持的清理策略。请访问博客部分 以更深入地了解各种 Hudi 概念。
一文彻底理解Apache Hudi的多版本清理服务的更多相关文章
- 深入理解Apache Hudi异步索引机制
在我们之前的文章中,我们讨论了多模式索引的设计,这是一种用于Lakehouse架构的无服务器和高性能索引子系统,以提高查询和写入性能.在这篇博客中,我们讨论了构建如此强大的索引所需的机制,异步索引机制 ...
- 一文彻底掌握Apache Hudi的主键和分区配置
1. 介绍 Hudi中的每个记录都由HoodieKey唯一标识,HoodieKey由记录键和记录所属的分区路径组成.基于此设计Hudi可以将更新和删除快速应用于指定记录.Hudi使用分区路径字段对数据 ...
- 一文彻底掌握Apache Hudi异步Clustering部署
1. 摘要 在之前的一篇博客中,我们介绍了Clustering(聚簇)的表服务来重新组织数据来提供更好的查询性能,而不用降低摄取速度,并且我们已经知道如何部署同步Clustering,本篇博客中,我们 ...
- 数据湖框架选型很纠结?一文了解Apache Hudi核心优势
英文原文:https://hudi.apache.org/blog/hudi-indexing-mechanisms/ Apache Hudi使用索引来定位更删操作所在的文件组.对于Copy-On-W ...
- 使用Apache Spark和Apache Hudi构建分析数据湖
1. 引入 大多数现代数据湖都是基于某种分布式文件系统(DFS),如HDFS或基于云的存储,如AWS S3构建的.遵循的基本原则之一是文件的"一次写入多次读取"访问模型.这对于处理 ...
- 基于Apache Hudi在Google云构建数据湖平台
自从计算机出现以来,我们一直在尝试寻找计算机存储一些信息的方法,存储在计算机上的信息(也称为数据)有多种形式,数据变得如此重要,以至于信息现在已成为触手可及的商品.多年来数据以多种方式存储在计算机中, ...
- 使用Amazon EMR和Apache Hudi在S3上插入,更新,删除数据
将数据存储在Amazon S3中可带来很多好处,包括规模.可靠性.成本效率等方面.最重要的是,你可以利用Amazon EMR中的Apache Spark,Hive和Presto之类的开源工具来处理和分 ...
- 直播 | Apache Kylin & Apache Hudi Meetup
千呼万唤始出来,Meetup 直播终于来啦- 本次线上 Meetup 由 Apache Kylin 与 Apache Hudi 社区联合举办,将于 3 月 14 日晚进行直播,邀请到来自丁香园.腾讯. ...
- 官宣!ASF官方正式宣布Apache Hudi成为顶级项目
马萨诸塞州韦克菲尔德(Wakefield,MA)- 2020年6月 - Apache软件基金会(ASF).350多个开源项目和全职开发人员.管理人员和孵化器宣布:Apache Hudi正式成为Apac ...
随机推荐
- Day003 包机制
包机制 为了更好地组织类,Java提供了包机制,用于区别类名的命名空间. 包语句的语法格式为: package pkg1[.pkg2[.pkg3....]]; 一般利用公司的域名倒置作为包名; 例如: ...
- Python设计模式知多少
设计模式 设计模式是前辈们经过相当长的一段时间的试验和错误总结出来的最佳实践.我找到的资料列举了以下这些设计模式:工厂模式.抽象工厂模式.单例模式.建造者模式.原型模式.适配器模式.桥接模式.过滤器模 ...
- Git 系列教程(12)- 分支的新建与合并
实际工作场景 可能会遇到的工作流 开发某个网站 为实现某个新的用户需求,创建一个分支 在这个分支上开展新工作 正在此时,你突然接到一个电话说有个很严重的问题需要紧急修补,你将按照如下方式来处理: 切换 ...
- 2.HTML案例二 头条页面
4 HTML案例-头条页面 4.1 案例效果 4.2 案例分析 4.2.1 div布局的进阶 想要将div布局成案例效果,首先需要对多个div进行区分,再分别设置每一个div自身的效果. 1)div的 ...
- VS·.Net WCF多项目调试方法
阅文时长 | 0.12分钟 字数统计 | 252.8字符 主要内容 | 1.引言&背景 2.声明与参考资料 『VS·.Net WCF多项目调试方法』 编写人 | SCscHero 编写时间 | ...
- hive beeline详解
Hive客户端工具后续将使用Beeline 替代HiveCLI ,并且后续版本也会废弃掉HiveCLI 客户端工具,Beeline是 Hive 0.11版本引入的新命令行客户端工具,它是基于SQLLi ...
- Ubuntu 配置本地源
Ubuntu 配置本地源 操作系统 Ubuntu 20.04.2 LTS 一.挂载 iso 到本地 mount -t iso9660 -o loop /dev/sr0 /media/cdrom //- ...
- Linux上使用iSCSI概述
iSCSI简介 1. scsi和iscsi SCSI技术是存储设备最基本的标准协议,通常需要设备互相靠近并用SCSI总线连接,因此受到物理环境的限制 iSCSI(Internet Small Comp ...
- CentOS7安装vncserver(启动失败及连接黑屏解决办法)
CentOS7安装vncserver(启动失败及连接黑屏解决办法) 转载weixin_34167043 最后发布于2017-11-09 15:11:00 阅读数 42 收藏 展开 AutoSAR入门 ...
- Java 常见转义字符
什么是转义符 计算机某些特殊字符是无法直接用字符表示,可以通过转义符 ( \ ) 的方式表示,也就是将原字符的含义转为其他含义. 比如,如果想要输出一个单引号,你可能会想到 char letter = ...