Intriguing Properties of Contrastive Losses
[Chen T. & Li L. Intriguing Properties of Contrastive Losses. arXiv preprint arXiv 2011.02803, 2020.]
概
普通的对比损失有一种广义的表示方法, 改变alignment和distribution项的权重比有何影响? 同时, 改用不同的先验分布会有什么影响?
另外作者还发现了一种特征压制的现象, 即对比损失会更容易抓住一些简单的特征(如果存在), 而忽视不易往往更为有效的特征, 且这种现象不会随着网络的大小, 训练的次数或者batch size等等因素变化而产生明显变化.
主要内容
广义对比损失
普通的对比损失
\]
广义的对比损失
\]
第一项为\(\mathcal{L}_{alignment}\), 第二项为\(\mathcal{L}_{distribution}\), 第一项会使得正样本之间靠近, 第二项使得负样本之间趋于一个先验分布, 普通的对比损失是以均匀分布为先验的(直观上这种情况下的熵最大). 从互信息的角度来理解:
\]
\(H(X)\)对应\(\mathcal{L}_{distribution}\), \(-H(X|Y)\)对应\(\mathcal{L}_{alignment}\).
不同的先验
作者首先研究了不同的先验分布会有什么影响(其算法涉及到sliced wasserstein distance, 暂时不想了解):

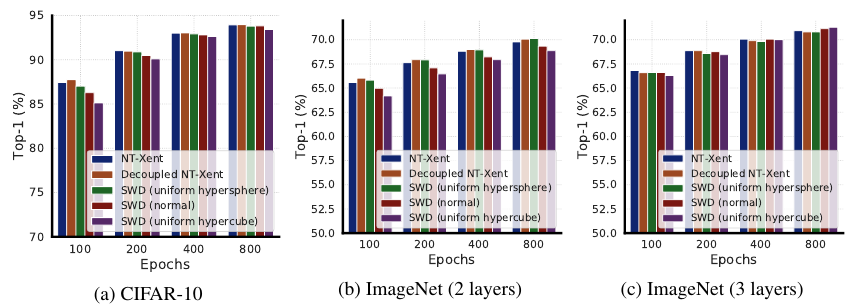
如下图所示, 在CIFAR-10上差距不大, ImageNet上当projection head只有两层的时候有差距但是增加到三层的时候又没啥差距了.
不同的权重比\(\tau, \lambda\)
现在广义对比损失上有两个我们可以调节的参数, 包括temperature \(\tau\)和\(\lambda\).
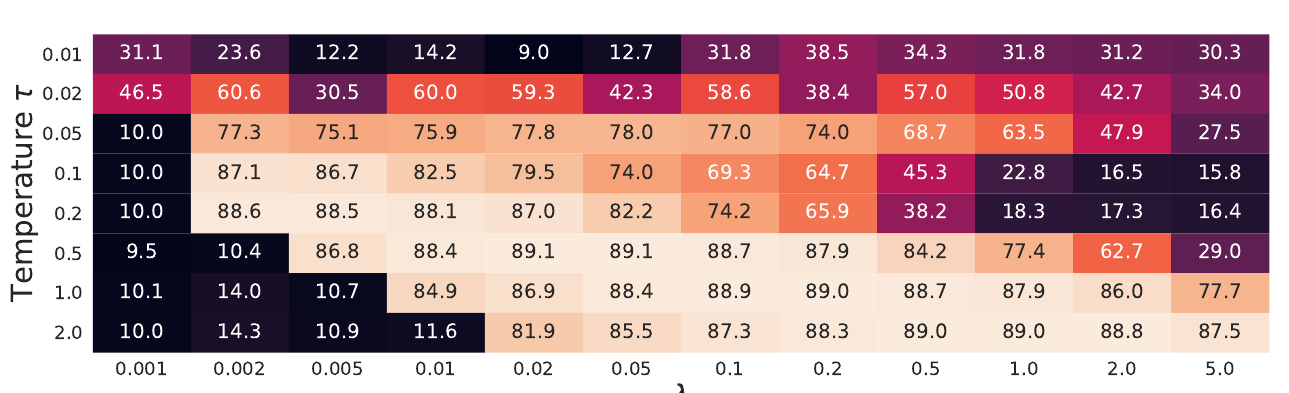
如上图所示, 作者称二者的关系是相反的, 即较大的\(\tau\)往往需要较小的\(\lambda\), 较小的\(\tau\)往往需要较大的\(\lambda\).
Feature Suppression
作者发现比较简单的特征更容易被学习到, 且该部分特征会阻碍网络学习其他的更加复杂的特征.
DigitOnImageNet dataset
第一个实验是, 在一些图片上加上一些数字:

注: 这些数字是在augmentation之前加的, 也就是说正样本之间是会共享这部分数字信息的.
用这个数据集在
监督学习
对比学习, 并且变换\(\tau\)
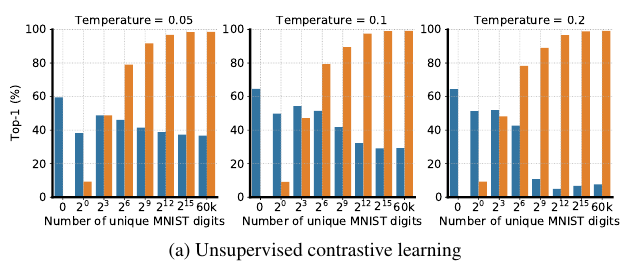
可以发现, 这部分共享信息对于有监督训练分类网络(关于Imagenet)是几乎没有影响的. 但是在对比学习中, 随着数字的量的增加, 提取到的特征大部分是用于分类数字而不是占据更多共享信息的图片. 虽然小一点的\(\tau\)能够在一定程度上缓解这一状况. 这说明, 对比学习很容易被一些小的简单的共享信息所误导, 去学习一些简单的特征, 而且这些特征会阻碍进一步学习更复杂的特征.
RandBit dataset
这部分实验进一步说明, 这些简单特征甚至能够完全抹杀复杂的特征.
这部分数据集的构造方式是, 对普通的RGB图片添加新的channels, 每一层channel要么都是\(1\), 要么都是\(0\)(看代码似乎是这个意思, 不过此时共享的信息应该是\(n\)?).
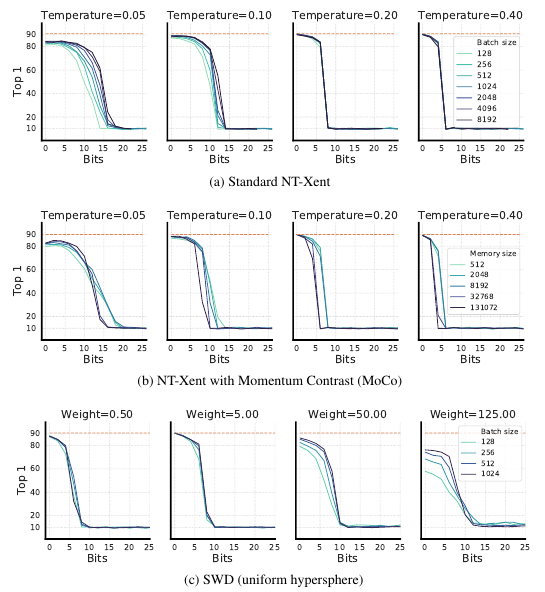
结果如上图, 可以发现, 这一点点的几个bits的共享的信息就能够使得对比损失效果骤降甚至是完全失效, 且改变\(\tau\), batch size, 或者是先验分布, 以及训练的框架都不能有所改善.
代码
Intriguing Properties of Contrastive Losses的更多相关文章
- Intriguing properties of neural networks
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! https://arxiv.org/abs/1312.6199v4 Abstract 深度神经网络是近年来在语音和视觉识别任务中取得最新性 ...
- (转) AdversarialNetsPapers
本文转自:https://github.com/zhangqianhui/AdversarialNetsPapers AdversarialNetsPapers The classical Pap ...
- ICLR 2014 International Conference on Learning Representations深度学习论文papers
ICLR 2014 International Conference on Learning Representations Apr 14 - 16, 2014, Banff, Canada Work ...
- (转) Awesome - Most Cited Deep Learning Papers
转自:https://github.com/terryum/awesome-deep-learning-papers Awesome - Most Cited Deep Learning Papers ...
- On Explainability of Deep Neural Networks
On Explainability of Deep Neural Networks « Learning F# Functional Data Structures and Algorithms is ...
- 瞎谈CNN:通过优化求解输入图像
本文同步自我的知乎专栏: From Beijing with Love 机器学习和优化问题 很多机器学习方法可以归结为优化问题,对于一个参数模型,比如神经网络,用来表示的话,训练模型其实就是下面的参数 ...
- 用Caffe生成对抗样本
同步自我的知乎专栏:https://zhuanlan.zhihu.com/p/26122612 上篇文章 瞎谈CNN:通过优化求解输入图像 - 知乎专栏 中提到过对抗样本,这篇算是针对对抗样本的一个小 ...
- (转)Is attacking machine learning easier than defending it?
转自:http://www.cleverhans.io/security/privacy/ml/2017/02/15/why-attacking-machine-learning-is-easier- ...
- My deep learning reading list
My deep learning reading list 主要是顺着Bengio的PAMI review的文章找出来的.包括几本综述文章,将近100篇论文,各位山头们的Presentation.全部 ...
随机推荐
- C/C++ Qt 数据库与ComBox多级联动
Qt中的SQL数据库组件可以与ComBox组件形成多级联动效果,在日常开发中多级联动效果应用非常广泛,例如当我们选择指定用户时,我们让其在另一个ComBox组件中列举出该用户所维护的主机列表,又或者当 ...
- Leetcode中的SQL题目练习(一)
595. Big Countries https://leetcode.com/problems/big-countries/description/ Description name contine ...
- Kafka 集群安装部署
2.1 安装部署 2.1.1 集群规划 192.168.1.102 192.168.1.103 192.168.1.104 zookeeper zookeeper zookeeper kafka ka ...
- oracle中的数组
Oracle中的数组分为固定数组和可变数组. 一.固定数组固定数组:在定义的时候预定义了数组的大小,在初始化数组时如果超出这个大小,会提示ORA-06532:超出小标超出限制!语法: T ...
- Linux下查看JDK安装路径
在安装好Git.JDK和jenkins之后,就需要在jenkins中进行对应的设置,比如在全局工具配置模块,需要写入JDK的安装路径. 这篇博客,介绍几种常见的在Linux中查看JDK路径的方法... ...
- Mave 下载与安装
一,Maven 介绍 我们在开发中经常需要依赖第三方的包,包与包之间存在依赖关系,版本间还有兼容性问题,有时还需要将旧的包升级或降级,当项目复杂到一定程度时包管理变得非常重要.Maven是当前最受欢迎 ...
- 【Java多线程】Java 原子操作类API(以AtomicInteger为例)
1.java.util.concurrent.atomic 的包里有AtomicBoolean, AtomicInteger,AtomicLong,AtomicLongArray, AtomicRef ...
- maven管理本地jar包
maven作为包管理工具,好处不必多说.但是有些情况,比如需要引入第三方包,如快递鸟,支付宝,微信等jar包(当然有可能直接提供maven依赖),如果直接下载到本地之后,怎么整合到自己的maven工程 ...
- 看看线程特有对象ThreadLocal
作用:设计线程安全的一种技术. 在使用多线程的时候,如果多个线程要共享一个非线程安全的对象,常用的手段是借助锁来实现线程的安全.线程安全隐患的前提是多线程共享一个不安全的对象 ,那么有没有办法让线程之 ...
- 使用Booststrap布局网页页面
<!DOCTYPE html><html lang="zh-CN"><head> <meta charset="utf-8&qu ...