终于彻底搞清楚了spin-lock 之一次CPU问题定位过程总结
首先这个问题,我只是其中参与者之一。但这个问题很有参考意义,特记录下来。
还有我第一次用“彻底”这个词,不知道会不会有人喷?其实,还有一些问题,也不是特别清楚。比如说什么是CPU流水(我又不是硬件工程师)。
问题现象
现网数据库切换到新的物理服务器时,出现了业务查询超时异常问题。
详细过程不再熬述了,总之对比新旧硬件环境的不同。初步怀疑是新服务器CPU的问题。
定位过程
现网肯定不能不停重试,于是在本地服务器用sysbench压测。
查看CPU占比,sys占比特别高。vmstat显示context switch高。
通过perf top查看调用栈。
调用栈如下。
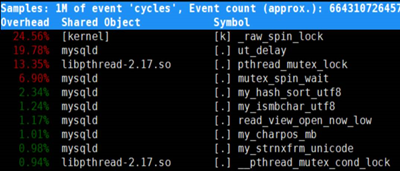
问题原因
如上,可以看到调用栈,spin_lock占用了很大比例。
与美团的CPU原因类似。因为某些你懂的原因,具体细节就不多说了。因为我主要是讲解一下何为spin lock。
而且看完全篇,你就会发现其实内容远比你想象中的多。
https://dev.mysql.com/doc/refman/8.0/en/innodb-parameters.html#sysvar_innodb_spin_wait_pause_multiplier
什么是自旋锁
多线程中,对共享资源进行访问,为了防止并发引起的相关问题,通常都是引入锁的机制来处理并发问题。
获取到资源的线程A对这个资源加锁,其他线程比如B要访问这个资源首先要获得锁,而此时A持有这个资源的锁,只有等待线程A逻辑执行完,释放锁,这个时候B才能获取到资源的锁进而获取到该资源。
这个过程中,A一直持有着资源的锁,那么没有获取到锁的其他线程比如B怎么办?通常就会有两种方式:
1. 一种是没有获得锁的进程就直接进入阻塞(BLOCKING),这种就是互斥锁
2. 另外一种就是没有获得锁的进程,不进入阻塞,而是一直循环着,看是否能够等到A释放了资源的锁。
自旋锁(spin lock)是一种非阻塞锁,也就是说,如果某线程需要获取锁,但该锁已经被其他线程占用时,该线程不会被挂起,而是在不断的消耗CPU的时间,不停的试图获取锁。
自旋锁避免了进程上下文的调度开销,因此对于线程只会阻塞很短时间的场合是有效的。因此操作系统的实现在很多地方往往用自旋锁。
为什么要使用自旋锁
互斥锁有一个缺点,他的执行流程是这样的 托管代码 - 用户态代码 - 内核态代码、上下文切换开销与损耗,假如获取到资源锁的线程A立马处理完逻辑释放掉资源锁,如果是采取互斥的方式,那么线程B从没有获取锁到获取锁这个过程中,就要用户态和内核态调度、上下文切换的开销和损耗。所以就有了自旋锁的模式,让线程B就在用户态循环等着,减少消耗。
自旋锁的本质
Critical Section Integration (CSI)
本质上自旋锁产生的效果就是一个CPU core 按顺序逐一执行关键区域的代码,所以在我们的优化代码中将关键区域的代码以函数的形式表现出来,当线程抢锁的时候,如果发现有冲突,那么就将自己的函数挂在锁拥有者的队列上,然后使用MCS进入spinning 状态,而锁拥有者在执行完自己的关键区域之后,会检测是否还有其他锁的请求,如果有那么依次执行并且通知申请者,然后返回。可以看到通过这个方法所有的共享数据更新都是在CPU私用缓存内完成,能够大幅度减少共享数据的迁移,由于减少了迁移时间,那么加快了关键区域运行时间最终也减少了冲突可能性。
提升自旋锁spinlock的性能-pause指令
自旋锁 pause版权看源码的时候get的一个新的知识点,可以提升自旋锁spinlock的性能-pause指令,看到的源码如下:
# define UT_RELAX_CPU() asm ("pause" )
# define UT_RELAX_CPU() __asm__ __volatile__ ("pause")
经过上网查找资料pause指令。当spinlock执行lock()获得锁失败后会进行busy loop,不断检测锁状态,尝试获得锁。这么做有一个缺陷:频繁的检测会让流水线上充满了读操作。另外一个线程往流水线上丢入一个锁变量写操作的时候,必须对流水线进行重排,因为CPU必须保证所有读操作读到正确的值。流水线重排十分耗时,影响lock()的性能。
自旋锁spinlock剖析与改进Pause指令解释(from intel):Description Improves the performance of spin-wait loops. When executing a “spin-wait loop,” a Pentium 4 or Intel Xeon processor suffers a severe performance penalty when exiting the loop because it detects a possible memory order violation. The PAUSE instruction provides a hint to the processor that the code sequence is a spin-wait loop. The processor uses this hint to avoid the memory order violation in most situations, which greatly improves processor performance. For this reason, it is recommended that a PAUSE instruction be placed in all spin-wait loops.
MySQL spin lock处理代码
MySQL关于spin lock的部分代码。如下代码可以看到MySQL默认作了30次(innodb_sync_spin_loops=30)mutex检查后,才放弃占用CPU资源。
rw_lock_sx_lock_func( // 加sx锁函数
{
/* Spin waiting for the lock_word to become free */
os_rmb;
while (i < srv_n_spin_wait_rounds
&& lock->lock_word <= X_LOCK_HALF_DECR) {
if (srv_spin_wait_delay) {
ut_delay(ut_rnd_interval(
0, srv_spin_wait_delay)); // 加锁失败,调用ut_delay
}
i++;
}
spin_count += i;
if (i >= srv_n_spin_wait_rounds) {
os_thread_yield(); //暂停当前正在执行的线程对象(及放弃当前拥有的cup资源)
} else {
goto lock_loop; //MySQL关于spin lock的部分代码。如下代码可以看到MySQL默认作了30次(innodb_sync_spin_loops=30)mutex检查后,才放弃占用CPU资源。 os_thread_yield(); //暂停当前正在执行的线程对象(及放弃当前拥有的cup资源) }
...
ulong srv_n_spin_wait_rounds = 30;
ulong srv_spin_wait_delay = 6;
注:上面代码,线程中的yield()方法说明
yield 多线程版权Thread.yield()方法作用是:暂停当前正在执行的线程对象(及放弃当前拥有的cup资源),并执行其他线程。yield()做的是让当前运行线程回到可运行状态,以允许具有相同优先级的其他线程获得运行机会。因此,使用yield()的目的是让相同优先级的线程之间能适当的轮转执行。
每次ut_delay默认执行pause指令300次( innodb_spin_wait_delay=6*50)
ut_delay(
/*=====*/
ulint delay) /*!< in: delay in microseconds on 100 MHz Pentium */
{
ulint i, j;
UT_LOW_PRIORITY_CPU();
j = 0;
for (i = 0; i < delay * 50; i++) {
j += i;
UT_RELAX_CPU();
}
UT_RESUME_PRIORITY_CPU();
return(j);
}
# define UT_RELAX_CPU() asm ("pause" )
# define UT_RELAX_CPU() __asm__ __volatile__ ("pause")
操作系统中,SYS和USER这两个不同的利用率代表着什么?
操作系统中,SYS和USER这两个不同的利用率代表着什么?或者说二者有什么区别?
简单来说,CPU利用率中的SYS部分,指的是操作系统内核(Kernel)使用的CPU部分,也就是运行在内核态的代码所消耗的CPU,最常见的就是系统调用(SYS CALL)时消耗的CPU。而USER部分则是应用软件自己的代码使用的CPU部分,也就是运行在用户态的代码所消耗的CPU。比如ORACLE在执行SQL时,从磁盘读数据到db buffer cache,需要发起read调用,这个read调用主要是由操作系统内核包括设备驱动程序的代码在运行,因此消耗CPU计算到SYS部分;而ORACLE在解析从磁盘中读到的数据时,则只是ORACLE自己的代码在运行,因此消耗的CPU计算到USER部分。
那么SYS部分的CPU主要会由哪些操作或是系统调用产生呢?具体如下所示。
1> I/O操作。比如读写文件、访问外设、通过网络传输数据等。这部分操作一般不会消耗太多的CPU,因为主要的时间消耗会在1/O操作的设备上。比如从磁盘读文件时,主要的时间在磁盘内部的操作上,而消耗的CPU时间只占I/O操作响应时间的一少部分。只有在过高的并发I/O时才可能会使得SYS CPU 有所增加。
2> 内存管理。比如应用程序向操作系统申请内存,操作系统维护系统可用内存,交换空间换页等。其实与ORACLE类似,越大的内存,越频繁的内存管理操作,CPU的消耗会越高。
3> 进程调度。这部分CPU的使用,在于操作系统中运行队列的长短,越长的运行队列,表明越多的进程需要调度,那么内核的负担就越高。
4> 其他,包括进程间通信、信号量处理、设备驱动程序内部的一些活动等等。
什么是用户态?什么是内核态?如何区分?
一般现代CPU都有几种不同的指令执行级别。
在高执行级别下,代码可以执行特权指令,访问任意的物理地址,这种CPU执行级别就对应着内核态。
而在相应的低级别执行状态下,代码的掌控范围会受到限制。只能在对应级别允许的范围内活动。
举例:
intel x86 CPU有四种不同的执行级别0-3,linux只使用了其中的0级和3级分别来表示内核态和用户态。

系统调用与context switch
进程上下文切换,是指从一个进程切换到另一个进程运行。而系统调用过程中一直是同一个进程在运行
系统调用过程通常称为特权模式切换,而不是上下文切换。当进程调用系统调用或者发生中断时,CPU从用户模式(用户态)切换成内核模式(内核态),此时,无论是系统调用程序还是中断服务程序,都处于当前进程的上下文中,并没有发生进程上下文切换。
当系统调用或中断处理程序返回时,CPU要从内核模式切换回用户模式,此时会执行操作系统的调用程序。如果发现就需队列中有比当前进程更高的优先级的进程,则会发生进程切换:当前进程信息被保存,切换到就绪队列中的那个高优先级进程;否则,直接返回当前进程的用户模式,不会发生上下文切换。
system call
System calls in most Unix-like systems are processed in kernel mode, which is accomplished by changing the processor execution mode to a more privileged one, but no process context switch is necessary
context switch
Some operating systems(Not include Linux) also require a context switch to move between user mode and kernel mode tasks. The process of context switching can have a negative impact on system performance
通过vmstat查看context switch
一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如:
root@local:~# vmstat 2 1
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 3498472 315836 3819540 0 0 0 1 2 0 0 0 100 0

context switch 高,导致的争用其它案例
有很多种情况都会导致 context switch。MySQL 中的 mutex 和 RWlock 在获取不成功后,短暂spin,还不成功,就会发生 context switch,sleep,等待唤醒。
在 MySQL中,mutex 和 RWlock导致的 context switch,一般在show global status,show engine innodb mutex,show engine innodb status,performance_schema等中会体现出来,针对不同的mutex和RWlock等待,可以采取不同的优化措施。
除了MySQL的mutex和RWlock,还发现一种情况,是MySQL外的mutex竞争导致context switch高。
典型症状:
MySQL running 高,但系统 qps、tps 低
系统context switch很高,每秒超过200K
在 MySQL 内存查不到mutex和RWlock竞争信息
SYS CPU 高,USER CPU 低
并发执行的SQL中出现timestamp字段,MySQL的time_zone设置为system
分析
对于使用 timestamp 的场景,MySQL 在访问 timestamp 字段时会做时区转换,当 time_zone 设置为 system 时,MySQL 访问每一行的 timestamp 字段时,都会通过 libc 的时区函数,获取 Linux 设置的时区,在这个函数中会持有mutex,当大量并发SQL需要访问 timestamp 字段时,会出现 mutex 竞争。
MySQL 访问每一行都会做这个时区转换,转换完后释放mutex,所有等待这个 mutex 的线程全部唤醒,结果又会只有一个线程会成功持有 mutex,其余又会再次sleep,这样就会导致 context switch 非常高但 qps 很低,系统吞吐量急剧下降。
解决办法:设置time_zone=’+8:00’,这样就不会访问 Linux 系统时区,直接转换,避免了mutex问题。
问题解决对策
通过修改spin lock相应参数,问题现象得到了缓解。
至于CPU硬件本身是不是有可能存在问题,这个是留待他人解决吧。
可不能走自己的路,让他人无路可走。
总结
spin lock通过pause指令强制占有CPU,而使自己不被换出CPU,减少context switch发生的频率。从而实现系统的高效运行。
此例问题的原因是因为新的物理服务器的CPU PAUSE指令周期远小于旧的物理服务器。导致CPU context switch显著高于旧的服务器,从而影响user的运行(表象为查询超时)。
一两句话,能说清楚的问题,我居然说了这么多。看来,能把简单的事情,说复杂也是一种本事。哈哈。
参考资料
实在是太多了,就不列出来了。在此感谢那些提供了信息分享的朋友们。如引用了您的原文,但没有指出出处,还请见谅。
终于彻底搞清楚了spin-lock 之一次CPU问题定位过程总结的更多相关文章
- Linux内核同步机制之(四):spin lock【转】
转自:http://www.wowotech.net/kernel_synchronization/spinlock.html 一.前言 在linux kernel的实现中,经常会遇到这样的场景:共享 ...
- 14.4.9 Configuring Spin Lock Polling 配置Spin lock 轮询:
14.4.9 Configuring Spin Lock Polling 配置Spin lock 轮询: 很多InnoDB mutexes 和rw-locks 是保留一小段时间,在一个多核系统, 它可 ...
- Linux内核同步机制之(五):Read Write spin lock【转】
一.为何会有rw spin lock? 在有了强大的spin lock之后,为何还会有rw spin lock呢?无他,仅仅是为了增加内核的并发,从而增加性能而已.spin lock严格的限制只有一个 ...
- spin lock自旋锁 双链表操作(多线程安全)(Ring0)
通过spin lock自旋锁 ,为每个链表都定义并初始化一个锁,在需要向该链表插入或移除节点时不使用前面介绍的普通函数,而是使用如下方法: ExInterlockedInsertHeadList(&a ...
- 自旋锁(Spin Lock)
转载请您注明出处: http://www.cnblogs.com/lsh123/p/7400625.html 0x01 自旋锁简介 自旋锁也是一种同步机制,它能保证某个资源只能被一个线程所拥有, ...
- Synchronized和Lock, 以及自旋锁 Spin Lock, Ticket Spin Lock, MCS Spin Lock, CLH Spin Lock
Synchronized和Lock synchronized是一个关键字, Lock是一个接口, 对应有多种实现. 使用synchronized进行同步和使用Lock进行同步的区别 使用synchro ...
- Linux内核同步 - Read/Write spin lock
一.为何会有rw spin lock? 在有了强大的spin lock之后,为何还会有rw spin lock呢?无他,仅仅是为了增加内核的并发,从而增加性能而已.spin lock严格的限制只有一个 ...
- spin lock的理解
为什么在spin lock保护的代码里面不允许有休眠的操作呢? 因为spin lock不是空实现的前提下(内核没关抢占,或者是SMP打开),spin lock中是关抢占的,如果一个进程A拿到锁,内核抢 ...
- Pthreads并行编程之spin lock与mutex性能对比分析(转)
POSIX threads(简称Pthreads)是在多核平台上进行并行编程的一套常用的API.线程同步(Thread Synchronization)是并行编程中非常重要的通讯手段,其中最典型的应用 ...
随机推荐
- Golang学习(用代码来学习) - 第三篇
type Books struct { title string author string subject string id int } /** 结构体的学习 */ func struct_tes ...
- Vue(6)v-on指令的使用
v-on 监听事件 可以用 v-on 指令监听 DOM 事件,并在触发时运行一些 JavaScript 代码.事件代码可以直接放到v-on后面,也可以写成一个函数.示例代码如下: <div id ...
- Linux用户体系
1.系统中和用户相关的文件 (1)/etc/passwd:记录系统用户信息文件 (2)/etc/shadow:系统用户密码文件 (3)/etc/group:组用户信息文件 (4)/etc/gshado ...
- 7.6、openstack网络拓扑
1.openstack官方架构图: 2.openstack服务常用服务的端口号: mysql:3306 keystone:5000 memcache:11211 rabbitmq:5672 rabbi ...
- 【译】GO语言:管理多个错误
原文:https://medium.com/a-journey-with-go/go-multiple-errors-management-a67477628cf1 关于开发者使用Go遇到的最大挑 ...
- 谁知道百会CRM跟Zoho是一家公司吗?
说到ZohoCRM,无论是搜索引擎还是信息网站,总会有无数的身影.很多人不知道这两家公司的关系,甚至认为百会和Zoho是一家公司.那么,百会CRM和Zoho属于同一类公司吗?它们之间有什么关系?今天小 ...
- centos 8 安装 PostgreSQL-10
下载 PostgreSQL-10软件包 官网地址:https://www.postgresql.org/ 选择自己的版本 此处已postgresql-10.16-2-linux-x64.run安装为例 ...
- Mysql 中字符串的截取
一.从左开始截取字符串 用法:left(str, length),即:left(被截取字符串, 截取长度) mysql> SELECT LEFT('hello,world',3); +----- ...
- PHP7与php5
php在2015年12月03日发布了7.0正式版,带来了许多新的特性,以下是不完全列表: 性能提升:PHP7比PHP5.6性能提升了两倍. Improved performance: PHP 7 is ...
- 打开设置windows10内置linux功能-启用linux子系统
第一步设置开发者模式 步骤:windows+s打开娜娜,输入设置,并点击. 点击更新与安全 点击开发者选项,选择开发者模型,弹出的对话框选确定之后等待安装完毕. 第二步:安装linux 点击确定后等待 ...