HashMap 中7种遍历方式的性能分析
随着 JDK 1.8 Streams API 的发布,使得 HashMap 拥有了更多的遍历的方式,但应该选择那种遍历方式?反而成了一个问题。
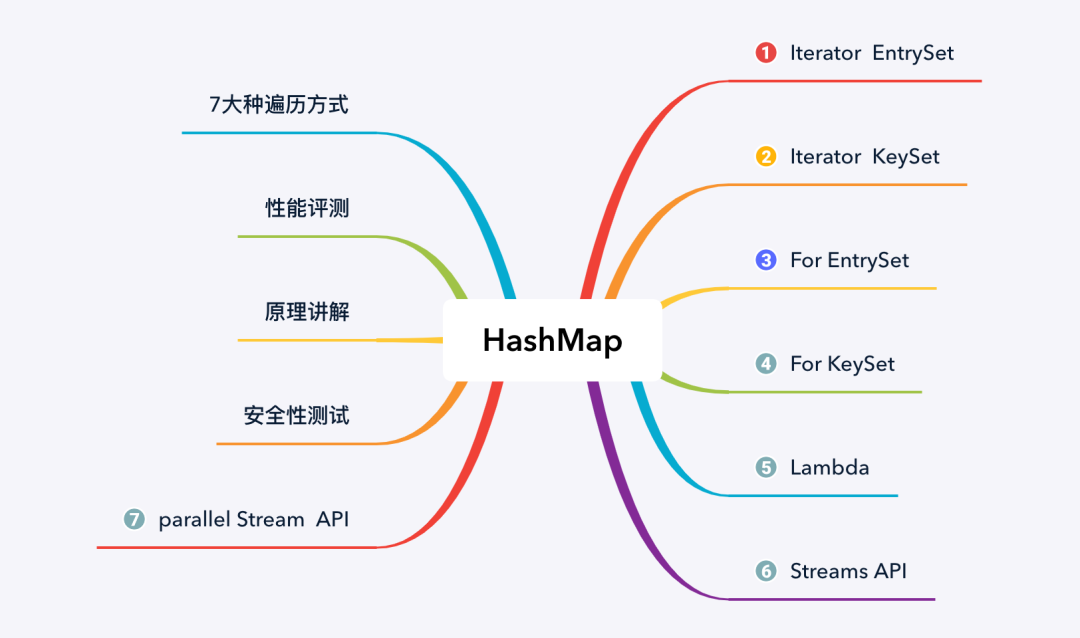
本文先从 HashMap 的遍历方法讲起,然后再从性能、原理以及安全性等方面,来分析 HashMap 各种遍历方式的优势与不足,本文主要内容如下图所示:
HashMap遍历
HashMap 遍历从大的方向来说,可分为以下 4 类:
- 迭代器(Iterator)方式遍历;
- For Each 方式遍历;
- Lambda 表达式遍历(JDK 1.8+);
- Streams API 遍历(JDK 1.8+)。
但每种类型下又有不同的实现方式,因此具体的遍历方式又可以分为以下 7 种:
- 使用迭代器(Iterator)EntrySet 的方式进行遍历;
- 使用迭代器(Iterator)KeySet 的方式进行遍历;
- 使用 For Each EntrySet 的方式进行遍历;
- 使用 For Each KeySet 的方式进行遍历;
- 使用 Lambda 表达式的方式进行遍历;
- 使用 Streams API 单线程的方式进行遍历;
- 使用 Streams API 多线程的方式进行遍历。
接下来我们来看每种遍历方式的具体实现代码。
1.迭代器 EntrySet
@Test
public void testIterator() {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Oracle Database");
// 遍历
Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> entry = iterator.next();
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}
运行结果:

2.迭代器 KeySet
@Test
public void testKeySet() {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Test KeySet");
// 遍历
Iterator<Integer> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
Integer key = iterator.next();
System.out.println(key + ":" + map.get(key));
}
}
运行结果:
3.ForEach EntrySet
@Test
public void testForEachEntrySet() {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Test ForEach EntrySet");
// 遍历
for (Map.Entry<Integer, String> entry : map.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}
运行结果:
4.ForEach KeySet
@Test
public void testForEachKeySet() {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Test ForEach KeySet");
// 遍历
for (Integer key : map.keySet()) {
System.out.println(key + ":" + map.get(key));
}
}
运行结果:

5.Lambda
@Test
public void testLambda() {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Test Lambda");
// 遍历
map.forEach((key, value) -> {
System.out.println(key + ":" + value);
});
}
运行结果:

6.Streams API 单线程
@Test
public void testStreamApi() {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Test Stream API");
// 遍历
map.entrySet().stream().forEach((entry) -> {
System.out.println(entry.getKey() + ":" + entry.getValue());
});
}
运行结果:

7.Streams API 多线程
@Test
public void testParallelStreamApi() {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Test Parallel Stream API");
// 遍历
map.entrySet().parallelStream().forEach((entry) -> {
System.out.println(entry.getKey() + ":" + entry.getValue());
});
}
运行结果:
性能分析
接下来我们使用 Oracle 官方提供的性能测试工具 JMH(Java Microbenchmark Harness,JAVA 微基准测试套件)来测试一下这 7 种循环的性能。
首先我们需要引入JMH框架,本次构建依赖使用工具为Gradle,引入配置如下:
implementation "org.openjdk.jmh:jmh-core:1.23"
implementation "org.openjdk.jmh:jmh-generator-annprocess:1.23"
如果使用Maven,可引入如下配置:
<!-- https://mvnrepository.com/artifact/org.openjdk.jmh/jmh-core -->
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.23</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.openjdk.jmh/jmh-generator-annprocess -->
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.23</version>
<scope>provided</scope>
</dependency>
编写性能测试代码如下:
/**
* @version V1.0
* @description HashMap 的 7 种遍历方式+性能分析
* @author zhangzg
* @date 2021/6/25 13:12
*/
//@BenchmarkMode(Mode.Throughput) // 测试类型:吞吐量
@BenchmarkMode(Mode.AverageTime) // 测试类型:平均消耗时间
//@OutputTimeUnit(TimeUnit.MILLISECONDS)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@Warmup(iterations = 4, time = 1, timeUnit = TimeUnit.SECONDS) // 预热 4 轮,每次 1s
@Measurement(iterations = 10, time = 3, timeUnit = TimeUnit.SECONDS) // 测试 10 轮,每次 3s
@Fork(1) // fork 1 个线程
@State(Scope.Thread) // 每个测试线程一个实例
public class HashMapTest { static Map<Integer, String> map = new HashMap() {
{
for(int var1 = 0; var1 < 2; ++var1) {
this.put(var1, "Kevin:" + var1);
} }
}; public static void main(String[] args) throws RunnerException {
// 启动基准测试
Options opt = new OptionsBuilder()
.include(HashMapTest.class.getSimpleName()) // 要导入的测试类
.output("E:/IDEAWorkSpaces/Test/src/main/java/com/kevin/performance/jmh-map2.log") // 输出测试结果的文件
.build();
new Runner(opt).run(); // 执行测试
} /**
* Iterator遍历 entrySet
*/
@Benchmark
public void entrySet() {
// 遍历
Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> entry = iterator.next();
Integer k = entry.getKey();
String v = entry.getValue();
}
} /**
* Foreach遍历 entrySet
*/
@Benchmark
public void forEachEntrySet() {
// 遍历
for (Map.Entry<Integer, String> entry : map.entrySet()) {
Integer k = entry.getKey();
String v = entry.getValue();
}
} /**
* Iterator遍历 keySet
*/
@Benchmark
public void keySet() {
Iterator<Integer> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
Integer k = iterator.next();
String v = map.get(k);
}
} /**
* Foreach遍历 keySet
*/
@Benchmark
public void forEachKeySet() {
for (Integer key : map.keySet()) {
Integer k = key;
String v = map.get(k);
}
} /**
* Lambda遍历
*/
@Benchmark
public void lambda() {
map.forEach((key, value) -> {
Integer k = key;
String v = value;
});
} /**
* 单线程遍历
*/
@Benchmark
public void streamApi() {
map.entrySet().stream().forEach((entry) -> {
Integer k = entry.getKey();
String v = entry.getValue();
});
} /**
* 多线程遍历
*/
public void parallelStreamApi() {
map.entrySet().parallelStream().forEach((entry) -> {
Integer k = entry.getKey();
String v = entry.getValue();
});
}
}
所有被添加了 @Benchmark 注解的方法都会被测试(由于 parallelStream 为多线程版本性能一定由于其他单线程,故不参与本次测试),测试结果如下:
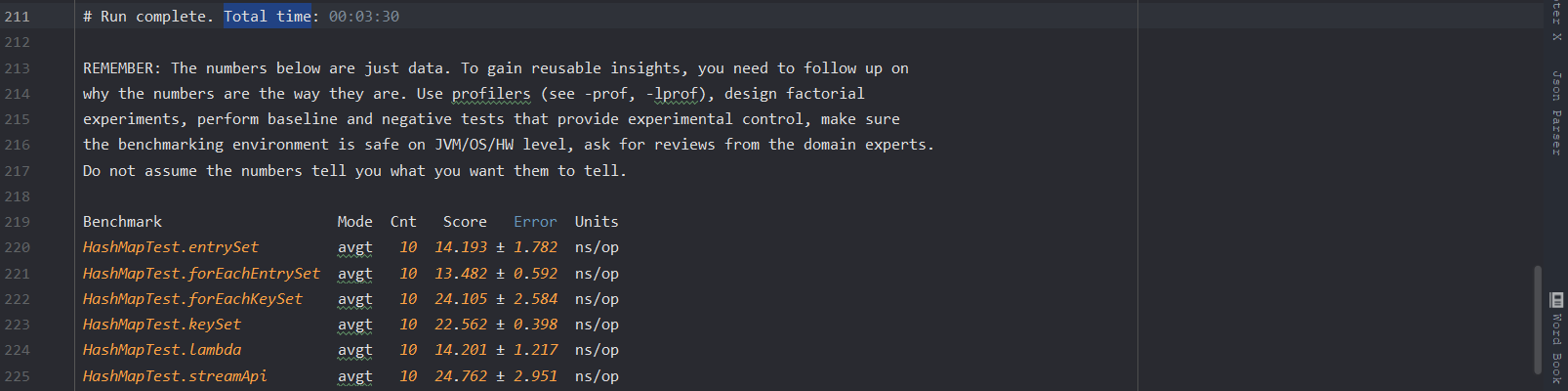
其中 Units 为 ns/op 意思是执行完成时间(单位为纳秒),而 Score 列为平均执行时间, ± 符号表示误差。从以上结果可以看出,两个 entrySet 的性能相近,并且执行速度最快,接下来是 stream ,然后是两个 keySet,性能最差的是 KeySet 。
结论
从以上结果可以看出 entrySet 的性能比 keySet 的性能高出了一倍之多,因此我们应该尽量使用 entrySet 来实现 Map 集合的遍历。
字节码分析
要理解以上的测试结果,我们需要把所有遍历代码通过 javac 编译成字节码来看具体的原因。
编译后,我们使用 Idea 打开字节码,内容如下:
public class HashMapTest {
static Map<Integer, String> map = new HashMap() {
{
for(int var1 = 0; var1 < 2; ++var1) {
this.put(var1, "Kevin:" + var1);
}
}
};
public HashMapTest() {
}
public static void main(String[] var0) {
entrySet();
keySet();
forEachEntrySet();
forEachKeySet();
lambda();
streamApi();
parallelStreamApi();
}
public static void entrySet() {
Iterator var0 = map.entrySet().iterator();
while(var0.hasNext()) {
Entry var1 = (Entry)var0.next();
System.out.println(var1.getKey() + ":" + (String)var1.getValue());
}
}
public static void keySet() {
Iterator var0 = map.keySet().iterator();
while(var0.hasNext()) {
Integer var1 = (Integer)var0.next();
System.out.println(var1 + ":" + (String)map.get(var1));
}
}
public static void forEachEntrySet() {
Iterator var0 = map.entrySet().iterator();
while(var0.hasNext()) {
Entry var1 = (Entry)var0.next();
System.out.println(var1.getKey() + ":" + (String)var1.getValue());
}
}
public static void forEachKeySet() {
Iterator var0 = map.keySet().iterator();
while(var0.hasNext()) {
Integer var1 = (Integer)var0.next();
System.out.println(var1 + ":" + (String)map.get(var1));
}
}
public static void lambda() {
map.forEach((var0, var1) -> {
System.out.println(var0 + ":" + var1);
});
}
public static void streamApi() {
map.entrySet().stream().forEach((var0) -> {
System.out.println(var0.getKey() + ":" + (String)var0.getValue());
});
}
public static void parallelStreamApi() {
map.entrySet().parallelStream().forEach((var0) -> {
System.out.println(var0.getKey() + ":" + (String)var0.getValue());
});
}
}
//从结果可以看出,除了 Lambda 和 Streams API 之外,通过迭代器循环和 for 循环的遍历的 EntrySet 最终生成的代码是一样的,他们都是在循环中创建了一个遍历对象 Entry ,代码如下:
public static void entrySet() {
Iterator var0 = map.entrySet().iterator();
while(var0.hasNext()) {
Entry var1 = (Entry)var0.next();
System.out.println(var1.getKey() + ":" + (String)var1.getValue());
}
}
public static void forEachEntrySet() {
Iterator var0 = map.entrySet().iterator();
while(var0.hasNext()) {
Entry var1 = (Entry)var0.next();
System.out.println(var1.getKey() + ":" + (String)var1.getValue());
}
}
//而 KeySet 的代码也是类似的,如下所示:
public static void keySet() {
Iterator var0 = map.keySet().iterator();
while(var0.hasNext()) {
Integer var1 = (Integer)var0.next();
System.out.println(var1 + ":" + (String)map.get(var1));
}
}
public static void forEachKeySet() {
Iterator var0 = map.keySet().iterator();
while(var0.hasNext()) {
Integer var1 = (Integer)var0.next();
System.out.println(var1 + ":" + (String)map.get(var1));
}
}
从结果可以看出,除了 Lambda 和 Streams API 之外,通过迭代器循环和 for 循环的遍历的 EntrySet 最终生成的代码是一样的,他们都是在循环中创建了一个遍历对象 Entry ,代码如下:
public static void entrySet() {
Iterator var0 = map.entrySet().iterator();
while(var0.hasNext()) {
Entry var1 = (Entry)var0.next();
System.out.println(var1.getKey() + ":" + (String)var1.getValue());
}
}
public static void forEachEntrySet() {
Iterator var0 = map.entrySet().iterator();
while(var0.hasNext()) {
Entry var1 = (Entry)var0.next();
System.out.println(var1.getKey() + ":" + (String)var1.getValue());
}
}
而 KeySet 的代码也是类似的,如下所示:
public static void keySet() {
Iterator var0 = map.keySet().iterator();
while(var0.hasNext()) {
Integer var1 = (Integer)var0.next();
System.out.println(var1 + ":" + (String)map.get(var1));
}
}
public static void forEachKeySet() {
Iterator var0 = map.keySet().iterator();
while(var0.hasNext()) {
Integer var1 = (Integer)var0.next();
System.out.println(var1 + ":" + (String)map.get(var1));
}
}
所以我们在使用迭代器或是 for 循环 EntrySet 时,他们的性能都是相同的,因为他们最终生成的字节码基本都是一样的;同理 KeySet 的两种遍历方式也是类似的。
性能分析
EntrySet 之所以比 KeySet 的性能高是因为,KeySet 在循环时使用了 map.get(key),而 map.get(key) 相当于又遍历了一遍 Map 集合去查询 key 所对应的值。为什么要用“又”这个词?那是因为在使用迭代器或者 for 循环时,其实已经遍历了一遍 Map 集合了,因此再使用 map.get(key) 查询时,相当于遍历了两遍。
而 EntrySet 只遍历了一遍 Map 集合,之后通过代码“Entry<Integer, String> entry = iterator.next()”把对象的 key 和 value 值都放入到了 Entry 对象中,因此再获取 key 和 value 值时就无需再遍历 Map 集合,只需要从 Entry 对象中取值就可以了。
所以,EntrySet 的性能比 KeySet 的性能高出了一倍,因为 KeySet 相当于循环了两遍 Map 集合,而 EntrySet 只循环了一遍。
安全性测试
从上面的性能测试结果和原理分析,我想大家应该选用那种遍历方式,已经心中有数的,而接下来我们就从「安全」的角度入手,来分析那种遍历方式更安全。
我们把以上遍历划分为四类进行测试:迭代器方式、For 循环方式、Lambda 方式和 Stream 方式,测试代码如下。
1.迭代器方式
Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> entry = iterator.next();
if (entry.getKey() == 1) {
// 删除
System.out.println("del:" + entry.getKey());
iterator.remove();
} else {
System.out.println("show:" + entry.getKey());
}
}
运行结果:
show:0
del:1
show:2
测试结果:迭代器中循环删除数据安全。
2.For 循环方式
for (Map.Entry<Integer, String> entry : map.entrySet()) {
if (entry.getKey() == 1) {
// 删除
System.out.println("del:" + entry.getKey());
map.remove(entry.getKey());
} else {
System.out.println("show:" + entry.getKey());
}
}
运行结果:
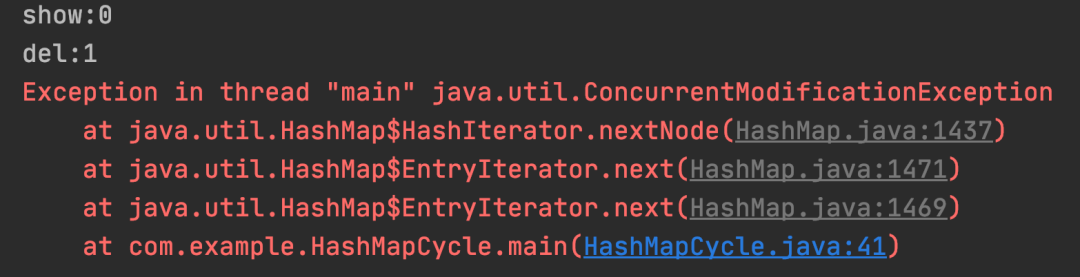
测试结果:For 循环中删除数据非安全。
3.Lambda 方式
map.forEach((key, value) -> {
if (key == 1) {
System.out.println("del:" + key);
map.remove(key);
} else {
System.out.println("show:" + key);
}
});
运行结果:
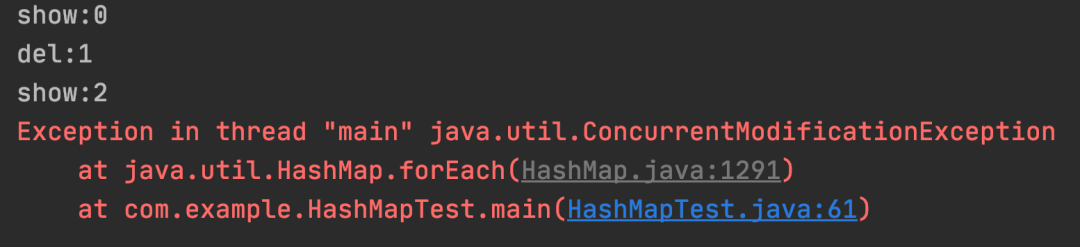
测试结果:Lambda 循环中删除数据非安全。
Lambda 删除的正确方式:
// 根据 map 中的 key 去判断删除
map.keySet().removeIf(key -> key == 1);
map.forEach((key, value) -> {
System.out.println("show:" + key);
});
运行结果:
show:0
show:2
从上面的代码可以看出,可以先使用 Lambda 的 removeIf 删除多余的数据,再进行循环是一种正确操作集合的方式。
4.Stream 方式
map.entrySet().stream().forEach((entry) -> {
if (entry.getKey() == 1) {
System.out.println("del:" + entry.getKey());
map.remove(entry.getKey());
} else {
System.out.println("show:" + entry.getKey());
}
});
运行结果:
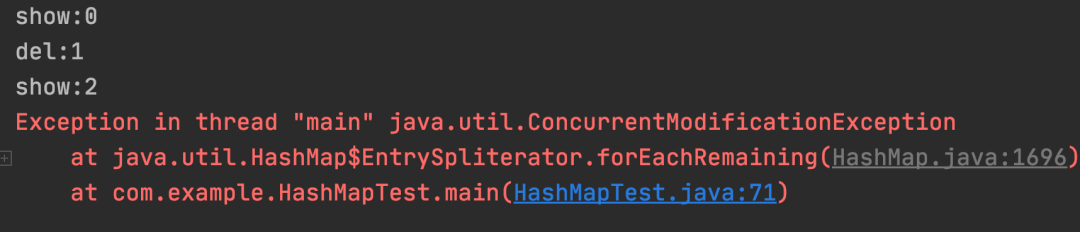
测试结果:Stream 循环中删除数据非安全。
Stream 循环的正确方式:
map.entrySet().stream().filter(m -> 1 != m.getKey()).forEach((entry) -> {
if (entry.getKey() == 1) {
System.out.println("del:" + entry.getKey());
} else {
System.out.println("show:" + entry.getKey());
}
});
运行结果:
show:0
show:2
从上面的代码可以看出,可以使用 Stream 中的 filter 过滤掉无用的数据,再进行遍历也是一种安全的操作集合的方式。
小结
我们不能在遍历中使用集合 map.remove() 来删除数据,这是非安全的操作方式,但我们可以使用迭代器的 iterator.remove() 的方法来删除数据,这是安全的删除集合的方式。同样的我们也可以使用 Lambda 中的 removeIf 来提前删除数据,或者是使用 Stream 中的 filter 过滤掉要删除的数据进行循环,这样都是安全的,当然我们也可以在 for 循环前删除数据在遍历也是线程安全的。
总结
本文我们讲了 HashMap 4 种遍历方式:迭代器、for、lambda、stream,以及具体的 7 种遍历方法,综合性能和安全性来看,我们应该尽量使用迭代器(Iterator)来遍历 EntrySet 的遍历方式来操作 Map 集合,这样就会既安全又高效了。
原文参考公众号【Java知音】
HashMap 中7种遍历方式的性能分析的更多相关文章
- HashMap 的 7 种遍历方式与性能分析
前言 随着 JDK 1.8 Streams API 的发布,使得 HashMap 拥有了更多的遍历的方式,但应该选择那种遍历方式?反而成了一个问题. 本文先从 HashMap 的遍历方法讲起,然后再从 ...
- HashMap的两种遍历方式
HashMap的两种遍历方式 HashMap存储的是键值对:key-value . java将HashMap的键值对作为一个整体对象(java.util.Map.Entry)进行处理,这优化了Hash ...
- JS几种数组遍历方式以及性能分析对比
前言 这一篇与上一篇 JS几种变量交换方式以及性能分析对比 属于同一个系列,本文继续分析JS中几种常用的数组遍历方式以及各自的性能对比 起由 在上一次分析了JS几种常用变量交换方式以及各自性能后,觉得 ...
- Java中的HashMap的2种遍历方式比较
首先我们准备数据,准备一个map Map<String, String> map = new HashMap<String, String>(); for (int i = 0 ...
- SQL Server中几种遍历方式比较
SQL遍历解析 在SQL的存储过程,函数中,经常需要使用遍历(遍历table),其中游标.临时表等遍历方法很常用.面对小数据量,这几种遍历方法均可行,但是面临大数据量时,就需要择优选择,不同的遍历方法 ...
- 谨慎使用keySet:对于HashMap的2种遍历方式比较
HashMap存储的是键值对,所以一般情况下其遍历同List及Set应该有所不同. 但java巧妙的将HashMap的键值对作为一个整体对象(java.util.Map.Entry)进行处理,这优化了 ...
- HashMap的几种遍历方式(转载)
今天讲解的主要是使用多种方式来实现遍历HashMap取出Key和value,首先在java中如果想让一个集合能够用for增强来实现迭代,那么此接口或类必须实现Iterable接口,那么Iterable ...
- OC中四种遍历方式
标准的C语言for循环.Objective-C 1.0出现的NSEnumerator.Objective-C 1.0出现的for in快速遍历.块遍历. 遍历的话,一般是NSArray.NSDicti ...
- HashMap的四种遍历方式
package com.xt.map; import java.util.HashMap; import java.util.Iterator; import java.util.Map; impor ...
随机推荐
- 优雅地使用命令行:Tmux 终端复用
转自:http://harttle.com/2015/11/06/tmux-startup.html 你是否曾经开过一大堆的Terminal?有没有把它们都保存下来的冲动?Tmux 的Session就 ...
- 【转载】基于Linux命令行KVM虚拟机的安装配置与基本使用
基于Linux命令行KVM虚拟机的安装配置与基本使用 https://alex0227.github.io/2018/06/06/%E5%9F%BA%E4%BA%8ELinux%E5%91%BD%E4 ...
- 强哥PHP学习笔记
1.php的代码,必须放在.php的文件中,php代码必须写在<?php ?>之间. 2.//单行注释 /* 多行注释 */ 3.默认首页index.php index.html inde ...
- 基于端口划分vlan
基于端口划分vlan 拓扑图 PC ip 配置 PC 5:192.168.1.5 PC 6:192.168.1.6 PC 7:192.168.1.7 PC 8: 192.168.1.8 交换机配置 创 ...
- Python3.x 基础练习题100例(91-100)
练习91: 题目: 时间函数举例1. 程序: if __name__ == '__main__': import time print (time.ctime(time.time())) print ...
- 如何正确地使用RecyclerView.ListAdapter
默认是在一个fragment中实现RecyclerView. private inner class CrimeAdapter() : ListAdapter<Crime, CrimeHolde ...
- 西门子 S7200 以太网模块连接力控组态方法
产品简介:北京华科远创科技有限研发的远创智控ETH-YC模块,以太网通讯模块型号有MPI-ETH-YC01和PPI-ETH-YC01,适用于西门子S7-200/S7-300/S7-400.SMART ...
- 解决了一个java服务线程退出的问题
问题背景 早上才上班,测试就提了一个问题:"昨天所有批量任务都没有跑".我看了一下任务监控页面,任务是有生成的,但却一直在等待调度状态.初步怀疑是我们的调度服务问题,于是上去查 ...
- GO学习-(15) Go语言基础之包
Go语言基础之包 在工程化的Go语言开发项目中,Go语言的源码复用是建立在包(package)基础之上的.本文介绍了Go语言中如何定义包.如何导出包的内容及如何导入其他包. Go语言的包(packag ...
- K8S集群etcd备份与恢复
参考链接: K8S集群多master:Etcd v3备份与恢复 K8S集群单master:Kubernetes Etcd 数据备份与恢复 ETCD系列之一:简介:https://developer.a ...