将白码平台数据存储到MySQL数据库
概述:
此前在白码平台上搭建并使用系统,若想要将白码平台上搭建的系统的数据存储到自己本地的MySQL数据库中的话,需要将数据导出后再对数据进行处理。如今想要实现这一需求,直接通过使用白码的数据库对接功能,将数据存储到自己本地的数据库中即可。平均一个数据表只需要一分钟的操作时间便能完成对接,效率提升十分显著。
实现效果:
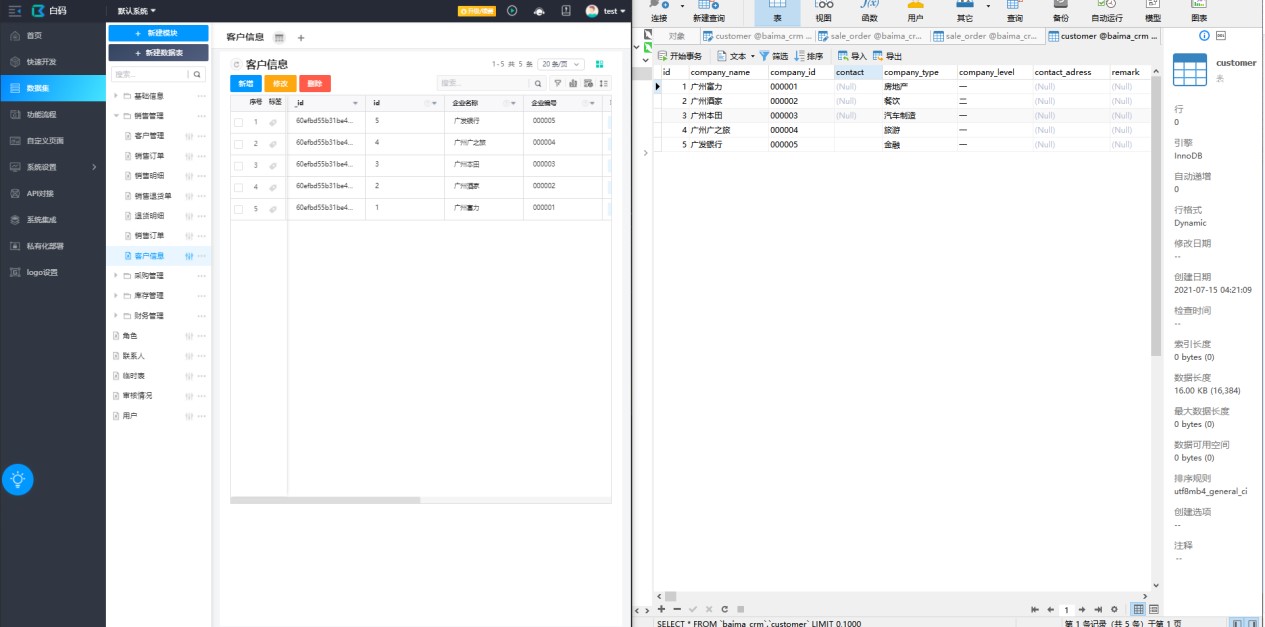
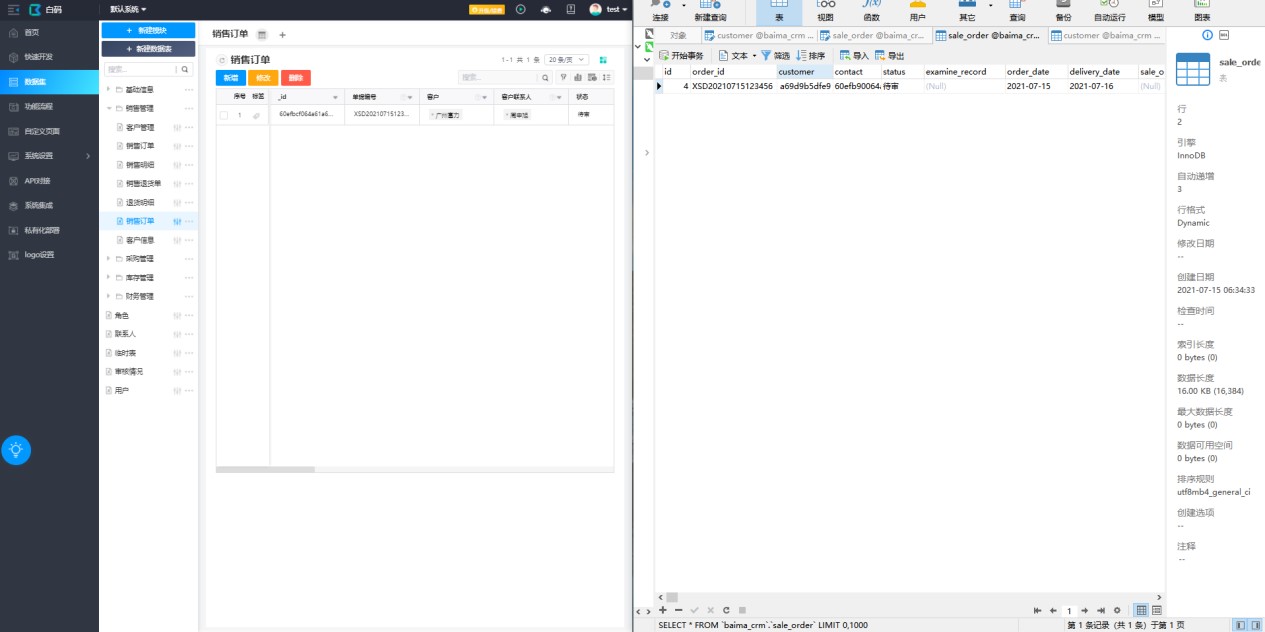
左边为白码数据表中的数据,右边为本地数据库的数据,点击自动生成后,字段以及数据就一并存储到本地的数据库中了,实现数据的同步。下面展示存储后的效果。
客户信息表:
销售订单表:
实现步骤:
本地数据库设置:
以进销存系统中的销售订单模块为例,订单表关联了多个数据表,包括客户信息表,销售明细表等。依次将这几个表在数据库中创建出来,不用再重新设计表结构,添加完主键并填写表名保存就可以了,字段以及数据使用对接功能自动同步。
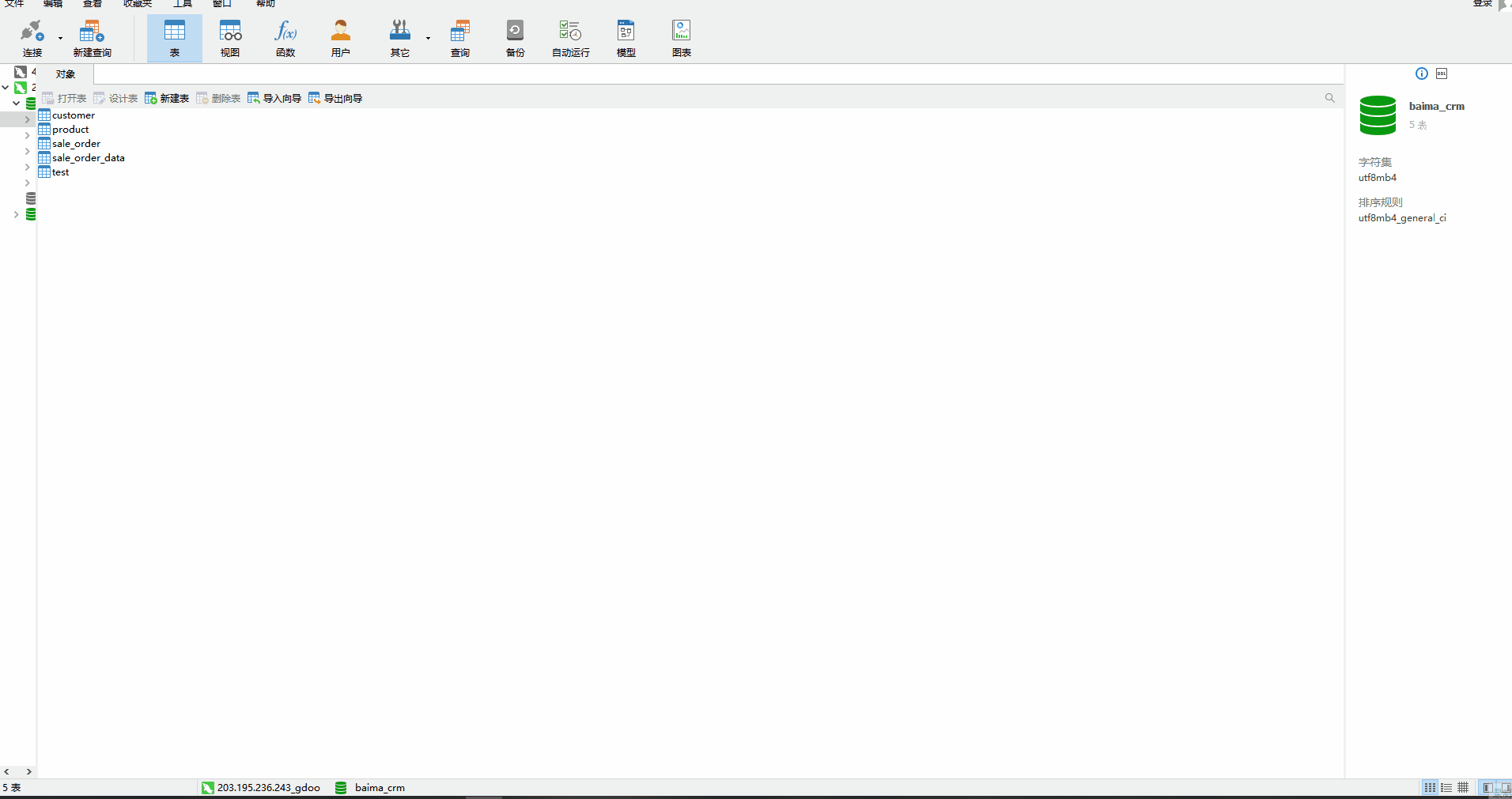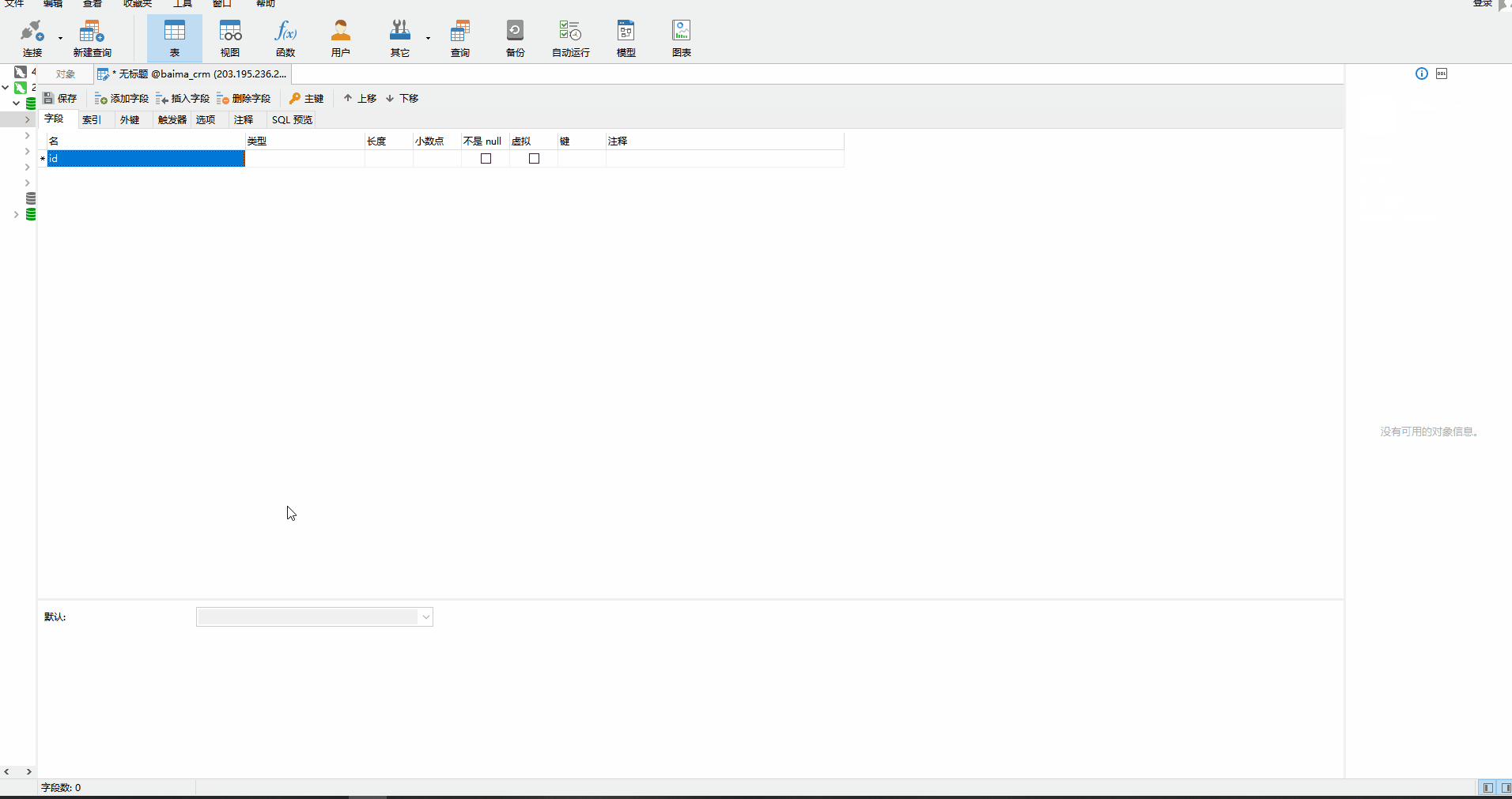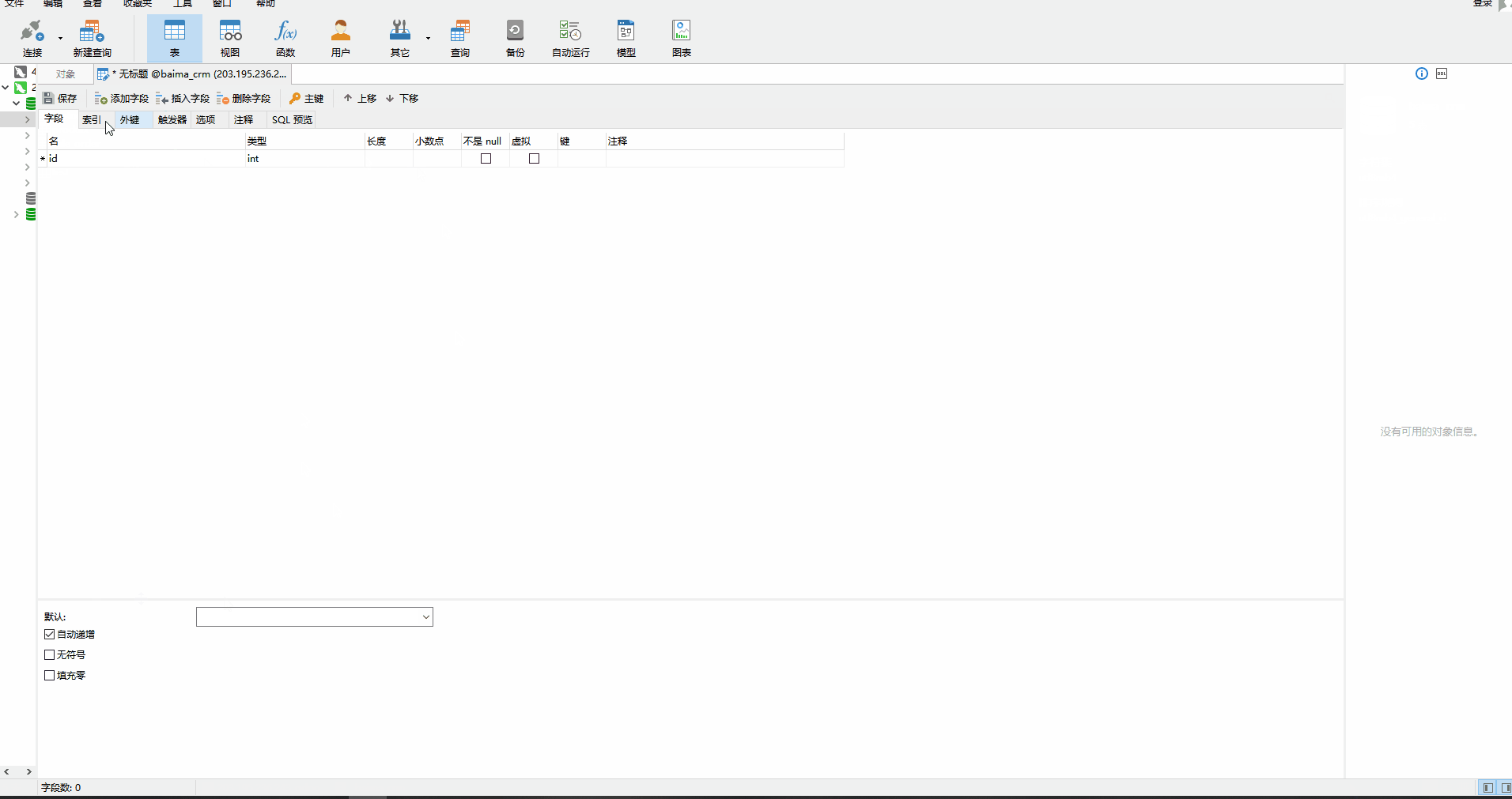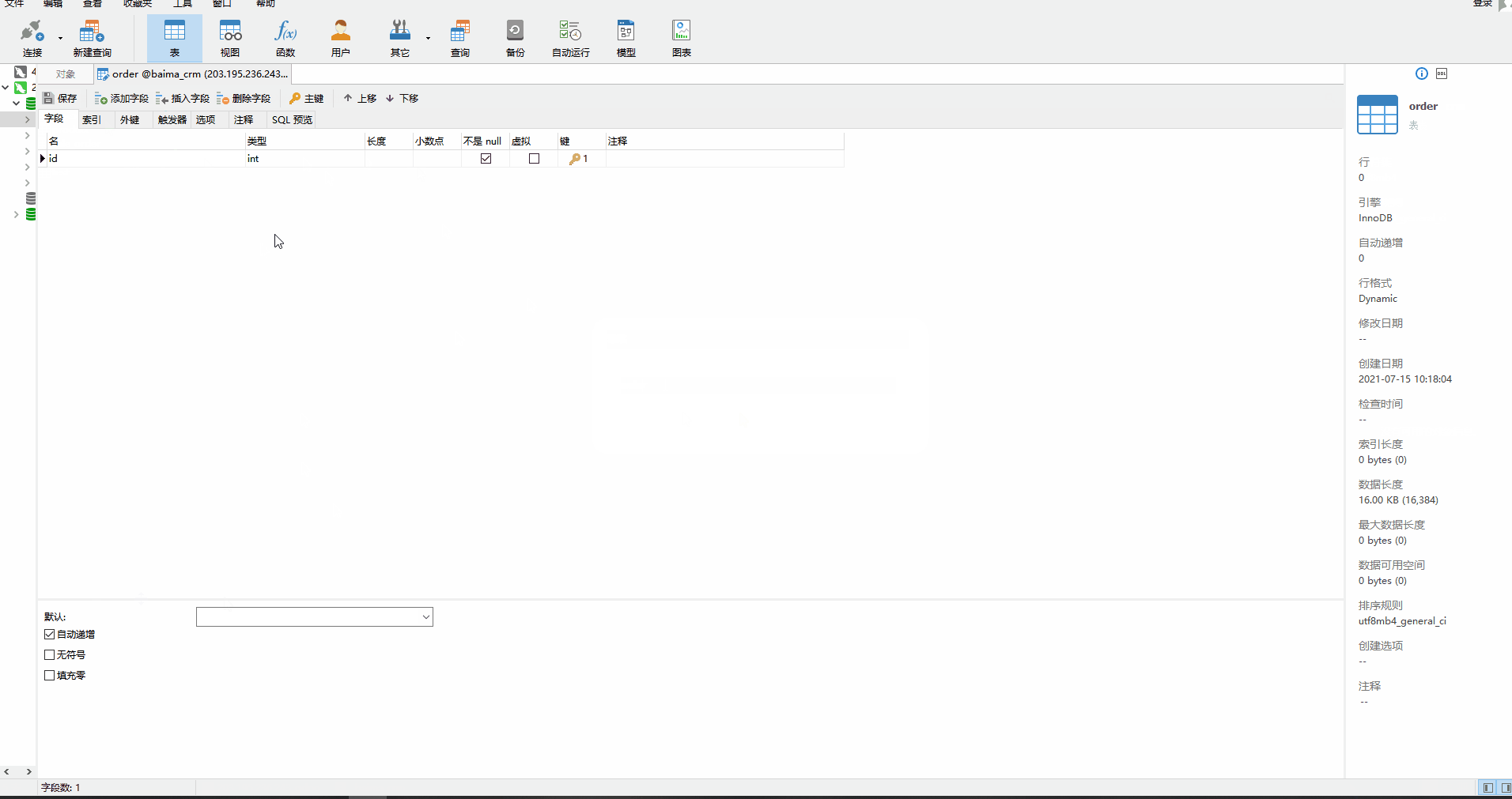
在本地数据库中创建完对应的表后,需要在白码平台上对数据表进行数据库对接配置。
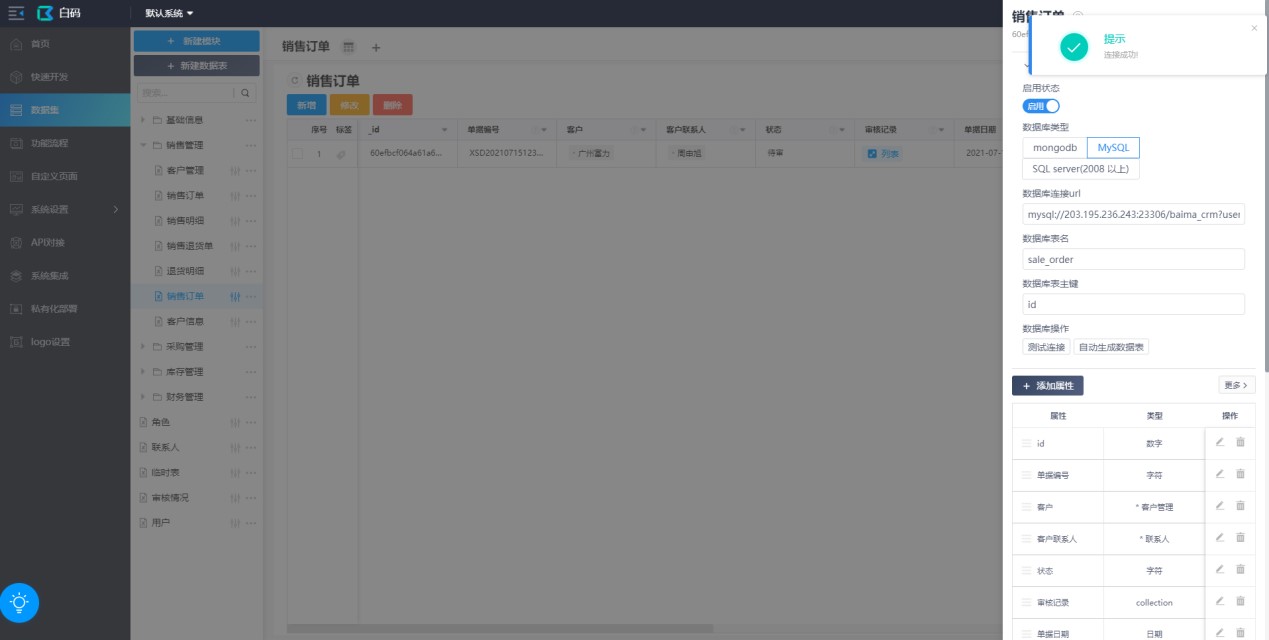
数据库对接配置操作步骤:
- 启用数据库对接功能。
- 选择数据库类型(MySQL)。
- 输入数据库连接URL。
- 输入对应的数据表名。
- 输入刚刚本地创建数据表时设置的主键。
- 点击保存后测试有没有连接成功。
- 点击“自动生成数据表”在本地数据库中自动生成数据表。
数据表字段类型说明:
- 关联类型对应 varchar 50
- 字符类型对应 varchar 255
- 数字类型对应 decimal
- 时间类型对应 varchar 50
- 日期类型对应 varchar 50
客户信息表字段:
白码:

MySQL数据库:
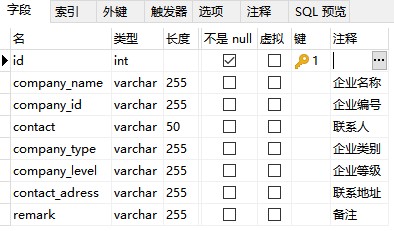
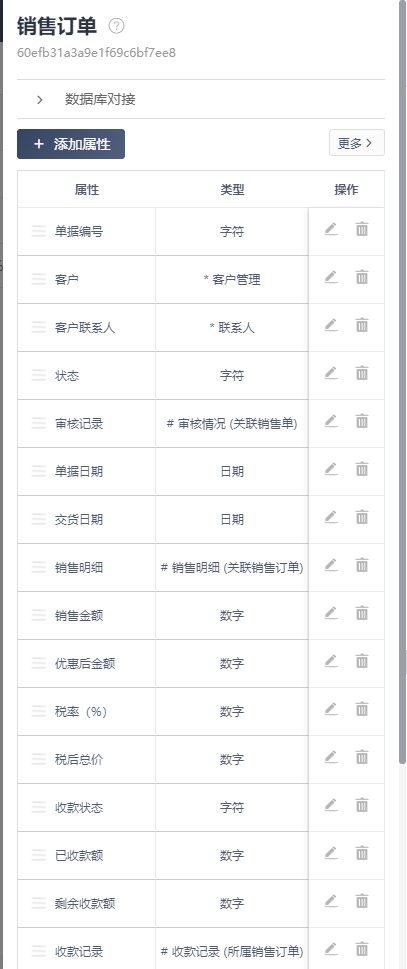
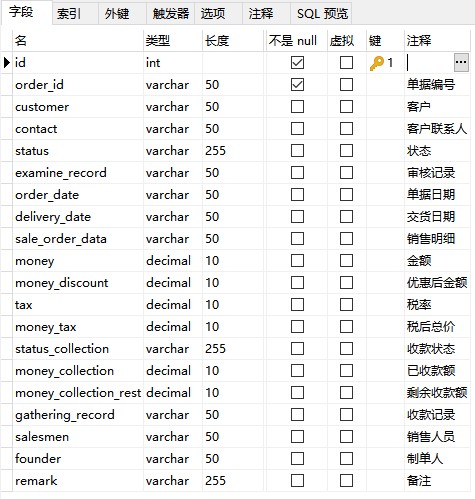
销售订单表字段:
白码:
MySQL数据库:
将白码平台数据存储到MySQL数据库的更多相关文章
- 猫眼电影爬取(一):requests+正则,并将数据存储到mysql数据库
前面讲了如何通过pymysql操作数据库,这次写一个爬虫来提取信息,并将数据存储到mysql数据库 1.爬取目标 爬取猫眼电影TOP100榜单 要提取的信息包括:电影排名.电影名称.上映时间.分数 2 ...
- scrapy数据存储在mysql数据库的两种方式
方法一:同步操作 1.pipelines.py文件(处理数据的python文件) import pymysql class LvyouPipeline(object): def __init__(se ...
- 猫眼电影爬取(二):requests+beautifulsoup,并将数据存储到mysql数据库
上一篇通过requests+正则爬取了猫眼电影榜单,这次通过requests+beautifulsoup再爬取一次(其实这个网站更适合使用beautifulsoup库爬取) 1.先分析网页源码 可以看 ...
- 爬取网贷之家平台数据保存到mysql数据库
# coding utf-8 import requests import json import datetime import pymysql user_agent = 'User-Agent: ...
- 猫眼电影爬取(三):requests+pyquery,并将数据存储到mysql数据库
还是以猫眼电影为例,这次用pyquery库进行爬取 1.简单demo,看看如何使用pyquery提取信息,并将提取到的数据进行组合 # coding: utf-8 # author: hmk impo ...
- Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了.现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中.需求有了,剩下的就是实现了. 在开始之前,保证已经安装好 ...
- python3下scrapy爬虫(第十卷:scrapy数据存储进mysql)
上一卷中我将爬取的数据文件直接写入文本文件中,现在我将数据存储到mysql中,我依然用的是pymysql,这个很麻烦建表需要在外面建 这次代码只需要改变pipyline就行 来 现在看下结果: 对比发 ...
- 如何将MongoDB数据库的数据迁移到MySQL数据库中
FAQ v2.0终于上线了,断断续续忙了有2个多月.这个项目是我实践的第一个全栈的项目,从需求(后期有产品经理介入)到架构,再到设计(有征询设计师的意见).构建(前端.后台.数据库.服务器部署),也是 ...
- Python爬取招聘信息,并且存储到MySQL数据库中
前面一篇文章主要讲述,如何通过Python爬取招聘信息,且爬取的日期为前一天的,同时将爬取的内容保存到数据库中:这篇文章主要讲述如何将python文件压缩成exe可执行文件,供后面的操作. 这系列文章 ...
随机推荐
- 全网唯一开源java开发的支持高扩展,高性能的Mqtt集群broker!
SMQTT是一款开源的MQTT消息代理Broker, SMQTT基于Netty开发,底层采用Reactor3反应堆模型,支持单机部署,支持容器化部署,具备低延迟,高吞吐量,支持百万TCP连接,同时支持 ...
- FirstDay
昨天心血来潮,想着注册一博客,没想到今天再登时,审阅就通过了,多少有点庆辛.从今天起,我也算是有博客的人了! 为什么选博客园开通?好多IT论坛里都允许有博文,CSDN感觉过于高大上,其他系列论坛大多内 ...
- C语言:GB2312编码和GBK编码,将中文存储到计算机
计算机是一种改变世界的发明,很快就从美国传到了全球各地,得到了所有国家的认可,成为了一种不可替代的工具.计算机在广泛流行的过程中遇到的一个棘手问题就是字符编码,计算机是美国人发明的,它使用的是 ASC ...
- Qt5MV自定义模型与实例浅析
1. Model/View结构 这种结构,其实就是将界面组件与所编辑的数据分离开来,又通过数据源的方式连接起来,相当于解耦,视图层只关心显示和与用户交互,而数据层负责与实际的数据进行通信,并为视图组件 ...
- 详解Window10下使用IDEA搭建Hadoop开发环境
前言 经过三次重装,查阅无数资料后成功完成hadoop在win10上实现伪分布式集群,以及IDEA开发环境的搭建.一步一步跟着本文操作可以避免无数天坑. 下载安装Hadoop 下载安装包 进入官网下载 ...
- deepin解压乱码
使用unzip命令解压:unzip -O GBK xxxx.zip -d xxx
- Python+Request库+第三方平台实现验证码识别示例
1.登录时经常的出现验证码,此次结合Python+Request+第三方验证码识别平台(超级鹰识别平台) 2.首先到超级鹰平台下载对应语言的识别码封装,超级鹰平台:http://www.chaojiy ...
- DIV+css排版问题技巧总结---v客学院技术分享
DIV+css排版问题技巧总结 一.排版思路 1.从上到下,从左到右,从大到小. 2.首先确定排版分区,排除色块分布,然后再从简单的部分开始. 3.在某一块内将HTML部分写好 ...
- Python (paramiko) 连接Linux服务器
目录 参考资料 Paramiko 安装 连接Linux 文件上传/下载 文件封装 其他 参考资料 https://www.liujiangblog.com/blog/15/ https://blog. ...
- 微信小程序云开发-数据库-商品列表数据排序
一.wxml添加升序和降序 在商品列表的wxml文件中添加超链接a标签,分别用于升序和降序的点击.分别绑定升序和降序的点击事件. 二.js文件实现升序和降序 分别写对应的按价格升序函数sortByPr ...