Redis的一致性哈希算法
一.节点取余
根据redis的键或者ID,再根据节点数量进行取余。
key:value如下
name:1 zhangsna:18:北京
对name:1 进行hash操作,得出来得值是2423423452,用这个值除3,余1则放到1号节点中进行存储,余2则放到2号节点存储。
二.一致性hash
一致性哈希分区(Distributed Hash Table) 实现思路是为系统中每个节
点分配一个token, 范围一般在0~232, 这些token构成一个哈希环。 数据读写
执行节点查找操作时, 先根据key计算hash值, 然后顺时针找到第一个大于
等于该哈希值的token节点, 如图10-3所示
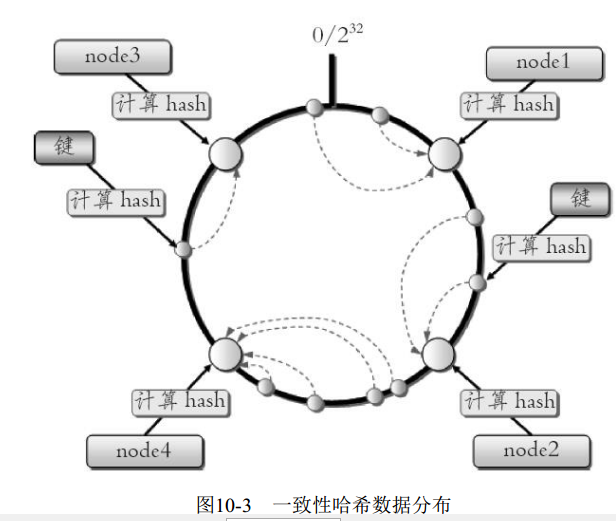
这种方式相比节点取余最大的好处在于加入和删除节点只影响哈希环中
相邻的节点, 对其他节点无影响。 但一致性哈希分区存在几个问题:
·加减节点会造成哈希环中部分数据无法命中, 需要手动处理或者忽略
这部分数据, 因此一致性哈希常用于缓存场景。
当使用少量节点时, 节点变化将大范围影响哈希环中数据映射, 因此
这种方式不适合少量数据节点的分布式方案。
·普通的一致性哈希分区在增减节点时需要增加一倍或减去一半节点才
能保证数据和负载的均衡。
传统的取模方式
例如10条数据 0 1 2 3 4 5 6 7 8 9
3个节点node a b c
如果按照取模的方式,那就是
node a: 0,3,6,9
node b: 1,4,7
node c: 2,5,8
当增加一个节点的时候,数据分布就变更为
node a:0,4,8
node b:1,5,9
node c: 2,6
node d: 3,7
总结:数据3,4,5,6,7,8,9在增加节点的时候,都需要做搬迁,成本太高
而搬迁就是从节点a的机器上把数据移动到节点d上
一致性哈希方式
最关键的区别就是,对节点和数据,都做一次哈希运算,然后比较节点和数据的哈希值,数据取和节点最相近的节点做为存放节点。这样就保证当节点增加或者减少的时候,影响的数据最少。
十条数据,算出各自的哈希值,(这里就不变了,实际上要经过一系列计算)
0 : 0
1 : 1
2 : 2
3 : 3
4 : 4
5 : 5
6 : 6
7 : 7
8 : 8
9 : 9
有三个节点,算出各自的哈希值
node a: 3
node b: 5
node c: 7
这个时候比较两者的哈希值,5等于b,则归属b,4小于b,归属b,3等于a,则归属a,最后所有大于c的,归属于c(这里只是模拟)
相当于整个哈希值就是一个环,对应的映射结果:
node a: 0,1,2,3
node b: 4,5
node c: 6,7,8,9
这个时候加入node d, 就可以算出node d的哈希值:
node d: 9
这个时候对应的数据就会做迁移:
node a: 0,1,2,3
node b: 4,5
node c: 6,7
node d: 8,9
只有最后8,9这2条数据被存储到新的节点,其他不变
三.虚拟槽分区
虚拟槽分区巧妙地使用了哈希空间, 使用分散度良好的哈希函数把所有
数据映射到一个固定范围的整数集合中, 整数定义为槽(slot) 。 这个范围
一般远远大于节点数, 比如Redis Cluster槽范围是0~16383。 槽是集群内数据
管理和迁移的基本单位。 采用大范围槽的主要目的是为了方便数据拆分和集
群扩展。 每个节点会负责一定数量的槽, 如图10-4所示。
当前集群有5个节点, 每个节点平均大约负责3276个槽。 由于采用高质
量的哈希算法, 每个槽所映射的数据通常比较均匀, 将数据平均划分到5个
节点进行数据分区。 Redis Cluster就是采用虚拟槽分区, 下面就介绍Redis数
据分区方法。
redis将每个数据放到一个槽中,而很多槽放到节点中。当槽进行扩容,只需要把某些槽迁移到新节点即可。
Redis的一致性哈希算法的更多相关文章
- _00013 一致性哈希算法 Consistent Hashing 新的讨论,并出现相应的解决
笔者博文:妳那伊抹微笑 博客地址:http://blog.csdn.net/u012185296 个性签名:世界上最遥远的距离不是天涯,也不是海角,而是我站在妳的面前.妳却感觉不到我的存在 技术方向: ...
- (转)每天进步一点点——五分钟理解一致性哈希算法(consistent hashing)
背景:在redis集群中,有关于一致性哈希的使用. 一致性哈希:桶大小0~(2^32)-1 哈希指标:平衡性.单调性.分散性.负载性 为了提高平衡性,引入“虚拟节点” 每天进步一点点——五分钟理解一致 ...
- 一致性哈希算法(consistent hashing)PHP实现
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似.一致性哈希修正了CARP使用的简单哈希 ...
- 一致性哈希算法与Java实现
原文:http://blog.csdn.net/wuhuan_wp/article/details/7010071 一致性哈希算法是分布式系统中常用的算法.比如,一个分布式的存储系统,要将数据存储到具 ...
- 五分钟理解一致性哈希算法(consistent hashing)
转载请说明出处:http://blog.csdn.net/cywosp/article/details/23397179 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法 ...
- 每天进步一点点——五分钟理解一致性哈希算法(consistent hashing)
转载请说明出处:http://blog.csdn.net/cywosp/article/details/23397179 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT) ...
- 一致性哈希算法以及其PHP实现
在做服务器负载均衡时候可供选择的负载均衡的算法有很多,包括: 轮循算法(Round Robin).哈希算法(HASH).最少连接算法(Least Connection).响应速度算法(Respons ...
- Java_一致性哈希算法与Java实现
摘自:http://blog.csdn.net/wuhuan_wp/article/details/7010071 一致性哈希算法是分布式系统中常用的算法.比如,一个分布式的存储系统,要将数据存储到具 ...
- 一致性哈希算法(consistent hashing)【转】
一致性哈希算法 来自:http://blog.csdn.net/cywosp/article/details/23397179 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希 ...
随机推荐
- Linux基础一:基础命令
Linux是什么,是干什么用的? 1.Linux是一个操作系统,电脑=软件+硬件,而操作系统就是特殊的软件 2.Linux系统内一切皆文件 3.bash shell 是红帽默认的shell(shell ...
- Django笔记&教程 3-2 模板语法介绍
Django 自学笔记兼学习教程第3章第2节--模板语法介绍 点击查看教程总目录 参考:https://docs.djangoproject.com/en/2.2/topics/templates/# ...
- 菜鸡的Java笔记第二 - java 数据类型
1.程序的本质实际上就是在于数据的处理上. JAVA中的数据类型有两类 基本数据类型:是进行内容的操作而不是内存的操作 数值型: 整型:byte(-128 ~ 127),short(-32768 ~ ...
- 菜鸡的Java笔记 第二十四 - java 接口的基本定义
1.接口的基本定义以及使用形式 2.与接口有关的设计模式的初步认识 3.接口与抽象类的区别 接口与抽象类相比,接口的使用几率是最高的,所有的 ...
- [atARC075F]Mirrored
假设$n=\sum_{i=0}^{k}a_{i}10^{i}$(其中$a_{k}>0$),则有$d=f(n)-n=\sum_{i=0}^{k}(10^{k-i}-10^{i})a_{i}$,考虑 ...
- [loj3052]春节十二响
首先可以发现对于两条链来说,显然是对两边都排好序,然后大的配大的,小的配小的(正确性比较显然),最后再加入根(根只能单独选)这个结果其实也可以理解为将所有max构成一条新的链,求出因此,对于每一个结点 ...
- [bzoj1037]生日聚会
dp,用f[i][j][x][y]表示i个男孩,j个女孩,以i+j为结尾的子序列男-女最多为x,女-男最多为y的合法方案数,转移到f[i+1][j][x+1][max(y-1,0)]和f[i][j+1 ...
- electron另一种运行方式
编写helloword 全局安装软件 npm install -g electron 快速编写html html:5 完整代码和流程: 1.index.html <!DOCTYPE htm ...
- windows系统开/关机日志位置
邮件计算机=>管理 =>系统工具=>事件查看器=>Windows日志=>系统 过滤:关机:事件ID=6006 开机:事件ID=6005
- C 语言do while 循环
do while 循环小练习 1 #include <stdio.h> 2 #include <stdlib.h> 3 4 int main(void) 5 { 6 int a ...