Kafka详细教程加面试题
一、部署kafka集群
启动zookeeper服务:
zkServer.sh start
修改配置文件config/server.properties
#broker 的全局唯一编号,不能重复
broker.id=0
#删除 topic 功能使能
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘 IO 的现成数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka 运行日志存放的路径
log.dirs=/opt/module/kafka/logs
#topic 在当前 broker 上的分区个数
num.partitions=1
#用来恢复和清理 data 下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment 文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接 Zookeeper 集群地址
zookeeper.connect=localhost:2181
配置环境变量
vi /etc/profile
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile
启动kafka服务:
cd /usr/local/kafka/
nohup bin/kafka-server-start.sh config/server.properties &
创建topic
bin/kafka-topics.sh --create --zookeeper 192.168.1.12:2181,192.168.1.12:2181,192.168.1.14:2181 --replication-factor 1 --partitions 1 --topic mmc
查看topic
bin/kafka-topics.sh --zookeeper localhost:2181 --list
查看topic详情
bin/kafka-topics.sh --describe --topic mmc --zookeeper localhost:2181
产生消息:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
接收消息:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
二、Kafka架构
kafka没有实现JMS协议,但其消费组可以像点对点模型一样让消息被一组进程处理,同时也可以像发布/订阅模式一样,让你发送广播消息到多个消费组。
简单来说:一个消费组就是点对点,多个消费组就能实现发布、订阅。
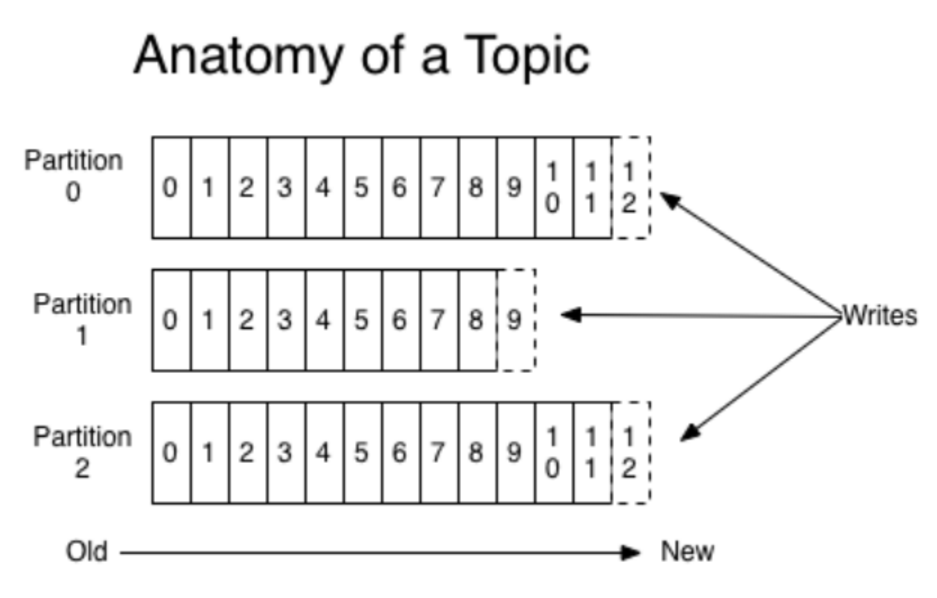
一个Topic可以有多个分区,每个分区是一个有序的,不可变的消息序列。新的消息不断追加,同时分区会给每个消息记录分配一个顺序ID号 – 偏移量。尽管记录被消费了,也不会马上删除,只是移动偏移量,Kafka会有可配置的保留策略删除(默认7天)。
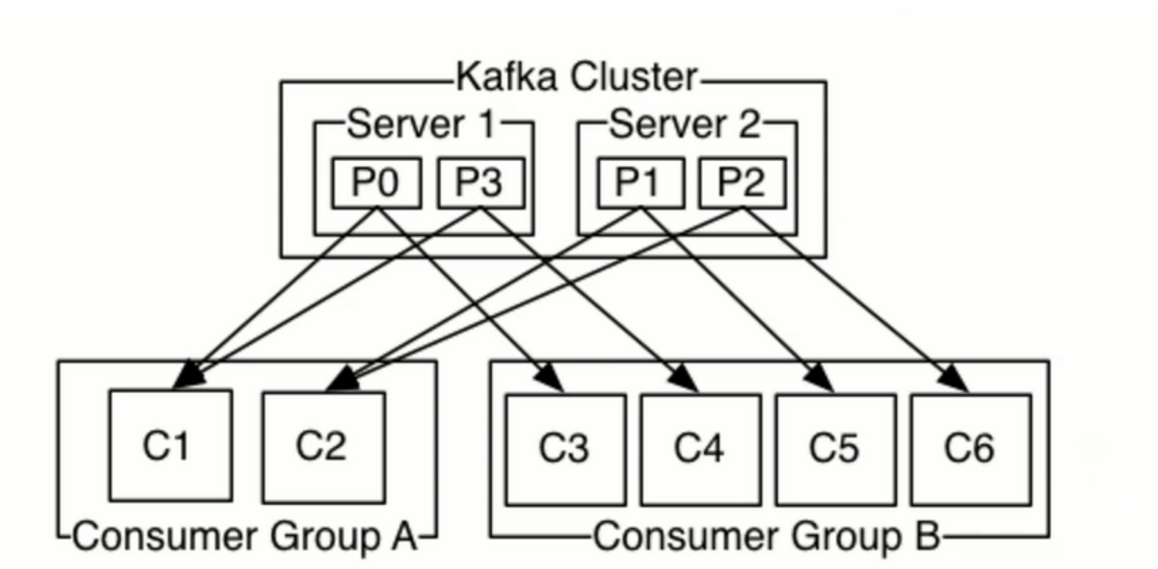
Kafka只保证一个分区内的消息有序,不能保证一个主题的不同分区之间的消息有序。但是,如果你想要保证所有的消息都绝对有序可以只为一个主题分配一个分区,虽然这将意味着每个消费群同时只能有一个消费进程在消费。
分区策略
生产者发送消息后会进入哪个分区?
- 用户可以指定消息的分区
- 也可以指定key,系统根据key的hash值取模得到分区
- 如果用户不指定分区,也不声明key,那么系统会自动生成key,并根据自动生成的key进行hash之后取模然后算出分区
2.2 存储架构
- 将一个topic的多个parition大文件分为多个小文件段(segment)存储。segment文件由两部分组成,分别为“.index”文件和“.log”文件,分别表示索引文件和数据文件
- 通过索引文件可以快速定位到message和确定response的最大大小。
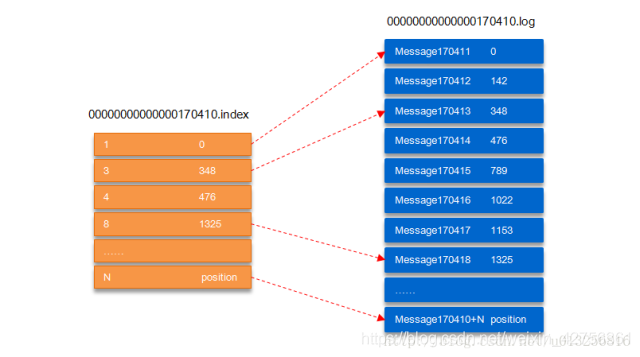
00000000000000170410.log这个文件记录了第170411到~(下一个log文件编号)的消息。图中第三条消息对应的是348,也就是说在log文件中,第三条消息的偏移量是348.
三、保证数据可靠性
3.1 副本同步策略
一般有两种方案,Kafka选择了第二种。
| 方案 | 优点 | 缺点 |
|---|---|---|
| 半数以上完成同步,发送ack | 延迟低 | 选取新的leader时,容忍n个节点故障时,必须要有2n+1个副本 |
| 全数以上完成同步,发送ack | 选取新的leader时,容忍n个节点故障时,需要n+1个副本 | 延迟高 |
3.2 ISR
ISR(In-sync replica set)意为与leader保持同步的follower集合。当ISR中的follower完成与leader的数据同步时,向生产者发送ask。如果在规定的时间内(replica.lag.time.max.ms 此参数设定)follower未同步数据,则踢出ISR。leader出现故障后,就在ISR队列里选举。
3.3 ack应答机制
通过设置request.required.acks应答来保证。有如下三种设置方式
- 1(默认):代表producer在ISR中的leader成功接收到数据并确认时,继续发送下一条数据。如果leader宕机,则丢失数据
- 0:无需确认则直接发送下一条,可靠性最低
- -1:等待producer在ISR中的所有follower确认再发送下一条。此时消息副本数越多则可靠性越高。
3.4 故障处理细节
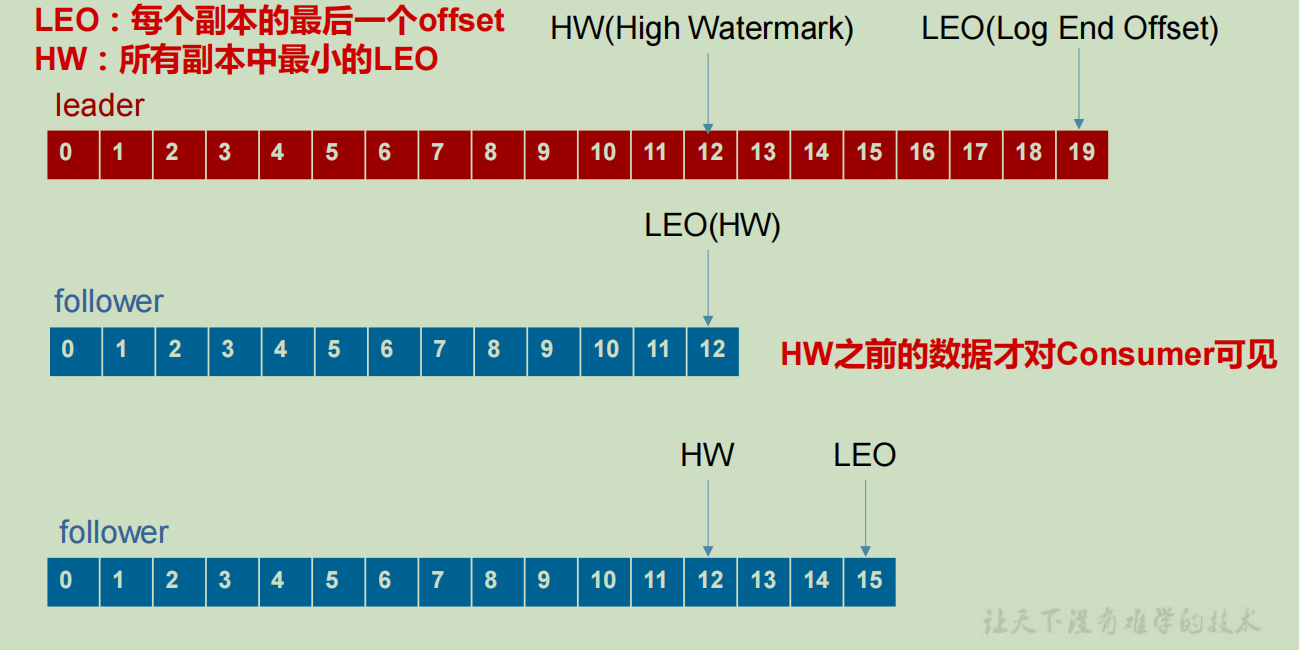
LEO:每个副本最大的offset
HW:消费者能见到的最大的offet,ISR中最小的LEO
(1)follower故障时
follower发生故障后会被临时踢出ISR,待该follower重启后,follower会读取本地磁盘记录的上次的HW,然后将他log文件中高于HW的部分截掉,然后从leader开始同步,直到该follower的LEO大于或等于该Partition的HW,就可以重新加入ISR。
(2)leader故障时
leader发生故障后,会重新选取一个leader,为了保证多个副本的数据一致性,其余的follower会将高于HW的部分截掉,然后从新leader那里同步
Exactly Once 语义
当ack设置为-1时,可以保证producer到Server之间不丢数据,即至少一次
而ack设置为0,则以保证消息至多一次。
而对于某些非常重要的消息,要保证既不丢失又不重复,即Exactly Once语义。在 0.11 版本以前的 Kafka是做不到的。0.11 版本的 Kafka,引入了一项重大特性:幂等性。所谓的幂等性就是指Producer不论向 Server发送多少次重复数据,Server 端都只会持久化一条。幂等性结合 At Least Once 语
义,就构成了 Kafka 的 Exactly Once 语义。即:
At Least Once + 幂等性 = Exactly Once
要启用幂等性,将enable.idompotence 设置为 true 即可
实现方式;开启幂等性的Producer在初始化的时候会分配一个PID,发往同一个Partition的消息会附带Sequence Number。而Broker端会对<PID,Partition,SeqNumber>做缓存,当相同主键的消息提交时,只会持久化一条。但是PID重启就会发生变化,不同的Partition也具有不同的主键,所以他的幂等性无法保证跨分区跨会话。
四、消费者
4.1 消费方式
消息是采用的pull的方式,pull方式的不足之处是如果没有数据,会造成空轮询,针对这一点,Kafka的消费者在消费数据时会传入一个时长参数 timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回,这段时长即为 timeout。
4.2 分区分配策略
Kafka消息消费的时候,有两种策略,RoundRobin和Range
4.3 消费者Offset位置保存
Offset是以消费者组+Topic+Partatition为key来保存的。
0.9版本前保存在Zookeeper里
0.9版本之后保存在Kafka内置的一个Topic中,该topic为__consumer_offsets
5.1 Kafka高效读写数据
- 顺序写磁盘
顺序写可达到600M/s,而随机写只有100K/s
2. 零拷贝技术
5.2 Kafka事务
Kafka在0.11版本后引入了事务支持。事务可以保证消息正好一次语义的基础上,生产和消费可以跨分区和会话。
为了实现跨分区跨会话的事务,需要引入一个全局唯一的 Transaction ID,并将 Producer获得的PID和Transaction ID 绑定。这样当Producer 重启后就可以通过正在进行的Transaction ID 获得原来的 PID。
六、Kafka API
6.1 Producer API
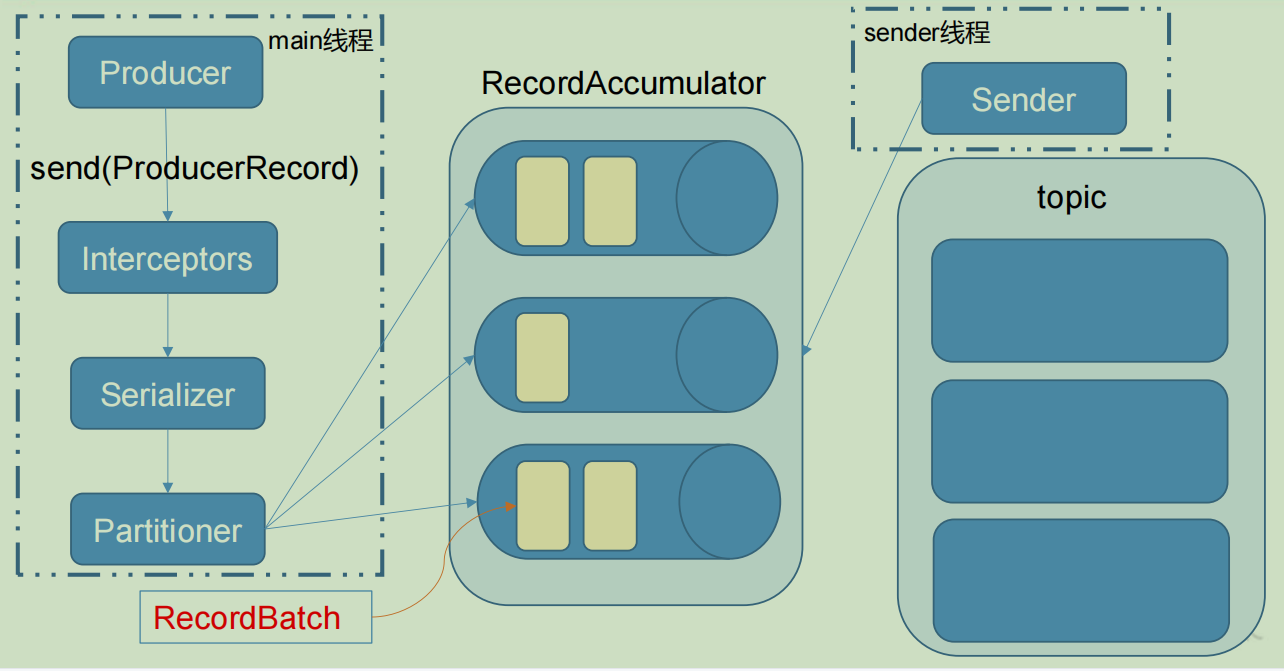
消息发送过程
代码示例
package com.mmc.springbootstudy.kafka;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
/**
* @description:
* @author: mmc
* @create: 2021-04-22 21:22
**/
public class ProductDemo {
public final static String TOPIC = "mmc";
/**
* 不带回调的发送API
*/
public void send() {
Properties props = new Properties();
props.put("bootstrap.servers", "49.234.77.60:9092");
props.put("acks", "all");
props.put("retries", 3);
props.put("batch.size", 16384);
props.put("key.serializer", StringSerializer.class.getName());
props.put("value.serializer", StringSerializer.class.getName());
String key="test";
String value="我是一个小红花222";
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
producer.send(new ProducerRecord<String, String>(TOPIC,key,value));
producer.close();
}
/**
* 带回调的发送
*/
public void callSend() {
Properties props = new Properties();
props.put("bootstrap.servers", "49.234.77.60:9092");
props.put("acks", "all");
props.put("retries", 3);
props.put("batch.size", 16384);
props.put("key.serializer", StringSerializer.class.getName());
props.put("value.serializer", StringSerializer.class.getName());
String key="test";
String value="我是一个小红花222";
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
producer.send(new ProducerRecord<String, String>(TOPIC, key, value), new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if(e == null){
System.out.println("发送成功");
}else {
e.printStackTrace();
}
}
});
producer.close();
}
/**
* 同步发送API
* 一条消息发送之后,会阻塞当前线程,直至返回 ack。
*/
public void syncSend() throws ExecutionException, InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", "49.234.77.60:9092");
props.put("acks", "all");
props.put("retries", 3);
props.put("batch.size", 16384);
props.put("key.serializer", StringSerializer.class.getName());
props.put("value.serializer", StringSerializer.class.getName());
String key="test";
String value="我是一个小红花222";
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
RecordMetadata recordMetadata = producer.send(new ProducerRecord<String, String>(TOPIC, key, value)).get();
System.out.println("----------recordMetadata:"+recordMetadata);
producer.close();
}
public static void main( String[] args ) throws ExecutionException, InterruptedException {
// new ProductDemo().send();
new ProductDemo().syncSend();
}
}
KafkaProducer 对象是比较重的,并且他是线程安全的,所以可以全局都用同一个对象去发消息。
6.2 Consumer API
消费者消费的时候有区分自动提交、手动同步提交和手动异步提交。手动同步提交会阻塞当前线程直到成功提交,并有失败重试。而异步手动提交没有失败重试。
不管是同步提交还是异步提交,都会可能造成数据漏消费和重复消费。如果先提交offset后消费,有可能导致数据漏消费,如果先消费后提交offset就有可能导致数据重复消费。
package com.mmc.springbootstudy.kafka;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.util.Arrays;
import java.util.Map;
import java.util.Properties;
/**
* @description:
* @author: mmc
* @create: 2021-04-22 21:32
**/
public class ConsumerDemo {
public final static String TOPIC = "mmc";
/**
* 自动提交offset
* @throws InterruptedException
*/
void receive() throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", "49.234.77.60:9092");
props.put("group.id", "group_id");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("max.poll.records", 1000);
props.put("auto.offset.reset", "earliest");
props.put("key.deserializer", StringDeserializer.class.getName());
props.put("value.deserializer", StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(TOPIC));
while (true){
ConsumerRecords<String, String> msgList=consumer.poll(1000);
for (ConsumerRecord<String,String> record:msgList){
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
/**
* 手动同步提交
* @throws InterruptedException
*/
void commitSyncReceive() throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", "49.234.77.60:9092");
props.put("group.id", "group_id");
props.put("enable.auto.commit", "false");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("max.poll.records", 1000);
props.put("auto.offset.reset", "earliest");
props.put("key.deserializer", StringDeserializer.class.getName());
props.put("value.deserializer", StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(TOPIC));
while (true){
ConsumerRecords<String, String> msgList=consumer.poll(1000);
for (ConsumerRecord<String,String> record:msgList){
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
//同步提交,当前线程会阻塞直到 offset 提交成功
consumer.commitSync();
}
}
/**
* 手动异步提交
* @throws InterruptedException
*/
void commitAsyncReceive() throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", "49.234.77.60:9092");
props.put("group.id", "group_id");
props.put("enable.auto.commit", "false");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("max.poll.records", 1000);
props.put("auto.offset.reset", "earliest");
props.put("key.deserializer", StringDeserializer.class.getName());
props.put("value.deserializer", StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(TOPIC));
while (true){
ConsumerRecords<String, String> msgList=consumer.poll(1000);
for (ConsumerRecord<String,String> record:msgList){
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {
if(e!=null){
System.err.println("commit failed for "+map);
}
}
});
}
}
public static void main(String[] args) throws InterruptedException {
// new ConsumerDemo().receive();
new ConsumerDemo().commitSyncReceive();
}
}
6.3 自定义分区
实现Partitioner接口,并在配置中加入
props.put("partitioner.class", "com.mmc.springbootstudy.kafka.MyPartition");
自定义分区实现类:
package com.mmc.springbootstudy.kafka;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
/**
* @description:
* @author: mmc
* @create: 2021-04-27 20:41
**/
public class MyPartition implements Partitioner {
@Override
public int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) {
return 0;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
自定义存储offset
consumer.subscribe(Arrays.asList(TOPIC), new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> collection) {
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> collection) {
}
});
6.4 自定义拦截器
package com.mmc.springbootstudy.kafka;
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Map;
/**
* @description:
* @author: mmc
* @create: 2021-04-30 20:47
**/
public class CountIntercepter implements ProducerInterceptor<String,String> {
private int successCount=0;
private int failCount=0;
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> producerRecord) {
System.out.println("拦截到消息的分区:"+producerRecord.topic());
return producerRecord;
}
@Override
public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {
if(e==null){
successCount++;
}else {
failCount++;
}
}
@Override
public void close() {
System.out.println("success count:"+successCount);
}
@Override
public void configure(Map<String, ?> map) {
}
}
在生产者中需要加入
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,"com.mmc.springbootstudy.kafka.CountIntercepter");
七、第三方扩展
7.1 Kafka Eagle 监控
八、面试题
- Kafka 中的ISR(InSyncRepli)、OSR(OutSyncRepli)、AR(AllRepli)代表什么?
答: kafka中与leader副本保持一定同步程度的副本(包括leader)组成ISR。与leader滞后太多的副本组成OSR。分区中所有的副本通称为AR。
- Kafka 中的HW、LEO等分别代表什么?
答:HW:高水位,指消费者只能拉取到这个offset之前的数据
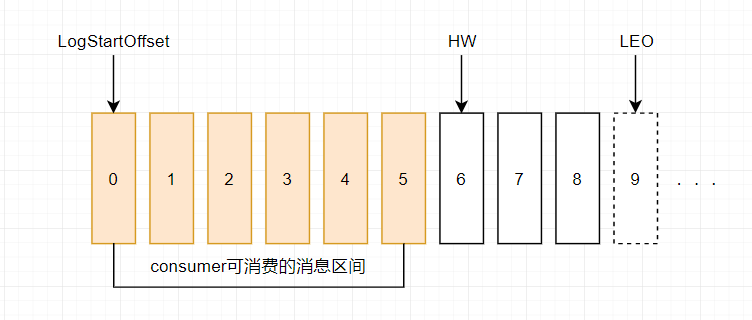
LEO:标识当前日志文件中下一条待写入的消息的offset,大小等于当前日志文件最后一条消息的offset+1.
- Kafka 中是怎么体现消息顺序性的?
生产者:向leader副本负责消息的顺序写入
消费者:同一个分区只能被同一个消费者组中的一个消费者消费。
kafka只保证同一个分区的顺序性,所以如果是想保证全局顺序,可以自定义分区策略,将关联的消息发到同一个分区。如同一个订单的各个状态。
4. Kafka生产者客户端的结构
答:整个生产者客户端主要有两个线程,主线程以及Sender线程。Producer在主线程中产生消息,然后通过拦截器,序列化器,分区器之后缓存到消息累加器RecordAccumulator中。Sender线程从RecordAccumulator中获取消息并发送到kafka中。RecordAccumulator主要用来缓存消息,这样发送的时候进行批量发送以便减少相应的网络传输。RecordAccumulator缓存的大小可以通过配置参数buffer.memory配置,默认是32M。如果创建消息的速度过快,超过sender发送给kafka服务器的速度,会导致缓存空间不足,这个时候sender线程可能会阻塞或者抛出异常,max.block.ms配置决定阻塞的最大时间。
RecordAccumulator中为每个分区维护了一个双端队列,队列中的内容是ProducerBatch,即Deque,创建消息写入到尾部,发送消息从头部读取。ProducerBatch是消息发送的一个批次,里面包含了一个或多个ProducerRecord。
- 分区策略有哪些?
答:有两种,一种是 RangeAssignor 分配策略(范围分区),另一种是RoundRobinAssignor分配策略(轮询分区)。默认采用 Range 范围分区。
Range策略:
如有10个分区,3个消费者,那么通过10/3=3算出一个消费者消费3个分区。多出的分区由排在前面的消费者消费。那么消费者1消费0,1,2,3分区。消费者2消费4,5,6分区。消费者3消费7,8,9分区。
缺点就是前面的消费者就会多消费到一个分区,如果是多个topic,那么这个消费者就会多消费到多个分区。
RandRobin策略:同样的例子,分区0被消费者1消费,分区1被消费者2消费,分区2被消费者3消费
注意:这种策略需要一个组内的消费者订阅的主题相同。这样轮询的时候才是均匀的。
当出现以下几种情况时,Kafka 会进行一次分区分配操作,即 Kafka 消费者端的 Rebalance 操作
- 同一个 consumer 消费者组 group.id 中,新增了消费者进来,会执行 Rebalance 操作
- 消费者离开当期所属的 consumer group组。比如宕机
- 分区数量发生变化时(即 topic 的分区数量发生变化时)
- 消费者主动取消订阅
- kafka中哪些地方会选举?
答:BrokerController:
在broker启动的时候,都会创建BrokerController,第一个在zookeeper中创建指定临时节点成功的那个节点就是BrokerController。他负责管理集群 broker的上下线,所有topic的分区副本分配和 leader 选举等工作。
Partition Leader:
- 从Zookeeper中读取当前分区的所有ISR(in-sync replicas)集合
- 调用配置的分区选择算法选择分区的leader
- 分区数能新增或减少吗?
答:能新增,不能减少。因为减少的话,分区内已有的数据不好处理。
Kafka详细教程加面试题的更多相关文章
- kafka实战教程(python操作kafka),kafka配置文件详解
kafka实战教程(python操作kafka),kafka配置文件详解 应用往Kafka写数据的原因有很多:用户行为分析.日志存储.异步通信等.多样化的使用场景带来了多样化的需求:消息是否能丢失?是 ...
- Windows7 64位系统搭建Cocos2d-x-2.2.1最新版以及Android交叉编译环境(详细教程)
Windows7 64位系统搭建Cocos2d-x-2.2.1最新版以及Android交叉编译环境(详细教程) 声明:本教程在参考了以下博文,并经过自己的摸索后实际操作得出,本教程系本人原创,由于升级 ...
- git详细教程
Table of Contents 1 Git详细教程 1.1 Git简介 1.1.1 Git是何方神圣? 1.1.2 重要的术语 1.1.3 索引 1.2 Git安装 1.3 Git配置 1.3.1 ...
- GitHub详细教程(转载)
1 Git详细教程 1.1 Git简介 1.1.1 Git是何方神圣? 1.1.2 重要的术语 1.1.3 索引 1.2 Git安装 1.3 Git配置 1.3.1 用户信息 1.3.2 高亮显示 1 ...
- GitHub详细教程
GitHub详细教程 Table of Contents 1 Git详细教程 1.1 Git简介 1.1.1 Git是何方神圣? 1.1.2 重要的术语 1.1.3 索引 1.2 Git安装 1.3 ...
- 安装64位Oracle 10g超详细教程
安装64位Oracle 10g超详细教程 1. 安装准备阶段 1.1 安装Oracle环境 经过上一篇博文的过程,已经完成了对Linux系统的安装,本例使用X-Manager来实现与Linux系统的连 ...
- Solr集群搭建详细教程(二)
注:欢迎大家转载,非商业用途请在醒目位置注明本文链接和作者名dijia478,商业用途请联系本人dijia478@163.com. 之前步骤:Solr集群搭建详细教程(一) 三.solr集群搭建 注意 ...
- ROS连接ABB机械臂调试详细教程-ROS(indigo)和ABB RobotStudio 6.03.02-
在ROS industrial介绍中,给出了ROS和常用机械臂的连接方式.具体信息可以参考:http://wiki.ros.org/Industrial ROS连接ABB机械臂调试详细教程-ROS(i ...
- NumPy 超详细教程(2):数据类型
系列文章地址 NumPy 最详细教程(1):NumPy 数组 NumPy 超详细教程(2):数据类型 NumPy 超详细教程(3):ndarray 的内部机理及高级迭代 文章目录 NumPy 数据类型 ...
随机推荐
- 构建后端第6篇之---java 多态的本质 父类引用 指向子类实现
张艳涛写于2021-2-20 今天来个破例了,不用英文写了,今天在家里电脑写的工具不行,简单的说 主题是:java多态的原理与实现 结论是:java的多态 Father father= new Son ...
- Go通关03:控制结构,if、for、switch逻辑语句
if 条件语句 func main() { i:=6 if i >10 { fmt.Println("i>10") } else if i>5 && ...
- 从net到java:java快速入门
学习java那是不可能的,到为什么不学习一下呢.仅为总结.希望自己在不久的将来能书写优美的java程序.加油!奥利给 1.注释 注释的重要性不言而喻,我们不管写什么代码注释必不可少,那么java的注释 ...
- Bugku-login1(SKCTF)(SQL约束攻击)
原因 sql语句中insert和select对长度和空格的处理方式差异造成漏洞. select对参数后面的空格的处理方式是删除,insert只是取规定的最大长度的字符串. 逻辑 1.用 select ...
- 十六进制转十进制 BASIC-12
十六进制转十进制 代码 import java.math.BigInteger; import java.util.Scanner; /* * 从键盘输入一个不超过8位的正的十六进制数字符串, * 将 ...
- docker-01
Docker介绍 1 什么是容器? Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源 Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级.可移 ...
- springboot:使用异步注解@Async的那些坑
springboot:使用异步注解@Async的那些坑 一.引言 在java后端开发中经常会碰到处理多个任务的情况,比如一个方法中要调用多个请求,然后把多个请求的结果合并后统一返回,一般情况下调用其他 ...
- Python - typing 模块 —— 类型别名
前言 typing 是在 python 3.5 才有的模块 前置学习 Python 类型提示:https://www.cnblogs.com/poloyy/p/15145380.html 常用类型提示 ...
- linux中文件内核数据结构
3.文件io 3.1 文件内核数据结构 3.2 复制文件描述符的内核数据结构 3.3 对指定的描述符打印文件标志 #include "apue.h" #include <fc ...
- 理解SpingAOP
目录 什么是AOP? AOP术语 通知(Advice) 连接点(Join point) 切点(Pointcut) 连接点和切点的区别 切面(Aspect) 引入(Introduction) 织入(We ...