Heritrix工具实现网络爬虫
上次用的java相关知识实现了一个简单的网络爬虫,现在存在许多开源免费的爬虫工具,相对来说,可以很简单的获取网页数据,并写入到本地。
下面我就阐述一下我用Heritrix爬虫工具实现网页数据爬取。
------>
目录
1、Heritrix文件配置
2、Heritrix服务器job配置
3、如何创建job并执行
4、有选择的爬取网页
5、总结
----->
1‘ 基础文件配置
网上下载heritrix的压缩包,即可配置一个爬虫服务器,其核心使用的是Tomcat。
解压压缩包,将conf目录下的 文件拷贝到根目录下。
文件拷贝到根目录下。
修改根目录下此文件,将.template去掉。
然后用记事本(我用的UItraEdit工具 ,方便看配置文件和代码)将文件打开,将@PASSWORD@的内容,更改为你的用户名和密码(自定义)。
,方便看配置文件和代码)将文件打开,将@PASSWORD@的内容,更改为你的用户名和密码(自定义)。

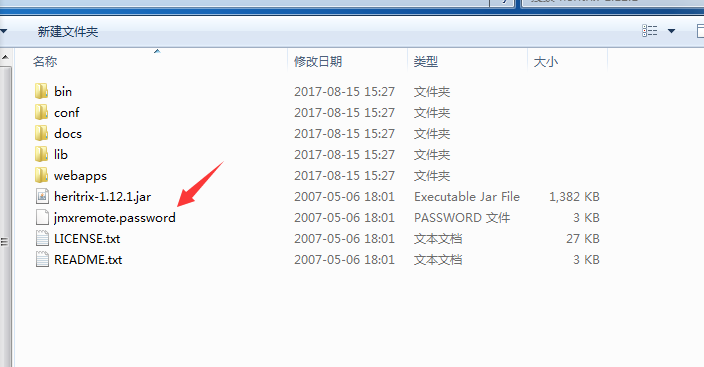
将imxremote.password的文件变为只读(属性)。
注意:【!!!如果是win7系统,需要将此文件的所有者改为当前用户,如图。
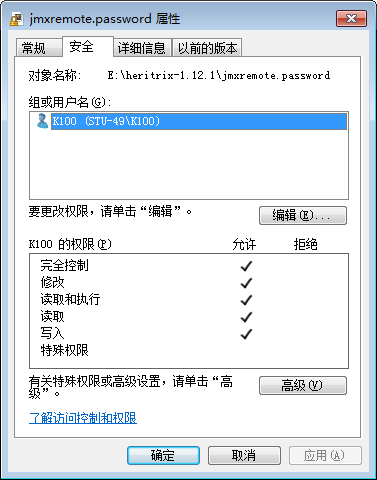
点击“高级”,
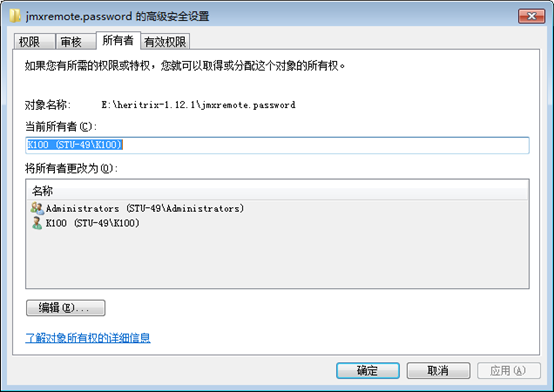
点击“编辑”
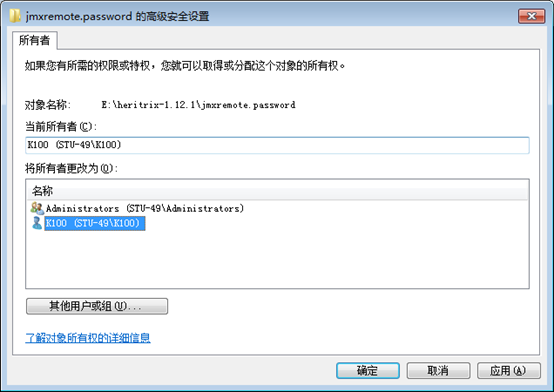
此处选择当前的用户,再点击”应用“,即可。
!!!】
2’ 服务器Job配置
执行bin目录下的heritrix.cmd命令,用来启动这个服务器(必须在命令行下执行)。
示例:首先进入该文件的bin目录下,启动命令为:
heritrix.cmd --admin=user:password
启动如果成功,显示窗口:

启动成功之后,通过浏览器访问当前服务器的8080端口来准备进行数据采集。
即输入 localhost:8080/

进入之后首先输入你刚开始配置时设定的用户名和密码。
然后进入首页:
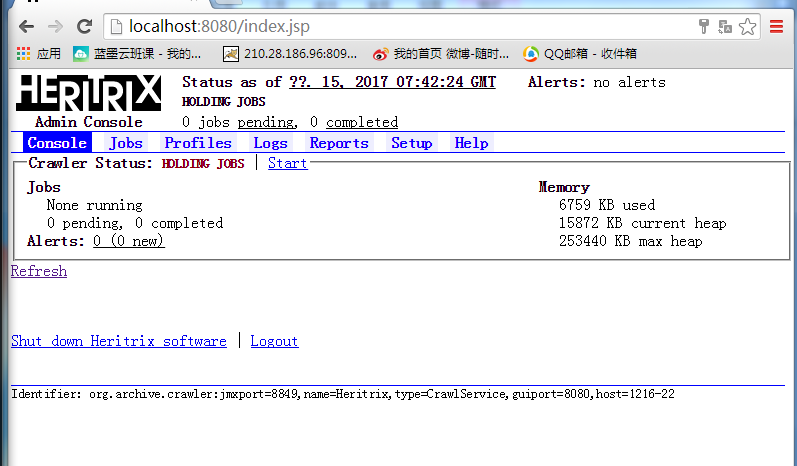
此窗口可以看到一些选项,有三个选项是比较重要的:
1) Console:控制台,在这里可以监控当前的任务爬取状态
2) Jobs:可以在这里建立新的爬取任务
3) Profiles:配置爬取的属性,例如:爬取的总线程数
首先需要在profiles中自己建立一个自定义的爬取的属性配置。在Profiles选项内选择New Profile based on it

进入界面:

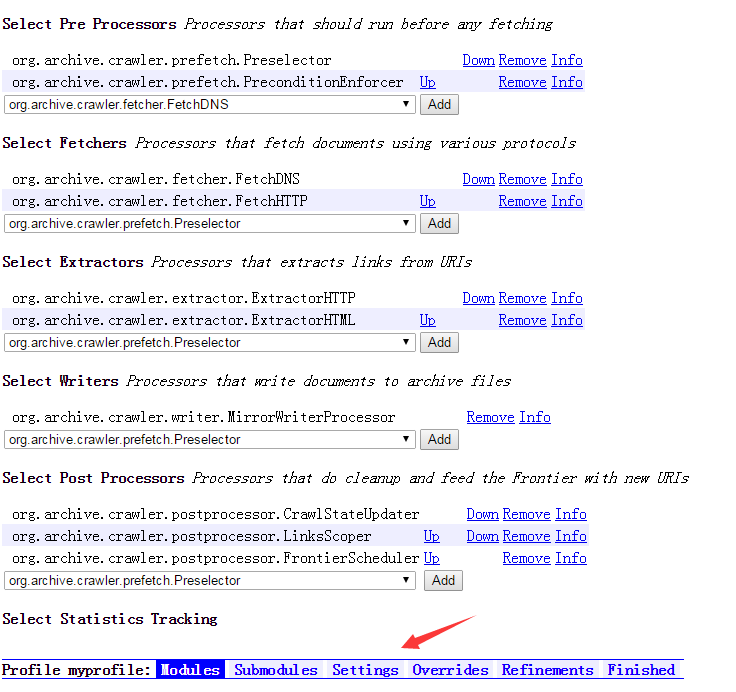
点击Modules,
这里需要设置爬取时的参数类。
例如:爬取的范围,下载后的保存类型,爬取时所要下载的文件类型等。
首先要注意一点,两个change必须要点一下,我当时就是忽略了这个导致job无法提交!!!

之后,你需要在此界面下面设置10个类,按我的图来(规则我就不解释了):
之后,选择Settings进行一些其他属性的配置,此处要更改一个线程数,(这个看你的电脑配置咯),之后再http-headers里面需要填写你的工具版本,ip地址以及个人邮箱(这个主要是告诉网站管理者哪个帅锅在爬我的网页,当然,劝告一下,国外和国内一些大型的网站不要爬取,很容易被监测到也可能触犯到信息窃取):

之后,点击Finished会提示Profile modified,表示修改成功。
3’ 建立爬取任务并执行
在Jobs选项里,选择Based on a profile选项,然后选择刚刚配置的那个myprofile,在此处选择你需要爬取的网站,我选择的是新浪新闻的首页:
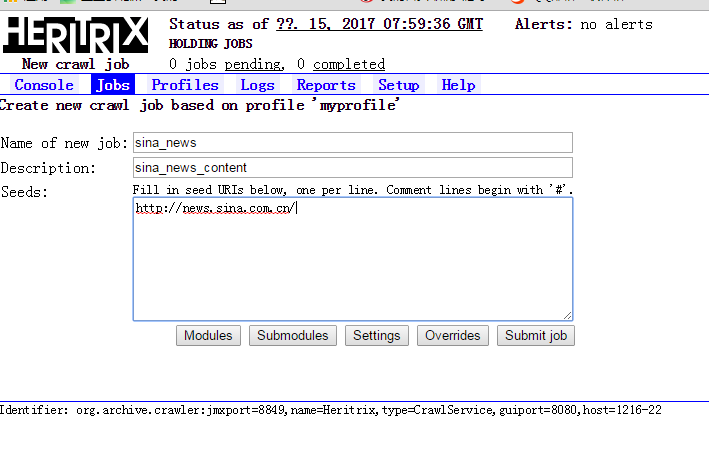
然后点击submit job,如果两个箭头都显示才表示创建job成功,相反我有一个配置类的没有点击change下面一个箭头就会提示初始化错误!

此时你进入console点击Start就会开始执行任务:
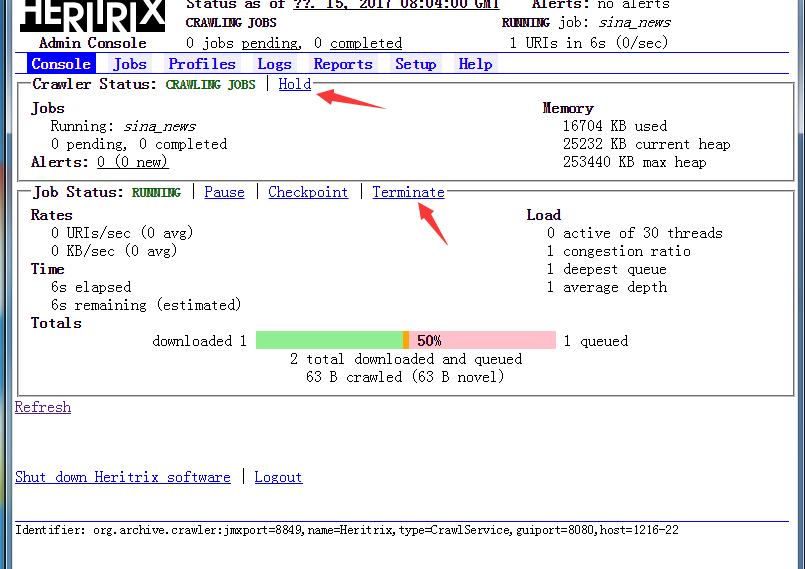
如果你要结束或者暂停任务,点击Terminate。
此时线程在不断爬取数据,你不断的点击Refresh会发现在不断更新数据,然后爬取的文件会在heritrix的根目录jobs里面找到,所有数据存放位置在如下路径的mirror文件夹内:
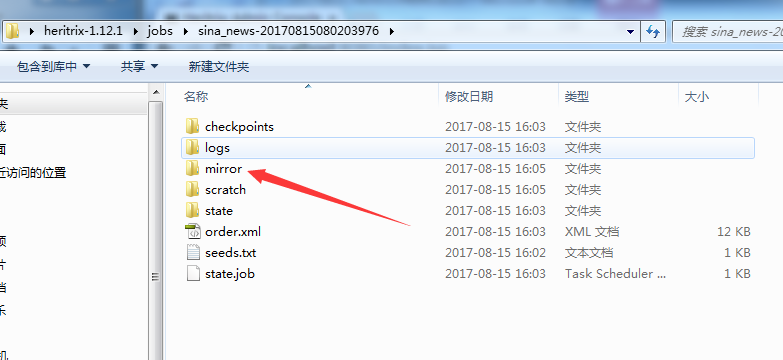
到此刻,网络爬取结束,如上就是这个工具的使用方法。
4‘ 如何有选择的爬取网页
测试时会发现,爬取的内容太杂,不一定都是我们想要的,因此我们需要对这个工具的源代码进行一些简单的调整。
首先要将heritrix的jar包备份解压;
然后需要将heritrix-1.12.1.jar文件拷贝到一个项目里,基于这个文件来进行配置。
package org.liky.utils; import org.archive.crawler.datamodel.CandidateURI;
import org.archive.crawler.postprocessor.FrontierScheduler; public class SinaNewsScheduler extends FrontierScheduler { public SinaNewsScheduler(String name) {
super(name);
} @Override
public void schedule(CandidateURI caUri) {
// 根据路径,判断该url是否有必要抓取。
// 这里我们要求路径必须包含, news.sina.com.cn
if (caUri.toString().contains("news.sina.com.cn")) {
// 允许爬取
super.schedule(caUri);
}
}
}
自己编写好这个工具类。
编写好以后,需要将这个类打包到jar包里。(使用class文件)
之后,修改modules下的Processor.options文件。
将以下内容加入到这个文件中。
|
org.liky.utils.SinaNewsScheduler|SinaNewsScheduler |
|
前半部分是包.类名,后半部分就是类名,中间用 | 分隔。 |
然后使用jar命令将包打到一起。
将jar包替换掉原有的包(可以把原有的做个备份留下,防止打包有问题无法恢复)。
重新启动heritrix,然后修改Profile的配置。
此时,再次爬取新浪新闻的时候,只会提取链接含有指定字符串的网址,排除很多无关的链接。
总结:
相对来说,Heritrix工具来爬取网页数据是相当简单的,无需写代码就可以进行大量的数据收集。
但是,与我上一篇博客《java实现网络爬虫》还是有些许不同:
首先在自由度上,手写的代码可以确认爬取的深度、排除无需爬取的网页、提取有用的数据;
其次在内容上很繁杂,很多无效的数据也收集了,而且爬取的网页会越来越多(当然,有一种修改配置的方法,写一个java代码限制爬取的网页,然后将该class文件放入heritrix的jar包(上述第四个标题)),关于修改源代码我相信很多新手都会望而止步,而且多写java代码来实现网络爬虫,益处多多;
最后在下一步数据分析上,可能多一点麻烦,谁会乐意整理一堆繁杂纷乱的数据呢?
至此,我还是倾向于java代码实现网络爬虫,而且可以很方便的将数据收集到hadoop中,进行大数据的mapreduce进行分析。
这样就相当于一个初步的大数据数据采集了。
Heritrix工具实现网络爬虫的更多相关文章
- 基于Heritrix的特定主题的网络爬虫配置与实现
建议在了解了一定网络爬虫的基本原理和Heritrix的架构知识后进行配置和扩展.相关博文:http://www.cnblogs.com/hustfly/p/3441747.html 摘要 随着网络时代 ...
- 网络爬虫系统Heritrix的结构分析 (个人读书报告)
摘要 随着网络时代的日新月异,人们对搜索引擎,网页的内容,大数据处理等问题有了更多的要求.如何从海量的互联网信息中选取最符合要求的信息成为了新的热点.在这种情况下,网络爬虫框架heritrix出现 ...
- python网络爬虫之自动化测试工具selenium[二]
目录 前言 一.获取今日头条的评论信息(request请求获取json) 1.分析数据 2.获取数据 二.获取今日头条的评论信息(selenium请求获取) 1.分析数据 2.获取数据 房源案例(仅供 ...
- 开源的49款Java 网络爬虫软件
参考地址 搜索引擎 Nutch Nutch 是一个开源Java 实现的搜索引擎.它提供了我们运行自己的搜索引擎所需的全部工具.包括全文搜索和Web爬虫. Nutch的创始人是Doug Cutting, ...
- 网络爬虫之Windows环境Heritrix3.0配置指南
一.引言: 最近在忙某个商业银行的项目,需要引入外部互联网数据作为参考,作为技术选型阶段的工作,之前已经确定了中文分词工具,下一个话题就是网络爬虫的选择,目标很明确,需要下载一些财经网站的新闻信息,然 ...
- crawler_浅谈网络爬虫
题记: 1024,今天是个程序猿的节日 ,哈哈,转为正题,从事了一线网络爬虫开发有近1000天.简单阐述下个人对网络爬虫的理解. 提纲: 1:是什么 2:能做什么 3:怎么做 4:综述 1:是什么 w ...
- 【转】44款Java 网络爬虫开源软件
原帖地址 http://www.oschina.net/project/lang/19?tag=64&sort=time 极简网络爬虫组件 WebFetch WebFetch 是无依赖极简网页 ...
- Python3之网络爬虫<0>初级
由于Python3合并URLib与URLlib2统一为URLlib,Python3将urlopen方法放在了urllib.request对象下. 官方文档:https://docs.python.or ...
- hadoop中实现java网络爬虫
这一篇网络爬虫的实现就要联系上大数据了.在前两篇java实现网络爬虫和heritrix实现网络爬虫的基础上,这一次是要完整的做一次数据的收集.数据上传.数据分析.数据结果读取.数据可视化. 需要用到 ...
随机推荐
- python迭代器生成器(三)
扩展的列表解析语法 今天接着昨天的继续写. 列表解析可以变得更加复杂---例如,它可以包含嵌套的循环,也可能被编写为一系列的for子句.(这里只是简单介绍一下,以后再说这个语法的问题) 例如:构建一个 ...
- java程序员常见面试题目
答:每当程序出现异常之后,如果程序没有进行相应的处理,则程序会出现中断现象.实际上,产生了异常之后,JVM会抛出一个异常类的实例化对象,如果此时使用了try语句捕获的话,则可以进行异常的处理,否则 ...
- 原声js 五子棋 源码
Welcome to use MarkDown <style type="text/css"> .box{ width: 600px; height: 600px; b ...
- VB6之CRC32
翻译篇:http://www.cnblogs.com/duzouzhe/archive/2009/08/05/1539543.html Private Declare Function GetTick ...
- voa 2015.4.29
Nepal has declared three days of mourning for the victims of Saturday's 7.8 magnitude earthquake tha ...
- 互联网级监控系统必备-时序数据库之Influxdb
时间序列数据库,简称时序数据库,Time Series Database,一个全新的领域,最大的特点就是每个条数据都带有Time列. 时序数据库到底能用到什么业务场景,答案是:监控系统. Baidu一 ...
- Codeforces Round #424 (Div. 2, rated, based on VK Cup Finals)A B题
当时晚上打CF时候比较晚,加上是集训期间的室友都没有晚上刷题的习惯,感觉这场CF很不在状态.A题写复杂WA了一发后去厕所洗了个脸冷静了下,换个简单写法,可是用cin加了ios::sync_with_s ...
- vue vuex 提交 this.$store.commit({type: 'setSelectPro', selectPro: this.productId});
1.store.commit({'type':'mutation','parameter':'value'}); store.dispatch('action'); 2.获取state保存的值 sto ...
- CSS3文本
1.文字省略 text-overflow:ellipsis; overflow:hidden; white-space:nowrap; //text-overflow(clip.ellipsis)只是 ...
- vs2015数据驱动的单元测试
今天在做测试的时候boss让我这个菜鸟做vs2015下c#的单元测试,并且给了我参考http://www.cnblogs.com/kingmoon/archive/2011/05/13/2045278 ...