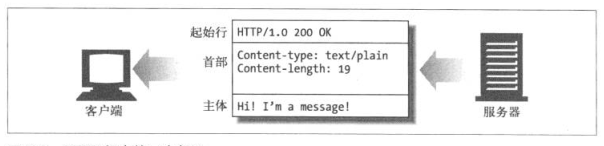
HTTP报文
HTTP报文是HTTP应用程序间发送的数据块,它由三部分组成:起始行(start line),首部(header)和主体(body),如下图所示:
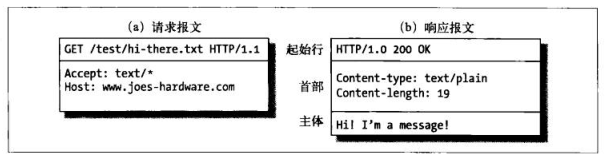
从分类上,报文又可以分为请求报文和响应报文
报文结构
请求报文的结构:
--------------------------------
<方法> <URL> <版本>
--------------------------------
<首部>
--------------------------------
<主体>
--------------------------------
响应报文的结构
--------------------------------------
<版本> <状态码> <原因短语>
--------------------------------------
首部
--------------------------------------
主体
--------------------------------------
【注意】 请求报文和响应报文在结构上只有起始行有不同
图示如下:
下面对上面的结构组成部分进行进一步的解释
起始行各成分解析
方法(method)
方法是客户端用于告诉服务器希望做什么事情,它包括GET, POST, OPTIONS, PUT,DELETE等。例如:GET表示客户机告诉服务器想要发来一份文档, POST表示客户机想要传一份数据过去给服务器处理, OPTIONS表示客户机在不了解的情况下询问服务器:你能处理哪些方法呀? PUT表示将请求报文上的主体让服务器保存下来,DELETE表示在服务器上删除一份文档
URL
请求的资源的路径
版本
版本(version)的一般格式为HTTP/x.y, 其中x表示主要版本号,y表示次要版本号, 版本用于客户机和服务器相互告知对方自己能够处理的HTTP协议的最高等级, 这里要说明一下的是 x.y并不是一个数字,而是两个, HTTP/2.22是要比HTTP/2.23的等级高的
状态码
方法是客户端用来告诉服务器:“我想要做什么事情”
而状态码则是服务器用来告诉客户端:“你要我办的事情现在办得这样XXX了”
状态码用三位数字表示:
2开头表示成功
3开头表示资源被移走
4开头表示客户端请求出错
5开头表示服务器有错误
原因短语
原因短语用一个单词,去表示执行的大体情况,所以它覆盖的范围要比状态码大一些
例如起始行HTTP/2.0 200 OK 中的OK是表示执行成功的意思
HTTP连接管理
处于应用层的HTTP是以更底层的传输层的TCP为基础的,所以在这一小节我们都将探讨HTTP和TCP的关系所衍生出来的一些知识点
并行连接
关于HTTP和TCP有以下几点: 1. 每个Web页面上的对象都对应着一个HTTP事务 2. 每个HTTP事务由一个TCP连接传输 3. TCP连接耗时长, 实际上,在客户端和服务器没有过载的情况下, HTTP传输时延主要就是由TCP连接的时延构成的 4. 这几个TCP连接可以串行建立, 也可以并行地建立
串行连接: 先后建立多个TCP连接, 分别传输HTTP事务
并行连接: 同时建立多个TCP连接,处理HTTP事务
并行连接图示
并行连接的优势:
1.优化用户体验
串行连接有一个很明显的优势,那就是每个时刻只能加载一个页面上的对象,而不能多个页面对象同时加载, 假设一个极简的网站A由三部分组成:左栏的图片,中栏的图片和右栏的图片。
如果单纯依靠串行连接,(在网速比较慢的情况下)你可能会这样看到图片加载: 左栏一点一点地加载(中/右栏什么都没有),加载出左栏后,中栏一点一点的加载(右栏什么都没有),这样的用户体验实际是比较差的
如果依靠并行连接的话,情况就好一点: 左中右栏都一点一点的加载出来(当然每张图片的加载比之前的要慢), 这样就能获得比较好的用户体验
2. 可能要比串行连接快(可能)
我们上面说到,一般情况下, HTTP传输时延主要就是由TCP连接的时延构成的,所以并行连接的时候,TCP时延迟会叠加起来, 这会让并行连接比串行连接要快。 但为什么说不一定呢? 因为在带宽有限的情况下,多个通过TCP连接运行的HTTP事务对带宽的竞争很可能耗尽带宽,这样每个页面的对象都只能以较慢的速度加载
持久连接
一个TCP连接可以只用于处理一个HTTP事务, 并在该事务结束的时候关闭连接,这种连接方式叫做非持久连接; 当然, 一个TCP连接也可以在处理完一个事务后不关闭, 而处理多个HTTP事务,这种连接方式就叫持久连接。
同样,我们上面说到,HTTP传输时延主要就是由TCP连接的时延构成的,所以持久连接省去了相当一部分的TCP建立过程所用的时耗,因而取得了大幅度的性能提升
前面我们介绍了两种体系结构,那么基于http协议搭建的应用(Web应用)是基于哪种体系结构呢? 大家应该不难知道,是客户端/服务器结构,所以我们接下来的表述,都将基于这一结构展开
客户机/服务器结构在硬件层面, 你可以把他俩看成是两个主机,而在Web程序层面,你可以看成这是浏览器程序和服务器程序俩程序,因为我们接下来主要是从Web应用的层面描述http,所以在下面:
客户端 ==浏览器
客户端和服务器交互的技术: cookie
请先允许我用一个比喻来描述cookie的性质: 有这么一个人他叫“浏览器A”,因为他头发长的很快,所以他每过几天就要去洗头房...啊呸说错了!应该是理发店去理发,而这个理发店叫做“服务器理发店”(为人民服务的理发店嘛对不对!) 。
“浏览器A”第一次去“服务器理发店”理发的时候呢,因为他是第999到店理发的顾客,所以老板为他免费办了一张VIP卡,这张卡上上有和“浏览器A”先生唯一对应的编号,同时老板在单子上登记下了“浏览器A”先生的编号。从此以后就好办事了,因为每次“浏览器A”先生光临“服务器理发店”的时候,老板都可以根据他VIP卡上的定死的编号识别这个“浏览器A”先生,然后就可以:统计一下烫头的次数啦~ 记录下A先生喜欢什么发型啦~ 等到A先生理发的次数达到20次免费给他赠送3次理发机会啦,等等。。。。
cookie, 就是那张第一次进店的时候办的VIP卡!
cookie技术取决于四个关键点
1. 服务器发往浏览器的HTTP响应报文里的Set-cookie
2. 浏览器发往服务器的HTTP的请求报文里的Cookie首部行
3. 浏览器系统里用于保存不同网站cookie的cookie文件
4. 在Web站点有一个后端站数据库
如下图所示:
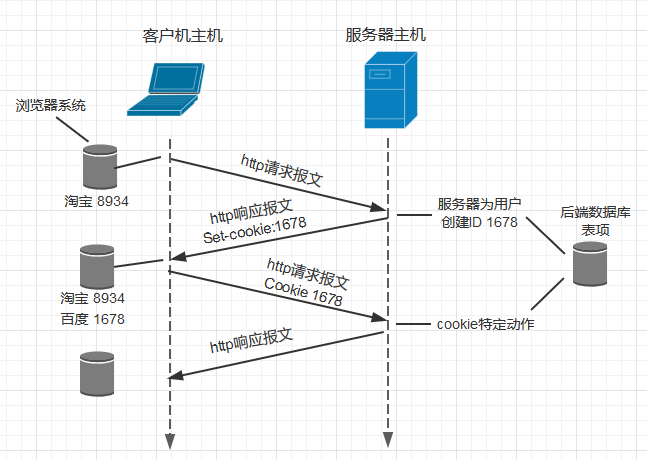
当彭先生使用他的笔记本电脑第一次访问百度网站baidu.com的时候,百度站点会产生一个唯一的识别码,并以此为索引在后端数据库生成一个表项,再然后baidu服务器用一个包含Set-cookie首部行的HTTP响应报文对彭先生的浏览器进行响应,其中Set-cookie上带有识别码,例如该首部行可能是:
Set-cookie: 1678
而当彭先生接受到该报文的时候,会在它的cookie文件中添加一行,其中包含该百度服务器的主机名和识别码1678
当彭先生使用他的笔记本电脑第二次和以后访问百度网站的时候,会在请求报文里面添加一行首部行
Cookie:1678, 百度服务器接收到这个响应报文的时候,它并不需要知道彭先生是谁,但通过cookie的唯一标志,它可以确切的记录每一次访问的时候访问了哪些页面,按照什么顺序,在什么时间
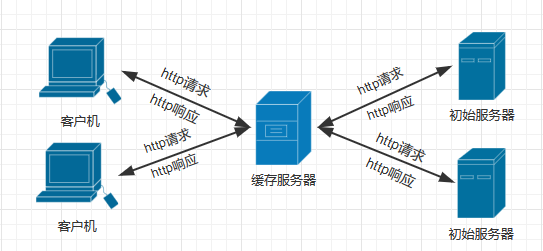
Web缓存服务器
Web缓存服务器(Web cache)会将客户机最近向原始服务器请求过的对象进行拷贝和保存,当客户机再次发起对原始服务器请求的时候,Web缓存服务器会进行检查:诶,这个对象是不是我早先保存过的呀? 如果是,这种现象就叫做”缓存命中“,再然后,这个请求在前往原始服务器的半路上被”劫道“了,这时,缓存服务器直接发送这个对象给客户机,而不需要继续把请求发给原始服务器了。
使用缓存服务器的好处:
1.避免了冗余的数据传输
2. 减少传播时延(距离时延)
3. 缓解了带宽瓶颈
4. 应对“瞬间拥塞”
下面我将一一解释:
一. 避免了冗余的数据传输
如果没有缓存服务器, 冗余的数据传输将会给原始服务器带来巨大的压力, 这次我以博客园为例: 我个人有个抓狂的毛病:在发出博客后我可能会在一段时间内一直刷新博客园的首页(就为了看自己的推荐数和阅读数有没有上升,顺便看会不会被移出首页), 我可能会在1分钟内连刷首页10次,但大家知道,在一分钟内一般没人会推新博客到首页,所以首页是没有任何变化的。假设没有缓存服务器,我可能一分钟内对博客园的原始服务器发出了10次冗余的请求! 再假设我同宿舍另外三个哥们也跟我做同样的事情的话,那就达到了每分钟40次的冗余请求(博客园旁白:你有病喵???)
所以如果没有缓存服务器:1. 给原始服务器带来不必要的负载压力 2. 浪费我的带宽
二. 减少传播时延
客户端和原始服务器一般离得比较远, 所以分组的传播时延比较长。例如我家住广东,要访问一个服务器在北京的网址的话, 因为北京和广东距离大约为1900千米, 用最快的物理介质光纤来计算的话:传播时延要1900千米 / (300000千米/s) ≈ 60毫秒,
而相比起原始服务器,缓存服务器和客户端“离得很近”(一般由学校或居民区的ISP配置),所以走过的链路长度短,所以分组传播时延就短到可以忽略不计的地步
三. 缓解带宽瓶颈
当客户机和初始服务器的瓶颈带宽远低于客户机和缓存服务器的瓶颈带宽的时候,增加缓存服务器能降低链路的流量强度,流量强度降低意味着链路相对“没那么拥挤了”,从而减少了分组的排队时延
下面举个实际的例子进一步证明缓存服务器的优点
在举例子前,先说一下流量强度的概念: 流量强度(traffic intensity) = 实际数据传输速率/ 链路最大传输速率, 设计链路的时候流量强度不能大于等于1, 因为这时候分组的排队时延将很大并且不断增长
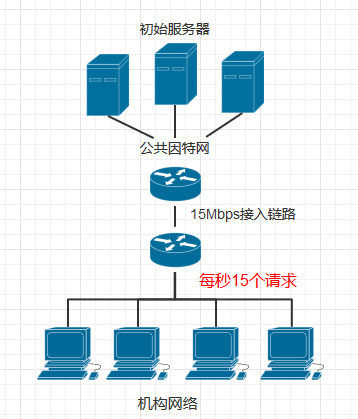
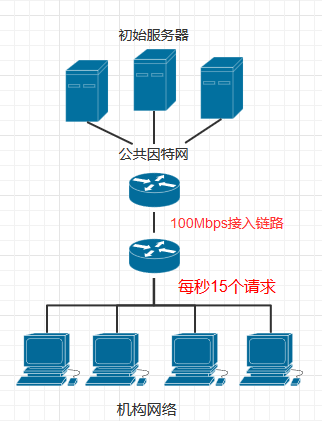
如下图所示, 一个机构(如公司)的内部网络是个高速局域网,内部网络和因特网通过一条15Mbps的链路连接,我们假设和公共因特网相连的路由器从转发请求到接收到响应所用平均时长为2s
同时假设机构内的请求速率为每秒15个请求,每个请求对象的平均长度为1Mb,那么可以得出公共接入链路的流量强度为(15个请求/秒) × (1Mb/请求) / (15Mbps) = 1, 接入链路接近1的流量强度会使得分组时延很大而且不断增长,这时所有客户机将长时间得不到响应,所以我们需要采取措施减少接入链路的流量强度
减少接入链路的流量强度的方式有两种:
1. 增加接入链路的带宽
2. 增设缓存服务器
让我们先看看采用第一种方式会怎样:
方案一.通过增加带宽
如上图所示,我们将接入链路的速率从15Mbps拓宽到100Mbps,那么这时候接入链路的流量强度为(15个请求/秒) × (1Mb/请求) / (100Mbps) = 0.15,在流量强度为0.15的情况下,接入链路的排队时延很短,几乎可以忽略,那么这时候每个请求的平均时延就是2s(前面假设的和因特网相连的路由器从转发请求到接收到响应所用的平均时长)
OK. 让我们评价下方案一(通过增加带宽减少流量强度)
1. 平均时延2s
2. 增加接入链路带宽所付出的高成本
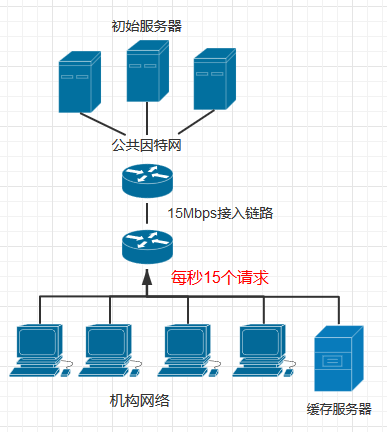
方案二. 增设缓存服务器
我们现在尝试第二种方案: 不增加接入链路的带宽(仍然是15Mbps),而是为机构的客户机增加一个缓存服务器
我们假设缓存服务器的命中率是0.4, 那么也就是说,缓存服务器能够拦截掉40%通过接入链路进入因特网的请求,很显然,这时候流量强度将由原来的1下降到 1 - 1 × 0.4 = 0.6, 对一条15Mbps的链路来说, 流量强度小于0.8的时候时延很小(几十毫秒,和假设的2s的因特网时延相比可以忽略)
假设缓存命中时,缓存服务器直接返回响应所用时延为0.01s
那么客户机得到响应的平均时延应该为:
0.4 × 0.01s + 0.6 × 2s = 1.204s约等于1.2s
(0.4的几率缓存命中,从缓存服务器返回响应,0.6的几率未命中,请求进入因特网)
OK. 让我们评价下方案二(通过增设缓存服务器减少流量强度)
1. 平均时延1.2s
2. 相比于方案一(增加接入链路带宽)来说成本低(很多缓存器就是使用在廉价PC机上运行的公共领域软件)
四. 应对“瞬间拥塞”
“瞬间拥塞”是原始服务器最为恐惧的状况之一, 那就是,在一个难以预料的时间节点,无数的客户端突然对原始服务器发起海量的请求,例如前段时间的鹿晗炸掉微博的事件就是一个例子,但实际上,虽然微博还是炸了,但缓存服务器也付出了它力所能及的帮助,不然的话,微博崩掉的时间点还得往前提。
条件GET请求
Web缓存固然给我们带来了一系列的便利,但与此同时我们还需要考虑另外一些问题: 如果缓存服务器里面保存的对象是陈旧的该怎么办呢?
例如就可能存在这么一种情况: 我每天都喜欢浏览博客园的首页,去看看他人写的新博客,也许在我第一次浏览博客园网站的时候,缓存服务器帮我保存了和这个网站相关的所有对象,当然,我下次浏览博客园的时候速度会快很多(这会让我感觉很好), 但是! 我却永远只能看到我第一次进博客园时所能看到的那些旧的博客页面,这该是多么难受的一件事情! 博客园每隔几分钟就会有新写的博客被推进首页,但我却永远看不到,就因为缓存服务器已经强制做了“缓存”这件事情
当然, 缓存服务器自有一套机制避免这个烦恼降临, 它就是条件GET请求
如果一个请求满足以下两个条件:
1. 请求报文使用GET方法
2. 请求报文中包含一个If-modified-since首部行(if-modified-since: 日期XX 表示询问: 对象在日期XX后是否修改(更新)过?)
那么这个请求报文就是一个条件GET请求
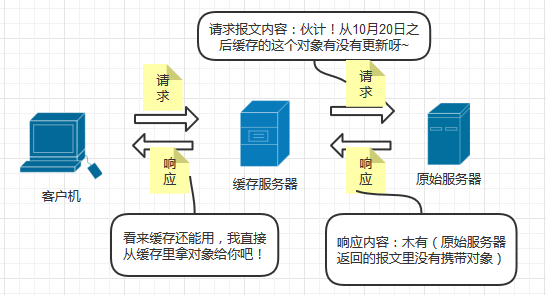
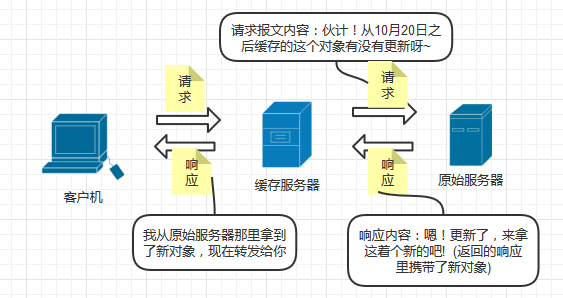
缓存服务器在接收到客户机的请求后,可以向原始服务器发送条件GET请求,用于确认对象是否更新过
1.如果对象在约定时间后没有更新,则原始服务器发回一个不携带请求对象的报文(节约带宽),告诉缓存服务器缓存是“新”的, 可以使用
2. 如果对象在约定时间后有更新,则原始服务器发回一个携带新对象的报文给缓存服务器
【完】
- 计算机网络-应用层(5)P2P应用
P2P系统的索引:信息到节点位置(IP地址+端口号)的映射 在文件共享(如电驴中):利用索引动态跟踪节点所共享的文件的位置.节点需要告诉索引它拥有哪些文件.节点搜索索引从而获知能够得到哪些文件 在即时 ...
- 计算机网络-应用层之HTTP协议
1.概念 HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写:HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等). ...
- [计算机网络-应用层] HTTP协议
1.HTTP概况 Web的应用层协议是超文本传输协议(HTTP),它是Web的核心. HTTP由两部分程序实现:一个客户机程序和一个服务器程序,它们运行在不同的端系统中,通过交换HTTP报文进行对话. ...
- 计算机网络-应用层(4)DNS协议
域名系统(Domain Name System, DNS):一个分层的由DNS服务器实现的分布式数据库+一个使得主机能够查询分布式数据库的应用层协议 DNS服务器通常是运行BIND (Berkeley ...
- 计算机网络应用层之cookie
一.生活中的cookie 无论你知不知道Cookie是什么,在你的生活中,肯定有使用过它.还记得你使用浏览器浏览网页时,当你要登陆时,网页上有一个记住密码或自动登陆的选项,当你选择时,你就使用了Coo ...
- [计算机网络-应用层] DNS:因特网的目录服务
我们知道有两种方式可以识别主机:通过主机名或者IP地址.人们喜欢便于记忆的主机名标识,而路由器则喜欢定长的.有着层次结构的IP地址.为了折中这些不同的偏好,我们需要一种能进行主机名到IP地址转换的目录 ...
- [计算机网络-应用层] FTP协议
文件传输协议:FTP 如下图所示:用户通过一个FTP用户代理与FTP交互.该用户首先提供远程主机的主机名,使本地主机的FTP客户机进程建立一个到远程主机FTP服务器进程的TCP连接.然后,该用户提供用 ...
- [计算机网络-应用层] P2P应用
首先我们要先来区分一下下面的几种体系结构: CS:Client/Server 客户-服务器结构BS:Browser/Server 浏览器-服务器结构 P2P:Peer to Peer 对等结构 BS ...
- 计算机网络-应用层(3)Email应用
因特网电子邮箱系统主要由用户代理(user agent) .邮件服务器(mail server) 和简单邮件传输协议(SMTP)组成 邮件服务器(Mail Server) 邮箱:存储发给该用户的E ...
- 计算机网络-应用层(2)FTP协议
文件传输协议(FTP,File Transfer Protocol)是Internet上使用最广泛的文件传送协议.FTP提供交互式的访问,允许客户指明文件的类型与格式,并允许文件具有存取权限.它屏蔽了 ...
随机推荐
- 201521123044 《Java程序设计》第9周学习总结
1. 本章学习总结 2. 书面作业 本次PTA作业题集异常 1.常用异常题目5-1 1.1 截图你的提交结果(出现学号) 1.2 自己以前编写的代码中经常出现什么异常.需要捕获吗(为什么)?应如何避免 ...
- 201521123002 《Java程序设计》第13周学习总结
本次作业参考文件 正则表达式参考资料 1. 本周学习总结 以你喜欢的方式(思维导图.OneNote或其他)归纳总结多网络相关内容. 网络 基本概念:协议 IP 域名 端口 通信:socket URL ...
- 201521123089 《Java程序设计》第11周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多线程相关内容. 2. 书面作业 本次PTA作业题集多线程 Q1.互斥访问与同步访问 1.1 除了使用synchronized修饰方 ...
- while循环_do_while循环_switch
swith语法: switch(值) { case 值1: 语句 break; case 值2: 语句 break; case 值3: 语句 break; default: break; } 1.值与 ...
- PowerBI开发 第四篇:DAX表达式
DAX 表达式主要用于创建度量列(Measure),度量值是根据用户选择的Filter和公式,计算聚合值,DAX表达式基本上都是引用对应的函数,函数的执行有表级(Table-Level)上下文和行级( ...
- logback:用slf4j+logback实现多功能日志解决方案
slf4j是原来log4j的作者写的一个新的日志组件,意思是简单日志门面接口,可以跟其他日志组件配合使用,常用的配合是slf4j+logback,无论从功能上还是从性能上都较之log4j有了很大的提升 ...
- headfirst设计模式(3)—装饰者模式
序 好久没写设计模式了,自从写了两篇之后,就放弃治疗了,主要还是工作太忙了啊(借口,都是借口),过完年以后一直填坑,填了好几个月,总算是稳定下来了,可以打打酱油了. 为什么又重新开始写设计模式呢?学习 ...
- Apache Spark 2.2.0 中文文档 - Spark 编程指南 | ApacheCN
Spark 编程指南 概述 Spark 依赖 初始化 Spark 使用 Shell 弹性分布式数据集 (RDDs) 并行集合 外部 Datasets(数据集) RDD 操作 基础 传递 Functio ...
- String,StringBuffer,StringBuilder的区别及其源码分析
String,StringBuffer,StringBuilder的区别这个问题几乎是面试必问的题,这里做了一些总结: 1.先来分析一下这三个类之间的关系 乍一看它们都是用于处理字符串的java类,而 ...
- Android 之内容提供者 内容解析者 内容观察者
contentProvider:ContentProvider在Android中的作用是对外提供数据,除了可以为所在应用提供数据外,还可以共享数据给其他应用,这是Android中解决应用之间数据共享的 ...


m2~74eij(@~f.png)