Python爬虫番外篇之关于登录
常见的登录方式有以下两种:
- 查看登录页面,csrf,cookie;授权;cookie
- 直接发送post请求,获取cookie
上面只是简单的描述,下面是详细的针对两种登录方式的时候爬虫的处理方法
第一种情况
这种例子其实也比较多,现在很多网站的登录都是第一种的方法,这里通过以github为例子:
分析页面
获取authenticity_token信息
我们都知道登录页面这里都是一个form表单提交,我可以可以通过谷歌浏览器对其进行分析
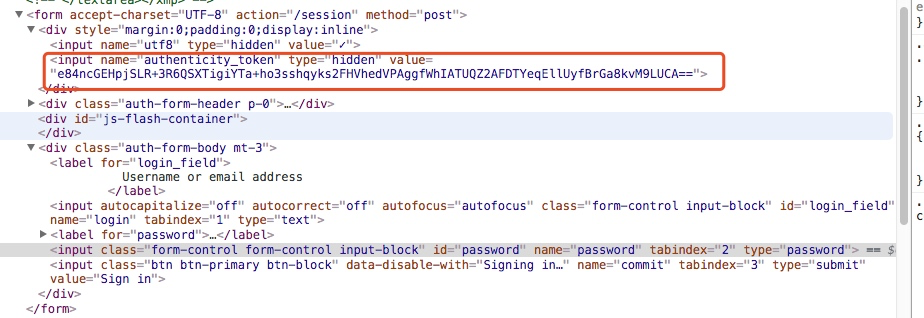
如上图我们找到了这个token信息
所以我们在登录之前应该先通过代码访问这个登录页面获取这个authenticity_token信息
获取登陆页面的cookie信息
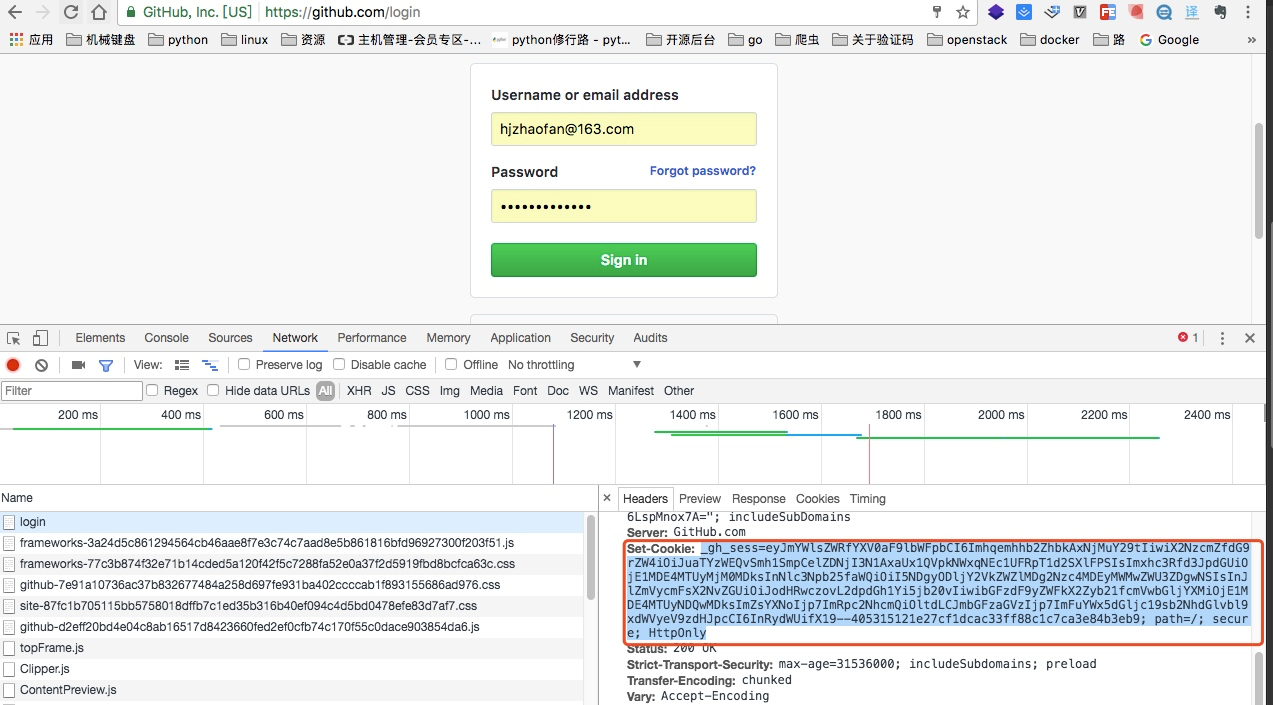
set-cookie这里是登录页面的cookie
分析登录包获取提交地址
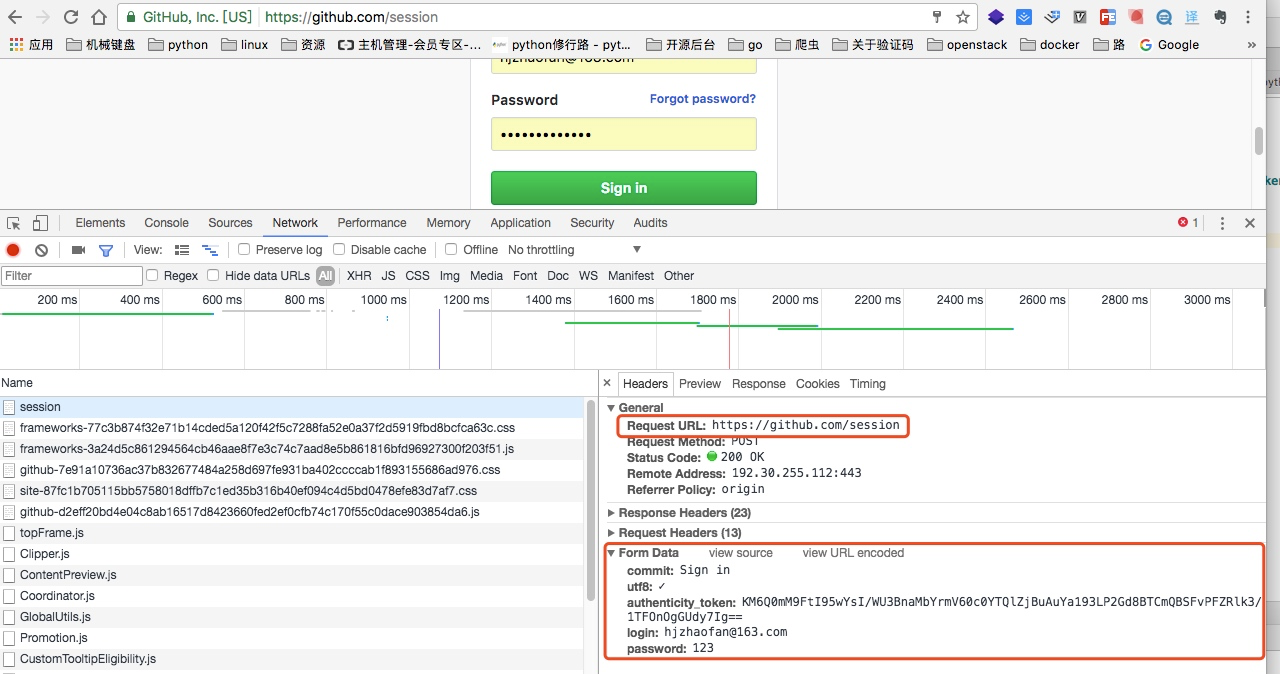
当我们输入用户名和密码之后点击提交,我们可以从包里找到如上图的地址,就是post请求提交form的信息
请求的地址:https://github.com/session
请求的参数有:
"commit": "Sign in",
"utf8":"✓",
"authenticity_token":“KM6Q0mM9FtI95wYsI/WU3BnaMbYrmV60c0YTQlZjBuAuYa193LP2Gd8BTCmQBSFvPFZRlk3/1TFOnOgGUdy7Ig==”,
"login":"hjzhaofan@163.com",
"password":"123"
从这里我们也可以看出提交参数中的“authenticity_token”,而这个参数就是需要我们从登陆页面先获取到。
当我们登录成功后:

再次访问github,这个时候cookie里就增加了两个cookie信息,而这个信息是登录后在增加的信息
所以如果我们想要通过程序登录,我们就需要在登录成功后再次获取cookie信息
然后通过这个cookie去访问我们github的其他信息例如我们的个人信息设置页面:
https://github.com/settings/profile
代码实现
下面代码实现了登录并访问https://github.com/settings/repositories
import requests
from bs4 import BeautifulSoup Base_URL = "https://github.com/login"
Login_URL = "https://github.com/session" def get_github_html(url):
'''
这里用于获取登录页的html,以及cookie
:param url: https://github.com/login
:return: 登录页面的HTML,以及第一次的cooke
'''
response = requests.get(url)
first_cookie = response.cookies.get_dict()
return response.text,first_cookie def get_token(html):
'''
处理登录后页面的html
:param html:
:return: 获取csrftoken
'''
soup = BeautifulSoup(html,'lxml')
res = soup.find("input",attrs={"name":"authenticity_token"})
token = res["value"]
return token def gihub_login(url,token,cookie):
'''
这个是用于登录
:param url: https://github.com/session
:param token: csrftoken
:param cookie: 第一次登录时候的cookie
:return: 返回第一次和第二次合并后的cooke
''' data= {
"commit": "Sign in",
"utf8":"✓",
"authenticity_token":token,
"login":"你的github账号",
"password":"*****"
}
response = requests.post(url,data=data,cookies=cookie)
print(response.status_code)
cookie = response.cookies.get_dict()
#这里注释的解释一下,是因为之前github是通过将两次的cookie进行合并的
#现在不用了可以直接获取就行
# cookie.update(second_cookie)
return cookie if __name__ == '__main__':
html,cookie = get_github_html(Base_URL)
token = get_token(html)
cookie = gihub_login(Login_URL,token,cookie)
response = requests.get("https://github.com/settings/repositories",cookies=cookie)
print(response.text)
第二种情况
这里通过伯乐在线为例子,这个相对于第一种就比较简单了,没有太多的分析过程直接发送post请求,然后获取cookie,通过cookie去访问其他页面,下面直接是代码实现例子:
http://www.jobbole.com/bookmark/ 这个地址是只有登录之后才能访问的页面,否则会直接返回登录页面
这里说一下:http://www.jobbole.com/wp-admin/admin-ajax.php是登录的请求地址这个可以在抓包里可以看到
import requests
def login():
url = "http://www.jobbole.com/wp-admin/admin-ajax.php"
data = {
"action": "user_login",
"user_login":"zhaofan1015",
"user_pass": '******',
}
response = requests.post(url,data)
cookie = response.cookies.get_dict()
print(cookie)
url2 ="http://www.jobbole.com/bookmark/"
response2 = requests.get(url2,cookies=cookie)
print(response2.text) login()
Python爬虫番外篇之关于登录的更多相关文章
- Python爬虫番外篇之Cookie和Session
关于cookie和session估计很多程序员面试的时候都会被问到,这两个概念在写web以及爬虫中都会涉及,并且两者可能很多人直接回答也不好说的特别清楚,所以整理这样一篇文章,也帮助自己加深理解 什么 ...
- python爬虫番外篇(一)进程,线程的初步了解
一.进程 程序并不能单独和运行只有将程序装载到内存中,系统为他分配资源才能运行,而这种执行的程序就称之为进程.程序和进程的区别在于:程序是指令的集合,它是进程的静态描述文本:进程是程序的一次执行活动, ...
- python之爬虫--番外篇(一)进程,线程的初步了解
整理这番外篇的原因是希望能够让爬虫的朋友更加理解这块内容,因为爬虫爬取数据可能很简单,但是如何高效持久的爬,利用进程,线程,以及异步IO,其实很多人和我一样,故整理此系列番外篇 一.进程 程序并不能单 ...
- python爬虫【实战篇】模拟登录人人网
requests 提供了一个叫做session类,来实现客户端和服务端的会话保持 使用方法 1.实例化一个session对象 2.让session发送get或者post请求 session = req ...
- python学习番外篇——字符串的数据类型转换及内置方法
目录 字符串的数据类型转换及内置方法 类型转换 内置方法 优先掌握的方法 需要掌握的方法 strip, lstrip, rstrip lower, upper, islower, isupper 插入 ...
- python自动化测试应用-番外篇--接口测试2
篇2 book-python-auto-test-番外篇--接口测试2 --lamecho辣么丑 大家好! 我是lamecho(辣么丑),今天将继续上一篇python接 ...
- #3使用html+css+js制作网页 番外篇 使用python flask 框架 (II)
#3使用html+css+js制作网页 番外篇 使用python flask 框架 II第二部 0. 本系列教程 1. 登录功能准备 a.python中操控mysql b. 安装数据库 c.安装mys ...
- #3使用html+css+js制作网页 番外篇 使用python flask 框架 (I)
#3使用html+css+js制作网页 番外篇 使用python flask 框架(I 第一部) 0. 本系列教程 1. 准备 a.python b. flask c. flask 环境安装 d. f ...
- 给深度学习入门者的Python快速教程 - 番外篇之Python-OpenCV
这次博客园的排版彻底残了..高清版请移步: https://zhuanlan.zhihu.com/p/24425116 本篇是前面两篇教程: 给深度学习入门者的Python快速教程 - 基础篇 给深度 ...
随机推荐
- JavaScript事件与例子
事件,就是预先设置好的一段代码,等到用户触发的时候执行. 一:常见的事件: 1.关于鼠标的事件 onclick 鼠标单击触发 ondblclick 鼠标双击触发 onmouseover 鼠标移上触发 ...
- 深入理解 JavaScript 事件循环(二)— task and microtask
引言 microtask 这一名词是 JS 中比较新的概念,几乎所有人都是在学习 ES6 的 Promise 时才接触这一新概念,我也不例外.当我刚开始学习 Promise 的时候,对其中回调函数的执 ...
- kaggle
注册kaggle可真所谓费劲心思,先是邮箱验证不来,换了两三个浏览器都不成功,非常恼火,没有验证码,最后还是FQ加谷歌浏览器,哎,注册之旅还是非常坎坷德,但是好消息是注册成功了.接下来是机器学习语言, ...
- 使用jQuery修改动态修改超链接
以下是修改a元素标签的href链接和文字的代码: <script type="text/javascript" src="jquery-1.9.1.min.js&q ...
- TCP札记
协议对于通信就像算法对于计算一样.算法允许人们在不必知道特定的CPU指令集的情况下指定或理解具体的计算形式.同样地,通信协议允许人们不依赖特定厂家的网络硬件来指定或理解数据通信. 网络协议通常分不同层 ...
- mysql安装不上 failed to install the service
先前安装的没有卸载干净必须删除相应的注册表方法如下:1)“运行”中敲入“Regedit”进入注册表编辑2)HKEY_LOCAL_MACHINE->SYSTEM->ControlSet001 ...
- Linux常用操作命令(三)
查看linux日志某几行 用逆序显示命令tail查看 命令格式:tail [ -r ] [ -n Number ] [ File ] [一]从第3000行开始,显示1000行.即显示3000~39 ...
- 《Java编程思想》第一二章
前段时间一直通过网络教程学习Java基础,把面向对象部分学完之后本来打算继续深入学习,但是感觉自己操之过急了,基础根本不够扎实,所以入手了一本<Java编程思想>,希望先把基础打好,再深入 ...
- 虚拟硬盘格式vdi、vhd、vmdk相互转换
Windows7的引导程序能够引导vhd格式的虚拟硬盘,而VirtualBox创建的虚拟硬盘文件是vdi格式的,怎么办呢? 以前要借助其他软件才能实现,但是VirtualBox早就悄悄为我们带来了一个 ...
- eclipse 设置 默认编码为 utf-8
学习javaweb时,开发工具都采用utf-8的编码方式,给eclipse设置默认编码为utf-8的编码方法 菜单 Window -> preference -> General -> ...