Hadoop学习---Eclipse中hadoop环境的搭建
在eclipse中建立hadoop环境的支持
1.需要下载安装eclipse
2.需要hadoop-eclipse-plugin-2.6.0.jar插件,插件的终极解决方案是https://github.com/winghc/hadoop2x-eclipse-plugin下载并编译。也是可用提供好的插件。
3.复制编译好的hadoop-eclipse-plugin-2.6.0.jar复制到eclipse插件目录(plugins目录)下,如图所示
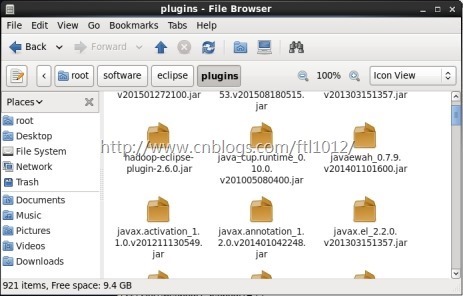
重启eclipse
4.在eclipse中配置hadoop安装目录
windows ->preference -> hadoop Map/Reduce -> Hadoop installation directory在此处指定hadoop的安装目录
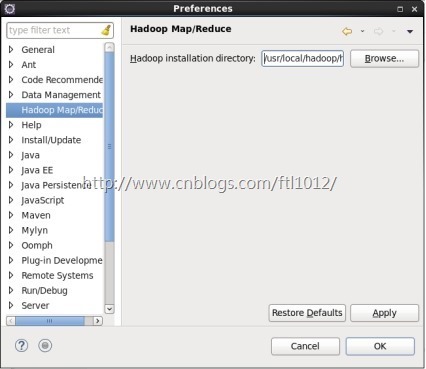
点击Apply,点击OK确定
5.配置Map Reduce视图
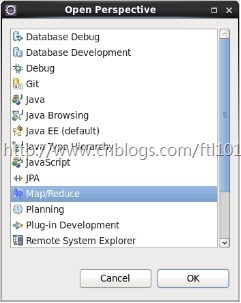
window -> Open Perspective ->other-> Map/Reduce -> 点击“OK”
window -> show view -> other -> Map/Reduce Locations -> 点击“OK”
6.在“Map/Reduce Location”Tab页点击图标<大象+>或者在空白的地方右键,选择“New Hadoop location...”,弹出对话框“New hadoop location...”,进行相应的配置
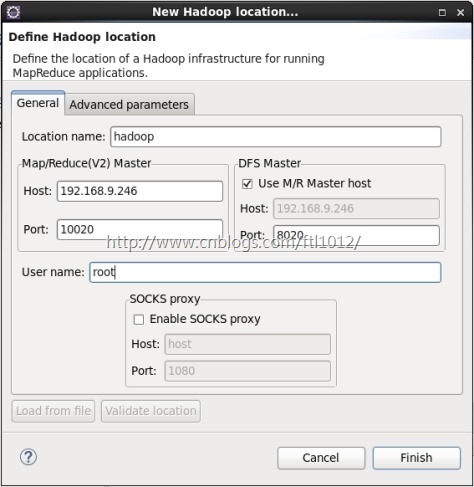
设置Location name为任意都可以,Host为hadoop集群中主节点所在主机的ip地址或主机名,这里MR Master的Port需mapred-site.xml配置文件一致为10020,DFS Master的Port需和core-site.xml配置文件的一致为9000,User name为root(安装hadoop集群的用户名)。之后点击finish。在eclipse的DFS Location目录下出现刚刚创建的Location name(这里为hadoop),eclipse就与hadoop集群连接成功,如图所示。

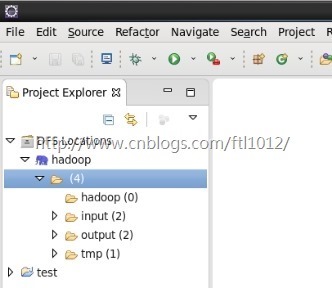
7.打开Project Explorers查看HDFS文件系统,如图所示
8.新建Map/Reduce任务
需要先启动Hadoop服务
File -> New -> project -> Map Reduce Project ->Next
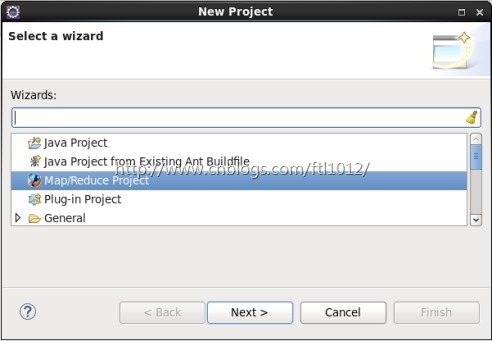
填写项目名称
编写WordCount类:
package test; import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class MyMap extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} public static class MyReduce extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(MyMap.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
运行WordCount程序:
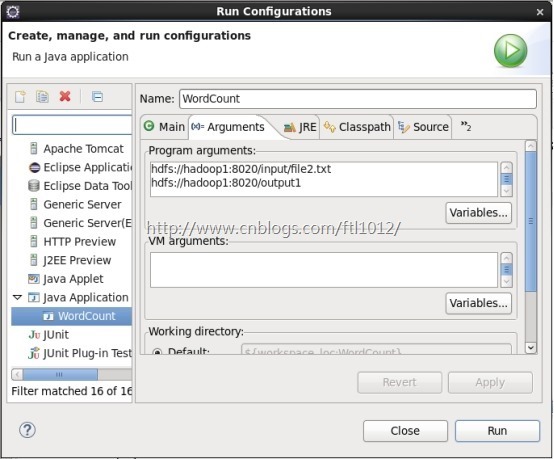
右键单击Run As -> Run Configurations
选择Java Applications ->WordCount(要运行的类)->Arguments
在Program arguments中填写输入输出路径,点击Run
Hadoop学习---Eclipse中hadoop环境的搭建的更多相关文章
- Hadoop学习---CentOS中hadoop伪分布式集群安装
注意:此次搭建是在ssh无密码配置.jdk环境已经配置好的情况下进行的 可以参考: Hadoop完全分布式安装教程 CentOS环境下搭建hadoop伪分布式集群 1.更改主机名 执行命令:vi / ...
- Hadoop学习---Ubuntu中hadoop完全分布式安装教程
软件版本 Hadoop版本号:hadoop-2.6.0-cdh5.7.0: VMWare版本号:VMware 9或10 Linux系统:CentOS 6.4-6.5 或Ubuntu版本号:ubuntu ...
- hadoop学习(一)环境的搭建
1.安装几台Linux虚拟机.安装的过程就不赘述了,网上教程很多.win7系统上装了一个VMWare,因为一些原因,VMWare版本不是最新的,是VMWare7.1版本,由于VMWare版本不高,所以 ...
- eclipse中JDK环境的搭建
现在就可以用记事本开发java程序了,但是eclipse是一款java开发不可缺少的IDE,并且安装简单,下面说一下步骤,首先下载eclipse, 官网下载链接:http://www.eclipse. ...
- Hadoop学习笔记(3)——分布式环境搭建
Hadoop学习笔记(3) ——分布式环境搭建 前面,我们已经在单机上把Hadoop运行起来了,但我们知道Hadoop支持分布式的,而它的优点就是在分布上突出的,所以我们得搭个环境模拟一下. 在这里, ...
- Hadoop在eclipse中的配置
在安装完linux下的hadoop框架,实现完所现有的wordCount程序,能够完美输出结果之后,我们开始来搭建在window下的eclipse的环境,进行相关程序的编写. 在网上有很多未编译版本, ...
- Eclipse中Hadoop插件配置
Eclipse中Hadoop插件DFS配置 http://www.cnblogs.com/xia520pi/archive/2012/05/20/2510723.html
- [转帖]hadoop学习笔记:hadoop文件系统浅析
hadoop学习笔记:hadoop文件系统浅析 https://www.cnblogs.com/sharpxiajun/archive/2013/06/15/3137765.html 1.什么是分布式 ...
- 吴裕雄--天生自然Hadoop学习笔记:Hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速运算和存储.Hadoop实现了一个分布式文件系统(H ...
随机推荐
- new Map的妙用
const actions = new Map([ [1, ['processing','IndexPage']], [2, ['fail','FailPage']], [3, ['fail','Fa ...
- redux-thunk, redux-logger 阮一峰 ( react中间件 )
http://www.ruanyifeng.com/blog/2016/09/redux_tutorial_part_two_async_operations.html Redux 入门教程(二):中 ...
- 初探flow.js
第一部分:前言 我们知道JS是弱类型语言,在声明变量时不论是什么类型的变量我们都用var即可,所以js是非常灵活的,但是同时问题就是弱类型语言有可能会出错,比如在调用函数时,且往往在运行起来时才可以检 ...
- 【C语言】-指针
本文目录 直接引用 一.什么是指针? 二.指针的定义 三.指针的初始化 四.指针运算符 五.指针的用途举例 六.关于指针的疑问 说明:这个C语言专题,是学习iOS开发的前奏.也为了让有面向对象语言开发 ...
- MacOS系统下的图形化工具
MacOS系统下的图形化工具 MacOS系统下安装了Git后,发现如果Git中有中文文档操作还是比较麻烦(需要输入中文的文件名).图形化对Git的操作还是相对于方便一些.所以准备找一个图形化的工具. ...
- 《c++primer》疑惑记录
第4章 96页,数组维数为变量 第8章 246. IO对象不可复制.赋值原因是类设计时复制构造函数.赋值函数是私有的,为什么这么设计呢? 251. tie举例 第15章 484 派生类可以恢复,但不可 ...
- 数据结构与算法(C++)大纲
1.栈 栈的核心是LIFO(Last In First Out),即后进先出 出栈和入栈只会对栈顶进行操作,栈底永远为0 1.1概念 栈底(bottom):栈结构的首部 栈顶(top):栈结构的尾部 ...
- tsung
要做针对mongodb的压力测试,下了个tsung,看看他的策略是什么,目前定位ts_launcher.erl:do_launch({Intensity, MyHostName, PhaseId})- ...
- ApplicationHost.config文件被破坏导致IIS崩溃
“”Application Host Helper Service 在尝试删除历史目录“C:\inetpub\history\CFGHISTORY_0000000475”时遇到错误.将跳过并忽略此目录 ...
- 廖雪峰JavaScript练习题2
请把用户输入的不规范的英文名字,变为首字母大写,其他小写的规范名字.输入:['adam', 'LISA', 'barT'],输出:['Adam', 'Lisa', 'Bart'] 肯定有更简单的方法, ...