大数据技术原理与应用——大数据处理架构Hadoop
Hadoop简介
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。
Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中。
Hadoop的核心是分布式文件系统(Hadoop Distributed File System,HDFS)和MapReduce。
Hadoop被公认为行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力。
Hadoop的特性
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性:
高可靠性:采用冗余数据存储方式,即使一个副本发生故障,其他副本也可以保证正常对外提供服务。
高效性:作为并行分布式计算平台,Hadoop采用分布式存储和分布式处理两大核心技术,能够高效地处理PB级数据。
高可扩展性:Hadoop的设计目标是可以高效稳定地运行在廉价的计算机集群上,可以扩展到数以千万计的计算机节点上。
高容错性:采用冗余数据存储方式,自动保存数据的多个副本,并且能够自动将失败的任务进行重新分配。
成本低:Hadoop采用廉价的计算机集群,成本比较低,普通用户也很容易用自己的PC搭建Hadoop运行环境。
运行在Linux平台上:Hadoop是基于Java语言开发的,可以较好地运行在Linux平台上。
支持多种编程语言:Hadoop上的应用程序也可以使用其他编程语言编写。
Hadoop生态系统
经过多年的发展。Hadoop生态系统不断完善和成熟,目前已经包括了多个子项目。除了核心的HDFS和MapReduce以外,Hadoop生态系统还包括Zookeeper,HBase,Hive,Pig,Mahout、Sqoop、Flume、Ambari等功能组件。需要说明的是,Hadoop2.0中新增了一些重要的组件,即HDFS HA和分布式资源调度管理框架YRAN等。
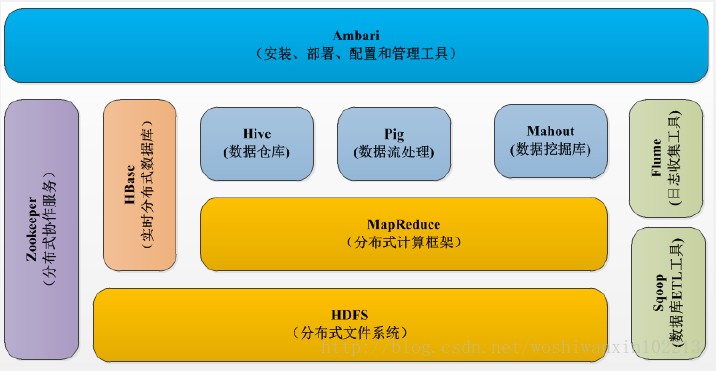
HDFS:Hadoop分布式文件系统是Hadoop项目的两大核心之一,是针对谷歌文件系统的开源实现。HDFS具有处理超大数据、流式处理、可以运行在廉价商用服务器上等优点。HDFS在设计之初就是要运行在廉价的大型服务器集群上,因此在设计上就把硬件故障作为一种常态来考虑,可以保证在部分硬件发生故障的情况下仍然能够保证文件系统的整体可用性和可靠性。
HBase:HBase是一个提供高可靠性、高性能、可伸缩、实时读写、分布式的列式数据库,一般采用HDFS作为其底层数据存储。HBase是针对谷歌BigTable的开源实现,二者都采用了相同的数据模型,具有强大的非结构化数据存储能力。HBase与传统关系数据库的一个重要区别是,前者采用基于列的存储,而后者采用基于行的存储。HBase具有良好的横向扩展能力,可以通过不断增加廉价的商用服务器来增加存储能力。
MapReduce:Hadoop MapReduce是针对谷歌MapReduce的开源实现。MapRedece是一种编程模型,用于大规模数据集(大于1TB)的并行运算,它将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数——Map和Reduce上,并且允许用户在不了解分布式系统底层细节的情况下开发并行应用程序,并将其运行于廉价计算机集群上,完成海量数据的处理。通俗地说,MapReduce的核心思想就是“分而治之”,它把输入的数据集切分为若干独立的数据块,分发给一个主节点管理下的各个分节点来共同并行完成;最后,通过整合各个节点的中间结果得到最终结果。
Hive:Hive是一个基于Hadoop的数据仓库工具,可以用于对Hadoop文件中数据集进行数据整理、特殊查询和分析存储。Hive学习门槛比较低,因为它提供了类似于关系数据库SQL语言的查询语句——Hive QL,可以通过Hive QL语句快速实现简单的MapReduce统计,Hive自身可以将Hive QL语句转换为MapReduce任务进行运行,而不必开发专门的MapReduce应用,因而十分适合数据仓库的统计分析。
Pig:是一种数据流语言和运行环境,适合于使用Hadoop和MapRedeuce平台来查询大型半结构化数据集。虽然MapReduce应用程序的编写不是十分复杂,但毕竟也是需要一定的开发经验的。Pig的出现大大简化了Hadoop常见的工作任务,它在MapReduce的基础上创建了更简单的过程语言抽象,为Hadoop应用程序提供了一种更加接近结构化查询语言(SQL)的接口。Pig是一个相对简单的语言,它可以执行语句,因此当我们需要从大型数据集中搜索满足某个给定搜索条件的记录时,采用Pig要比MapReduce具有明显的优势,前者只需要编写一个简单的脚本在集群中自动并行处理与分发,而后者则需要编写一个单独的MapReduce应用程序。
Mahout:Mahout是Apache软件基金会旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。
Zookeeper:是针对谷歌Chubby的一个开源实现,是高效和可靠的协同工作系统,提供分布式锁之类的基本服务(如统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等),用于构建分布式应用,减轻分布式应用程序所承担的协调任务,Zookeeper使用Java编写,很容易编程接入,它使用了一个和文件树结构相似的数据模型,可以使用Java或者C来进行编程接入。
Flume:是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统。Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理并写到各种数据接收方的能力。
Sqoop:是SQL-to-Hadoop的缩写,主要用来在Hadoop和关系数据库之间交换数据,可以改进数据的互操特性。通过Sqoop可以方便地将数据从MySQL、Oracle、PostgreSQL等关系数据库中导入Hadoop(可以导入HDFS、HBase或Hive),或者将数据从Hadoop导出到关系数据库,使得传统关系数据库和Hadoop之间的数据迁移变得非常方便。Sqoop主要通过JDBC和关系数据库进行交互,理论上,支持JDBC的关系数据库都可以使用Sqoop和Hadoop进行数据交互。Sqoop是专门为大数据集设计的,支持增量更新,可以将新纪录添加到最近一次导出的数据源上,或者指定上次修改的时间戳。(写到这里突然想起来面试的时候不知天高地厚非要和HR交流技术,HR问我将大规模数据从数据库导出应该使用什么技术,傻傻地回答JDBC。)
Ambari:Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的安装、部署、配置和管理。Ambari目前已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、HBase、Zookeeper、Sqoop等。
大数据技术原理与应用——大数据处理架构Hadoop的更多相关文章
- 【学习笔记】大数据技术原理与应用(MOOC视频、厦门大学林子雨)
1 大数据概述 大数据特性:4v volume velocity variety value 即大量化.快速化.多样化.价值密度低 数据量大:大数据摩尔定律 快速化:从数据的生成到消耗,时间窗口小,可 ...
- 大数据技术原理与应用:【第二讲】大数据处理架构Hadoop
2.1 Hadoop概论 创始人:Doug Cutting 1.简介: 开源免费; 操作简单,极大降低使用的复杂性; Hadoop是Java开发的; 在Hadoop上开发应用支持多种编程语言.不限于J ...
- 大数据技术原理与应用【第五讲】NoSQL数据库:5.1 NoSQL概论&5.2 NoSQL与关系数据库的比较
5.1 NoSQL概论 最初:反SQL 概念演变,现在:Not only SQL 特点: 1.灵活的可扩展性 所以支持海量数据存储 2.灵活的数据模型 例如:HBase 3.和云计算的紧密结合 (一) ...
- 大数据技术原理与应用——分布式文件系统HDFS
分布式文件系统概述 相对于传统的本地文件系统而言,分布式文件系统(Distribute File System)是一种通过网络实现文件在多台主机上进行分布式存储的文件系统.分布式文件系统的设计一般采用 ...
- 大数据技术原理与应用【第五讲】NoSQL数据库:5.6 文档数据库MongoDB
文档数据库介于关系数据库和NoSql之间: 是最像关系数据库的一款产品,也是当前最热门的一款产品. 1.MongoDB简介: 1) 2)文档类型BSON(Binary JSON),结构类似 ...
- 大数据技术原理与应用【第五讲】NoSQL数据库:5.4 NoSQL的三大基石
NoSQL的三大基石:cap,Base,最终一致性 5.4.1 cap理论(帽子理论): consistency:一致性availability:可用性partition tolerance: ...
- 大数据技术原理与应用【第五讲】NoSQL数据库:5.3 NoSQL的四大类型
5.3 NoSQL的四大类型 5.3.1 键值数据库和列族数据库 可以分为四大类产品:键值数据库,列族数据库,文档数据库,图数据库 (代表) 1.键值数据库: 用的多:redis云数据库: ...
- 学一下HDFS,很不错(大数据技术原理及应用)
http://study.163.com/course/courseMain.htm?courseId=1002887002 里面的HDFS这一部分.
- 大数据技术原理与应用【第五讲】NoSQL数据库:5.5 从NoSQL到NewSQL数据库
应用场景: OldSql数据库:希望一种架构就能支持多种应用场景,但证明不可能. NewSql数据库:同时具备OldSql和NoSQL各自的优点:水平可扩展性,强一致性,事务一致性,支持查询,支持 ...
随机推荐
- Linux-->Mysql:安装,测试
环境准备 mysql下载地址:https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.19-linux-glibc2.12-x86_64.tar ...
- Ubuntu下python的第三方module无法在pycharm中导入
换了台笔记本,新安装的requests module无法在pycharm导入: Traceback (most recent call last): File "/home/winsterc ...
- ubuntu 摄像头软件
sudo apt-get install cheese
- spring定时器quartz版本问题
如果quartz的版本是1.8.5启动会报错,修改给2.0版本以上即可 <dependency> <groupId>org.quartz-scheduler</group ...
- im2rec打包图片
https://mxnet.incubator.apache.org/faq/finetune.html python ~/mxnet/tools/im2rec.py --list --recursi ...
- 【[HNOI2006]超级英雄】
看到楼下有大佬说了网络流做法,来给大佬配个代码 我们只有我可能都觉得如果不动态加边的话\(dinic\)可能跑不了这种需要中途退出的二分图匹配 正当我准备去敲匈牙利的时候突然想到这个题可以二分啊 于是 ...
- 20、Springboot 与数据访问(JDBC/自动配置)
简介: 对于数据访问层,无论是SQL还是NOSQL,Spring Boot默认采用整合 Spring Data的方式进行统一处理,添加大量自动配置,屏蔽了很多设置.引入 各种xxxTemplate,x ...
- Mac python3.5 + Selenium 开发环境配置
一. python 3.5 1. 下载 2. Mac默认为2.7,所以这里主要介绍如何将系统Python默认修改为3.5. 原理: 1)Mac自带的python环境在: python2.7: /Sys ...
- 使用jmeter进行简单的压测
安装下载 前往官网下载,[地址] 环境 需要java环境,此处略 最好对jmeter配置下环境变量,方便打开,此处略 运行 启动jmeter 进入到bin目录,输入 ./jmeter 启动 ...
- 使用Redis存取数据+数据库存取(spring+java)
RoleMapper接口: package com.wbg.springRedis.dao; import com.wbg.springRedis.entity.Role; import org.sp ...