ResNet 修改
https://github.com/tornadomeet/ResNet
apache 开源项目
修改如下:
训练模块
import argparse,logging,os
import mxnet as mx
from symbol_resnet import resnet logger = logging.getLogger()
logger.setLevel(logging.INFO) def multi_factor_scheduler(begin_epoch, epoch_size, step=[60, 75, 90], factor=0.1):
step_ = [epoch_size * (x-begin_epoch) for x in step if x-begin_epoch > 0]
return mx.lr_scheduler.MultiFactorScheduler(step=step_, factor=factor) if len(step_) else None def main():
if args.data_type == "cifar10":
args.aug_level = 1
args.num_classes = 10
# depth should be one of 110, 164, 1001,...,which is should fit (args.depth-2)%9 == 0
if((args.depth-2)%9 == 0 and args.depth >= 164):
per_unit = [(args.depth-2)/9]
filter_list = [16, 64, 128, 256]
bottle_neck = True
elif((args.depth-2)%6 == 0 and args.depth < 164):
per_unit = [(args.depth-2)/6]
filter_list = [16, 16, 32, 64]
bottle_neck = False
else:
raise ValueError("no experiments done on detph {}, you can do it youself".format(args.depth))
units = per_unit*3
symbol = resnet(units=units, num_stage=3, filter_list=filter_list, num_class=args.num_classes,
data_type="cifar10", bottle_neck = bottle_neck, bn_mom=args.bn_mom, workspace=args.workspace,
memonger=args.memonger)
elif args.data_type == "imagenet":
args.num_classes = 3
if args.depth == 18:
units = [2, 2, 2, 2]
elif args.depth == 34:
units = [3, 4, 6, 3]
elif args.depth == 50:
units = [3, 4, 6, 3]
elif args.depth == 101:
units = [3, 4, 23, 3]
elif args.depth == 152:
units = [3, 8, 36, 3]
elif args.depth == 200:
units = [3, 24, 36, 3]
elif args.depth == 269:
units = [3, 30, 48, 8]
else:
raise ValueError("no experiments done on detph {}, you can do it youself".format(args.depth))
symbol = resnet(units=units, num_stage=4, filter_list=[64, 256, 512, 1024, 2048] if args.depth >=50
else [64, 64, 128, 256, 512], num_class=args.num_classes, data_type="imagenet", bottle_neck = True
if args.depth >= 50 else False, bn_mom=args.bn_mom, workspace=args.workspace,
memonger=args.memonger)
else:
raise ValueError("do not support {} yet".format(args.data_type))
kv = mx.kvstore.create(args.kv_store)
devs = mx.cpu() if args.gpus is None else [mx.gpu(int(i)) for i in args.gpus.split(',')]
epoch_size = max(int(args.num_examples / args.batch_size / kv.num_workers), 1)
begin_epoch = args.model_load_epoch if args.model_load_epoch else 0
if not os.path.exists("./model"):
os.mkdir("./model")
model_prefix = "model/resnet-{}-{}-{}".format(args.data_type, args.depth, kv.rank)
checkpoint = mx.callback.do_checkpoint(model_prefix)
arg_params = None
aux_params = None
if args.retrain:
_, arg_params, aux_params = mx.model.load_checkpoint(model_prefix, args.model_load_epoch)
if args.memonger:
import memonger
symbol = memonger.search_plan(symbol, data=(args.batch_size, 3, 32, 32) if args.data_type=="cifar10"
else (args.batch_size, 3, 128, 128))
train = mx.io.ImageRecordIter(
path_imgrec = os.path.join(args.data_dir, "cifar10_train.rec") if args.data_type == 'cifar10' else
os.path.join(args.data_dir, "train_256_q90.rec") if args.aug_level == 1
else os.path.join(args.data_dir, "train_480_q90.rec"),
label_width = 1,
data_name = 'data',
label_name = 'softmax_label',
data_shape = (3, 32, 32) if args.data_type=="cifar10" else (3, 128, 128),
batch_size = args.batch_size,
pad = 4 if args.data_type == "cifar10" else 0,
fill_value = 127, # only used when pad is valid
rand_crop = True,
max_random_scale = 1.0, # 480 with imagnet, 32 with cifar10
min_random_scale = 1.0 if args.data_type == "cifar10" else 1.0 if args.aug_level == 1 else 0.533, # 256.0/480.0
max_aspect_ratio = 0 if args.data_type == "cifar10" else 0 if args.aug_level == 1 else 0.25,
random_h = 0 if args.data_type == "cifar10" else 0 if args.aug_level == 1 else 36, # 0.4*90
random_s = 0 if args.data_type == "cifar10" else 0 if args.aug_level == 1 else 50, # 0.4*127
random_l = 0 if args.data_type == "cifar10" else 0 if args.aug_level == 1 else 50, # 0.4*127
max_rotate_angle = 0 if args.aug_level <= 2 else 10,
max_shear_ratio = 0 if args.aug_level <= 2 else 0.1,
rand_mirror = True,
shuffle = True,
num_parts = kv.num_workers,
part_index = kv.rank)
val = mx.io.ImageRecordIter(
path_imgrec = os.path.join(args.data_dir, "cifar10_val.rec") if args.data_type == 'cifar10' else
os.path.join(args.data_dir, "val_256_q90.rec"),
label_width = 1,
data_name = 'data',
label_name = 'softmax_label',
batch_size = args.batch_size,
data_shape = (3, 32, 32) if args.data_type=="cifar10" else (3, 128, 128),
rand_crop = False,
rand_mirror = False,
num_parts = kv.num_workers,
part_index = kv.rank)
model = mx.model.FeedForward(
ctx = devs,
symbol = symbol,
arg_params = arg_params,
aux_params = aux_params,
num_epoch = 200 if args.data_type == "cifar10" else 120,
begin_epoch = begin_epoch,
learning_rate = args.lr,
momentum = args.mom,
wd = args.wd,
optimizer = 'nag',
# optimizer = 'sgd',
initializer = mx.init.Xavier(rnd_type='gaussian', factor_type="in", magnitude=2),
lr_scheduler = multi_factor_scheduler(begin_epoch, epoch_size, step=[120, 160], factor=0.1)
if args.data_type=='cifar10' else
multi_factor_scheduler(begin_epoch, epoch_size, step=[30, 60, 90], factor=0.1),
)
model.fit(
X = train,
eval_data = val,
eval_metric = ['acc', 'ce'] if args.data_type=='cifar10' else
['acc','ce', mx.metric.create('top_k_accuracy', top_k = 5)],
kvstore = kv,
batch_end_callback = mx.callback.Speedometer(args.batch_size, args.frequent),
epoch_end_callback = checkpoint)
# logging.info("top-1 and top-5 acc is {}".format(model.score(X = val,
# eval_metric = ['acc', mx.metric.create('top_k_accuracy', top_k = 5)]))) if __name__ == "__main__":
parser = argparse.ArgumentParser(description="command for training resnet-v2")
parser.add_argument('--gpus', type=str, default='', help='the gpus will be used, e.g "0,1,2,3"')
parser.add_argument('--data-dir', type=str, default='./data/imagenet/', help='the input data directory')
parser.add_argument('--data-type', type=str, default='imagenet', help='the dataset type')
parser.add_argument('--list-dir', type=str, default='./',
help='the directory which contain the training list file')
parser.add_argument('--lr', type=float, default=0.1, help='initialization learning reate')
parser.add_argument('--mom', type=float, default=0.9, help='momentum for sgd')
parser.add_argument('--bn-mom', type=float, default=0.9, help='momentum for batch normlization')
parser.add_argument('--wd', type=float, default=0.0001, help='weight decay for sgd')
parser.add_argument('--batch-size', type=int, default=256, help='the batch size')
parser.add_argument('--workspace', type=int, default=512, help='memory space size(MB) used in convolution, if xpu '
' memory is oom, then you can try smaller vale, such as --workspace 256')
parser.add_argument('--depth', type=int, default=50, help='the depth of resnet')
parser.add_argument('--num-classes', type=int, default=1000, help='the class number of your task')
parser.add_argument('--aug-level', type=int, default=2, choices=[1, 2, 3],
help='level 1: use only random crop and random mirror\n'
'level 2: add scale/aspect/hsv augmentation based on level 1\n'
'level 3: add rotation/shear augmentation based on level 2')
parser.add_argument('--num-examples', type=int, default=1281167, help='the number of training examples')
parser.add_argument('--kv-store', type=str, default='device', help='the kvstore type')
parser.add_argument('--model-load-epoch', type=int, default=0,
help='load the model on an epoch using the model-load-prefix')
parser.add_argument('--frequent', type=int, default=50, help='frequency of logging')
parser.add_argument('--memonger', action='store_true', default=False,
help='true means using memonger to save momory, https://github.com/dmlc/mxnet-memonger')
parser.add_argument('--retrain', action='store_true', default=False, help='true means continue training')
args = parser.parse_args()
logging.info(args)
main()
为减小网络大小,将图片全部缩放为128*128大小,平时使用ResNet-50的网络,将num_classes 改为需要的分类数目。
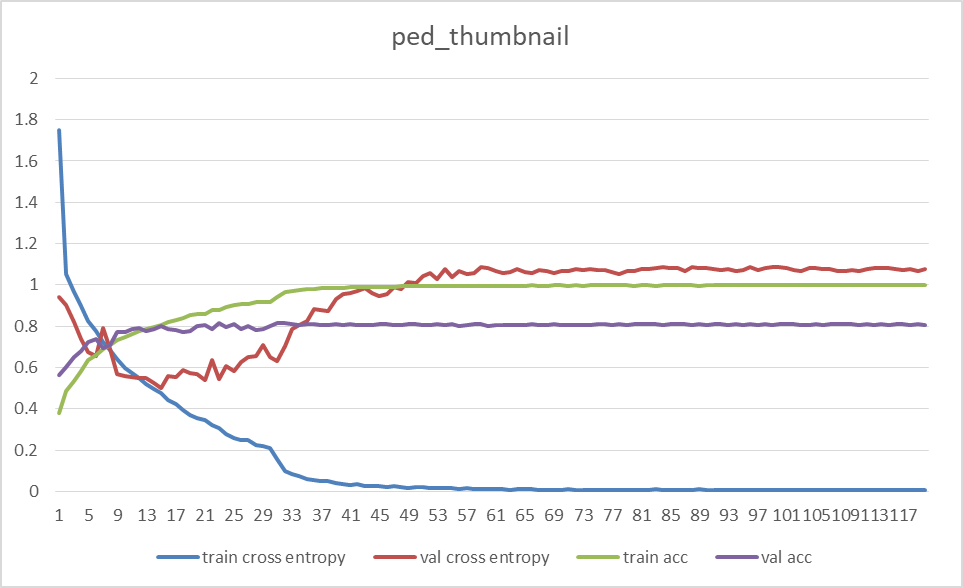
train acc可以在99.9%水平,val acc 稳定在80%左右
预测模块
import numpy as np
import cv2
import mxnet as mx
import argparse def ch_dev(arg_params, aux_params, ctx):
new_args = dict()
new_auxs = dict()
for k, v in arg_params.items():
new_args[k] = v.as_in_context(ctx)
for k, v in aux_params.items():
new_auxs[k] = v.as_in_context(ctx)
return new_args, new_auxs def predict(img):
# compute the predict probabilities
mod.forward(Batch([img]))
prob = mod.get_outputs()[0].asnumpy()
# print the top-5
prob = np.squeeze(prob)
a = np.argsort(prob)[::-1]
for i in a[0:3]:
print('probability=%f, class=%s' %(prob[i], labels[i])) def main():
synset = [l.strip() for l in open(args.synset).readlines()]
# 添加预测
ctx = mx.gpu(args.gpu)
sym, arg_params, aux_params = mx.model.load_checkpoint(args.prefix, args.epoch)
mod = mx.mod.Module(symbol=sym, context=ctx, label_names=None)
mod.bind(for_training=False, data_shapes=[('data', (1,3,128,128))],label_shapes=mod._label_shapes)
mod.set_params(arg_params, aux_params, allow_missing=True) from collections import namedtuple
Batch = namedtuple('Batch', ['data']) if args.lst:
file = open('instances_test.lst')
for line in file:
src = ""
for i in range(len(line)-1,0,-1):
if line[i] == '\t':
break
src += line[i]
src = src[::-1]
src = "/mnt/hdfs-data-4/data/jian.yin/ped_thumbnail/instances_test/" + src
print(src[0:-1]) # convert into format (batch, RGB, width, height)
img = mx.image.imdecode(open(src[0:-1],'rb').read())
img = mx.image.imresize(img, 128, 128) # resize
img = img.transpose((2, 0, 1)) # Channel first
img = img.expand_dims(axis=0) # batchify
img = img.astype('float32') # for gpu context mod.forward(Batch([img]))
prob = mod.get_outputs()[0].asnumpy()
# print the top-3
prob = np.squeeze(prob)
a = np.argsort(prob)[::-1]
for i in a[0:3]:
print('probability=%f, class=%s' %(prob[i], synset[i])) # img = cv2.cvtColor(cv2.imread(src[0:-1]), cv2.COLOR_BGR2RGB)
# img = cv2.resize(img, (128, 128)) # resize to 224*224 to fit model
# img = np.swapaxes(img, 0, 2)
# img = np.swapaxes(img, 1, 2) # change to (c, h,w) order
# img = img[np.newaxis, :] # extend to (n, c, h, w) # ctx = mx.gpu(args.gpu)
# sym, arg_params, aux_params = mx.model.load_checkpoint(args.prefix, args.epoch)
# arg_params, aux_params = ch_dev(arg_params, aux_params, ctx)
# arg_params["data"] = mx.nd.array(img, ctx)
# arg_params["softmax_label"] = mx.nd.empty((1,), ctx)
# exe = sym.bind(ctx, arg_params ,args_grad=None, grad_req="null", aux_states=aux_params)
# exe.forward(is_train=False) # prob = np.squeeze(exe.outputs[0].asnumpy())
# pred = np.argsort(prob)[::-1]
# print("Top1 result is: ", synset[pred[0]])
# # print("Top5 result is: ", [synset[pred[i]] for i in range(5)])
file.close() if __name__ == "__main__":
parser = argparse.ArgumentParser(description="use pre-trainned resnet model to classify one image")
parser.add_argument('--img', type=str, default='test.jpg', help='input image for classification')
# add --lst
parser.add_argument('--lst',type=str,default='test.lst',help="input image's lst for classification")
parser.add_argument('--gpu', type=int, default=0, help='the gpu id used for predict')
parser.add_argument('--synset', type=str, default='synset.txt', help='file mapping class id to class name')
parser.add_argument('--prefix', type=str, default='resnet-50', help='the prefix of the pre-trained model')
parser.add_argument('--epoch', type=int, default=0, help='the epoch of the pre-trained model')
args = parser.parse_args()
main()
添加了--lst可选参数,可以批处理序列化文件预测。
原文预测模块效率较低,改用mxnet标准的predict写法:https://mxnet.incubator.apache.org/tutorials/python/predict_image.html
添加一个脚本,防止忘记一些参数的写法:
#!/usr/bin/
python -u predict.py --lst instances_test.lst --prefix resnet-50 --synset ped_thumbnail.txt --gpu 0
记得运行的时候添加管道命令 >
/mnt/1/385_328_428_402_6.jpg
probability=0.994927, class=1 Cyclist
probability=0.003335, class=2 Others
probability=0.001739, class=0 Pedestrian
/mnt2/439_359_481_428_0.jpg
probability=0.994793, class=2 Others
probability=0.002817, class=0 Pedestrian
probability=0.002390, class=1 Cyclist
/mnt/2/619_337_658_401_16.jpg
probability=0.992218, class=2 Others
probability=0.007275, class=1 Cyclist
probability=0.000507, class=0 Pedestrian
/mnt1/511_288_561_385_1.jpg
probability=0.997837, class=1 Cyclist
probability=0.001525, class=0 Pedestrian
probability=0.000638, class=2 Others
分析预测结果
可以先把各种分类的路径记录下来。
import itertools
import numpy as np
import matplotlib.pyplot as plt from sklearn import svm, datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix file = open('myPredict.txt') cnt = 0 true = []
pred = [] for line in file:
if cnt%4 == 0:
pos =-1
for i in range(len(line)-1,-1,-1):
if line[i]=='/':
pos = i - 1
break
true.append(int(line[pos]))
if cnt%4 == 1:
pos = -1
for i in range(len(line)-1,-1,-1):
if line[i] == ' ':
pos = i - 1
break
pred.append(int(line[pos]))
cnt+=1 print(true)
print(pred)
print(confusion_matrix(true,pred)) file.close() zero_zero = []
zero_one = []
zero_two = []
one_zero = []
one_one = []
one_two = []
two_zero = []
two_one = []
two_two = [] cnt = 0
pos = 0
file = open('myPredict.txt') for line in file:
if cnt%4==0:
if true[pos] == 0 and pred[pos] == 0:
zero_zero.append(line)
if true[pos] == 0 and pred[pos] == 1:
zero_one.append(line)
if true[pos] == 0 and pred[pos] == 2:
zero_two.append(line)
if true[pos] == 1 and pred[pos] == 0:
one_zero.append(line)
if true[pos] == 1 and pred[pos] == 1:
one_one.append(line)
if true[pos] == 1 and pred[pos] == 2:
one_two.append(line)
if true[pos] == 2 and pred[pos] == 0:
two_zero.append(line)
if true[pos] == 2 and pred[pos] == 1:
two_one.append(line)
if true[pos] == 2 and pred[pos] == 2:
two_two.append(line)
pos+=1
cnt+=1
file.close() print(len(zero_one)+len(zero_two)+len(one_zero)+len(one_two)+len(two_zero)+len(two_one)) # 0 - 0
write_zero_zero = open('zero_zero.txt','w')
for i in range(len(zero_zero)):
write_zero_zero.write(zero_zero[i])
write_zero_zero.close() # 0 - 1
write_zero_one = open('zero_one.txt','w')
for i in range(len(zero_one)):
write_zero_one.write(zero_one[i])
write_zero_one.close() # 0 - 2
write_zero_two = open('zero_two.txt','w')
for i in range(len(zero_two)):
write_zero_two.write(zero_two[i])
write_zero_two.close() # 1 - 0
write_one_zero = open('one_zero.txt','w')
for i in range(len(one_zero)):
write_one_zero.write(one_zero[i])
write_one_zero.close() # 1 - 1
write_one_one = open('one_one.txt','w')
for i in range(len(one_one)):
write_one_one.write(one_one[i])
write_one_one.close() # 1 - 2
write_one_two = open('one_two.txt','w')
for i in range(len(one_two)):
write_one_two.write(one_two[i])
write_one_two.close() # 2 - 0
write_two_zero = open('two_zero.txt','w')
for i in range(len(two_zero)):
write_two_zero.write(two_zero[i])
write_two_zero.close() # 2 - 1
write_two_one = open('two_one.txt','w')
for i in range(len(two_one)):
write_two_one.write(two_one[i])
write_two_one.close() # 2 - 2
write_two_two = open('two_two.txt','w')
for i in range(len(two_two)):
write_two_two.write(two_two[i])
write_two_two.close()
混淆矩阵如下:

ResNet 修改的更多相关文章
- "Regressing Robust and Discriminative 3D Morphable Models with a very Deep Neural Network" 解读
简介:这是一篇17年的CVPR,作者提出使用现有的人脸识别深度神经网络Resnet101来得到一个具有鲁棒性的人脸模型. 原文链接:https://www.researchgate.net/publi ...
- Pytorch修改ResNet模型全连接层进行直接训练
之前在用预训练的ResNet的模型进行迁移训练时,是固定除最后一层的前面层权重,然后把全连接层输出改为自己需要的数目,进行最后一层的训练,那么现在假如想要只是把 最后一层的输出改一下,不需要加载前面层 ...
- 残差网络resnet学习
Deep Residual Learning for Image Recognition 微软亚洲研究院的何凯明等人 论文地址 https://arxiv.org/pdf/1512.03385v1.p ...
- 深度学习——卷积神经网络 的经典网络(LeNet-5、AlexNet、ZFNet、VGG-16、GoogLeNet、ResNet)
一.CNN卷积神经网络的经典网络综述 下面图片参照博客:http://blog.csdn.net/cyh_24/article/details/51440344 二.LeNet-5网络 输入尺寸:32 ...
- Resnet论文翻译
摘要 越深层次的神经网络越难以训练.我们提供了一个残差学习框架,以减轻对网络的训练,这些网络的深度比以前的要大得多.我们明确地将这些层重新规划为通过参考输入层x,学习残差函数,来代替没有参考的学习函数 ...
- Pytorch1.0入门实战二:LeNet、AleNet、VGG、GoogLeNet、ResNet模型详解
LeNet 1998年,LeCun提出了第一个真正的卷积神经网络,也是整个神经网络的开山之作,称为LeNet,现在主要指的是LeNet5或LeNet-5,如图1.1所示.它的主要特征是将卷积层和下采样 ...
- Feature Extractor[ResNet]
0. 背景 众所周知,深度学习,要的就是深度,VGG主要的工作贡献就是基于小卷积核的基础上,去探寻网络深度对结果的影响.而何恺明大神等人发现,不是随着网络深度增加,效果就好的,他们发现了一个违背直觉的 ...
- Feature Extractor[ResNet v2]
0. 背景 何凯明大神等人在提出了ResNet网络结构之后,对其做了进一步的分析工作,详细的分析了ResNet 构建块能起作用的本质所在.并通过一系列的实验来验证恒等映射的重要性,并由此提出了新的构建 ...
- 学习笔记TF033:实现ResNet
ResNet(Residual Neural Network),微软研究院 Kaiming He等4名华人提出.通过Residual Unit训练152层深神经网络,ILSVRC 2015比赛冠军,3 ...
随机推荐
- JMS - ActiveMQ集成Spring
下面是ActiveMQ官网提供的文档.http://activemq.apache.org/spring-support.html 下面是我添加的一些dependency: <!-- jms a ...
- 十三、nginx 强制下载txt等文件
当前的浏览器能够识别文件格式,如果浏览器本身能够解析就会默认打开,如果不能解析就会下载该文件. 那么使用nginx做资源服务器的时候,如何强制下载文件呢? location /back/upload/ ...
- C Primer Plus(第六版)中文版 中的错误1
#include<stdio.h> #include<stdlib.h> #include<string.h> #define TSIZE 45 struct fi ...
- 多实例部署多个tomcat
注意点: 1.多实例tomcat的更新维护,需要考虑如何能“优雅”地对所有实例进行升级: 2.尽量不要影响应用程序,在更新tomcat时,一不小心就把conf目录等全部覆盖,所以尽量要把配置文件和安装 ...
- laravel验证规则
就拿laravel的登入验证来举例: 1.进入login控制器, use AuthenticatesUsers;从这里点进去找到验证规则 //验证protected function validate ...
- flask-login2的简单使用
#coding:utf8 from flask import Flask, render_template, request, redirect, url_for, flash, abort from ...
- 移动web中的幻灯片切换效果
百度或者谷歌下类似的插件有很多,原理都差不多,关键适合自己的项目,如果移动端要引入jquery这么大的插件,只能呵呵了.... 下面是工作中针对webkit内核的浏览器写的,html很简单: < ...
- package.json中版本理解
一个完整的版本号可以理解为: [主要版本号,次要版本号,补丁版本号]版本号 x.y.z :其中z 表示一些小的bugfix, y表示一些大的版本更改,比如一些API的变化x表示一些设计的变动及模块的重 ...
- 表单校验常用原生js库
1.字符串去除左右空格继承形式// 除去左右空格String.prototype.Trim = function() { return this.replace(/(^\s*)|(\s*$)/g, & ...
- easyui numberbox输入框 编辑不可编辑的切换
背景:申请单里需要选费用类型,费用类型有的有子明细项,有个合计项 当有子明细项的时候,合计项的值是通过弹出的子明细项价格的总和(设置为可编辑没问题,因为点击出来弹框,编辑不了) 没有子明细 ...