【机器学习笔记】循环神经网络RNN
1. 从一个栗子开始 - Slot Filling
比如在一个订票系统上,我们的输入 “Arrive Taipei on November 2nd” 这样一个序列,我们设置几个槽位(Slot),希望算法能够将关键词'Taipei'放入目的地(Destination)槽位, 将November和2nd放入到达时间(Time of Arrival)槽位,将Arrive和on放入其他(Other)槽位,实现对输入序列的一个归类,以便后续提取相应信息。
用前馈神经网络(Feedforward Neural Network)来解决这个问题的话,我们首先要对输入序列向量化,将每一个输入的单词用向量表示,可以使用 One-of-N Encoding 或者是 Word hashing 等编码方法,输出预测槽位的概率分布。
但是这样做的话,有个问题就出现了。如果现在又有一个输入是 “Leave Taipei on November 2nd”,这里Taipei是作为一个出发地(Place of Departure),所以我们应当是把Taipei放入Departure槽位而不是Destination 槽位,可是对于前馈网络来说,对于同一个输入,输出的概率分布应该也是一样的,不可能出现既是Destination的概率最高又是Departure的概率最高。
所以我们就希望能够让神经网络拥有“记忆”的能力,能够根据之前的信息(在这个例子中是Arrive或Leave)从而得到不同的输出。将两段序列中的Taipei分别归入Destionation槽位和Departure槽位。
2. RNN
基本概念
在RNN中,隐层神经元的输出值都被保存到记忆单元中,下一次再计算输出时,隐层神经元会将记忆单元中的值认为是输入的一部分来考虑
RNN中考虑了输入序列顺序,序列顺序的改变会影响输出的结果。
常见变体
- Elman Network
将隐层的输出(即记忆单元中的值)作为下一次的输入
\(h_t = \sigma_h(W_hx_t + U_h\color{green}{h_{t-1}} + b_h)\)
\(y_t = \sigma_h(W_yh_t + b_y)\)
- Jordan Network
将上一时间点的输出值作为输入
\(h_t = \sigma_h(W_hx_t + U_h\color{green}{y_{t-1}} + b_h)\)
\(y_t = \sigma_h(W_yh_t + b_y)\)
- Bidirectional RNN
- Elman Network
3. Long Short-term Memory (LSTM)
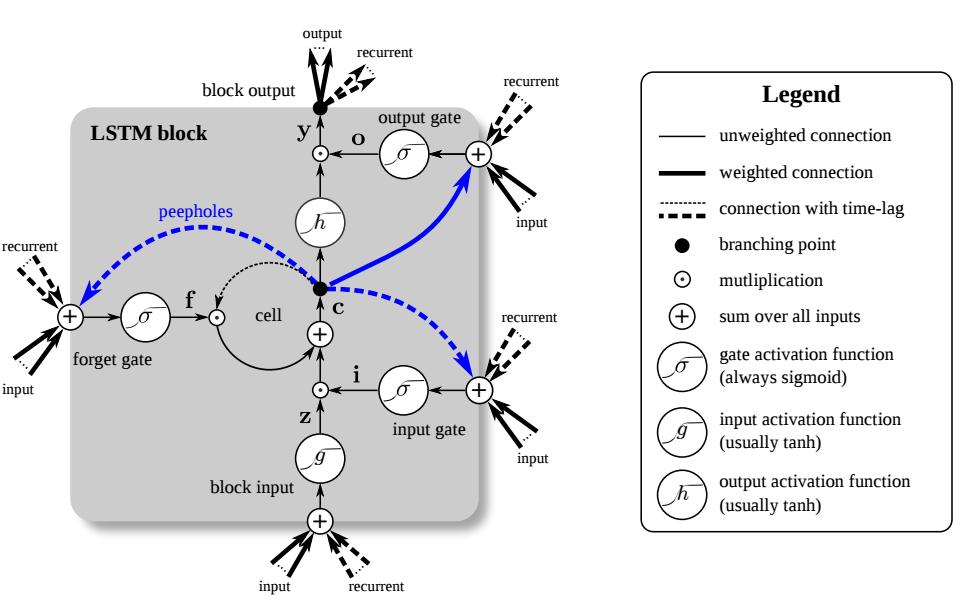
- 基本结构
- 由Memory Cell, Input Gate, Output Gate, Forget Gate 组成
- 特殊的神经元结构,包含4个input(三个Gate的控制信号以及输入的数据),1个output
- 激活函数通常选用sigmoid function, sigmoid的输出介于0到1之间,表征了Gate的打开程度。
Traditional LSTM
\[
\begin{align}
f_t & = \sigma_g(W_fx_t + \color{green}{U_fh_{t-1}} + b_f) \\
i_t & = \sigma_g(W_i x_t + \color{green}{U_ih_{t-1}} + b_i) \\
o_t & = \sigma_g(W_o x_t + \color{green}{U_oh_{t-1}} + b_o) \\
c_t & = f_t\,{\circ}\,c_{t-1} + i_t\,{\circ}\,\sigma_c(W_cx_t\color{green}{+ U_ch_{t-1}} +b_c) \\
h_t & = o_t \,{\circ}\, \sigma_h(c_t)
\end{align}
\]Peephole LSTM, 在大部分的情况下,用\(\color{blue}{c_{t-1}}\)取代\(\color{green}{h_{t-1}}\)
\[
\begin{align}
f_t & = \sigma_g(W_fx_t + \color{green}{U_f\color{blue}{c_{t-1}}} + b_f) \\
i_t & = \sigma_g(W_i x_t + \color{green}{U_i\color{blue}{c_{t-1}}} + b_i) \\
o_t & = \sigma_g(W_o x_t + \color{green}{U_o\color{blue}{c_{t-1}}} + b_o) \\
c_t & = f_t\,{\circ}\,c_{t-1} + i_t\,{\circ}\,\sigma_c(W_cx_t +b_c) \\
h_t & = o_t \,{\circ}\, \sigma_h(c_t)
\end{align}
\]- \(x_t\)表示输入向量,\(h_t\)表示输出向量,\(c_t\)表示记忆单元的状态向量,\(\circ\)代表Hadamard product(A.k.a. Schur product)
- \(W\)表示输入权重,\(U\)表示循环权重,\(b\)表示偏置
- \(\delta_g\)代表sigmoid function,\(\delta_c\)代表hyperbolic tangent, \(\delta_h\)表示 hyperbolic tangent(peephole LSTM论文中建议选用\(\delta_h(x)=x\))
- \(f_t\),\(i_t\)和\(o_t\)表示门控向量值
- \(f_t\)表示遗忘门向量,表征记忆旧信息的能力
- \(i_t\)表示输入门向量,表征获取新信息的能力
- \(o_t\)表示输出门向量,表征输出信息的能力
- 补充知识点
- Short-term,表示保留对前一时间点输出的短期记忆,相比于最原始的RNN结构中的记忆单元(每次有新的输入时记忆体的状态就会被更新,因此是短期的记忆),而LSTM的记忆体则拥有相对较长的记忆时间(由Forget Gate决定),所以是Long Short-term
- LSTM一般采用多层结构组合,Multiple-layer LSTM
- Keras中实现了LSTM,GRU([Cho,Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation,EMNLP'14] 只有两个Gate,容易训练),SimpleRNN层,可以方便的调用。
4. RNN如何学习?
- 损失函数的定义:
- 每一个时间点的RNN的输出和标签值的交叉熵(cross-entropy)之和
- 训练过程:
- 使用被称作Backpropagation through time(BPTT)的梯度下降法
- 训练其实是比较困难的,因为Total Loss可能会出现剧烈的抖动
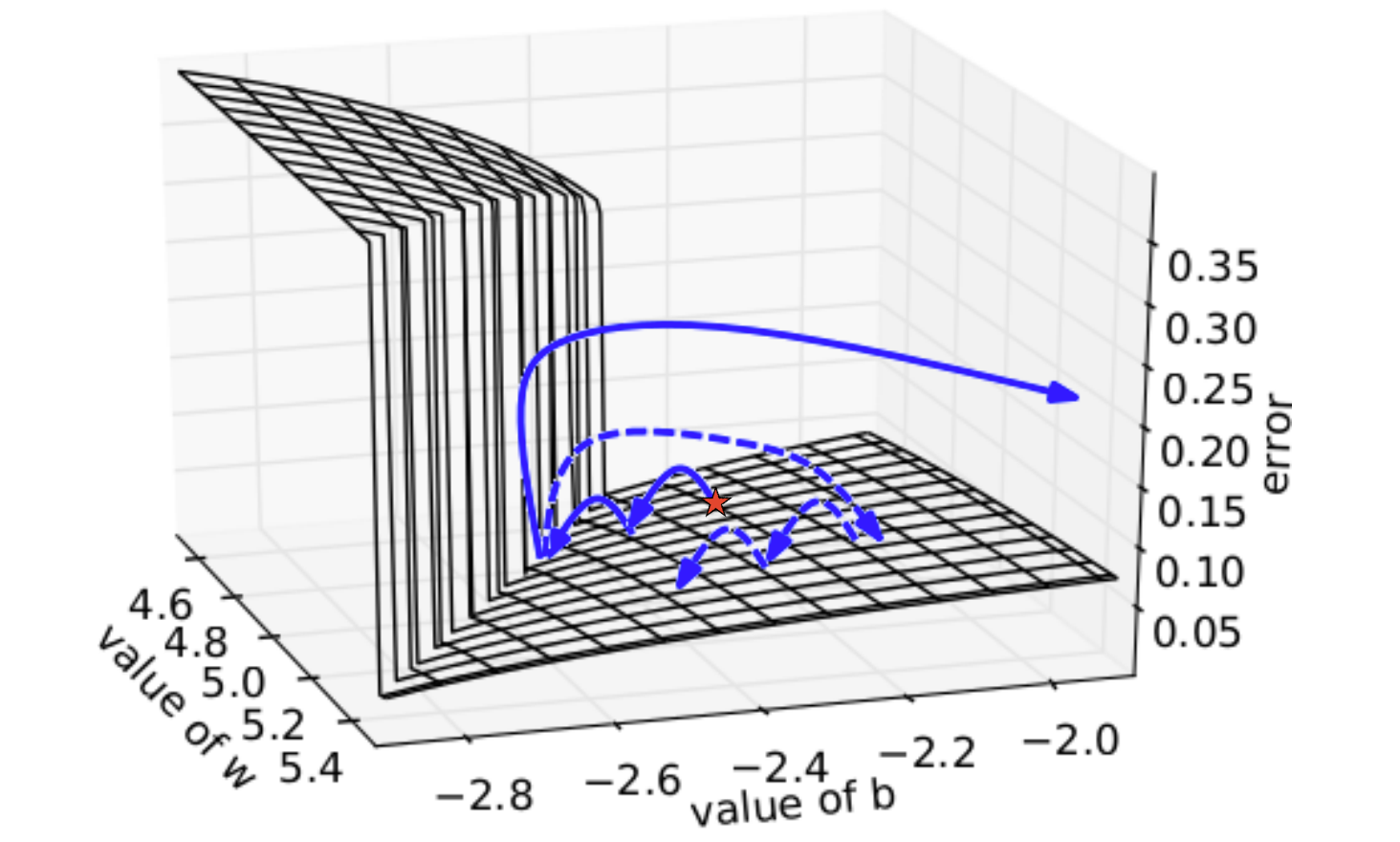
- 根据论文[Razvan Pascanu,On the difficulty of training Recurrent Neural Networks,ICML'13]上对RNN的分析,损失函数的表面要么非常平坦,要么非常陡峭(The error surface is either very flat or very steep),当你的参数值在较为平坦的区域做更新时,因此该区域梯度值比较小,此时的学习率一般会变得的较大,如果突然到达了陡峭的区域,梯度值陡增,再与此时较大的学习率相乘,参数就有很大幅度更新(实线表示的轨迹),因此学习过程非常不稳定。Razvan Pascanu使用了叫做“Clipping”的训练技巧:为梯度设置阈值,超过该阈值的梯度值都会被cut,这样参数更新的幅度就不会过大(虚线表示的轨迹),因此容易收敛。
- 为什么在RNN中会有这种问题?
- 是因为激活函数选用了sigmoid而不是ReLU么?然而并不是。事实上,在RNN中使用ReLU反而效果会不如Sigmoid,不过也是看你的参数初始化值的选取,所以也不一定,比如后面提到的Quoc V.Le的那篇文章,使用特别初始化技巧硬训ReLU的RNN得到了可比拟LSTM的效果。因此激活函数并不是这里的关键点。
- 那究竟是什么原因呢?我们来分析梯度更新公式中的\(w-\eta\frac{\partial{L}}{\partial{w}}\)来探寻一番。但是这样一个偏微分的关系我们应该如何来分析呢?这里我们用一个技巧:给w值一个微小的变化,观察对应的Loss的变化情况。假设当前模型是1000个只含有一个线性隐层的RNN级联结构。并假设我们当前的输入是100000……(只有第一个值是1,剩下全是0),因此最后的输出值是\(w^{999}\)。现在假设我们\(w\)的值是1,那么RNN在最后时间点的输出是1,给\(w\)一个微小的变化+0.01,此时的输出变成了大约20000!这段区域呈现出一个陡峭的趋势。如果给\(w\)一个微小的变化-0.01变为0.99,测试的输出基本变成0,哪怕是\(w\)变到0.01时,输出依旧是0,这段区域呈现出一个平坦的趋势。因此我们可以看出由于RNN采用时间序列的结构,权重值在不同时间点被反复使用,这种累积性的变化可能对结果造成极大的影响,也可能会很长一段时间保持平稳。
- 常用的技巧
- 使用LSTM单元。LSTM单元可以处理梯度消失问题,但无法处理梯度爆炸问题。为什么呢?这是因为RNN和LSTM对待记忆单元的做法是不同的,RNN中每一个时间点的记忆单元中的内容(状态)都会更新,而LSTM则是将记忆单元中的值与输入值相加(按某种权值)再更新状态,记忆单元中的值会始终对输出产生影响(除非Forget Gate完全的关闭),因此不用担心梯度值会弥散,相反的,这倒极易引起梯度爆炸。
- 采用一些更新颖的结构或训练方法,比如:
- Clockwise RNN [Jan Koutnik,A Clockwork RNN,JMLR'14]
- Structurally Constrained Recurrent Network(SCRN)[Tomas Mikolov,Learning Longer Memory in Recurrent Neural Networks,ICLR'15]
- Vanilla RNN Initialized with Identity matrix + ReLU activation function [Quoc V.Le,A Simple Way to Initialize Recurrent Networks of Rectified Linear Units,arXiv'15]该位仁兄用了特别的初始化技巧,硬训RNN,效果可比拟甚至超越LSTM
5. RNN的更多应用场景
- Sentiment Analysis 情感分析
- Key Term Extraction 关键字提取
- Speech Recognition 语音辨识
- Connectionist Temporal Classification(CTC):语音辨识中的一个关键技术,通过增加一个额外的Symbol代表NULL来解决叠字问题(参考论文[Graves, Alex, and Navdeep Jaitly. "Towards end-to-end speech recognition with recurrent neural networks." Proceedings of the 31st International Conference on Machine Learning (ICML-14). 2014.])。
- Sequence to sequence learning(输入和输出都是不同长度的序列)
- Machine Translation 机器翻译
- Syntactic parsing 句法分析
- Seq-to-seq Auto-encoder
- 将文档转换为向量表示(BoW模型会忽略掉语序,在某些情况下相反意思的语句会产生相同的词袋模型,而RNN的方法考虑语序,因此更为鲁棒)
- 将语音转换为向量表示
- Attention-based Model 注意力模型
- Neural Turing Machine 神经图灵机
- Reading Comprehension
- 问答系统
6. 其他的学习资料
- The Unreasonable Effectiveness of Recurrent Neural Networks
- Understanding LSTM Networks
7. 本文参考资料
- Machine Learning (2016,Fall), Hung-yi Lee, NTU
- Deep Learning, Ian Goodfellow and Yoshua Bengio and Aaron Courville
- Deep Learning in a Nutshell: Sequence Learning
- Long short-term memory
Deep & Structured 未完待续
【机器学习笔记】循环神经网络RNN的更多相关文章
- 用纯Python实现循环神经网络RNN向前传播过程(吴恩达DeepLearning.ai作业)
Google TensorFlow程序员点赞的文章! 前言 目录: - 向量表示以及它的维度 - rnn cell - rnn 向前传播 重点关注: - 如何把数据向量化的,它们的维度是怎么来的 ...
- 循环神经网络(RNN, Recurrent Neural Networks)介绍(转载)
循环神经网络(RNN, Recurrent Neural Networks)介绍 这篇文章很多内容是参考:http://www.wildml.com/2015/09/recurrent-neur ...
- 通过keras例子理解LSTM 循环神经网络(RNN)
博文的翻译和实践: Understanding Stateful LSTM Recurrent Neural Networks in Python with Keras 正文 一个强大而流行的循环神经 ...
- 循环神经网络RNN及LSTM
一.循环神经网络RNN RNN综述 https://juejin.im/entry/5b97e36cf265da0aa81be239 RNN中为什么要采用tanh而不是ReLu作为激活函数? htt ...
- 深度学习之循环神经网络RNN概述,双向LSTM实现字符识别
深度学习之循环神经网络RNN概述,双向LSTM实现字符识别 2. RNN概述 Recurrent Neural Network - 循环神经网络,最早出现在20世纪80年代,主要是用于时序数据的预测和 ...
- 循环神经网络RNN模型和长短时记忆系统LSTM
传统DNN或者CNN无法对时间序列上的变化进行建模,即当前的预测只跟当前的输入样本相关,无法建立在时间或者先后顺序上出现在当前样本之前或者之后的样本之间的联系.实际的很多场景中,样本出现的时间顺序非常 ...
- 从网络架构方面简析循环神经网络RNN
一.前言 1.1 诞生原因 在普通的前馈神经网络(如多层感知机MLP,卷积神经网络CNN)中,每次的输入都是独立的,即网络的输出依赖且仅依赖于当前输入,与过去一段时间内网络的输出无关.但是在现实生活中 ...
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
原文地址: http://blog.csdn.net/heyongluoyao8/article/details/48636251# 循环神经网络(RNN, Recurrent Neural Netw ...
- 《转》循环神经网络(RNN, Recurrent Neural Networks)学习笔记:基础理论
转自 http://blog.csdn.net/xingzhedai/article/details/53144126 更多参考:http://blog.csdn.net/mafeiyu80/arti ...
- 吴恩达deepLearning.ai循环神经网络RNN学习笔记_看图就懂了!!!(理论篇)
前言 目录: RNN提出的背景 - 一个问题 - 为什么不用标准神经网络 - RNN模型怎么解决这个问题 - RNN模型适用的数据特征 - RNN几种类型 RNN模型结构 - RNN block - ...
随机推荐
- java的串行化
参考博客:Java 对象的串行化(Serialization) 1,什么是串行化 对象的寿命通常随着生成该对象的程序的终止而终止.有时候,可能需要将对象的状态保存下来,在需要时再将对象恢复.我们把对象 ...
- 使用Fragment填充ViewPager
在上一篇文章中,讲解了使用PagerAdapter作为适配器时的ViewPager的使用方法.然后在实际项目中更多的使用Fragment作为页卡,因为实际开发中每一个页卡要复杂的多.而使用Fragme ...
- redis持久化那些事(kēng)儿
这是一篇包含了介绍性质和吐槽性质的日志.主要介绍一下我学习redis持久化时候被坑的经历.redis的使用介绍现在没有打算写,因为比较多,以我如此懒的性格...好吧,还是有点这方面想法的,不过一篇博客 ...
- FBKVOController代码阅读
功能:对kvo机制进行封装,简化使用,简化内存管理: 要素:观察者.被观察者.处理函数. 模式:注册表模式: 机制:对象创建.注册管理.内存管理.处理机制转换: 其它:注册去重: kvo的管理机制:
- CentOS 安装 dokuwiki
前期准备:yum 安装httpd和mysql 1.下载dokuwiki安装包 http://download.dokuwiki.org/: 2.centos系统中httpd的根目录为:/var/www ...
- BZOJ5293:[BJOI2018]求和(LCA,差分)
Description master 对树上的求和非常感兴趣.他生成了一棵有根树,并且希望多次询问这棵树上一段路径上所有节点深度的k 次方和,而且每次的k 可能是不同的.此处节点深度的定义是这个节点 ...
- 如何在jsp页面获取系统时间
<%@ page import="java.util.*"%> //获取系统时间必须导入的 <%@ page import="java.text.*&q ...
- java中exception和error有什么区别,运行时异常和一般异常有什么区别
1.exception和error都是继承了throwable类,在java中只有throwable类型的实例才可以被抛出(throw)或者捕获(catch),它是异常处理机制的基本组成类型 2.ex ...
- 手写redis客户端
一.RESP通信协议 Redis Serialization Protocol (Redis序列化协议). 特点:容易实现.解析快.可读性强 以\r\n分割数据. 二.撸代码 package com. ...
- oracle导出sequences
将某个用户的全部sequence查询出来,并拼成创建语句: select 'create sequence '||sequence_name|| ' minvalue '||min_value|| ' ...