【Spark】源码分析之RDD的生成及stage的切分
一、概述
Spark源码整体的逻辑(spark1.3.1):
从saveAsTextFile()方法入手
-->saveAsTextFile()
--> saveAsHadoopFile()
--> 封装hadoopConf,并传入saveAsHadoopDataset()方法
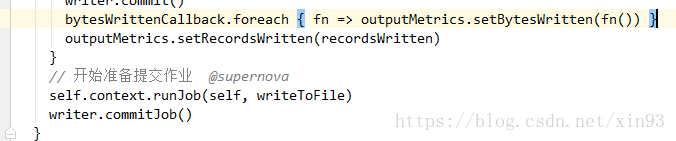
--> 拿到写出流SaprkHadoopWriter,调用self.context.runJob(self,writeToFile)
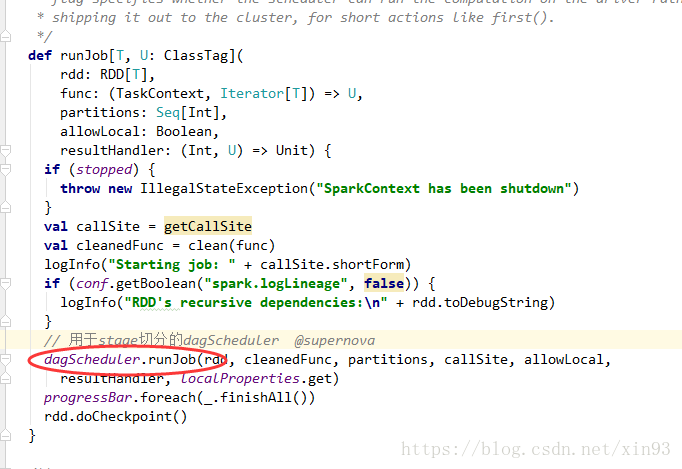
--> runJob方法中,使用dagScheduler划分stage
--> submitJob开始提交作业
-->任务处理器的post方法启动线程,获取队列中的任务,并调用onRecevie()方法提交任务
-->调用handleJobSubmitted,使用newStage中的getParentStage方法对stage进行切分
-->getParentStage方法中,使用HashSet、Stack来存放stage和RDD,用栈来存储RDD主要是为了便于后面通过循环进行模式匹配,判断该RDD和父RDD的依赖关系,如果是宽依赖就会生成stage,如果是窄依赖,就会继续找父RDD
二、Spark源码详情
1. 在spark1.3.1的源码中,saveAsTextFile的关键代码在于它内部调用了saveAsHadoopFile()方法。
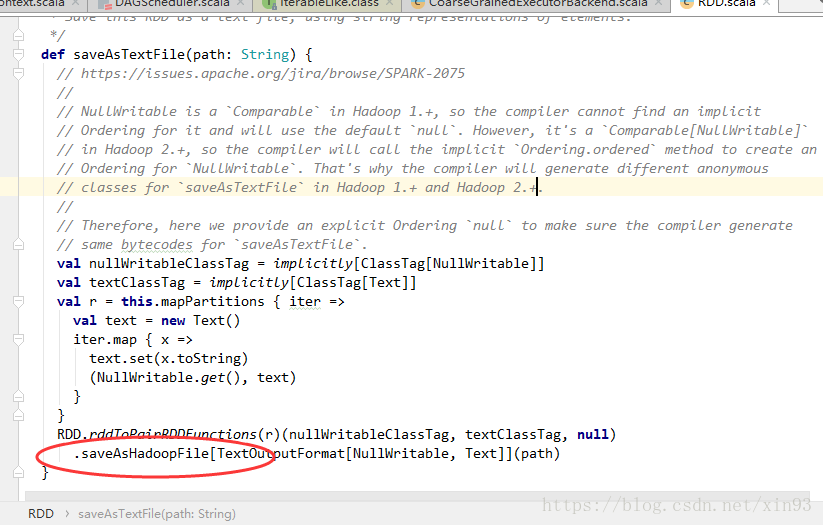
2. 进入到saveAsHadoopFile()方法中,首先spark会对配置信息进行封装,然后将配置信息传入saveAsHadoopDataset( )方法
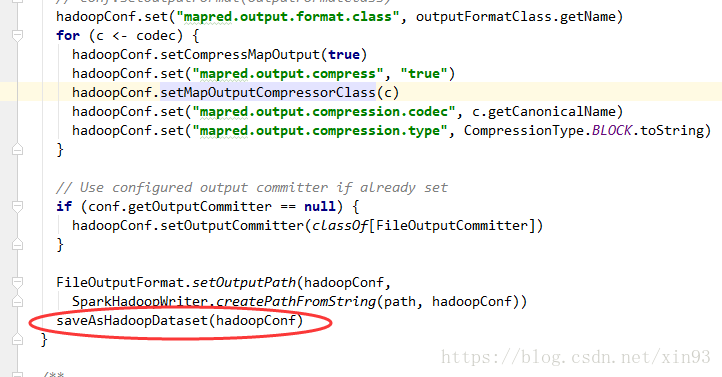
3. saveAsHadoopDataset()方法中将会拿到Spark的写出流,并调用runJob方法准备开始提交作业。

4. 进入runJob方法中,会使用dagScheduler进行stage的切分
5. submitJob开始提交作业

6. 获取finalRDD的分区数,并调用任务处理器的post方法,循环取出数据放入队列中
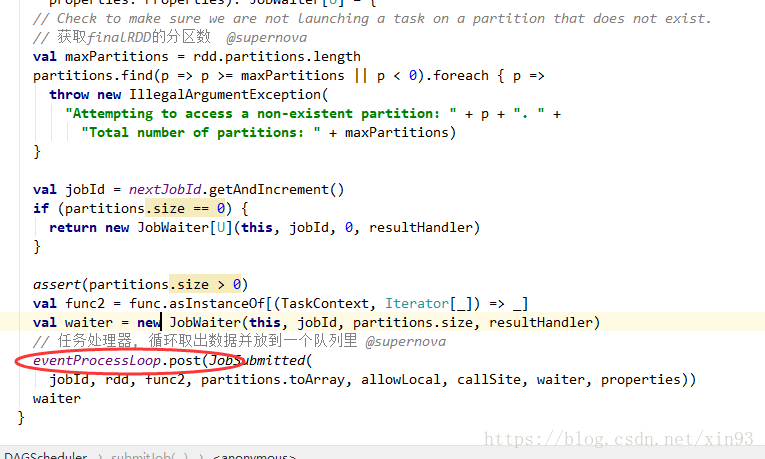
7. post方法中,将启动一个线程,将获取队列中的任务,并调用onRecevie()方法提交任务

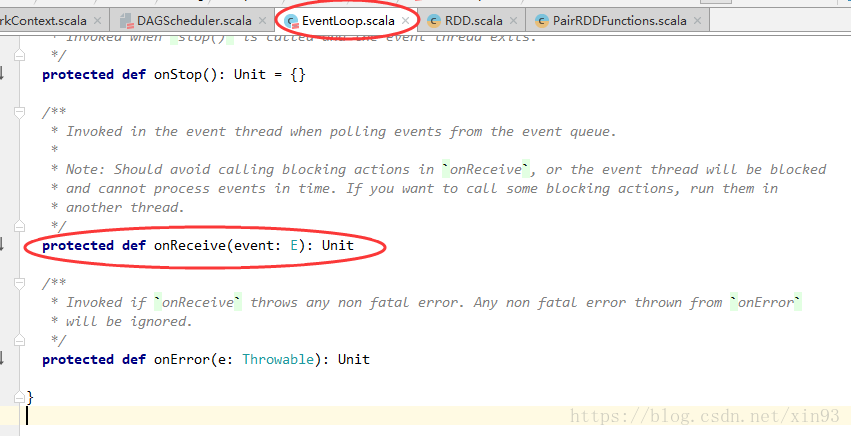
8. 进入onReceive(),可以看到它是一个抽象类中的方法
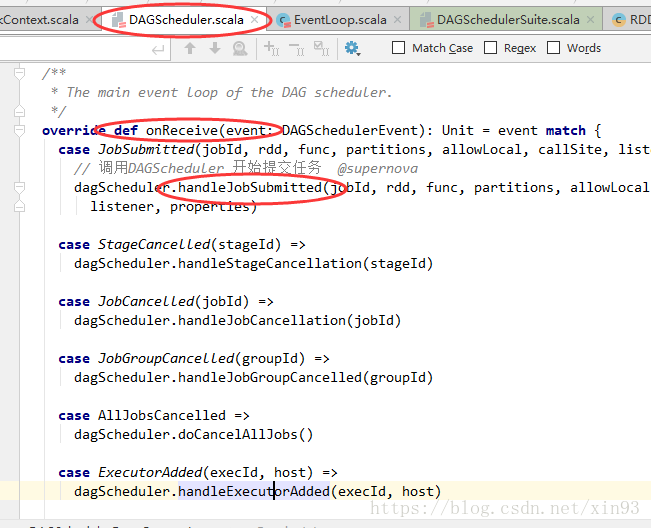
9. 方法的实现在DAGScheduler中,对方法进行模式匹配。 匹配到任务提交的方法后,调用handleJobSumitted提交任务
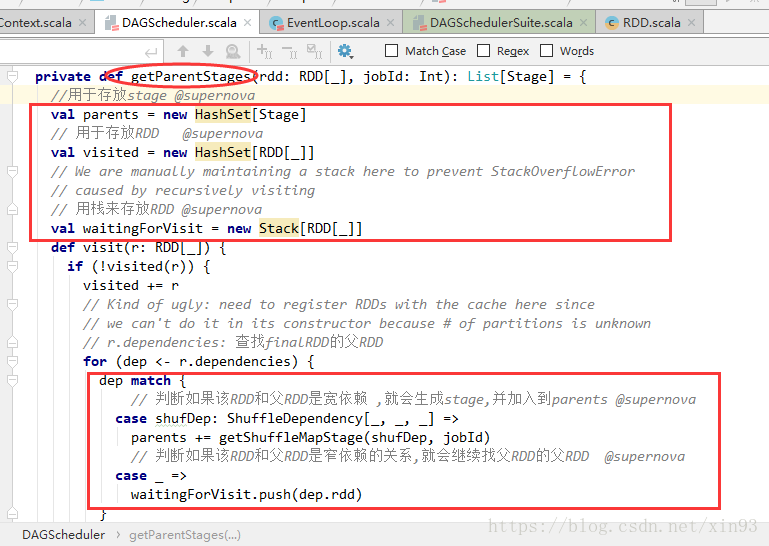
10. handleJobSubmitted中,使用newStage中的getParentStage方法对stage进行切分

11. getParentStage方法中,使用HashSet、Stack来存放stage和RDD,用栈来存储RDD主要是为了便于后面通过循环进行模式匹配,判断该RDD和父RDD的依赖关系,如果是宽依赖就会生成stage,如果是窄依赖,就会继续找父RDD
【Spark】源码分析之RDD的生成及stage的切分的更多相关文章
- spark 源码分析之一 -- RDD的四种依赖关系
RDD的四种依赖关系 RDD四种依赖关系,分别是 ShuffleDependency.PrunDependency.RangeDependency和OneToOneDependency四种依赖关系.如 ...
- spark 源码分析之十九 -- DAG的生成和Stage的划分
上篇文章 spark 源码分析之十八 -- Spark存储体系剖析 重点剖析了 Spark的存储体系.从本篇文章开始,剖析Spark作业的调度和计算体系. 在说DAG之前,先简单说一下RDD. 对RD ...
- Spark 源码分析系列
如下,是 spark 源码分析系列的一些文章汇总,持续更新中...... Spark RPC spark 源码分析之五--Spark RPC剖析之创建NettyRpcEnv spark 源码分析之六- ...
- spark源码分析以及优化
第一章.spark源码分析之RDD四种依赖关系 一.RDD四种依赖关系 RDD四种依赖关系,分别是 ShuffleDependency.PrunDependency.RangeDependency和O ...
- Spark源码分析 – DAGScheduler
DAGScheduler的架构其实非常简单, 1. eventQueue, 所有需要DAGScheduler处理的事情都需要往eventQueue中发送event 2. eventLoop Threa ...
- Spark源码分析:多种部署方式之间的区别与联系(转)
原文链接:Spark源码分析:多种部署方式之间的区别与联系(1) 从官方的文档我们可以知道,Spark的部署方式有很多种:local.Standalone.Mesos.YARN.....不同部署方式的 ...
- Spark源码分析 – Shuffle
参考详细探究Spark的shuffle实现, 写的很清楚, 当前设计的来龙去脉 Hadoop Hadoop的思路是, 在mapper端每次当memory buffer中的数据快满的时候, 先将memo ...
- Spark源码分析 – BlockManager
参考, Spark源码分析之-Storage模块 对于storage, 为何Spark需要storage模块?为了cache RDD Spark的特点就是可以将RDD cache在memory或dis ...
- Spark源码分析 – SparkContext
Spark源码分析之-scheduler模块 这位写的非常好, 让我对Spark的源码分析, 变的轻松了许多 这里自己再梳理一遍 先看一个简单的spark操作, val sc = new SparkC ...
随机推荐
- python numpy+mkl+scipy win64 安装
用pip在windows下安装numpy,scipy等库时一般来说都不会很顺利比较好的方式是自己下载对应的whl文件pip install 话不多说上链接 http://www.lfd.uci.edu ...
- Linux Mint 18.2安装后需要进行的设置
自己的笔记本电脑升级到win10后各种不好用,运行速度慢,开关机时间很长,系统也是经常性的更新,外加发热严重.更改设置和更换驱动都没能解决问题.另外感觉在Linux下能够更加专注,所以索性将主系统更换 ...
- 【Leetcode】【Medium】Search a 2D Matrix
Write an efficient algorithm that searches for a value in an m x n matrix. This matrix has the follo ...
- nginx 开启gzip压缩--字符串压缩比率很牛叉
刚刚给博客加了一个500px相册插件,lightbox引入了很多js文件和css文件,页面一下子看起来非常臃肿,所以还是把Gzip打开了. 环境:Debian 6 1.Vim打开Nginx配置文件 v ...
- php解决高并发设想
1.我突然想到一个解决系统并发的一个方法, 当然不算太友好, 就是并发时候,首先加载系统负载量文件, 如果到达一个值,比如60%,就跳到404页面,或者输出稍后之类的这样 2.静态文件和图片存到cdn ...
- JQuery里ajax的表单传值serialize()用法
本文导读:在jQuery中,当我们使用ajax时,常常需要拼装 input数据以键值对(Key/Value)的形式发送到服务器,用JQuery的serialize方法可以轻松的完成这个工作 ...
- July 24th 2017 Week 30th Monday
The only limit to our realization of tomorrow will be our doubts of today. 实现明天理想的唯一障碍就是今天的疑虑. When ...
- delegate 和 event
delegate 和 event 观察者模式 这里面综合了几本书的资料. 需求 有这么个项目: 需求是这样的: 一个气象站, 有三个传感器(温度, 湿度, 气压), 有一个WeatherData对象, ...
- Struts2.3.4.1 + Spring3.1.2 + Hibernate4.1.6整合
1. Jar包 2. web.xml配置 3. struts.xml配置 4. hibernate.cfg.xml配置 5. applicationContext.xml配置 6. log4j.pro ...
- springmvc常用注解标签详解(转载)
1.@Controller 在SpringMVC 中,控制器Controller 负责处理由DispatcherServlet 分发的请求,它把用户请求的数据经过业务处理层处理之后封装成一个Model ...