MapReduce最佳成绩统计,男生女生比比看
上一篇文章我们了解了MapReduce优化方面的知识,现在我们通过简单的项目,学会如何优化MapReduce性能
1、项目介绍
我们使用简单的成绩数据集,统计出0~20、20~50、50~100这三个年龄段的男、女学生的最高分数
2、数据集
姓名 年龄 性别 成绩
Alice 23 female 45
Bob 34 male 89
Chris 67 male 97
Kristine 38 female 53
Connor 25 male 27
Daniel 78 male 95
James 34 male 79
Alex 52 male 69
3、分析
基于需求,我们通过以下几步完成:
1、编写Mapper类,按需求将数据集解析为key=gender,value=name+age+score,然后输出
2、编写Partitioner类,按年龄段,将结果指定给不同的Reduce执行
3、编写Reducer类,分别统计出男女学生的最高分
4、编写run方法执行MapReduce作业
4、实现
package com.buaa;
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; /**
* @ProjectName BestScoreCount
* @PackageName com.buaa
* @ClassName Gender
* @Description 统计不同年龄段内,男、女最高分数
* @Author 刘吉超
* @Date 2016-05-09 09:49:50
*/
public class Gender extends Configured implements Tool {
private static String TAB_SEPARATOR = "\t"; public static class GenderMapper extends Mapper<LongWritable, Text, Text, Text> {
/*
* 调用map解析一行数据,该行的数据存储在value参数中,然后根据\t分隔符,解析出姓名,年龄,性别和成绩
*/
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
/*
* 姓名 年龄 性别 成绩
* Alice 23 female 45
* 每个字段的分隔符是tab键
*/
// 使用\t,分割数据
String[] tokens = value.toString().split(TAB_SEPARATOR); // 性别
String gender = tokens[2];
// 姓名 年龄 成绩
String nameAgeScore = tokens[0] + TAB_SEPARATOR + tokens[1] + TAB_SEPARATOR + tokens[3]; // 输出 key=gender value=name+age+score
context.write(new Text(gender), new Text(nameAgeScore));
}
} /*
* 合并 Mapper输出结果
*/
public static class GenderCombiner extends Reducer<Text, Text, Text, Text> { public void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException {
int maxScore = Integer.MIN_VALUE;
int score = 0;
String name = " ";
String age = " "; for (Text val : values) {
String[] valTokens = val.toString().split(TAB_SEPARATOR);
score = Integer.parseInt(valTokens[2]);
if (score > maxScore) {
name = valTokens[0];
age = valTokens[1];
maxScore = score;
}
} context.write(key, new Text(name + TAB_SEPARATOR + age + TAB_SEPARATOR + maxScore));
}
} /*
* 根据 age年龄段将map输出结果均匀分布在reduce上
*/
public static class GenderPartitioner extends Partitioner<Text, Text> { @Override
public int getPartition(Text key, Text value, int numReduceTasks) {
String[] nameAgeScore = value.toString().split(TAB_SEPARATOR);
// 学生年龄
int age = Integer.parseInt(nameAgeScore[1]); // 默认指定分区 0
if (numReduceTasks == 0)
return 0; // 年龄小于等于20,指定分区0
if (age <= 20) {
return 0;
}else if (age <= 50) { // 年龄大于20,小于等于50,指定分区1
return 1 % numReduceTasks;
}else // 剩余年龄,指定分区2
return 2 % numReduceTasks;
}
} /*
* 统计出不同性别的最高分
*/
public static class GenderReducer extends Reducer<Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
int maxScore = Integer.MIN_VALUE;
int score = 0;
String name = " ";
String age = " ";
String gender = " "; // 根据key,迭代 values集合,求出最高分
for (Text val : values) {
String[] valTokens = val.toString().split(TAB_SEPARATOR);
score = Integer.parseInt(valTokens[2]);
if (score > maxScore) {
name = valTokens[0];
age = valTokens[1];
gender = key.toString();
maxScore = score;
}
} context.write(new Text(name), new Text("age:" + age + TAB_SEPARATOR + "gender:" + gender + TAB_SEPARATOR + "score:" + maxScore));
}
} @SuppressWarnings("deprecation")
@Override
public int run(String[] args) throws Exception {
// 读取配置文件
Configuration conf = new Configuration(); Path mypath = new Path(args[1]);
FileSystem hdfs = mypath.getFileSystem(conf);
if (hdfs.isDirectory(mypath)) {
hdfs.delete(mypath, true);
} // 新建一个任务
Job job = new Job(conf, "gender");
// 主类
job.setJarByClass(Gender.class);
// Mapper
job.setMapperClass(GenderMapper.class);
// Reducer
job.setReducerClass(GenderReducer.class); // map 输出key类型
job.setMapOutputKeyClass(Text.class);
// map 输出value类型
job.setMapOutputValueClass(Text.class); // reduce 输出key类型
job.setOutputKeyClass(Text.class);
// reduce 输出value类型
job.setOutputValueClass(Text.class); // 设置Combiner类
job.setCombinerClass(GenderCombiner.class); // 设置Partitioner类
job.setPartitionerClass(GenderPartitioner.class);
// reduce个数设置为3
job.setNumReduceTasks(3); // 输入路径
FileInputFormat.addInputPath(job, new Path(args[0]));
// 输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1])); // 提交任务
return job.waitForCompletion(true)?0:1;
} public static void main(String[] args) throws Exception {
String[] args0 = {
"hdfs://ljc:9000/buaa/gender/gender.txt",
"hdfs://ljc:9000/buaa/gender/out/"
};
int ec = ToolRunner.run(new Configuration(),new Gender(), args0);
System.exit(ec);
}
}
5、运行效果
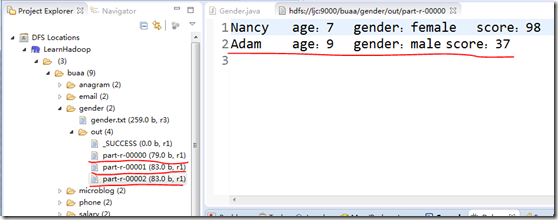
MapReduce最佳成绩统计,男生女生比比看的更多相关文章
- 实训任务05 MapReduce获取成绩表的最高分记录
实训任务05 MapReduce获取成绩表的最高分记录 实训1:统计用户纺问次数 任务描述: 统计用户在2016年度每个自然日的总访问次数.原始数据文件中提供了用户名称与访问日期.这个任务就是要获取 ...
- 2016福州大学软件工程第二次团队作业——预则立&&他山之石成绩统计
第二次团队作业--预则立&&他山之石成绩统计结果如下: T:团队成绩 P:个人贡献比 T+P:折算个人成绩,计算公式为T+T/15*团队人数*P 学号 组别 Team P T+P 03 ...
- MapReduce实战:统计不同工作年限的薪资水平
1.薪资数据集 我们要写一个薪资统计程序,统计数据来自于互联网招聘hadoop岗位的招聘网站,这些数据是按照记录方式存储的,因此非常适合使用 MapReduce 程序来统计. 2.数据格式 我们使用的 ...
- sdut 3-5 学生成绩统计
3-5 学生成绩统计 Time Limit: 1000MS Memory limit: 65536K 题目描写叙述 通过本题目练习能够掌握对象数组的使用方法,主要是对象数组中数据的输入输出操作. 设计 ...
- (注意输入格式)bistuoj(旧)1237 成绩统计
成绩统计 Time Limit(Common/Java):1000MS/3000MS Memory Limit:65536KByteTotal Submit:88 ...
- 成绩统计程序(Java)
我的程序: package day20181018;/** * 成绩统计系统 * @author Administrator */import java.util.Scanner;//提供计算机直接扫 ...
- 体育成绩统计——20180801模拟赛T3
体育成绩统计 / Score 题目描述 正所谓“无体育,不清华”.为了更好地督促同学们进行体育锻炼,更加科学地对同学们进行评价,五道口体校的老师们在体育成绩的考核上可谓是煞费苦心.然而每到学期期末时, ...
- YTU 2798: 复仇者联盟之数组成绩统计
2798: 复仇者联盟之数组成绩统计 时间限制: 1 Sec 内存限制: 128 MB 提交: 136 解决: 96 题目描述 定义一个5行3列的二维数组,各行分别代表一名学生的高数.英语.C++ ...
- YTU 2769: 结构体--成绩统计
2769: 结构体--成绩统计 时间限制: 1 Sec 内存限制: 128 MB 提交: 1021 解决: 530 题目描述 建立一个简单的学生信息表,包括:姓名.性别.年龄及一门课程的成绩,统计 ...
随机推荐
- HTTP 无法注册 URL http://+:80/Temporary_Listen_Addresses/92819ef8-81ea-4bd9-
今天在练习wcf时,客户端调用服务端方法时出现异常.如下: 未处理System.ServiceModel.AddressAlreadyInUseException Message="HTTP ...
- ajax请求遇到服务器重启或中断
常会有不断轮询发送ajax请求,处理一些业务的场景. 要考虑到: 1. 服务器重启,中断,恢复后仍然能恢复正常业务处理. 服务器重启过程中,再次发送请求,请求状态将变为net::ERR_CONNECT ...
- 实用lsof常用命令行
1, 使用 lsof 命令行列出所有打开的文件 # lsof 这可是一个很长的列表,包括打开的文件和网络 上述屏幕截图中包含很多列,例如 PID.user.FD 和 TYPE 等等. FD - Fil ...
- 典当行以及海尔java小节
1.视图问题,发现jar包都出现在根目录下面了,非常不方便.结果如下表: 原始视图是JavaEE,切换到Java视图即可: 2.Tomcat编译的时候什么都没有加载,看到的是一堆红字,那是因为tomc ...
- Label设置行间距--b
内容摘要 UILabel显示多行文本 UILabel设置行间距 解决单行文本 & 多行文本显示的问题 场景描述 众所周知,UILabel显示多行的话,默认行间距为0,但实际开发中,如果显示多行 ...
- BASLER 镜头选型白皮书
本文翻译自Basler镜头选型白皮书 有许多方法来进行镜头选型.本文将会讨论其中的指导原则,以帮助你在项目中选择合适的镜头.我们将讨论许多镜头的基本概念,比如镜头接口.图像大小.放大率.焦距.F数和光 ...
- nutch-1.7 编译
转载自:http://peigang.iteye.com/blog/1563288 从nutch-.3开始 本地抓取(单击) 和 分布式抓取(集群)所使用的配置文件和命令单独分开. 资源:下载地址:h ...
- BZOJ 3083 遥远的国度 树链剖分
3083: 遥远的国度 Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 797 Solved: 181[Submit][Status] Descrip ...
- 用状态机STATE MACHINE实现有选择的文件转换
用书上的例子实现在解析HTML文本时,对"<>"中的符号不进行字符转换. import sys import string from optparse import O ...
- Qt写的截图软件包含源代码和可执行程序
http://blog.yundiantech.com/?log=blog&id=14 Qt写的截图软件包含源代码和可执行程序 http://download.csdn.net/downloa ...