day21-22Redis Mahout
PS: Redis 在博客的 JavaEE PS:大数据实时执行3个特性,Storm,kafka,Redis
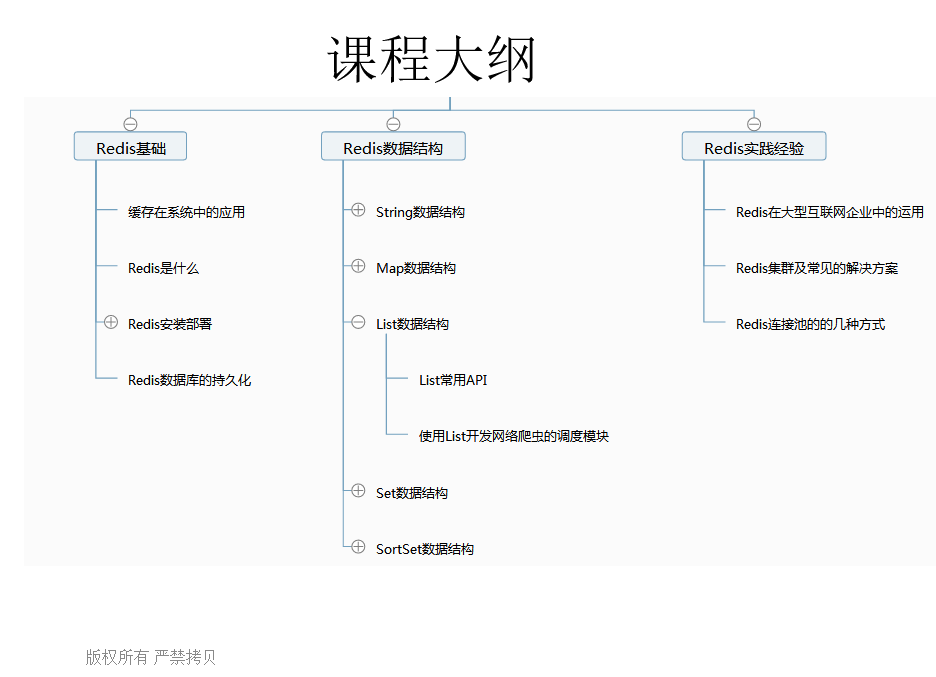
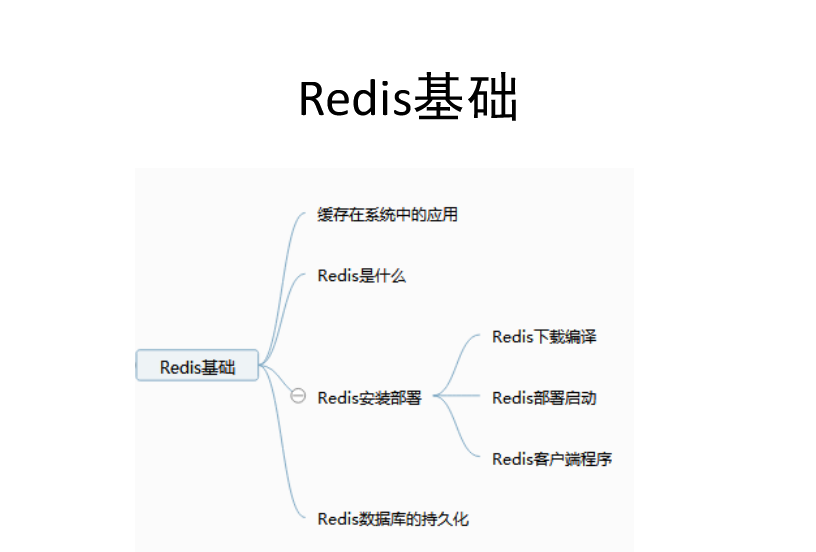
PS:比如在系统中,1s中有大量的请求涌入的系统中,那么请求就存入数据库就挂了,这就需要到了Redis缓存了。


day22 ------------------------
PS: 主要讲诉了日志采集系统,后台又代码,可以参看 flume +kafka+ storm +redis



package mahout; import org.apache.mahout.cf.taste.impl.recommender.GenericItemBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.similarity.ItemSimilarity;
import org.apache.mahout.cf.taste.similarity.precompute.example.GroupLensDataModel; import java.io.File;
import java.util.List; /**
* Describe:
* 与基于用户的技术不同的是,这种方法比较的是内容项与内容项之间的相似度。
* Item-based 方法同样需要进行三个步骤获得推荐:
* 1)得到内容项(Item)的历史评分数据;
* 2)针对内容项进行内容项之间的相似度计算,找到目标内容项的“最近邻居”;
* 3)产生推荐。这里内容项之间的相似度是通过比较两个内容项上的用户行为选择矢量得到的。
* 第二代协同过滤算法
* Author: maoxiangyi
* Domain: www.itcast.cn
* Data: 2015/11/26.
*/
public class BaseItemRecommender { public static void main(String[] args) throws Exception {
//准备数据 这里是电影评分数据
File file = new File("E:\\itcast\\项目中心\\大数据课程研发\\大数据课程-参考资料\\推荐系统\\数据\\ml-10m\\ml-10M100K\\ratings.dat");
//将数据加载到内存中,GroupLensDataModel是针对开放电影评论数据的
DataModel dataModel = new GroupLensDataModel(file);
//计算相似度,相似度算法有很多种,欧几里得、皮尔逊等等。
ItemSimilarity itemSimilarity = new PearsonCorrelationSimilarity(dataModel);
//构建推荐器,协同过滤推荐有两种,分别是基于用户的和基于物品的,这里使用基于物品的协同过滤推荐
GenericItemBasedRecommender recommender = new GenericItemBasedRecommender(dataModel, itemSimilarity);
//给用户ID等于5的用户推荐10个与2398相似的商品
List<RecommendedItem> recommendedItemList = recommender.recommendedBecause(5, 2398, 10);
//打印推荐的结果
System.out.println("使用基于物品的协同过滤算法");
System.out.println("根据用户5当前浏览的商品2398,推荐10个相似的商品");
for (RecommendedItem recommendedItem : recommendedItemList) {
System.out.println(recommendedItem);
}
long start = System.currentTimeMillis();
recommendedItemList = recommender.recommendedBecause(5, 34, 10);
//打印推荐的结果
System.out.println("使用基于物品的协同过滤算法");
System.out.println("根据用户5当前浏览的商品2398,推荐10个相似的商品");
for (RecommendedItem recommendedItem : recommendedItemList) {
System.out.println(recommendedItem);
}
System.out.println(System.currentTimeMillis() -start);
}
}
day21-22Redis Mahout的更多相关文章
- [Mahout] 完整部署过程
概述 Mahout底层依赖Hadoop,部署Mahout过程中最困难的就是Hadoop的部署 本文假设用户本身没有进行Hadoop的部署,记述部署Mahout的过程 ...
- Mahout之数据承载
转载自:https://www.douban.com/note/204399134/ 推荐数据的处理是大规模的,在集群环境下一次要处理的数据可能是数GB,所以Mahout针对推荐数据进行了优化. Pr ...
- Mahout推荐算法API详解
转载自:http://blog.fens.me/mahout-recommendation-api/ Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, ...
- 从源代码剖析Mahout推荐引擎
转载自:http://blog.fens.me/mahout-recommend-engine/ Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pi ...
- mahout 安装测试
1 下载 在http://archive.apache.org/dist/mahout下载相应版本的mahout 版本,获取官网查看http://mahout.apache.org 相关的信息
- Hadoop里的数据挖掘应用-Mahout——学习笔记<三>
之前有幸在MOOC学院抽中小象学院hadoop体验课. 这是小象学院hadoop2.X的笔记 由于平时对数据挖掘做的比较多,所以优先看Mahout方向视频. Mahout有很好的扩展性与容错性(基于H ...
- 初学Mahout测试kmeans算法
预备工作: 启动hadoop集群 准备数据 Synthetic_control.data数据集下载地址http://archive.ics.uci.edu/ml/databases/synthetic ...
- Mahout安装与配置
一.安装mahout 1.下载mahout(mahout-distribution-0.9.tar.gz) http://pan.baidu.com/s/1kUtOMQb 2.解压至指定目录 我平时都 ...
- Mahout 的安装
Mahout 的安装 Mahout是Hadoop的一种高级应用.运行Mahout需要提前安装好Hadoop,Mahout只在Hadoop集群的NameNode节点上安装一个即可,其他数据节点上不需要安 ...
- Mahout源码分析之 -- 文档向量化TF-IDF
fesh个人实践,欢迎经验交流!Blog地址:http://www.cnblogs.com/fesh/p/3775429.html Mahout之SparseVectorsFromSequenceFi ...
随机推荐
- javascript 跑马灯
1.看了写跑马灯的教程案例,隔了段时间自己写了一个简单的跑马灯.将过程中遇到的问题特此记录下来 代码如下: <!DOCTYPE html> <html> <head> ...
- day17-json格式转换
Json简介:Json,全名 JavaScript Object Notation,是一种轻量级的数据交换格式.Json最广泛的应用是作为AJAX中web服务器和客户端的通讯的数据格式.现在也常用于h ...
- day6-if,while,for的快速掌握
python的缩进和冒号 python之所以如此简单,归功于它的缩进机制,严格的缩进机制是的代码非常整齐规范,赏心悦目,提高了可读性,在一定意义上提高了可维护性,但对于从其他语音转过来的朋友如:jav ...
- 将自己的域名解析跳转到博客主页(GitHub中的gitpage跳转)
最近突然迷上了博客,突然又突发奇想,将自己几个月前买的现在限制的域名拿来跳转到自己的csdn博客.经过一番研究,总结---- 把自己的购买的域名(比如我买的circleyuan.top)跳转到CSDN ...
- Android : SELinux 简析&修改
一 SELinux背景知识 SELinux出现之前,Linux上的安全模型叫DAC,全称是Discretionary Access Control,翻译为自主访问控制.DAC的核心思想很简单,就是: ...
- Android : 获取声卡信息的测试代码
完整的编译包(android平台): 链接:http://pan.baidu.com/s/1qXMTT7I 密码:2bow /* * ALSA parameter test program * * C ...
- MFC Release版本串口连不上的问题
项目开发过程中发现Release版本存在连接串口时,第一次开机后,出现连接不上的问题,但在Debug版本下正常:而且只要连接上一次,Release版本就能正常连接: 解决方案: 在串口配置过程中更改为 ...
- 自定义String
// ShStringNew.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include<iostream> #inclu ...
- java中Calendar类
1.测试代码: package com; import java.text.SimpleDateFormat; import java.util.Calendar; import java.util. ...
- http响应头
If-Modified-Since标签,下图可以看出requestHeader中有If-Modified-Since