pytorch实现autoencoder
关于autoencoder的内容简介可以参考这一篇博客,可以说写的是十分详细了https://sherlockliao.github.io/2017/06/24/vae/
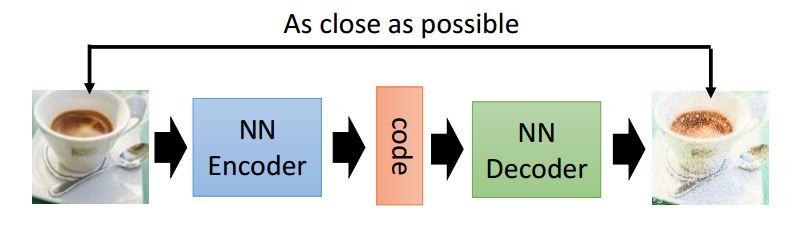
盗图一张,自动编码器讲述的是对于一副输入的图像,或者是其他的信号,经过一系列操作,比如卷积,或者linear变换,变换得到一个向量,这个向量就叫做对这个图像的编码,这个过程就叫做encoder,对于一个特定的编码,经过一系列反卷积或者是线性变换,得到一副图像,这个过程叫做decoder,即解码。
然而自动编码器有什么用,看到上面的博客所写
所以现在自动编码器主要应用有两个方面,第一是数据去噪,第二是进行可视化降维。然而自动编码器还有着一个功能就是生成数据。
然而现在还没有用过这方面的应用,在这里需要着重说明一点的是autoencoder并不是聚类,因为虽然对于每一副图像都没有对应的label,但是autoencoder的任务并不是对图像进行分类啊。
就事论事,下面来分析一下一个大神写的关于autoencoder的代码,这里先给出github链接
先奉上代码
# -*-coding: utf-8-*-
__author__ = 'SherlockLiao' import torch
import torchvision
from torch import nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.utils import save_image
from torchvision.datasets import MNIST
import os if not os.path.exists('./dc_img'):
os.mkdir('./dc_img') def to_img(x): # 将vector转换成矩阵
x = 0.5 * (x + 1)
x = x.clamp(0, 1)
x = x.view(x.size(0), 1, 28, 28)
return x num_epochs = 100
batch_size = 128
learning_rate = 1e-3 img_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]) dataset = MNIST('./data', transform=img_transform)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True) class autoencoder(nn.Module):
def __init__(self):
super(autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, 3, stride=3, padding=1), # b, 16, 10, 10
nn.ReLU(True),
nn.MaxPool2d(2, stride=2), # b, 16, 5, 5
nn.Conv2d(16, 8, 3, stride=2, padding=1), # b, 8, 3, 3
nn.ReLU(True),
nn.MaxPool2d(2, stride=1) # b, 8, 2, 2
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(8, 16, 3, stride=2), # b, 16, 5, 5
nn.ReLU(True),
nn.ConvTranspose2d(16, 8, 5, stride=3, padding=1), # b, 8, 15, 15
nn.ReLU(True),
nn.ConvTranspose2d(8, 1, 2, stride=2, padding=1), # b, 1, 28, 28
nn.Tanh() # 将输出值映射到-1~1之间
) def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x model = autoencoder().cuda()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate,
weight_decay=1e-5) for epoch in range(num_epochs):
for data in dataloader:
img, _ = data # img是一个b*channel*width*height的矩阵
img = Variable(img).cuda()
# ===================forward=====================
output = model(img)
a = img.data.cpu().numpy()
b = output.data.cpu().numpy()
loss = criterion(output, img)
# ===================backward====================
optimizer.zero_grad()
loss.backward()
optimizer.step()
# ===================log========================
print('epoch [{}/{}], loss:{:.4f}'
.format(epoch+1, num_epochs, loss.data[0]))
if epoch % 10 == 0:
pic = to_img(output.cpu().data) # 将decoder的输出保存成图像
save_image(pic, './dc_img/image_{}.png'.format(epoch)) torch.save(model.state_dict(), './conv_autoencoder.pth')
可以说是写的相当清晰了,卷积,pooling,卷积,pooling,最后encoder输出的是一个向量,这个向量的尺寸是8*2*2,一共是32个元素,然后对这个8*2*2的元素进行反卷积操作,pytorch关于反卷积的操作的尺寸计算可以看这里
大概就这样开始训练,save_image是util中的一个函数,给定某一个batchsize的图像,将这个图像保存成8列,特定行的操作。
训练的loss如下
输出的图像如下,从左到右,从上往下,依次为epoch递增的情况










其实还是可以发现,随着epoch的增加,经过decoder生成的图像越来越接近真实图片
pytorch实现autoencoder的更多相关文章
- Pytorch中的自编码(autoencoder)
Pytorch中的自编码(autoencoder) 本文资料来源:https://www.bilibili.com/video/av15997678/?p=25 什么是自编码 先压缩原数据.提取出最有 ...
- Variational Auto-encoder(VAE)变分自编码器-Pytorch
import os import torch import torch.nn as nn import torch.nn.functional as F import torchvision from ...
- PyTorch官方中文文档:torch.nn
torch.nn Parameters class torch.nn.Parameter() 艾伯特(http://www.aibbt.com/)国内第一家人工智能门户,微信公众号:aibbtcom ...
- pytorch做seq2seq注意力模型的翻译
以下是对pytorch 1.0版本 的seq2seq+注意力模型做法语--英语翻译的理解(这个代码在pytorch0.4上也可以正常跑): # -*- coding: utf-8 -*- " ...
- Pytorch入门之VAE
关于自编码器的原理见另一篇博客 : 编码器AE & VAE 这里谈谈对于变分自编码器(Variational auto-encoder)即VAE的实现. 1. 稀疏编码 首先介绍一下“稀疏编码 ...
- (转)Awesome PyTorch List
Awesome-Pytorch-list 2018-08-10 09:25:16 This blog is copied from: https://github.com/Epsilon-Lee/Aw ...
- (转) The Incredible PyTorch
转自:https://github.com/ritchieng/the-incredible-pytorch The Incredible PyTorch What is this? This is ...
- 库、教程、论文实现,这是一份超全的PyTorch资源列表(Github 2.2K星)
项目地址:https://github.com/bharathgs/Awesome-pytorch-list 列表结构: NLP 与语音处理 计算机视觉 概率/生成库 其他库 教程与示例 论文实现 P ...
- VAE--就是AutoEncoder的编码输出服从正态分布
花式解释AutoEncoder与VAE 什么是自动编码器 自动编码器(AutoEncoder)最开始作为一种数据的压缩方法,其特点有: 1)跟数据相关程度很高,这意味着自动编码器只能压缩与训练数据相似 ...
随机推荐
- Eclipse导出WAR包
参考: https://jingyan.baidu.com/article/ab0b56309110b4c15afa7de2.html
- POJ 1390 Blocks(记忆化搜索+dp)
POJ 1390 Blocks 砌块 时限:5000 MS 内存限制:65536K 提交材料共计: 6204 接受: 2563 描述 你们中的一些人可能玩过一个叫做“积木”的游戏.一行有n个块 ...
- laravel创建资源路由控制器
php artisan make:controller PhotoController --resource
- linux网络操作 配置文件
网络接口配置文件(网卡信息文件) '/etc/sysconfig/network-srcipts/ifcfg-*(eth0)' (注意区分大小写) DEVICE=eth0 网卡编号 HWADDR=08 ...
- Win10系列:VC++媒体播放控制4
(7)音量控制 MediaElement控件具有一个Volume属性,通过设置此属性的值可以改变视频音量的大小.接下来介绍如何实现视频的音量控制,首先打开MainPage.xaml文件,并在Grid元 ...
- jar包在控制台下运行
今天有个项目需要在控制台下面运行jar文件 流程 1 新建java项目 2 新建 HelloWorld.java public class HelloWorld { public static voi ...
- [Codeforces513E2]Subarray Cuts
Problem 给定一个长度为n的数字串,从中选取k个不重叠的子串(可以少选),将每个串求和si 求max|s1 - s2| + |s2 - s3| + ... + |sk - 1 - sk|(n & ...
- getopts的使用方法
getopts的使用 语法格式:getopts [option[:]] [DESCPRITION] VARIABLE option:表示为某个脚本可以使用的选项 ":":如果某个选 ...
- day23 模块02
核能来袭--模块 2 1.nametuple() 2.os模块 3.sys模块(重点) 4.序列化 (四个函数) 5.pickle(重点) 6.json(重点中的重点) 1.nametuple() 命 ...
- Cracking The Coding Interview 4.1
//Implement a function to check if a tree is balanced. For the purposes of this question, a balanced ...