NOI 2007 货币兑换Cash (bzoj 1492) - 斜率优化 - 动态规划 - CDQ分治
Description
.png)
.png)
Input
Output
只有一个实数MaxProfit,表示第N天的操作结束时能够获得的最大的金钱数目。答案保留3位小数。
Sample Input
1 1 1
1 2 2
2 2 3
Sample Output
HINT
.png)
题目大意 每天可以根据一定比例购买或者卖出纪念劵。问最多在$n$天后可以得到多少钱。
由题意易得,一定存在一种最优的方案满足,能买时就全买,能卖时就全卖。因为如果要赚就要尽可能地多赚,会亏就一点都不去碰。
设$f[i]$表示第$i$天后把手上的纪念劵都卖掉后可以得到最多的钱,于是轻松地列出了dp方程:
$f[i] = \max\left \{ \frac{f[j]\left ( r_{j}A_{i} + B_{i} \right )}{r_{j}A_{j} + B_{j}}, f[i - 1] \right \}$
暂时先不管$\max$,当成等式,两边同除以$B_{i}$。
$\frac{f[i] }{B_{i}}= \frac{f[j]\left ( r_{j}\frac{A_{i}}{B_{i}} + 1 \right )}{r_{j}A_{j} + B_{j}}$
然后移移项什么的。。
$\frac{f[i] }{B_{i}}= \frac{f[j]r_{j}}{r_{j}A_{j} + B_{j}}\cdot \frac{A_{i}}{B_{i}}+\frac{ f[j]}{r_{j}A_{j} + B_{j}}$
$\frac{ f[j]}{r_{j}A_{j} + B_{j}}=- \frac{f[j]r_{j}}{r_{j}A_{j} + B_{j}}\cdot \frac{A_{i}}{B_{i}}+\frac{f[i] }{B_{i}}$
(第二步是把和$j$相关的扔到等号左边去,当做$y$,把形如$M\left(i\right)N\left(j \right )$,扔到左边,把其中的$M\left(i\right)$看作常数项,把$N\left(j \right )$看作$x$)
所以有:
$x_{i} = \frac{r_{i}f[i]}{r_{i}A_{i} + B{i}},y_{i}=\frac{f[i]}{r_{i}A_{i} + B{i}}$
然后可得:
$y_{j} = -\frac{A_{i}}{B_{i}}x_{j} + \frac{f[i]}{B_{i}}$
因为要最大化$f[i]$,所以应该最大化截距。所以维护上凸壳。
同时方程也可以写成:
$f[i] =\max\left \{ A_{i}x_{j}+B_{i}y_{j}, f[i - 1] \right \}$
考虑如何来求最大的截距。
因为这里插入点的$x$坐标不单调,询问的斜率也不单调,所以不能开单调队列暴力移指针了。
Solution 1 平衡树维护动态凸壳
(这是什么啊?可以吃吗?)
最后维护的凸壳是要长这个样子:
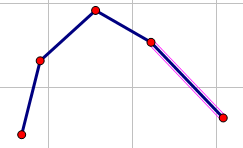
由于边不是很稳定,因为插入或者删除一个点,维护边的信息很麻烦。。。所以考虑用平衡树维护点,如果能够找到前驱后继,那么就可以轻松地找到边的信息。
由于要能找到边的信息,所以将点按照横坐标进行排序。
为了更好地偷懒,所以假设第0个点连接第1个点的直线的斜率为$inf$,最后一条点的后一条直线斜率为$-inf$
考虑插入一个点。
向左向右分别找到第一个能与它组成凸壳的点(即满足斜率递减,对于它前面的点来说就是,满足连接点$pre$的前驱和$pre$的直线的斜率大于连接点$pre$和当前点的直线的斜率)
显然这个东西可以二分。其实是不用的。。。(时间复杂均摊有保证,每个点被访后要么成为了要的点,结束了操作,要么被删了,所以时间复杂度$O\left(n\right)$)
当然还需要判断一下,这种情况
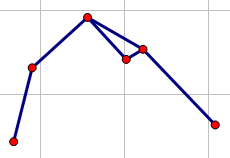
这种的话,只需要看看前面的点和后面的点以及当前点是否合法,不合法就说明当前点不该加入,否则就把它加入凸包。
至于如何维护前驱后继?
其实很简单,因为只在插入和删除的时候会发生改变,就在那个时候维护一下就好了。
现在考虑要在凸壳上找一个点,使得一条斜率为$k$的直线经过它,并且截距最大。
(这玩意儿显然可以三分)
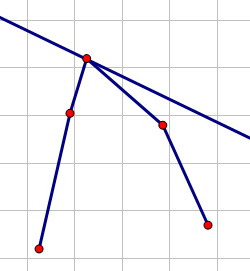
显然,当直线于凸壳相切(或者和凸壳的某一条边重合)的时候截距最大。不如一个不相切的情况:
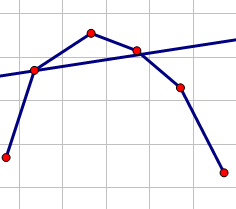
显然可以通过平移使得它更优。
考虑什么时候相切呢?当经过的点的前一条直线的斜率大于等于$k$,以及它的后一条直线的斜率小于等于$k$时。
这个显然可以二分。于是剩下的就是代码的问题。。
(注意精度问题。。)
Code
/**
* bzoj
* Problem#1492
* Accepted
* Time: 1160ms
* Memory: 11468k
*/
#include <bits/stdc++.h>
using namespace std;
typedef bool boolean;
#define pnn pair<TreapNode*, TreapNode*>
#define fi first
#define sc second const double eps = 1e-; int dcmp(double x) {
if(fabs(x) < eps) return ;
return (x > ) ? () : (-);
} typedef class TreapNode {
public:
double x;
double y;
int rd;
TreapNode *l, *r;
TreapNode *pre, *suf;
}TreapNode; #define Limit 200000 TreapNode pool[Limit];
TreapNode *top = pool; TreapNode* newnode(double x, double y) {
top->x = x, top->y = y;
top->l = top->r = NULL;
top->rd = rand();
return top++;
} typedef class DynamicConvexHull {
public:
TreapNode* root; DynamicConvexHull():root(NULL) { } pnn split(TreapNode* p, double x) {
if(!p) return pnn(NULL, NULL);
pnn rt;
if(p->x - eps > x) {
rt = split(p->l, x);
p->l = rt.sc, rt.sc = p;
} else {
rt = split(p->r, x);
p->r = rt.fi, rt.fi = p;
}
return rt;
} TreapNode* merge(TreapNode* a, TreapNode* b) {
if(a == NULL) return b;
if(b == NULL) return a;
if(a->rd > b->rd) {
a->r = merge(a->r, b);
return a;
}
b->l = merge(a, b->l);
return b;
} double slope(TreapNode* a, TreapNode* b) {
if(a == NULL) return 1e100;
if(b == NULL) return -1e100;
if(!dcmp(a->x - b->x))
return (dcmp(a->y - b->y) == -) ? (1e100) : (-1e100);
return (a->y - b->y) / (a->x - b->x);
} TreapNode* findPre(TreapNode* p, TreapNode* np) {
TreapNode* rt = NULL;
while(p) {
if(slope(p->pre, p) - eps > slope(p, np))
rt = p, p = p->r;
else
p = p->l;
}
return rt;
} TreapNode* findSuf(TreapNode* p, TreapNode* np) {
TreapNode* rt = NULL;
while(p) {
if(slope(np, p) - eps > slope(p, p->suf))
rt = p, p = p->l;
else
p = p->r;
}
return rt;
} void insert(double x, double y) {
TreapNode* pn = newnode(x, y);
pnn pr = split(root, x);
TreapNode* pre = findPre(pr.fi, pn);
TreapNode* suf = findSuf(pr.sc, pn);
pn->pre = pre, pn->suf = suf;
if(slope(pre, pn) - eps >= slope(pn, suf)) {
pr.fi = (pre) ? (split(pr.fi, pre->x + eps + eps).fi) : (NULL);
pr.sc = (suf) ? (split(pr.sc, suf->x - eps - eps).sc) : (NULL);
if(pre) pre->suf = pn;
if(suf) suf->pre = pn;
pr.fi = merge(pr.fi, pn);
}
root = merge(pr.fi, pr.sc);
} TreapNode* query(double k) {
TreapNode* p = root, *rt = NULL;
double cur, cmp;
while(p) {
cur = slope(p->pre, p);
if(cur - eps >= k) {
if(!rt || cur + eps < cmp)
rt = p, cmp = cur;
p = p->r;
} else
p = p->l;
}
return rt;
} // void debugOut(TreapNode* p) {
// if(!p) return;
// debugOut(p->l);
// cerr << "(" << p->x << ", " << p->y << ")" << endl;
// debugOut(p->r);
// }
}DynamicConvexHull; int n;
double *A, *B, *rate;
double *f;
DynamicConvexHull dch; inline void init() {
scanf("%d", &n);
A = new double[(n + )];
B = new double[(n + )];
f = new double[(n + )];
rate = new double[(n + )];
fill(f, f + n + , 0.0);
scanf("%lf", f);
for(int i = ; i <= n; i++)
scanf("%lf%lf%lf", A + i, B + i, rate + i);
} inline void solve() {
f[] = f[];
double y = f[] / (rate[] * A[] + B[]);
double x = rate[] * y, k;
dch.insert(x, y);
for(int i = ; i <= n; i++) {
k = -A[i] / B[i];
TreapNode* rt = dch.query(k);
f[i] = A[i] * rt->x + B[i] * rt->y;
f[i] = max(f[i], f[i - ]);
y = f[i] / (rate[i] * A[i] + B[i]);
x = y * rate[i];
dch.insert(x, y);
}
printf("%.3lf\n", f[n]);
} int main() {
init();
solve();
return ;
}
Cash(平衡树维护动态凸壳)
Solution 2 CDQ分治
考虑当前要求出$[l, r]$中的dp值。
根据CDQ分治的常用套路,考虑左区间对右区间的贡献。
假设现在已经成功计算出左区间中的dp值,并将这些状态按照横坐标排序。
那么就可以用单调队列维护静态凸壳把左区间的凸壳建出来。
将右区间按照询问的斜率从大到小排序。
于是,这就变成了最智障的斜率优化问题了。。
但是$O\left ( n\log^{2}n \right )$会不会T掉?
考虑计算右区间的时候并不需要按照横坐标排序,而是按照询问的斜率排序。
所以,在分治前按照询问的斜率排序,然后在回溯的过程中按照横坐标进行归并。
于是成功去掉一个$\log$,总时间复杂度$O\left ( n\log n \right )$
但是因为自带大常数,比别人的Splay慢好多,sad....
Code
/**
* bzoj
* Problem#1492
* Accepted
* Time: 1208ms
* Memory: 8732k
*/
#include <bits/stdc++.h>
using namespace std;
typedef bool boolean; const double eps = 1e-; int dcmp(double x) {
if(fabs(x) < eps) return ;
return (x > ) ? () : (-);
} typedef class Query {
public:
double k;
int id; boolean operator < (Query b) const {
return k > b.k;
}
}Query; int n;
double *A, *B, *rate;
double *xs, *ys;
double *f;
Query *qs, *qbuf;
int* sta; inline void init() {
scanf("%d", &n);
A = new double[(n + )];
B = new double[(n + )];
rate = new double[(n + )];
xs = new double[(n + )];
ys = new double[(n + )];
f = new double[(n + )];
qs = new Query[(n + )];
qbuf = new Query[(n + )];
sta = new int[(n + )];
scanf("%lf", f);
for(int i = ; i <= n; i++) {
scanf("%lf%lf%lf", A + i, B + i, rate + i);
qs[i].k = -A[i] / B[i], qs[i].id = i;
}
} double slope(int s, int t) {
if(dcmp(xs[s] - xs[t]) == ) return (1e100);
return (ys[t] - ys[s]) / (xs[t] - xs[s]);
} boolean cmpPoint(int a, int b) {
int d = dcmp(xs[a] - xs[b]);
return (d == - || (d == && dcmp(ys[a] - ys[b]) == -));
} void CDQDividing(int l, int r, int L, int R) {
if(l == r) {
f[l] = max(f[l], f[l - ]);
xs[l] = rate[l] * f[l] / (rate[l] * A[l] + B[l]);
ys[l] = f[l] / (rate[l] * A[l] + B[l]);
return;
} int mid = (l + r) >> , qL = L - , qR = mid; for(int i = L; i <= R; i++)
if(qs[i].id <= mid)
qbuf[++qL] = qs[i];
else
qbuf[++qR] = qs[i];
for(int i = L; i <= qR; i++)
qs[i] = qbuf[i];
CDQDividing(l, mid, L, qL); int pl = , pr = , t = L;
for(int i = L; i <= qL; i++) {
while(pr - pl > && dcmp(slope(sta[pr - ], sta[pr]) - slope(sta[pr], qs[i].id)) != ) pr--;
sta[++pr] = qs[i].id;
} for(int i = mid + , id; i <= R; i++) {
id = qs[i].id;
while(pr - pl > && dcmp(qs[i].k - slope(sta[pl], sta[pl + ])) == -) pl++;
f[id] = max(f[id], A[id] * xs[sta[pl]] + B[id] * ys[sta[pl]]);
} CDQDividing(mid + , r, mid + , R); pl = L, pr = mid + ;
while(pl <= qL || pr <= R) {
if((pr > R) || (pl <= qL && cmpPoint(qs[pl].id, qs[pr].id)))
qbuf[t++] = qs[pl++];
else
qbuf[t++] = qs[pr++];
}
for(int i = L; i <= R; i++)
qs[i] = qbuf[i];
} inline void solve() {
sort(qs + , qs + n + );
fill(f + , f + n + , );
CDQDividing(, n, , n);
printf("%.3lf\n", f[n]);
} int main() {
init();
solve();
return ;
}
NOI 2007 货币兑换Cash (bzoj 1492) - 斜率优化 - 动态规划 - CDQ分治的更多相关文章
- bzoj 1492: [NOI2007]货币兑换Cash【贪心+斜率优化dp+cdq】
参考:http://www.cnblogs.com/lidaxin/p/5240220.html 虽然splay会方便很多,但是懒得写,于是写了cdq 首先要想到贪心的思路,因为如果在某天买入是能得到 ...
- 【bzoj3672】[Noi2014]购票 斜率优化dp+CDQ分治+树的点分治
题目描述 给出一棵以1为根的带边权有根树,对于每个根节点以外的点$v$,如果它与其某个祖先$a$的距离$d$不超过$l_v$,则可以花费$p_vd+q_v$的代价从$v$到$a$.问从每个点到1花费 ...
- P4027 [NOI2007]货币兑换(斜率优化dp+cdq分治)
P4027 [NOI2007]货币兑换 显然,如果某一天要买券,一定是把钱全部花掉.否则不是最优(攒着干啥) 我们设$f[j]$为第$j$天时用户手上最多有多少钱 设$w$为花完钱买到的$B$券数 $ ...
- [NOI2007]货币兑换 --- DP + 斜率优化(CDQ分治)
[NOI2007]货币兑换 题目描述: 小 Y 最近在一家金券交易所工作.该金券交易所只发行交易两种金券:A 纪念券(以下简称 A 券)和 B 纪念券(以下简称 B 券). 每个持有金券的顾客都有一个 ...
- HDU 3824/ BZOJ 3963 [WF2011]MachineWorks (斜率优化DP+CDQ分治维护凸包)
题面 BZOJ传送门(中文题面但是权限题) HDU传送门(英文题面) 分析 定义f[i]f[i]f[i]表示在iii时间(离散化之后)卖出手上的机器的最大收益.转移方程式比较好写f[i]=max{f[ ...
- 【BZOJ2149】拆迁队(斜率优化DP+CDQ分治)
题目: 一个斜率优化+CDQ好题 BZOJ2149 分析: 先吐槽一下题意:保留房子反而要给赔偿金是什么鬼哦-- 第一问是一个经典问题.直接求原序列的最长上升子序列是错误的.比如\(\{1,2,2,3 ...
- BZOJ 1492 [NOI2007]货币兑换Cash:斜率优化dp + cdq分治
传送门 题意 初始时你有 $ s $ 元,接下来有 $ n $ 天. 在第 $ i $ 天,A券的价值为 $ A[i] $ ,B券的价值为 $ B[i] $ . 在第 $ i $ 天,你可以进行两种操 ...
- [NOI 2007]货币兑换Cash
Description 题库链接 (按我的语文水平完全无 fa♂ 概括题意,找了 hahalidaxin 的题意简述... 有 \(AB\) 两种货币,每天可以可以付 \(IP_i\) 元,买到 \( ...
- Luogu 3810 & BZOJ 3262 陌上花开/三维偏序 | CDQ分治
Luogu 3810 & BZOJ 3263 陌上花开/三维偏序 | CDQ分治 题面 \(n\)个元素,每个元素有三个值:\(a_i\), \(b_i\) 和 \(c_i\).定义一个元素的 ...
随机推荐
- 排名前10的vue前端UI框架框架值得你掌握
参考:https://juejin.im/post/5b34faeef265da59645b188e muse-ui 框架: https://juejin.im/entry/582974eb8ac24 ...
- nginx: [error] invalid PID number "" in "/usr/local/webserver/nginx/logs/nginx.pid" (原)
进入nginx文件下,例如 :/usr/local/nginx/sbin [root@iZ25f7emo7cZ /]# cd /usr/local/nginx/sbin 运行命令: [root@iZ2 ...
- java微信小程序调用支付接口(转)
简介:微信小程序支付这里的坑还是有的,所以提醒各位在编写的一定要注意!!! 1.首先呢,你需要准备openid,appid,还有申请微信支付后要设置一个32位的密钥,需要先生成一个sign,得到pre ...
- 004-全局应用程序类Global.asax
服务器对象:Request.Response.Server.Session.Application.Cookie //功能1:为服务器对象注册Start.End处理 protected void Ap ...
- linux常见运维题
linux运维题 一.填空题 1. 在Linux 系统 中,以文件方式访问设备 . (linux下一切都是文件) 2. Linux 内核引导时,从文件/etc/fstab中读取要加载的文件系统 . ( ...
- arc 092D Two Sequences
题意: 给出两个长度N相同的整数序列A和B,有N^2种方式从A中选择一个数Ai,从B中选择一个数Bj,让两个数相加,求这N^2个数的XOR,即异或. 思路: 暴力的求显然是会超时的,因为是异或,就考虑 ...
- highcharts插件
详见官网:https://www.highcharts.com.cn/demo/highcharts 详细使用代码: <!DOCTYPE html> <html lang=" ...
- python 类似java的三目运算符
python中没有其他语言中的三元表达式,不过有类似的实现方法 其他语言中,例如java的三元表达式是这样 int a = 1; String b = ""; b = a > ...
- Log4J基础详解及示例大全(转)
log4j可以通过使用配置文件的方式进行配置. 配置步骤如下: 1.定义日志组件logger 每个logger都可以拥有一个或者多个appender,每个appender表示一个日志的输出目的地,比如 ...
- linux常用命令:mv 命令
mv命令是move的缩写,可以用来移动文件或者将文件改名(move (rename) files),是Linux系统下常用的命令,经常用来备份文件或者目录. 1.命令格式: mv [选项] 源文件或目 ...