elk的安装部署
Elk日志安装文档
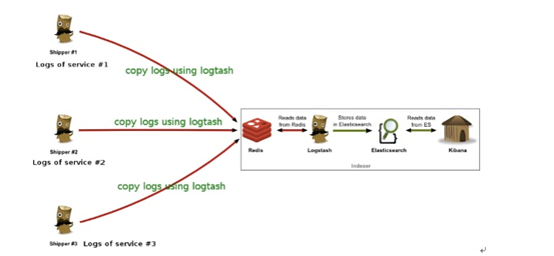
需要用到有三个软件包 和redis

分布式部署:已上图就是分布式部署的架构图
Logstash : 是部署在前台的应用上,收集数据的
和部署在redis和elasticsearch中间充当索引
Elasticsearch: 部署在logstash之后的,将logsstash收集的数据存储
Kibana : 部署在最后,经elasticsearch收集的数据通过页面展现出来(默认端口号:5601)
我这里部署的logstash elasticsearch kibana 在一台服务器上,但是应用的服务器还是要不是logstash的
开始部署:
Server端:(logstash clasticsearch kibana的部署)需要jdk环境
将软件包上传的要安装的目录,我安装目录是/picclife (注:要用普通用户暗转,不然不安全)
我有的是app_admin用户
安装jdk环境我安装在/picclife
编辑app_admin 用户的jdk变量
vim /home/app_admin/.bash_protfile
PATH=/picclife/jdk1.8.0_65/bin/:$PATH:$HOME/bin
export PATH
export JAVA_HOME=/picclife/jdk1.8.0_65/
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
申明变量:source /home/app_admin/.bash_protfile
查看java -version
安装logstash:
tar -zxf logstash-5.3.0.tar.gz
在/picclife/logstash-5.3.0/config 创建一个logstash.conf .conf结尾的文件
编辑vim logsstach.conf
input{
redis{
batch_count => 1
data_type => "list"
key => "logstash-uap-list" #logstach应用的服务器上一样就可以
host => "10.135.100.86" #redis的ip
port => 6379 #redis的端口好
password => "nick123" #redis的密码
db => 2 #redis的索引(可以在redis上查看一下如没人用就可以最下面有截图)
threads => 1
}
}
output{
elasticsearch{
hosts => ["10.135.33.129"] #elasticsearch的ip
index => "uap-log"
}
stdout{
codec => rubydebug{}
}
}
编辑启动脚本在/picclife/logstach-5.3.0
vim logstash_start.sh
nohup /picclife/logstash-5.3.0/bin/logstash -f /picclife/logstash-5.3.0/config/logstash.conf >> /picclife/logstash-5.3.0/logs/logstash-start.log 2>&1 & #nohup后台运行 将启动的程序追加到logstash-start.log文件里 可以到这个文件查看启动报不报错
在/picclife/logstach-5.3.0创建logs目录
mkdir logs
执行脚本启动
sh logstash_start.sh
关闭是: ps -ef |grep logstash kill 查到的进程
安装elasticsearch
tar -zxf elasticsearch-5.3.0.tar.gz
编辑启动脚本在/picclife/elasticsearch-5.3.0
vim elasticesarch_start.sh
nohup /picclife/elasticsearch-5.3.0/bin/elasticsearch >> /picclife/elasticsearch-5.3.0/logs/elasticsearch-start.log 2>&1 &
在/picclife/elasticsearch-5.3.0 下创建logs目录
mkdir logs
启动 sh elasticseart_start.sh
关闭 ps -ef|grep elasticseart kill 查到的进程
安装 kibana
tar -zxf kibana-5.3.0-linux-x86_64.tar.gz
在/picclife/kibana-5.3.0/config 编辑
vi kibana.yml 指向elasticsearch的ip
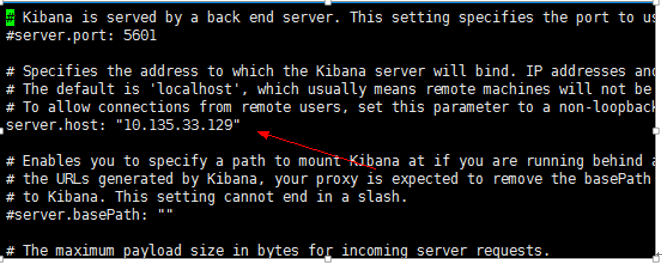
在/picclife/kibana-5.3.0/创建启动脚本
vi kibana_start.sh
nohup /picclife/kibana-5.3.0/bin/kibana >> /picclife/kibana5.3.0/logs/kibana-start.log 2>&1 &
在kibana-5.3.0创建logs目录
mkdir logs
启动是 sh kebana_start.sh
关闭是ps -ef|grep node kill 查到的进程 (kibana是不需要jdk环境的)
Redis 查看一显现是可以

服务器基本安装完成开始安装客户端:(jdk环境)
解压:
tar -zxf logstash-5.3.0.tar
在/picclife/logstash-5.3.0/config创建logstash.conf 的文件
Vim logstash.conf
input{
file{
path => ["/picclife/apache-tomcat-8.0.30/logs/catalina.out"] #监听的日志
type => "uap-log-all"
start_position => "beginning"
}
}
filter{
grok {
patterns_dir => "/picclife/logstash-5.3.0/config/patternsutils" #需要创建这个文件有日志格式的这则
match => {
"message" =>
[
"%{TIMESTAMP_ISO8601:RequestTime}%{SPACE}%{MATCHSTR:RequestName}%{SPACE}>>>%{SPACE}%{USERNAME:RequestId}%{SPACE}>>>%{SPACE}%{ROUTEID:RdID}%{SPACE}<<<%{SPACE}SystemNo:%{ZW:SystemNo}\,%{SPACE}InterfaceNo:%{ZW:InterfaceNo}\,%{SPACE}InterfaceName:%{ZW:InterfaceName}\,%{SPACE}Flag:%{ZW:Flag}\,%{SPACE}CostTime:%{INT:CostTime}%{SPACE}%{ZW:other}"
] #日志格式
}
remove_field => [ "message","other"]
}
##过滤日志(过滤掉requestName!=camlelog的记录)
if [RequestName]!="camellog" and [RequestName]!="gatherlog"{
drop{}
}
date {
match => ["RequestTime", "MMM dd YYY HH:mm:ss", "MMM d YYY HH:mm:ss", "ISO8601"]
locale => "en"
#timezone => "+00:00"
remove_field => [ "RequestTime" ]
}
mutate {
convert => { "CostTime" => "integer" }
}
}
output{
redis{
data_type => "list"
key => "logstash-uap-list"
host => "10.135.100.86" #redis ip
port => 6379 #redis端口
password => "nick123" #redis的密码
db => 2 #redis的索引和上面的一样
}
stdout{
codec => rubydebug{}
}
}
在/picclife/logstash-5.3.0/config/下穿件patternsutils文件
Vim patternsutils
ZW (.*)
SPSTR (([\s\S]*))
###匹配{....}格式的字符串
DKH (\{.*\})
###匹配字母
MATCHSTR ([A-Za-z]*)
###java 时间格式 2017-05-26 08:01:03
JAVA_DATE %{DATE_EU} %{TIME}
###匹配XXX{....}、XXX[...]以及XX字符
DKHBODY ((.*\{.*\})|(.*\[.*\])|(.*))
###匹配(
LEFTBRACKET (\()
###匹配)
RIGHTBRACKET (\))
###匹配括号里的routeid
ROUTEID (.{5,9})
在/picclife/logstash-5.3.0 创建启动脚本
vim logstash_start.sh
nohup /picclife/logstash-5.3.0/bin/logstash -f /picclife/logstash-5.3.0/config/logstash.conf >> /picclife/logstash-5.3.0/logs/logstash-start.log 2>&1 &
在/picclife/logstash-5.3.0/创建logs
mkdir logs
关闭: ps -ef |grep logstash kill 查到的进程
到此elk的安装完成
有道云笔记的参考
http://note.youdao.com/noteshare?id=a6bce94ea32d5fce9a2b1705d6a272aa
elk的安装部署的更多相关文章
- ELK详细安装部署
一.前言 日志主要包括系统日志和应用程序日志,运维和开发人员可以通过日志了解服务器中软硬件的信息,检查应用程序或系统的故障,了解故障出现的原因,以便解决问题.分析日志可以更清楚的了解服务器的状态和 ...
- ELK+KAFKA安装部署指南
一.ELK 背景 通常,日志被分散的储存不同的设备上.如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志.这样是不是感觉很繁琐和效率低下.当务之急我们使用集中化的日志管理,例如: ...
- elk单机安装部署
es 下载地址:wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.1.0-linux-x86_64.t ...
- ELK 安装部署小计
ELK的安装部署已经是第N次了! 其实也很简单,这里记下来,以免忘记. #elasticsearch安装部署 wget https://artifacts.elastic.co/downloads/e ...
- ELK日志监控平台安装部署简介--Elasticsearch安装部署
最近由于工作需要,需要搭建一个ELK日志监控平台,本次采用Filebeat(采集数据)+Elasticsearch(建立索引)+Kibana(展示)架构,实现日志搜索展示功能. 一.安装环境描述: 1 ...
- ELK 安装部署实战 (最新6.4.0版本)
一.实战背景 根据公司平台的发展速度,对于ELK日志分析日益迫切.主要的需求有: 1.用户行为分析 2.运营活动点击率分析 作为上述2点需求,安装最新版本6.4.0是非常有必要的,大家可根据本人之前博 ...
- ELK文档-安装部署
一.ELK简介 请参考:http://www.cnblogs.com/aresxin/p/8035137.html 二.ElasticSearch安装部署 请参考:http://blog.51cto. ...
- supervisor的安装部署及集群管理
supervisor的安装部署及集群管理 supervisor官网:http://www.supervisord.org/ 参考链接: http://blog.csdn.net/xyang81/art ...
- ELK集群部署实例(转)
转载自:http://blog.51cto.com/ckl893/1772287,感谢原博. 一.ELK说明 二.架构图 三.规划说明 四.安装部署nginx+logstash 五.安装部署redis ...
随机推荐
- cogs448
☆ 输入文件:1.in 输出文件:1.out 简单对比时间限制:1 s 内存限制:128 MB [题目描述] 在某次膜拜大会上,一些神牛被要求集体膜拜.这些神牛被奖励每人吃一些神牛果. ...
- MongoDB,无模式文档型数据库简介
MongoDB的名字源自一个形容词humongous(巨大无比的),在向上扩展和快速处理大数据量方面,它会损失一些精度,在旧金山举行的MondoDB大会上,Merriman说:“你不适宜用它来处理复杂 ...
- Linux用户创建/磁盘挂载相关命令
命令 作用 常用参数说明 groupadd 增加用户组 -g指定组id groupmod 修饰用户组 参数和groupadd类似 groupdel 删除用户组 直接组名没参数 useradd 增加用户 ...
- [转]使用CMS垃圾收集器产生的问题和解决方案
在之前的一篇文章<CMS vs. Parallel GC>里通过实验的方式对比了并行和并发GC的优缺点,在文章结尾提到,CMS并行GC是大多数应用的最佳选择,然而, CMS并不是完美的,在 ...
- Qt绘制字体并获取文本宽度
参考资料: https://blog.csdn.net/liang19890820/article/details/51227894 QString text("abc");QPa ...
- linux用户管理 用户和用户组信息
用户管理配置文件 用户信息文件 /etc/passwd 密码文件 /etc/shadow 用户配置文件 /etc/login.defs /etc/default/useradd 新用户信息文件 /e ...
- 用linq和datatable巧妙应用于微软报表rdlc
看看代码吧.现在我用Linq已经上瘾,对SQL语言已经几乎不用了,可惜的是rdlc不支持linq,要采用sql语言生成datatable,用datatable绑定rdlc,这里,应用了一个技巧,解决了 ...
- mysql不会使用索引,导致全表扫描情况
不会使用索引,导致全表扫描情况 1.不要使用in操作符,这样数据库会进行全表扫描,推荐方案:在业务密集的SQL当中尽量不采用IN操作符 2.not in 使用not in也不会走索引推荐方案:用not ...
- 高效方便的IO库: System.IO.Pipelines
我们在编写网络程序的时候,经常会进行如下操作: 申请一个缓冲区 从数据源中读入数据至缓冲区 解析缓冲区的数据 重复第2步 表面上看来这是一个很常规而简单的操作,但实际使用过程中往往存在如下痛点: 数据 ...
- 洛谷 P4515 [COCI2009-2010#6] XOR
题意 平面直角坐标系中有一些等腰直角三角形,且直角边平行于坐标轴,直角顶点在右下方,求奇数次被覆盖的面积.N<=10.输入为x,y,r,分别表示三角形顶点的坐标与三角形的边长. 如: 总面积为0 ...