scrapy爬取动态分页内容
1、任务定义:
爬取某动态分页页面中所有子话题的内容。
所谓“动态分页”:是指通过javascript(简称“js”)点击实现翻页,很多时候翻页后的页面地址url并没有变化,而页面内容随翻页动作动态变化。
2、任务难点及处理方法:
难点:
1) scrapy如何动态加载所有“下一页”:要知道scrapy本身是不支持js操作的。
2) 如何确保页面内容加载完成后再进行爬取:由于内容是通过js加载的,如果不加控制,很可能出现爬到空页面的情况。
处理方法:
1)scrapy+selenium模拟浏览器点击:通过模拟浏览器点击的方式进行翻页,从而获取每一页内部的有效链接。
2)使用WebDriverWait()等待数据加载:即确保对应内容加载完成后,再进行相应爬取任务。
3、基本思路:
1) 通过模拟浏览器翻页(涉及模拟点击翻页问题),获取每个分页中待爬取页面的url(涉及数据加载问题),将url列表存入文件;
2) 针对每一个url进行普通的爬取。
4、待爬取页面分析:
举例:爬取某网站中所有子话题的内容。
1)子话题都在ul[@class="post-list"]标签下,xpath可以写成li[@class],表示所有具备class属性的li标签。
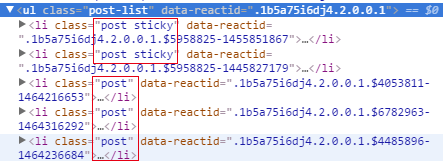
2)要想爬取所有页面,需要浏览器模拟点击右上角的“下一页”标签(<li>)。具体分析页面代码后发现,最后一页的“下一页”标签不可点击,可以作为停止获取url列表的标志。
最后一页的“下一页”标签:<liclass="pg_next pg_empty"data-reactid="XX"></li>
其余的“下一页”标签:<liclass="pg_next"data-reactid="XX"></li>
next_page = response.xpath('//ul[@class="pg1"]/li[@class="pg_next"]')
5、Spider代码:
# -*- coding: utf-8 -*-
import scrapy
import time
import base64
from selenium import webdriver
from selenium.webdriver.support.ui importWebDriverWait
from buluo.items import BuluoItem
class buluoSpider(scrapy.Spider):
name = 'buluo_spider'
def __init__(self, bid = None): #示例:bid = 12339
"""初始化起始页面和游戏bid
"""
super(buluoSpider, self).__init__()
self.bid = bid #参数bid由此传入
self.start_urls = ['http://buluo.qq.com/p/barindex.html?bid=%s' % bid]
self.allowed_domain = 'buluo.qq.com'
self.driver = webdriver.Firefox()
self.driver.set_page_load_timeout(5) #throw a TimeoutException when thepage load time is more than 5 seconds.
def parse(self, response):
"""模拟浏览器实现翻页,并解析每一个话题列表页的url_list
"""
url_set = set() #话题url的集合
self.driver.get(response.url)
while True:
wait = WebDriverWait(self.driver, 2)
wait.until(lambda driver:driver.find_element_by_xpath('//ul[@class="post-list"]/li[@class]/a'))#VIP,内容加载完成后爬取
sel_list = self.driver.find_elements_by_xpath('//ul[@class="post-list"]/li[@class]/a')
url_list = [sel.get_attribute("href") for sel in sel_list]
url_set |= set(url_list)
try:
wait =WebDriverWait(self.driver, 2)
wait.until(lambda driver:driver.find_element_by_xpath('//ul[@class="pg1"]/li[@class="pg_next"]'))#VIP,内容加载完成后爬取
next_page =self.driver.find_element_by_xpath('//ul[@class="pg1"]/li[@class="pg_next"]')
next_page.click() #模拟点击下一页
except:
print "#####Arrive thelast page.#####"
break
with open('url_set.txt', mode='w') as f:
f.write(repr(url_set))
for url in url_set:
yield scrapy.Request(url, callback=self.parse_content)
def parse_content(self, response):
"""提取话题页面内容,通过pipeline存入指定字段
"""
item = BuluoItem()
item['timestamp'] = time.strftime('%Y-%m-%d %H:%M:%S')
item['bid'] = self.bid
item['url'] = response.url
#item['content'] = response.body.decode('utf-8')
item['content'] = base64.b64encode(response.body) #编码为Base64的网页内容
yield item6、爬虫运行:
其余还需配置好settings.py、items.py和pipeline.py等文件,cmd中运行如下命令,即可根据游戏编号爬取想要的子话题内容:
scrapy crawl buluo_spider -a bid=12339
scrapy爬取动态分页内容的更多相关文章
- Scrapy 爬取动态页面
目前绝大多数的网站的页面都是冬天页面,动态页面中的部分内容是浏览器运行页面中的JavaScript 脚本动态生成的,爬取相对比较困难 先来看一个很简单的动态页面的例子,在浏览器中打开 http://q ...
- Python Scrapy环境配置教程+使用Scrapy爬取李毅吧内容
Python爬虫框架Scrapy Scrapy框架 1.Scrapy框架安装 直接通过这里安装scrapy会提示报错: error: Microsoft Visual C++ 14.0 is requ ...
- Scrapy 框架 使用 selenium 爬取动态加载内容
使用 selenium 爬取动态加载内容 开启中间件 DOWNLOADER_MIDDLEWARES = { 'wangyiPro.middlewares.WangyiproDownloaderMidd ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- Scrapy爬取美女图片第四集 突破反爬虫(上)
本周又和大家见面了,首先说一下我最近正在做和将要做的一些事情.(我的新书<Python爬虫开发与项目实战>出版了,大家可以看一下样章) 技术方面的事情:本次端午假期没有休息,正在使用fl ...
- 以豌豆荚为例,用 Scrapy 爬取分类多级页面
本文转载自以下网站:以豌豆荚为例,用 Scrapy 爬取分类多级页面 https://www.makcyun.top/web_scraping_withpython17.html 需要学习的地方: 1 ...
- scrapy爬取海量数据并保存在MongoDB和MySQL数据库中
前言 一般我们都会将数据爬取下来保存在临时文件或者控制台直接输出,但对于超大规模数据的快速读写,高并发场景的访问,用数据库管理无疑是不二之选.首先简单描述一下MySQL和MongoDB的区别:MySQ ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Scrapy爬取Ajax(异步加载)网页实例——简书付费连载
这两天学习了Scrapy爬虫框架的基本使用,练习的例子爬取的都是传统的直接加载完网页的内容,就想试试爬取用Ajax技术加载的网页. 这里以简书里的优选连载网页为例分享一下我的爬取过程. 网址为: ht ...
随机推荐
- 6月17 ThinkPHP连接数据库------数据的修改及删除
1.数据修改操作 save() 实现数据修改,返回受影响的记录条数 具体有两种方式实现数据修改,与添加类似(数组.AR方式) 1.数组方式 a) $goods = D(“Goods” ...
- position属性的总结
static 默认.位置设置为 static 的元素,它始终会处于页面流给予的位置(static 元素会忽略任何 top.bottom.left 或 right 声明). relative 位置被设置 ...
- UI基础六:UI报弹窗确认
数据检查部分: IF gv_zzzcustmodeno1 <> gv_zzzcustmodeno2 AND gv_plg_name NE 'YES'. lv_title = 'Confir ...
- java前后向查找个人理解
举一个最简单的栗子 这个前后说的是0宽所在的位置,是在:前还是后 http://www.sb.com 1.前向正向查找 (1) 如果用:.*(?=:) 首先(?=:)被称作0宽度断言,所谓0宽度应该是 ...
- MySQL5.6复制技术(4)-MySQL主从复制过滤参数
复制的过滤主要有2种方式: 在主服务器在把事件从进二制日志中过滤掉,相关的参数是:binlog_do_db和binlog_ignore_db. 在从服务器上把事件从中继日志中过滤掉,相关的参数是re ...
- Redis 系列之CentOS下Redis的安装
前言 安装Redis需要知道自己需要哪个版本,有针对性的安装,比如如果需要redis GEO这个地理集合的特性,那么redis版本就不能低于3.2版本,由于这个特性是3.2版本才有的.另外需要注意的是 ...
- Nop 4.1版本已经迁移到.net core2.1版本
1. github 下载,4.1版本,运行, install时,会让你新增后台账户密码,sql服务器 2. 在Configuration 新增Language 3. 上传中文语言包 , 你也可以先导出 ...
- 常用的flex知识 ,比起float position 好用不少
flex布局具有便捷.灵活的特点,熟练的运用flex布局能解决大部分布局问题,这里对一些常用布局场景做一些总结. web页面布局(topbar + main + footbar) 示例代码 要 ...
- mac nginx+php-fpm配置(安装过后nginx后访问php文件下载,访问php文件请求200显示空白页面)
访问php文件下载是因为没配置php-fpm 两个问题主要都是nginx.conf配置的问题: /usr/local/etc/nginx/nginx.conf server { listen 8 ...
- 【Java算法】输入一行字符,分别统计出其中英文字母、空格、数字和其它字符的个数
import java.util.Scanner; public class CountZimuShuzi { public static void main(String[] args) { Sys ...