Python 数据结构 链表
什么是时间复杂度
时间频度:一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才知道。但是我们不可能也没有必要对每一个算法都进行上机测试,只需要知道那个算法花费的时间多,那个算法花费得到时间少就可以了。并且一个算法花费的时间与算法中语句 的执行次数成正比。那个算法的语句执行次数多,他花费的时间就多,一个算法中的语句的执行次数成为语句的频度或时间频度,记为T(n)。
时间复杂度:在刚才提到是时间频度中,n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化,但有时我们想知道它的变化呈现什么规律,为此,引入时间复杂度的概念。一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数,记作T(n)= O(f(n)),称O(f(n))为算法的渐进时间复杂度,简称为时间复杂度。
常见的算法时间复杂度由小到大排序:Ο(1)<Ο(log2n)<Ο(n)<Ο(nlog2n)<Ο(n2)<Ο(n3)<…<Ο(2n)<Ο(n!)
一般情况下,对一个问题(或一类算法)只需选择一种基本操作来讨论算法的时间复杂度即可,有时也需要同时考虑几种基本操作,甚至可以对不同的操作赋予不同的权值,以反映执行不同操作所需的相对时间,这种做法便于综合比较解决同一问题的两种完全不同的算法。
求解算法的时间复杂度的具体步骤是:
⑴ 找出算法中的基本语句;
算法中执行次数最多的那条语句就是基本语句,通常是最内层循环的循环体。
⑵ 计算基本语句的执行次数的数量级;
只需计算基本语句执行次数的数量级,这就意味着只要保证基本语句执行次数的函数中的最高次幂正确即可,可以忽略所有低次幂和最高次幂的系数。这样能够简化算法分析,并且使注意力集中在最重要的一点上:增长率。
⑶ 用大Ο记号表示算法的时间性能。
将基本语句执行次数的数量级放入大Ο记号中。
如果算法中包含嵌套的循环,则基本语句通常是最内层的循环体,如果算法中包含并列的循环,则将并列循环的时间复杂度相加
# 时间复杂度是O(10)
for i in range(10):
print(i)
# 时间复杂度是O(10*10)
for i in range(10):
for j in range(10):
print(j)
# 一起的时间复杂度是 O(10)+O(10*10)
什么是链表
链表是一种常见的基础数据结构,但是不会线性的顺序存储数据,而是每一个节点里存储下一个节点的指针(Pointer),由于不必按照顺序存储,链表在插入的时候可以达到O(1)的复杂度,比起另一种线性表顺序快得多,但是查找一个节点或者访问特定编号的节点则需要O(n),的时间,而顺序表相应的时间复杂度分别是O(n)和O(1)。
链表的特点
使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理,但是链表失去了数组随机读取的优点,同时链表由于增加了节点的指针域,空间开销比较大。
链表的基本结构
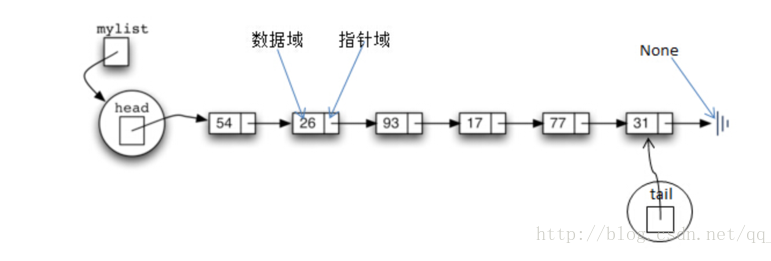
链表的种类


python 实现单链表
class Node(object):
def __init__(self, data, pnext=None):
# 初始化节点
self.data = data
self.next = pnext def __repr__(self):
# 打印节点信息
return str(self.data) class LinkList(object):
def __init__(self):
self.length = 0
self.head = None def is_empty(self):
# 判断是否为空
return self.length == 0 def append(self, data_or_node):
# 尾插 # 判断参数信息
if isinstance(data_or_node, Node):
item = data_or_node
else:
item = Node(data_or_node) if not self.head:
# 头指针为空
self.head = item
self.length += 1
else:
# 指向头指针所指地址
node = self.head
while node._next:
node = node._next
node._next = item
self.length += 1 def insert(self, value, index):
# 插入节点
if type(index) is int:
if index > self.length or index < 0:
print("index is out of index")
return
else:
if index == 0:
self.head = Node(value, self.head)
else:
current_node = self.head
while index-1:
current_node = current_node.next
index -= 1
i_node = Node(value, current_node.next)
current_node.next = i_node
self.length += 1
return
else:
print("Index is invaliable") def delete(self, index):
# 删除索引位置结点
if type(index) is int:
if index >= self.length or index < 0:
print("index is out of index")
return
else:
if 0 == index:
self.head = self.head.next
else:
node = self.head
while index-1:
node = node.next
index -= 1
node.next = node.next.next
self.length -= 1
return
else:
print("Index is not int") def update(self, value, index):
# 更新结点
if type(index) is int:
if index >= self.length or index < 0:
print("index is out of index")
return
else:
node = self.head
while index:
node = node.next
index -= 1
node.data = value
return
else:
return def get_value(self, index):
# 获取结点value
if type(index) is int:
if index >= self.length or index < 0:
print("index is out of index")
return
else:
node = self.head
while index:
node = node.next
index -= 1
return node.data
else:
return def get_length(self):
# 获取长度
node = self.head
length = 0
while node:
length += 1
node = node.next
print("length is ", length)
print("self.length is ", self.length) def clear(self):
# 清空链表
self.head = None
self.length = 0
print("Clear!") def print_list(self):
# 打印链表
if self.is_empty():
print("Link is empty")
else:
node = self.head
while node:
print node.data, "-->",
node = node.next
if __name__ == '__main__':
l = LinkList()
ele = Node(2)
l.append(ele)
l.insert(1,1)
l.insert(2,2)
l.insert(3,2)
# print l.get_value(2)
print l.print_list()
Python 数据结构 链表的更多相关文章
- Python—数据结构——链表
数据结构——链表 一.简介 链表是一种物理存储上非连续,数据元素的逻辑顺序通过链表中的指针链接次序,实现的一种线性存储结构.由一系列节点组成的元素集合.每个节点包含两部分,数据域item和指向下一个节 ...
- python数据结构链表之单向链表
单向链表 单向链表也叫单链表,是链表中最简单的一种形式,它的每个节点包含两个域,一个信息域(元素域)和一个链接域.这个链接指向链表中的下一个节点,而最后一个节点的链接域则指向一个空值. 表元素域ele ...
- Python数据结构--链表
class Node(): def __init__(self, dataval=None): self.dataval = dataval self.nextval = None class SLi ...
- Python数据结构——链表的实现
链表由一系列不必在内存中相连的结构构成,这些对象按线性顺序排序.每个结构含有表元素和指向后继元素的指针.最后一个单元的指针指向NULL.为了方便链表的删除与插入操作,可以为链表添加一个表头. 删除操作 ...
- python数据结构与算法——链表
具体的数据结构可以参考下面的这两篇博客: python 数据结构之单链表的实现: http://www.cnblogs.com/yupeng/p/3413763.html python 数据结构之双向 ...
- Python数据结构之单链表
Python数据结构之单链表 单链表有后继结点,无前继结点. 以下实现: 创建单链表 打印单链表 获取单链表的长度 判断单链表是否为空 在单链表后插入数据 获取单链表指定位置的数据 获取单链表指定元素 ...
- python数据结构之链表(一)
数据结构是计算机科学必须掌握的一门学问,之前很多的教材都是用C语言实现链表,因为c有指针,可以很方便的控制内存,很方便就实现链表,其他的语言,则没那么方便,有很多都是用模拟链表,不过这次,我不是用模拟 ...
- python数据结构与算法
最近忙着准备各种笔试的东西,主要看什么数据结构啊,算法啦,balahbalah啊,以前一直就没看过这些,就挑了本简单的<啊哈算法>入门,不过里面的数据结构和算法都是用C语言写的,而自己对p ...
- 算法之python创建链表实现cache
算法之python创建链表实现cache 本节内容 问题由来 解决思路 实现代码 总结 1. 问题由来 问题起因于朋友的一次面试题,面试公司直接给出两道题,要求四十八小时之内做出来,语言不限,做出来之 ...
随机推荐
- day_6.20动态加载py文件
__import__() 魔法方法! 关于动态网站打开的 代码流程!
- java内存溢出总结(1.8)
堆溢出 原因:老年代没有足够的空间存放即将进入老年代对象(或者没有连续的空间存下某个大对象),1.多次gc没有回收的对象 2. ygc后,s区满了,多余的对象直接进入老年代,3.大对象直接进入老年代 ...
- 将数据 导出excel表格式
我的考试完提交生成的数据 这是我的考试题类型 //导出调查评议的数据 public function diaocha(){ $xlsName = '表格形式 调查评议 信息'; $xlsTitle = ...
- vins-mono源码解读
https://blog.csdn.net/q597967420/article/details/76099409
- pygme 安装
输入pip install pygame-1.9.3-cp36-cp36m-win32.whl ModuleNotFoundError: No module named 'requests' pip ...
- 分区实践 注意分区名 p2018-01 p2018-02 被解释为同一分区名
# https://dev.mysql.com/doc/refman/5.6/en/partitioning-columns-range.html'''CREATE TABLE employees ( ...
- Java基础知识之集合
Collection集合 特点:长度可变,只能存储引用类型,可以存储不同的类型的元素 list 特点:元素有序(存储和取出的顺序一致),元素可以重复.list除了可以用迭代器循环遍历之外,因为其是有序 ...
- js面向对象、创建对象的工厂模式、构造函数模式、原型链模式
JS面向对象编程(转载) 什么是面向对象编程(OOP)?用对象的思想去写代码,就是面向对象编程. 面向对象编程的特点 抽象:抓住核心问题 封装:只能通过对象来访问方法 继承:从已有对象上继承出新的对象 ...
- Orchard Core 模块化
在上一篇文章谈到如何搭好一个基础的Orchard Core项目. 今天要尝试Orchard Core的模块化. 我自己的理解:一个系统可以分成一个个模块,这一个个模块是由一个个类库去实现的. 首先,在 ...
- es分布式文档系统_bulk api的奇特json格式与底层性能优化关系
1.bulk api奇特的json格式{"action":{"meta"}}\n{"data"}\n{"action": ...