Scrapy终端(Scrapy shell)
1.介绍文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/topics/shell.html#
2.终端的启用方式:scrapy shell url
url 即为你要爬取的网站
3.使用scrapy shell遇到的问题

当用scrapy shell访问如上图的链接时,报出如下错误:
DEBUG: Crawled (504) <GET http://wz.sun0769.com/index.php/question/questionType?type=4> (referer: None) ['partial']
最终发现问题的根源是user-agent:我们在使用scrapy shell进行爬虫调试的时候,user-agent的配置在默认的全局设置中
全局默认值位于scrapy.settings.default_settings 模块中,如下图:

解决方案1:将default_settings.py中的USER_AGENT修改为任意一个浏览器的user-agent
解决方案2:我们在终端输入scrapy shell --help有可以看到有一个选项为-s即为在启动爬虫的时候对默认的default_settings文件
中的设置项进行覆盖;
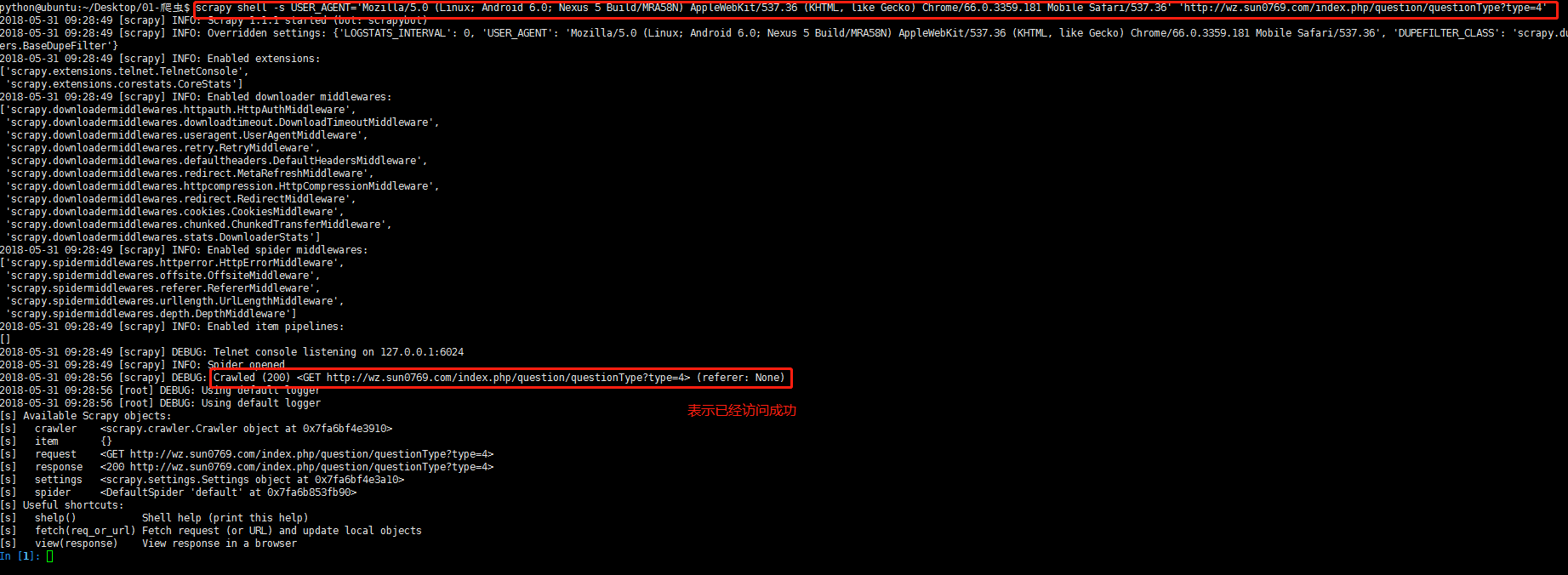
在终端键入:scrapy shell -s USER_AGENT='Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Mobile Safari/537.36' 'http://wz.sun0769.com/index.php/question/questionType?type=4',问题即看得到解决。
应该注意的是 USER_AGENT的等号不能有空格
Scrapy终端(Scrapy shell)的更多相关文章
- python爬虫scrapy之scrapy终端(Scrapy shell)
Scrapy终端是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码. 其本意是用来测试提取数据的代码,不过您可以将其作为正常的Python终端,在上面测试任何的Python代码. ...
- 爬虫:Scrapy7 - Scrapy终端(Scrapy shell)
Scrapy 终端是一个交互终端,可以在未启动 spider 的情况下尝试及调试你的爬取代码.其本意是用来测试提取数据的代码,不过可以将其作为正常的 Python 终端,在上面测试任何 Python ...
- Scrapy之Scrapy shell
Scrapy Shell Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据 ...
- scrapy框架之shell
scrapy shell scrapy shell是一个交互式shell,您可以在其中快速调试 scrape 代码,而不必运行spider.它本来是用来测试数据提取代码的,但实际上您可以使用它来测试任 ...
- Scrapy 常用的shell执行命令
1.在任意系统下,可以使用 pip 安装 Scrapy pip install scrapy/ 确认安装成功 >>> import scrapy >>> scrap ...
- 第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令 Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --u ...
- 十 web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --upgrade pip2.安装,wheel(建议网络安装) pip install wheel ...
- <scrapy爬虫>scrapy命令行操作
1.mysql数据库 2.mongoDB数据库 3.redis数据库 1.创建项目 scrapy startproject myproject cd myproject 2.创建爬虫 scrapy g ...
- Linux终端执行shell脚本,提示权限不够的解决办法
原文:http://blog.csdn.net/this_capslock/article/details/17415409 今天在Linux尝试搭建dynamips的工作环境,在执行shell脚本时 ...
- scrapy - 给scrapy 的spider 传值
scrapy - 给scrapy 的spider 传值 方法一: 在命令行用crawl控制spider爬取的时候,加上-a选项,例如: scrapy crawl myspider -a categor ...
随机推荐
- qt 两种按钮点击事件应用
1.传统connect 例如: connect(ui->findPushBtn,SIGNAL(clicked()),this,SLOT(find())); 参数1:事件UI 参数2:点击系统函数 ...
- MSF魔鬼训练营-3.1.2信息收集-通过搜索引擎进行信息搜集
1.Google hacking 技术 自动化的Google搜索工具 SiteDigger https://www.mcafee.com/us/downloads/free-tools/sitedig ...
- linux查看cd/dvd驱动器的设备信息
在linux下,如何来查看系统里的CD-ROM或者DVD驱动器的设备名呢? 你可以输入下面的命令来查看当前系统下的光盘驱动器信息: 1.使用dmesg命令来查看当前的硬件是否被linux内核正确的识别 ...
- 什么是SQL注入以及mybatis中#{}为什么能防止SQL注入而${}为什么不能防止SQL注入
1.什么是SQL注入 答:SQL注入是通过把SQL命令插入到web表单提交或通过页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL指令. 注入攻击的本质是把用户输入的数据当做代码执行. 举例如: ...
- bind函数作用、应用场景以及模拟实现
bind函数 bind 函数挂在 Function 的原型上 Function.prototype.bind 创建的函数都可以直接调用 bind,使用: function func(){ consol ...
- day 03 int bool str (索引,切片) for 循环
基础数类型总览 10203 123 3340 int +- * / 等等 '今天吃了没?' str 存储少量的数据,+ *int 切片, 其他操作方法 True False bool 判断真假 [12 ...
- KVM安装配置笔记
系统环境centos6.6 一.KVM安装前系统相关操作: (1)修改内核模式为兼容内核启动 # grep -v "#" /etc/grub.confdevice (hd0) HD ...
- 2019-11-29-VisualStudio-解决方案筛选器-slnf-文件
title author date CreateTime categories VisualStudio 解决方案筛选器 slnf 文件 lindexi 2019-11-29 08:41:13 +08 ...
- 阅读脚本控制pwm代码
在现有的项目上通过SoC的EHRPWM3B管脚产生PWM脉冲做为摄像头的framsync信号. datasheet描述: PWMSS:PWM Subsystem Resources eHRPWM: E ...
- php随机获取数组里面的值
srand() 函数播下随机数发生器种子,array_rand() 函数从数组中随机选出一个或多个元素,并返回.第二个参数用来确定要选出几个元素.如果选出的元素不止一个,则返回包含随机键名的数组,否则 ...