FacertGrid()的使用
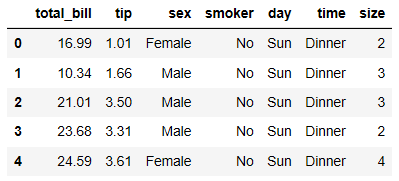
查看数据的前五行
tips = sns.load_dataset("tips")
tips.head()
引入数据,布置横向画布
g = sns.FacetGrid(tips, col='time')
g = sns.FacetGrid(tips, col='time')
g.map(plt.hist, "tip") #以tip为横轴画柱状图

g = sns.FacetGrid(tips, col="sex", hue="smoker")
g.map(plt.scatter, "total_bill", "tip", alpha=.7) #绘制散点图,设置横纵轴,设置透明度
g.add_legend() #加上如下图标注的图例

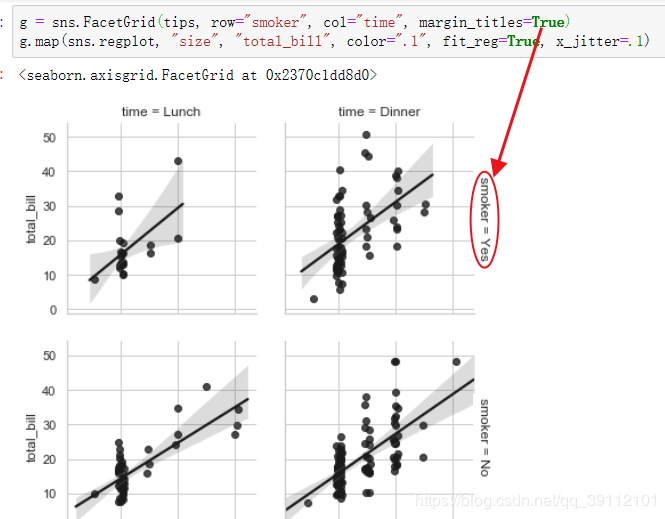
g = sns.FacetGrid(tips, row="smoker", col="time", margin_titles=True) #设置行列布局方式
g.map(sns.regplot, "size", "total_bill", color=".1", fit_reg=True, x_jitter=.1) #fit_reg画出回归线,x_jitter为摆动程度
画出柱形图
g = sns.FacetGrid(tips, col="day", size=4, aspect=.5)
g.map(sns.barplot, "sex", "total_bill")

from pandas import Categorical
ordered_days = tips.day.value_counts().index
print(ordered_days)
查看day的排列顺序
CategoricalIndex(['Sat', 'Sun', 'Thur', 'Fri'], categories=['Thur', 'Fri', 'Sat', 'Sun'], ordered=False, dtype='category')
重新设置行的排列顺序
ordered_days = Categorical(["Thur", "Sun", "Fri", "Sat"])
g = sns.FacetGrid(tips, row="day", row_order=ordered_days, size=1.7, aspect=4)
g.map(sns.boxplot, "total_bill")

(盒图能够自动识别哪个变量是离散型,哪个是连续型,然后对连续型构造盒图。)
例如以下代码
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib as mpl
from pandas import Categorical
import matplotlib.pyplot as plt tips = sns.load_dataset("tips") #seaborn内置数据集,DaraFram类型
print(tips.head())
ordered_days = Categorical(["Thur", "Sun", "Fri", "Sat"])
print(type(ordered_days))
print(ordered_days)
g = sns.FacetGrid(tips, row="day", row_order=ordered_days, size=1.7, aspect=4)
g.map(sns.boxplot, "total_bill", "sex") plt.show()
运行结果如下,函数识别出sex是离散型变量,所以对sex进行分类,然后在每一个类别上对连续型变量total_bill构造盒图。

还可以用FacertGrid的palette参数给hue的列的不同类设置不同颜色,代码如下
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib as mpl
from pandas import Categorical
import matplotlib.pyplot as plt tips = sns.load_dataset("tips") #seaborn内置数据集,DaraFram类型
print(tips.head())
pal = dict(Lunch="seagreen", Dinner="gray")
g = sns.FacetGrid(data=tips, hue="time", palette=pal, size=5)
g.map(plt.scatter, "total_bill", "tip", s=50, alpha=0.7, linewidths=0.5, edgecolors="white")
g.add_legend()
plt.show()
运行结果如下

如果再设置marker参数,可指定用什么图标画散点,可以是三角形或圆形等
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib as mpl
from pandas import Categorical
import matplotlib.pyplot as plt tips = sns.load_dataset("tips") #seaborn内置数据集,DaraFram类型
print(tips.head())
pal = dict(Lunch="seagreen", Dinner="gray")
g = sns.FacetGrid(data=tips, hue="time", palette=pal, size=5, hue_kws={"marker":['^', 'v']})
g.map(plt.scatter, "total_bill", "tip", s=50, alpha=0.7, linewidths=0.5, edgecolors="white")
g.add_legend()
plt.show()

还有一些小调整:set_axis_labels()函数可以自定义x和y轴名字,set(xticks, yticks)可以自定义x和y轴的刻度。fig.subplots_adjust()函数可以调整子图之间
的间隔和距离边框的大小。edgecolors可以设置散点周围的边缘颜色。
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib as mpl
from pandas import Categorical
import matplotlib.pyplot as plt tips = sns.load_dataset("tips") #seaborn内置数据集,DaraFram类型
print(tips.head())
with sns.axes_style("white"):
g = sns.FacetGrid(tips, row="sex", col="smoker", margin_titles=True, size=2.5)
g.map(plt.scatter, "total_bill", "tip", color="#334488", edgecolors="white", lw=0.5)
g.set_axis_labels("Total_bill", "Tip")
g.set(xticks=[10, 30, 50], yticks=[2, 6, 10])
g.fig.subplots_adjust(wspace=0.25, hspace=0.25)
plt.show()

可以用PairGrid对数据中的列进行两两配对绘制散点图,当然也可以指定要配对的列。
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib as mpl
from pandas import Categorical
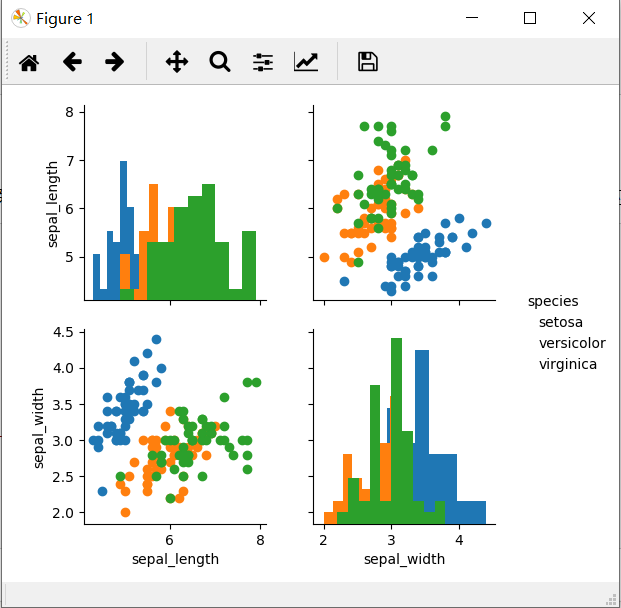
import matplotlib.pyplot as plt iris = sns.load_dataset("iris")
g = sns.PairGrid(data=iris, vars=["sepal_length", "sepal_width"], hue="species")
g.add_legend()
g.map_offdiag(plt.scatter)
g.map_diag(plt.hist)
plt.show()
函数PairGrid()中的vars参数指定要两两进行绘图的列,这些列是数据集的子列。map_offdiag和map_diag分别设置非对角的和对角的图使用的统计图类型。
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib as mpl
from pandas import Categorical
import matplotlib.pyplot as plt iris = sns.load_dataset("iris")
g = sns.PairGrid(data=iris, vars=["sepal_length", "sepal_width"], hue="species")
g.add_legend()
g.map_offdiag(plt.scatter)
g.map_diag(plt.hist)
plt.show()
FacertGrid()的使用的更多相关文章
随机推荐
- discuz论坛后台部分设置更改之后,清除了缓存网站前台不更新不生效的解决办法
discuz论坛后台部分设置更改之后,清除了缓存但网站前台不更新不生效的解决办法 在config/config_global.php 把 $_config['memory']['eaccelera ...
- AI换脸教程:DeepFaceLab使用教程(2.训练及合成)
如果前期工作已经准备完毕(DeepFaceLab下载(https://www.deepfacelabs.com/list-5-1.html),然后安装相应的显卡驱动,DeepFaceLab使用教程(1 ...
- Codeforces Round #593 (Div. 2) C. Labs A. Stones
题目:https://codeforces.com/contest/1236/problem/A 思路:两种操作收益都是3 且都会消耗b 操作2对b消耗较小 则可优先选择操作2 再进行操作1 即可得到 ...
- java ArrayList迭代过程中删除
第一种迭代删除方式: 第二种迭代删除方式: 第三种迭代删除: 第四种迭代删除: 第五种迭代删除: 第六种: ArrayList中remove()方法的机制,首先看源码: 真正的删除操作在fastRem ...
- SpringMVC @CookieValue注解
@CookieValue的作用 用来获取Cookie中的值 @CookieValue参数 1.value:参数名称 2.required:是否必须 3.defaultValue:默认值 @Cookie ...
- Android 在 4G 下访问 IPV6 慢的解决方案
Android 在 4G 下访问 IPV6 慢的解决方案 Android4G ipv6 起因 今天,用户反馈 Android 端加载数据较慢,经 Android 开发人员排查后,发现在公司 wifi ...
- Python修炼之路-异常
异常处理 在程序出现bug时一般不会将错误信息直接显示给用户,而是可以自定义显示内容或处理. 常见异常 AttributeError # 试图访问一个对象没有的树形,比如foo.x,但是foo没有属性 ...
- java 乱码
https://blog.csdn.net/qq_27545063/article/details/81138722 https://blog.csdn.net/dachaoa/article/det ...
- Linux 安装Samba服务器
1. 服务器 安装软件: yum -y install samba 创建共享目录并更改目录权限: mkdir -p /home/lee/samba chmod -R 0777 /home/lee/sa ...
- 最全的WEB前端开发程序员学习清单
史上最全的WEB前端开发程序员学习清单! 今天为什么要给大家分享这篇文章呢,我发现最近来学前端的特别多,群里面整天都有人问:前端好找工作吗?前端要怎么学啊?前端工资怎么样?前端XX,前端XXX,虽然我 ...