【HBase】二、HBase实现原理及系统架构
整个Hadoop生态中大量使用了master-slave的主从式架构,如同HDFS中的namenode和datanode,MapReduce中的JobTracker和TaskTracker,YARN中的资源管理器和节点管理器,Zookeeper中的leader和follower。我们将看到HBase同样是基于这种主从式的一种运行机制。
1、HBase实现原理
正如前面所说,HBase将表水平分裂为区域,集群中的每个节点管理若干个区域,区域是HBase集群上分布数据的最小单位,因此存储数据的节点就构成了一个个的区域服务器,叫做RegionServer。
在HBase中,同样采用了主从式的架构,用一个master节点协调管理多个RegionServer从属机,主控机负责启动安装,将区域分配给注册的RegionServer,恢复RegionServer的故障,管理和维护HBase表的分区信息,master 的负载很轻。而区域服务器RegionServer负责存储和维护分配给自己的Region,响应客户端的读写请求。
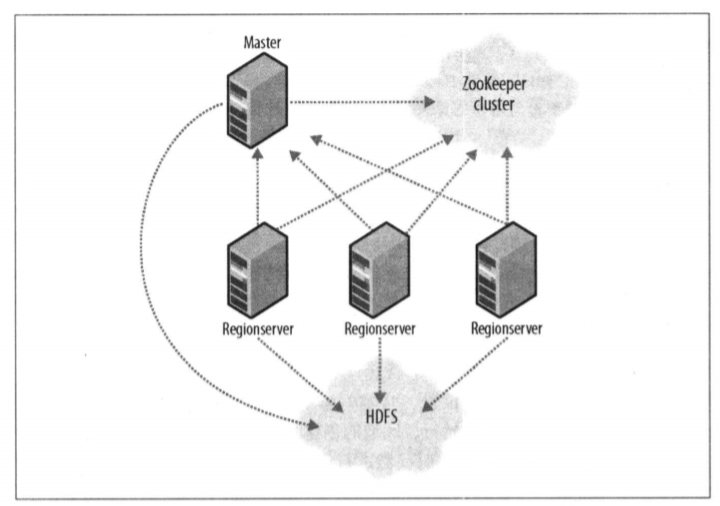
客户端并不是直接从Master主服务器上读取数据,而是在获得Region的存储位置信息后,直接从Region服务器上读取数据,因此主控机的负载很轻。
那么这里我们需要理清的一个重要问题就是如何定位区域在哪个服务器上,即Region的定位问题。
【Region是如何定位的?】
在HBase内部维护了一张名为hbase:meta的特殊目录表,这张表记录了当前集群上所有区域的列表、状态和位置,这张表的行键是区域名,即meta表的结构是:<区域名,位置,状态>,而区域名是由所属表名,区域的起始行,创建时间以及对前三者进行MD5哈希之后的结果共同组成的。
如表TestTable中起始行为xyz的区域的名称是:TestTable,xyz,1279729913622,1b6e176fb8.........(哈希值)
有了meta这张表,表是根据行键排序的,所以要查询某一行只需要与行键进行比较,即可得到对应的区域,进而得到对应的位置,然后直接到那个服务器上去读取数据。
更进一步,我们考虑这样的问题:meta表保存着所以区域的位置信息,因此这张表是很重要的,而且当数据量很大,区域很多时,这张表也可能大到一个区域无法保存,因此HBase实际上是有一个三层结构来完成区域定位的。
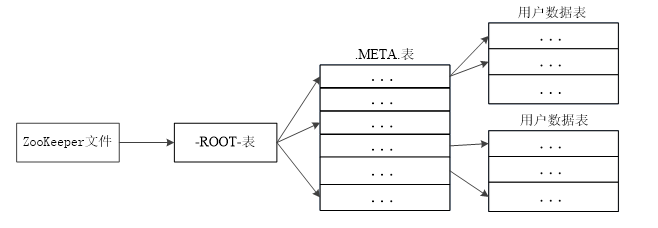
理解这个三层结构可以类别文件系统的多级索引机制,首先在Zookeeper中用一个文件保存Root表的位置,Root表中记录meta表的区域位置信息,meta表中记录数据的区域位置。
| 层次 | 名称 | 作用 |
|---|---|---|
| 第一层 | Zookeeper文件 | 记录了-ROOT-表的位置信息 |
| 第二层 | -ROOT-表 | 记录了.META.表的Region位置信息 -ROOT-表只能有一个Region通过-ROOT-表,就可以访问.META.表中的数据 |
| 第三层 | .META.表 | 记录了用户数据表的Region位置信息,.META.表可以有多个Region,保存了HBase中所有用户数据表的Region位置信息 |
至此,我们就可以完全理解HBase的运行机制了,客户端首先连接到Zookeeper集群,进而通过三级索引查找到hbase:meta表的位置,通过查meta表就可以获取数据区域所在的节点及位置,然后直接和管理那个区域的regionServer交互,进行数据的读写。
总结起来,我们可以看到每个行操作可能需要三次远程访问,一次是连接Root所在节点,一次是连接meta所在节点,还有一次是连接需要的RegionServer,为了节省这些开销,客户端可以通过缓存来存储之前访问meta表得到的信息,这样,后续可以现在缓存中查找,节省多次远程访问的开销。
2、HBase系统架构
实际上通过前面的实现原理,我们对HBase已经基本了解,再来从整体的角度理解其系统的架构。
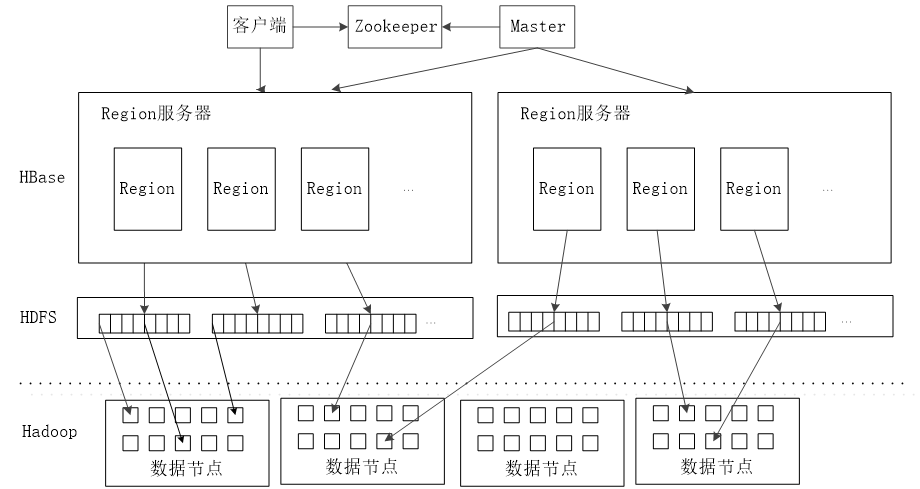
如图所示,HBase的整体系统架构如图所示,其中包含了客户端、Zookeeper、Master、RegionServer、HDFS这些基本实体。我们来做一个总结:
客户端:客户端包含访问HBase的接口,同时在缓存中维护着已经访问过的Region位置信息,用来加快后续数据访问过程。
Zookeeper服务器:HBase依赖于Zookeeper,它管理一个Zookeeper实例,作为集群的权威机构,之前我们看到root表的位置信息保存在Zookeeper服务器上,客户端通过Zookeeper才可以得到meta目录表的位置以及主控机的地址等信息,也就是说Zookeeper是整个HBase集群的注册机构,另外,Zookeeper可以帮助选举出一个Master作为集群的总管,并保证在任何时刻总有唯一一个Master在运行,这就避免了Master的“单点失效”问题。
主控机Master:主服务器Master主要负责表和Region的管理工作:管理用户对表的增加、删除、修改、查询等操作、实现不同Region服务器之间的负载均衡、在Region分裂或合并后,负责重新调整Region的分布、对发生故障失效的Region服务器上的Region进行迁移等。
Region服务器:Region服务器是HBase中最核心的模块,负责维护分配给自己的Region,并响应用户的读写请求。
HDFS:我们在一开始提到:HBase是基于HDFS开发的,也提到过一个列族的数据在磁盘上作为一个文件存储在一起,这里实际就是使用HDFS来持久化存储数据,是实际的数据存储的地方。
【HBase】二、HBase实现原理及系统架构的更多相关文章
- Android入门(二):Android的系统架构
android的系统架构和其操作系统一样,采用了分层的架构.从架构图看,android分为四个层,从高层到低层分别是应用程序层.应用程序框架层.系统运行库层和linux核心层. 从技术方面看,An ...
- 【Tomcat】Tomcat原理与系统架构
目录 版本: 一,目录说明 二,浏览器访问服务器的流程 三,Tomcat系统总体架构 3.1 Tomcat请求的大致流程 3.2 Servlet容器处理请求流程 3.3 Tomcat系统总体架构 四, ...
- 消息队列RabbitMQ(二):RabbitMQ的系统架构概述
前言 RabbitMQ是基于AMQP协议的,要想深入理解RabbitMQ,就必须先了解AMQP是个什么东东? AMQP协议 AMQP即Advanced Message Queuing Protocol ...
- 【Java进阶面试系列之一】哥们,你们的系统架构中为什么要引入消息中间件?
转: [Java进阶面试系列之一]哥们,你们的系统架构中为什么要引入消息中间件? **这篇文章开始,我们把消息中间件这块高频的面试题给大家说一下,也会涵盖一些MQ中间件常见的技术问题. 这里大家可以关 ...
- HBase 学习之路(二)—— HBase系统架构及数据结构
一.基本概念 一个典型的Hbase Table 表如下: 1.1 Row Key (行键) Row Key是用来检索记录的主键.想要访问HBase Table中的数据,只有以下三种方式: 通过指定的R ...
- HBase 系列(二)—— HBase 系统架构及数据结构
一.基本概念 一个典型的 Hbase Table 表如下: 1.1 Row Key (行键) Row Key 是用来检索记录的主键.想要访问 HBase Table 中的数据,只有以下三种方式: 通过 ...
- HBase 系统架构及数据结构
一.基本概念 2.1 Row Key (行键) 2.2 Column Family(列族) 2.3 Column Qualifier (列限定符) 2.4 Column ...
- Hbase 系统架构(zhuan)
一.系统架构 客户端连接hbase依赖于zookeeper,hbase存储依赖于hadoop client: 1.包含访问 hbase 的接口, client 维护着一些 cache(缓存) 来加快对 ...
- 列式存储hbase系统架构学习
一.Hbase简介 HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java.它是Apache软件基金会的Hadoop项目的一部分,运行 ...
随机推荐
- Prism MVVM使用WPF的DataGrid控件
此项目源码下载地址:https://github.com/lizhiqiang0204/PrismDataGird01 运行效果如下 前端代码如下 <Window x:Class="V ...
- 解决input 中placeholder的那些神坑
**昨天后台小哥哥提到placehold无法显示问题,我这边总结一下,顺便写个小文章分享给大家..** ============================================== 一 ...
- 【Linux】CentOS6上redis安装
1.官网下载安装包 https://redis.io 2.解压 tar -zxvf xxxx.tar.gz 3.编译安装 进入解压后的目录后 make 出现以下内容表示make成功 Hint: It' ...
- shiro框架学习-3- Shiro内置realm
1. shiro默认自带的realm和常见使用方法 realm作用:Shiro 从 Realm 获取安全数据 默认自带的realm:idae查看realm继承关系,有默认实现和自定义继承的realm ...
- Python3 操作mysql数据库
python关于mysql的API--pymysql模块 pymsql是Python中操作MySQL的模块,其使用方法和py2的MySQLdb几乎相同. 模块安装 pip install pymysq ...
- js 页面 保持状态 的方法
A -> B 带参数进去B页面, 刷新B页面还 保持状态 单机下一页, 改变请求参数, A->B 不带参数进去B页面 (不存在)当前状态保存在cookies中, 刷新页面,判断cooki ...
- Linux培训教程 linux系统下分割大文件的方法
在linux中分割大文件,比如一个5gb日志文件,需要把它分成多个小文件,分割后以利于普通的文本编辑器读取. 有时,需要传输20gb的大文件,Linux培训 教程件到另一台服务器,也需要把它分割成多个 ...
- #383 Div1 Problem B Arpa's weak amphitheater.... (分组背包 && 并查集)
题意 : 有n个人,每个人都有颜值bi与体重wi.剧场的容量为W.有m条关系,xi与yi表示xi和yi是好朋友,在一个小组. 每个小组要么全部参加舞会,要么参加人数不能超过1人. 问保证总重量不超过W ...
- yum install ntp 报错:Error: Package: ntp-4.2.6p5-25.el7.centos.2.x86_64 (base)
redhat7 在安装ntp时报如下错误 Error: Package: ntp-4.2.6p5-25.el7.centos.2.x86_64 (base) Requires: ntpdate = 4 ...
- Java equals 和 hashCode 的这几个问题可以说明白吗?
前言 上一篇文章 如何妙用 Spring 数据绑定? ,灵魂追问 环节留下了一个有关 equals 和 hashcode 问题 .基础面试经常会碰到与之相关的问题,这不是一个复杂的问题,但很多朋友都苦 ...