【2019.3.20】NOI模拟赛
这里必须标记一下那个傻逼问题,再不解决我人就没了!
先放一个 $T3$ $20$ 分暴力
- #include<bits/stdc++.h>
- #define rep(i,x,y) for(int i=(x);i<=(y);++i)
- #define dwn(i,x,y) for(int i=(x);i>=(y);--i)
- #define rep_e(i,u) for(int i=hd[u];i;i=e[i].nxt)
- #define lc tr[o].l
- #define rc tr[o].r
- #define N 100003
- #define inf 2147483647
- using namespace std;
- inline int read(){
- int x=; bool f=; char c=getchar();
- for(;!isdigit(c);c=getchar()) if(c=='-') f=;
- for(; isdigit(c);c=getchar()) x=(x<<)+(x<<)+(c^'');
- if(f) return x;
- return -x;
- }
- int T1_ROOT=;
- int n,m,L1,R1,L2,R2,W,ans;
- struct edge{int u,v,w;}e[*];
- int cnt;
- inline bool cmp(edge a,edge b){return a.w<b.w;}
- struct Tree{int l,r,v;}tr[N*];
- int rt[N<<],tot[];
- inline int newNode(int x){return ++tot[x];}
- inline void pushdown(int o){
- if(tr[o].v){
- tr[lc].v+=tr[o].v, tr[rc].v+=tr[o].v;
- tr[o].v=;
- }
- }
- void add2(int &o,int l,int r){
- if(!o) o=newNode();
- if(L2<=l && r<=R2){tr[o].v+=W; return;}
- pushdown(o);
- int mid=(l+r)>>;
- if(L2<=mid) add2(lc,l,mid);
- if(R2>mid) add2(rc,mid+,r);
- }
- void add1(int &o,int l,int r){
- if(!o) o=newNode();
- //printf("%d %d %d %d %d\n",o,l,r,L1,R1);
- //system("pause");
- if(L1<=l && r<=R1){add2(rt[o],,n); return;}
- int mid=(l+r)>>;
- if(L1<=mid) add1(lc,l,mid);
- if(R1>mid) add1(rc,mid+,r);
- }
- int X,mat[][];
- void dfs2(int o,int l,int r){
- if(!o) return;
- if(l==r){mat[X][l]+=tr[o].v; return;}
- pushdown(o);
- int mid=(l+r)>>;
- dfs2(lc,l,mid);
- dfs2(rc,mid+,r);
- }
- void dfs1(int o,int l,int r){
- if(!o) return;
- rep(i,l,r) X=i, dfs2(rt[o],,n);
- if(l==r) return;
- int mid=(l+r)>>;
- dfs1(lc,l,mid);
- dfs1(rc,mid+,r);
- }
- /*
- struct SegTree{
- struct TREE{int l,r,v;}tr[N*90];
- int L,R,W,e[2001][2001];
- inline void pushdown(int o){
- if(tr[o].v){
- tr[lc].v+=tr[o].v, tr[rc].v+=tr[o].v;
- tr[o].v=0;
- }
- }
- void add(int &o,int l,int r){
- if(!o) o=newNode(1);
- if(L1<=l && r<=R1){tr[o].v+=W; return;}
- pushdown(o);
- int mid=(l+r)>>1;
- if(L1<=mid) add1(lc,l,mid);
- if(R1>mid) add1(rc,mid+1,r);
- }
- inline void add(int ver,int l,int r,int w){
- L=l, R=r, W=w; add(rt[ver],1,n);
- }
- }
- */
- int fa[N];
- int find(int x){return x==fa[x] ? x : fa[x]=find(fa[x]);}
- namespace pts20{
- void solve(){
- rep(i,,m)
- L1=read(), R1=read(), L2=read(), R2=read(), W=read(), add1(T1_ROOT,,n);
- dfs1(,,n);
- rep(i,,n)
- rep(j,i+,n)
- e[cnt++]=(edge){i,j,mat[i][j]};
- sort(e,e+cnt,cmp);
- rep(i,,n) fa[i]=i;
- int e_cnt;
- for(int i=;i<cnt;++i){
- int fu=find(e[i].u), fv=find(e[i].v);
- //printf("zuixiao:%d %d %d\n",e[i].u,e[i].v,e[i].w);
- if(fu==fv) continue;
- fa[fv]=fu;
- ans+=e[i].w;
- ++e_cnt;
- //printf("%d %d %d %d\n",e_cnt,n-1,i,cnt);
- if(e_cnt>=n-) break;
- }
- printf("%d\n",ans);
- }
- }
- using namespace pts20;
- /*
- int mn_o,mn_v;
- void queryMin(int o,int l,int r){
- if(!o) return;
- if(l==r){mn_o=o, mn_v=tr[o].mn; return;}
- int mid=(l+r)>>1;
- if(tr[lc].mn<=tr[rc].mn) queryMin(lc,l,mid);
- else queryMin(rc,mid+1,r);
- }
- int blo;
- */
- int main(){
- //freopen("C.in","r",stdin);
- //freopen("C.out","w",stdout);
- n=read(), m=read();
- tot[]=, tot[]=n<<;
- if(n<=) pts20::solve();
- return ;
- }
- /*
- 5 4
- 1 2 3 4 10
- 1 1 2 2 -20
- 3 3 4 4 -5
- 2 2 5 5 -15
- */
写了个树套树连边,标准输入输出随便过样例,真爽。
然而加了个文件读写,测样例就输出 $-20$ 了。
我都忘了这种问题是什么情况了,考后重新输出中间结果查了一遍,发现真是石乐志。
注意第 $104$ 行,局部变量没有赋初值。没文件读写就默认把初值弄成 $0$,有文件读写就给了个随机初值。
这个问题其实大多数人都会犯,但我是真的想不起来这种错误了,先立个 $flag$,下次再出这种问题查不出来的话我得吃点什么。
T1
30pts
没想
50pts
我们把区间看成竖直的,第 $i$ 个区间代替成平面直角坐标系中 从 $(i,L_i)$ 到 $(i,R_i)$ 的线段。问题就成了有多少种直线能穿过所有 $n$ 条线段。
考虑暴力求斜率的上下界,然后枚举斜率,再扫一遍 $n$ 条线段,把每条直线的上下端点按斜率映射到 $y$ 轴上,最后这种斜率的直线穿过所有 $n$ 条线段的方案数 上端点映射在 $y$ 轴上的最小值 $-$ 就是下端点映射在 $y$ 轴上的最大值(这里注意特判一下,如果前者小于后者,方案数应该为 $0$)。
由斜率上下界的计算方法(见代码)可知,时间复杂度大概是 $O(线段长度 / n\times n) = O(线段长度)$。
100pts
(下标从 $0$ 开始算)
对于一条直线,我们用一个二元组 $(a,d)$ 表示,它的意义是直线与 $x=0$ 的交点的纵坐标为 $a$,直线的斜率为 $d$ 。
那对于每条直线,若其满足条件,则要满足该约束:$a∈[-id+L_i,\space -id+R_i]$
也就是 $-id+L_i\le a\le -id+R_i$
它的解的数量是一个以 $d$ 为横坐标,以 $a$ 为纵坐标的二维平面中两条直线所夹的范围内的整点数。
然后总共有 $n$ 个约束,那么就有 $2\times n$ 条直线。
解的总数就是被所有对直线夹起来的那一部分 二维平面的整点数,从图上看,它就是最里面的那一块。
半平面交?差不多就是求这种东西。
画图举例。同色线条代表一组约束,那么半平面交的部分就是中间的灰色区域。我们要求那部分面积。
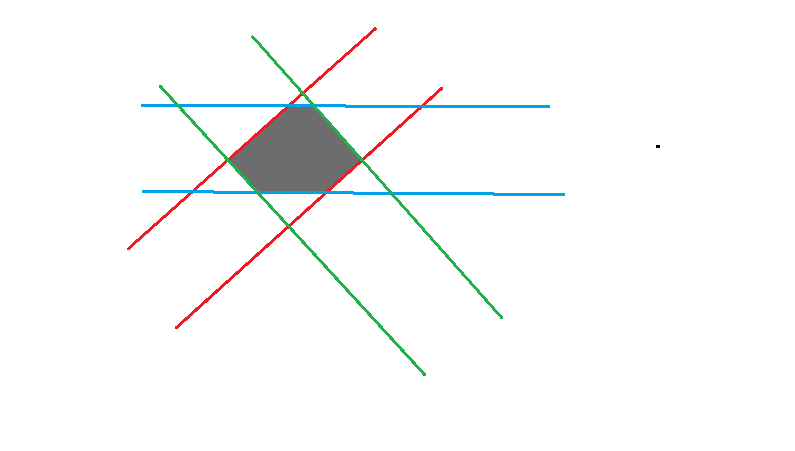
求半平面交应该并不好写,但这题有个特殊性质,就是直线是一对一对地放到平面上的,我们只要分别对所有上界直线和下界直线求凸包就可以了。
补充知识:维护凸包
以上凸包为例,把所有边按斜率 $k$ 从大到小排序,用一个单调队列维护当前认为的凸包边界。比如已经往单调队列中插入 $3$ 条边的情况如下(灰色区域为凸包内部):

插入第 $4$ 条直线(红线)时,判断单调队列最右端的两条直线的交点 与单调队列最右端一条直线与新插入的直线的交点 的横坐标,如果后者小于前者,就删掉单调队列最右端一条直线,并继续尝试往前删;否则将新插入的直线放在单调队列最右端。

结合画图可理解,因为后者小于前者时,新插入的直线与当前凸包最右边的直线的交点在凸包外,故新插入的之前在凸包范围内 会与当前凸包更靠左的直线相交(显然这样会缩小凸包),当前凸包最右边的直线就被排除到凸包外了,故删除。
下凸包同理。
求完上界的上凸包和下界的下凸包后,仔细思考一下,发现多边形无法直接计算面积,所以我们把凸包拆成若干个三角形和四边形,显然这两种图形都能计算面积。具体实现:用扫描线按横坐标从小到大扫凸包,每遇到凸包的一个拐点(不管拐点在上界还是下界),都计算一下凸包这一部分的三角形/梯形面积(具体地说就是计算点数)。

- #include<bits/stdc++.h>
- #define rep(i,x,y) for(int i=(x);i<=(y);++i)
- #define dwn(i,x,y) for(int i=(x);i>=(y);--i)
- #define rep_e(i,u) for(int i=hd[u];i;i=e[i].nxt)
- #define ll long long
- #define M 200020
- #define inf 100000010
- #define maxL -inf
- #define maxR inf
- using namespace std;
- inline int read(){
- int x=; bool f=; char c=getchar();
- for(;!isdigit(c);c=getchar()) if(c=='-') f=;
- for(; isdigit(c);c=getchar()) x=(x<<)+(x<<)+(c^'');
- if(f) return x;
- return -x;
- }
- int n,m,m1,m2;
- ll X[(M<<)+],c[][M],ans;
- struct line{
- ll k,b;
- line(){}
- line(ll _k,ll _b){k=_k,b=_b;}
- ll get(ll x){return k*x+b;}
- }mx[M],mn[M],s[][M];
- inline ll con(line &A,line &B){return (ll)ceil((double)(A.b-B.b)/(double)(B.k-A.k));}
- int build(line *x,line *S,ll *C){
- int top=; S[]=x[];
- rep(i,,n){
- while(top> && con(S[top],S[top-])>=con(S[top],x[i])) --top;
- S[++top]=x[i];
- }
- rep(i,,top)
- C[i]=i>?con(S[i],S[i-]):maxL, X[++m]=C[i];
- return top;
- }
- ll calc(line up,line dn,int l,int r){
- ll len=r-l;
- if(up.get(l)>=dn.get(l) && up.get(r)>=dn.get(r))
- return (up.get(l)-dn.get(l)+)*(len+)+(len*(len+)>>)*(up.k-dn.k);
- if(up.get(l)==dn.get(l) || up.get(r)==dn.get(r)) return 1ll; //构造出的任意两条直线的交点必定是个整点,所以反三角的顶点处必定是个整点
- if(up.get(l)<dn.get(l) & up.get(r)<dn.get(r)) return 0ll;
- ll pos=con(up,dn); return calc(up,dn,l,pos-)+calc(up,dn,pos,r);
- }
- void solve(){
- sort(X+,X+m+);
- for(int i=,t1=,t2=; i<=m; ++i) if(X[i]>X[i-]){
- while(t1<m1 && c[][t1+]<=X[i-]) t1++;
- while(t2<m2 && c[][t2+]<=X[i-]) t2++;
- ans+=calc(s[][t1],s[][t2],X[i-],X[i]-);
- }
- }
- int main(){
- n=read(), X[]=-maxL, X[m=]=maxR;
- int dn,up;
- rep(i,,n-){
- dn=read(), up=read();
- mx[i+]=line(-i,up), mn[i+]=line(-i,dn);
- }
- reverse(mn+,mn+n+);
- m1=build(mx,s[],c[]);
- m2=build(mn,s[],c[]);
- solve(), printf("%lld\n",ans);
- return ;
- }
T2
10pts
打表
100pts
这题题面出锅了,$pdf$ 开头说了下文题面不会有废话,但这题第二句实际上不但是废话还透露了题解……(虽然并不能看出来那是题解)
首先,期望 $=$ 概率 $\times$ 贡献,一个点最终的期望值,是由其它每个点由某个概率给来 $1$ 贡献得到的(也就是标记一个点时,标记点与这个点在同一连通块时才对这个点造成 $1$ 贡献,否则没有)。所以可以反过来考虑每一个点给其它点贡献的期望值,也就是造成贡献的概率。
对于一对点 $x,y$,当我们标记点 $x$ 时,只有连接两点的简单路径上没有点被标记的情况下(也就是两点在同一连通块),点 $x$ 才会对点 $y$ 造成 $1$ 贡献(同一连通块所有点点权 $+1$)。
既然连接两点的简单路径上所有点都没被标记过,那么点 $x$ 对点 $y$ 造成 $1$ 贡献的概率是 $\frac{1}{dis(x,y)+1}$。
因为在这条简单路径上的 $dis(x,y)+1$ 个点中,必须先选点 $x$ 才能对点 $y$ 造成 $1$ 贡献,若先选路径上其它一点,点 $x,y$ 就不在一个连通块,之后点 $x$ 就没法对点 $y$ 造成贡献了。
注意:$x$ 可以等于 $y$,因为标记一个点本身就会对自己造成 $1$ 贡献。
对于每一对点 $x,y$ 都是这样,所以题目要求的答案就是 $$\sum_{i=1}^{n}\sum_{j=1}^{n}\frac{1}{dis(i,j)+1}$$
也就是我们只需要统计对于 $i∈[1,n]$,求距离为 $i$ 的点对数。
一说到统计树上所有的简单路径,自然有点分治。
对于一个分治中心的两棵子树,开一个数组 $cnt$ 记录已经遍历过的子树中的点,以到重心的距离为下标,即 $cnt_i$ 表示已经遍历过的所有点中,到重心距离为 $i$ 的点数。
由于路径长度的合并性质,到重心距离分别为 $i$ 和 $j$ 的两个不同子树中的点的距离为 $i+j$,换在数组上就是 $cnt$ 数组的第 $i$ 位和第 $j$ 位的乘积存在 $ans$ 数组的第 $i+j$ 位上($ans_i$ 表示在当前遍历过的点集中,简单路径经过当前分治中心 且距离为 $i$ 的点对的数量 ),所以用 $NTT$ 合并数组即可。
复杂度 $O(n\times log^2(n))$(点分治共 $log$ 层,每层点数总和是 $n$ 级别的,合并这些点的复杂度是 $O(n\times log(n))$)。由于 $NTT$ 的大常数,开 $3$ 秒好像很有道理。
有点恶心的题……
- #include<bits/stdc++.h>
- #define rep(i,x,y) for(int i=(x);i<=(y);++i)
- #define dwn(i,x,y) for(int i=(x);i>=(y);--i)
- #define rep_e(i,u) for(int i=hd[u];i;i=e[i].nxt)
- #define ll long long
- #define N 100003
- #define mod 998244353
- #define G 3
- using namespace std;
- inline int read(){
- int x=; bool f=; char c=getchar();
- for(;!isdigit(c);c=getchar()) if(c=='-') f=;
- for(; isdigit(c);c=getchar()) x=(x<<)+(x<<)+(c^'');
- if(f) return x;
- return -x;
- }
- int n,inv[N];
- struct edge{int v,nxt;}e[N<<];
- int hd[N],cnt;
- inline void add(int u,int v){e[++cnt]=(edge){v,hd[u]}, hd[u]=cnt;}
- int siz[N],Siz,mn,root; bool vis[N];
- void getRoot(int u,int fa){
- siz[u]=; int mxson=;
- rep_e(i,u) if(!vis[e[i].v] && e[i].v!=fa){
- getRoot(e[i].v,u);
- siz[u]+=siz[e[i].v];
- mxson=max(mxson,siz[e[i].v]);
- }
- mxson=max(mxson,Siz-siz[u]);
- if(mxson<mn) mn=mxson, root=u;
- }
- int f[N],mxdis;
- void dfs(int u,int fa,int dis){
- f[dis]++, mxdis=max(mxdis,dis);
- rep_e(i,u) if(!vis[e[i].v] && e[i].v!=fa) dfs(e[i].v,u,dis+);
- }
- int r[N<<];
- int getlr(int len){
- int tmp=,_len=; for(; tmp<=len; ++_len,tmp<<=); len=_len; //之前程序跑得巨慢是因为多项式长度求错了,这行的tmp<=len写成了tmp<=cnt......
- rep(i,,tmp-) r[i]=(r[i>>]>>)|((i&)<<(len-));
- return tmp;
- }
- int Pow(ll x,int y){
- ll res=;
- while(y) {if(y&) res=res*x%mod; x=x*x%mod; y>>=;}
- return res;
- }
- void ntt(int *c,int lim,int tag){
- int i,j,k;
- for(i=;i^lim;++i) if(i<r[i]) swap(c[i],c[r[i]]);
- for(i=;i<lim;i<<=){
- int wn = Pow(tag==?G:inv[G], (mod-)/(i<<));
- for(j=;j<lim;j+=(i<<)){
- int w=, x, y;
- for(k=; k^i; ++k,w=(ll)w*wn%mod)
- x=c[j+k], y=(ll)w*c[j+i+k]%mod, c[j+k]=(x+y)%mod, c[j+i+k]=(x-y+mod)%mod;
- }
- }
- if(tag==-){
- int invn=Pow(lim,mod-);
- rep(i,,lim-) c[i]=(ll)c[i]*invn%mod;
- }
- }
- int A[N<<];
- void mul(int len){
- int lim=getlr(len<<);
- rep(i,,len) A[i]=f[i]; rep(i,len+,lim-) A[i]=;
- ntt(A,lim,);
- rep(i,,lim-) A[i]=(ll)A[i]*A[i]%mod;
- ntt(A,lim,-);
- return;
- }
- int sum[N];
- void getAns(int u,int val,int dep){
- mxdis=, dfs(u,u,dep), mul(mxdis);
- rep(i,,mxdis<<) sum[i+]=(sum[i+]+(ll)A[i]*val)%mod;
- rep(i,,mxdis) f[i]=;
- return;
- }
- void calc(int u){//inclusion-exclusion
- getAns(u,,);
- rep_e(i,u) if(!vis[e[i].v]) getAns(e[i].v,-,);
- }
- void solve(int u,int s){
- if(s==){sum[]=(sum[]+)%mod; vis[u]=; return;}
- Siz=s, mn=, getRoot(u,u);
- vis[u=root]=, calc(u);
- rep_e(i,u) if(!vis[e[i].v]){
- solve(e[i].v, siz[e[i].v]>siz[u]?s-siz[u]:siz[e[i].v]);
- }
- }
- int ans;
- int main(){
- n=read();
- int u,v;
- rep(i,,n) u=read(), v=read(), add(u,v), add(v,u);
- inv[]=; rep(i,,n) inv[i]=(ll)(mod-mod/i)*inv[mod%i]%mod;
- solve(,n);
- rep(i,,n) ans=(ans+(ll)inv[i]*sum[i]%mod)%mod;
- printf("%d\n",ans);
- return ;
- }
T3
常规连边是不可能的,我们回去考虑朴素做法。
发现题目的加法操作就是在邻接矩阵的两个矩形区域集体加一个数。
可以用扫描线加线段树维护这个。
但是怎么合并连通块?
有一种冷门的最小生成树算法(王爷以前提过)叫 $boruvka$算法。
做法是对于当前每个连通块,找到这块与其它块的连边中权值最小的那条,把它连上。
这样做一轮,连通块数量至少减少一半,所以只需要做 $log(n)$ 轮。
由于正常情况下这个算法的复杂度也是 $O(n\times log(n))$ 的,没 $kruskal$ 算法直观,所以几乎不用。
但在这题里用这种做法来连边效果会很好。
我们把每个矩形拆成 $2$ 个扫描线上的操作。
线段树上每个节点维护 $2$ 个 $pair$,记录连向两个不同连通块的边所指向的连通块和这条边的边权,在指向不同连通块的基础上再使边权最小。
线段树 $pushup$ 时讨论一下即可转移。
最后 $2$ 条边中至少有一条指向与当前点不在同一连通块的点,连上这条边即可。
我讲个道理,没有文字题解真的不是什么好事情,因为文字可以解释代码,而代码未必能很好地解释文字。做过一道题,过了若干个月就忘了怎么做的事情已经发生很多次了,相信我不用列举的。
【2019.3.20】NOI模拟赛的更多相关文章
- 【2019.8.20 NOIP模拟赛 T3】小X的图(history)(可持久化并查集)
可持久化并查集 显然是可持久化并查集裸题吧... 就是题面长得有点恶心,被闪指导狂喷. 对于\(K\)操作,直接\(O(1)\)赋值修改. 对于\(R\)操作,并查集上直接连边. 对于\(T\)操作, ...
- 【2019.7.20 NOIP模拟赛 T1】A(A)(暴搜)
打表+暴搜 这道题目,显然是需要打表的,不过打表的方式可以有很多. 我是打了两个表,分别表示每个数字所需的火柴棒根数以及从一个数字到另一个数字,除了需要去除或加入的火柴棒外,至少需要几根火柴棒. 然后 ...
- 【2019.8.20 NOIP模拟赛 T2】小B的树(tree)(树形DP)
树形\(DP\) 考虑设\(f_{i,j,k}\)表示在\(i\)的子树内,从\(i\)向下的最长链长度为\(j\),\(i\)子树内直径长度为\(k\)的概率. 然后我们就能发现这个东西直接转移是几 ...
- 【2019.7.20 NOIP模拟赛 T2】B(B)(数位DP)
数位\(DP\) 首先考虑二进制数\(G(i)\)的一些性质: \(G(i)\)不可能有连续两位第\(x\)位和第\(x+1\)位都是\(1\).因为这样就可以进位到第\(x+2\)位.其余情况下,这 ...
- 『2019/4/9 TGDay2模拟赛 反思与总结』
2019/4/9 TGDay2模拟赛 今天是\(TG\)模拟赛的第二天了,试题难度也是相应地增加了一些,老师也说过,这就是提高组的难度了.刚开始学难的内容,一道正解也没想出来,不过基本的思路也都是对了 ...
- 『2019/4/8 TGDay1模拟赛 反思与总结』
2019/4/8 TGDay1模拟赛 这次是和高一的学长学姐们一起参加的\(TG\)模拟考,虽然说是\(Day1\),但是难度还是很大的,感觉比\(18\)年的\(Day1\)难多了. 还是看一下试题 ...
- NOI模拟赛 Day1
[考完试不想说话系列] 他们都会做呢QAQ 我毛线也不会呢QAQ 悲伤ING 考试问题: 1.感觉不是很清醒,有点困╯﹏╰ 2.为啥总不按照计划来!!! 3.脑洞在哪里 4.把模拟赛当作真正的比赛,紧 ...
- 6.28 NOI模拟赛 好题 状压dp 随机化
算是一道比较新颖的题目 尽管好像是两年前的省选模拟赛题目.. 对于20%的分数 可以进行爆搜,对于另外20%的数据 因为k很小所以考虑上状压dp. 观察最后答案是一个连通块 从而可以发现这个连通块必然 ...
- FJoi2017 1月20日模拟赛 恐狼后卫(口糊动规)
Problem 1 恐狼后卫(wolf.cpp/c/pas) [题目描述] 著名卡牌游戏<石炉传说>中有一张随从牌:恐狼后卫.恐狼后卫的能力是使得相邻随从的攻击力提高. 现在有n张恐狼后卫 ...
- 2019.7.26 NOIP 模拟赛
这次模拟赛真的,,卡常赛. The solution of T1: std是打表,,考场上sb想自己改进匈牙利然后wei了(好像匈牙利是错的. 大力剪枝搜索.代码不放了. 这是什么神仙D1T1,爆蛋T ...
随机推荐
- js中的堆内存和栈内存
我们常常会听说什么栈内存.堆内存,那么他们到底有什么区别呢,在js中又是如何区分他们的呢,今天我们来看一下. 一.栈内存和堆内存的区分 一般来说,栈内存主要用于存储各种基本类型的变量,包括Boolea ...
- C#反射动态创建实例并调用方法
在.Net 中,程序集(Assembly)中保存了元数据(MetaData)信息,因此就可以通过分析元数据来获取程序集中的内容,比如类,方法,属性等,这大大方便了在运行时去动态创建实例. MSDN解释 ...
- SICK激光扫描仪LMS511连接通讯
一.设备介绍: 型号:LMS511-10100(DC 24v) 品牌:SICK 操作环境:Windows 10 64bit 软件:SOPAS ET 连接线:串口转网口线(1根/4针 子头),电源线( ...
- 【DSP开发】【Linux开发】Linux下PCI设备驱动程序开发
PCI是一种广泛采用的总线标准,它提供了许多优于其它总线标准(如EISA)的新特性,目前已经成为计算机系统中应用最为广泛,并且最为通用的总线标准.Linux的内核能较好地支持PCI总线,本文以Inte ...
- Autofac依赖注入容器
依赖注入容器-- Autofac https://github.com/danielpalme/IocPerformance Unity 更新频率高,微软的项目Grace 综合性能更高 目录: 一.简 ...
- C#实现多线程的方法:线程(Thread类)和线程池(ThreadPool)
简介 使用线程的主要原因:应用程序中一些操作需要消耗一定的时间,比如对文件.数据库.网络的访问等等,而我们不希望用户一直等待到操作结束,而是在此同时可以进行一些其他的操作. 这就可以使用线程来实现. ...
- python copy与deepcopy (拷贝与深拷贝)
copy与deepcopy python 中的copy与deepcopy是内存数据的操作,但是两个函数有一定的区别. 1.copy import copy list = [1, [4, 5, 6], ...
- 【Spring 源码】Spring 加载资源并装配对象的过程(XmlBeanDefinitionReader)
Spring 加载资源并装配对象过程 在Spring中对XML配置文件的解析从3.1版本开始不再推荐使用XmlBeanFactory而是使用XmlBeanDefinitionReader. Class ...
- 单机版的mysql安装
查是否安装了mysql:centos6:rpm -qa |grep mysqlcentos7:rpm -qa|grep mariadb或rpm -qa |grep mysql 有老的版本可以执行命令卸 ...
- Palindromic Substrings
Given a string, your task is to count how many palindromic substrings in this string. The substrings ...