java8学习之自定义收集器实现
在上次花了几个篇幅对Collector收集器的javadoc进行了详细的解读,其涉及到的文章有:
- http://www.cnblogs.com/webor2006/p/8311074.html
- http://www.cnblogs.com/webor2006/p/8318066.html
- http://www.cnblogs.com/webor2006/p/8324390.html
而系统有一个对它的具体实现则是在Collectors类中有一个CollectorImpl:

为了加深对Collector收集器的理解,咱们这次自定义一个自己的收集器,而不采用系统写好的,在自定义之前,先来回顾一下收集器的一些要点:
1、泛型参数的意义:
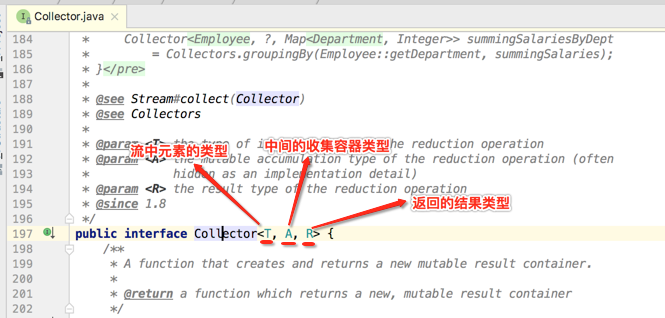
2、核心方法的意义:
其中包含五个重要的方法,具体如下:
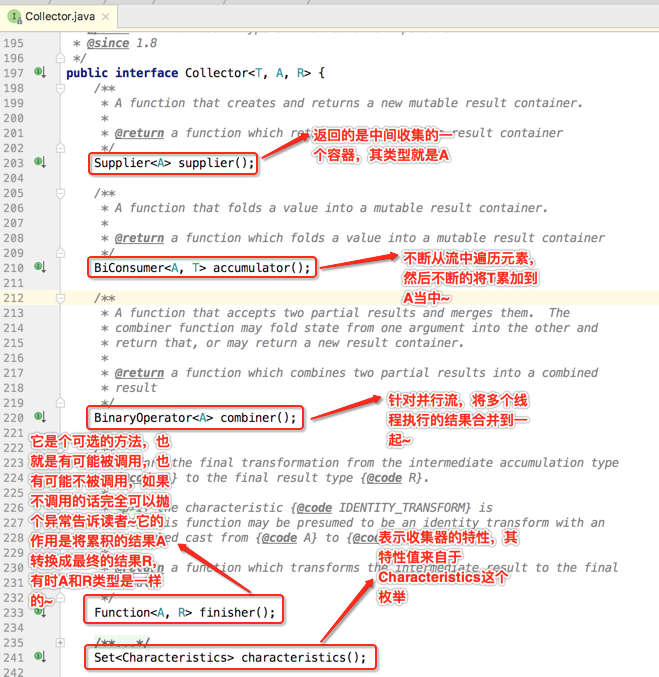
其中对于Characteristics这个枚举里面的值再说明一下,之后会用代码来进行进一步说明:
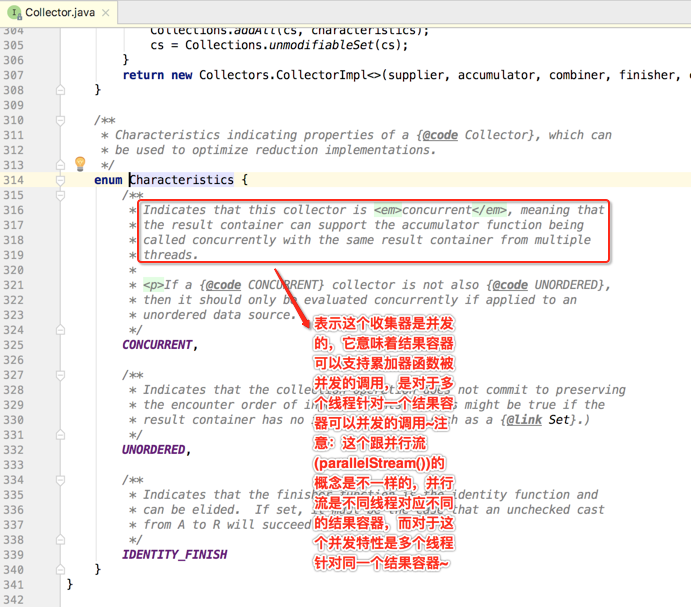



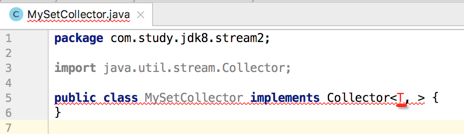
好了~~复习了这些细节之后,下面就开始编码,咱们对Set数据进行收集,如下:
接着来定义三个泛型参数,下面一个个来定义,首先是流中元素的类型,咱们用T来表示,如下:
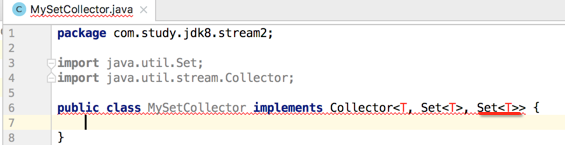
第二个参数则是中间累加的结果容器,很显然是Set<T>,如下:

最后一个参数则是最终结果的类型,咱们最终结果类型跟中间结果容器类型是一样的,都是Set,所以:
很显然目前的T还是标红的,是因为咱们还得在它上面定义一下,如下:
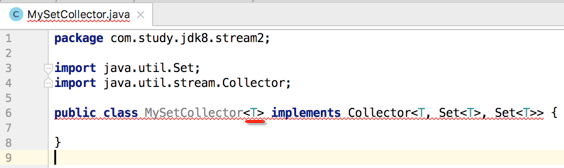
接下来将接口中的方法都得实现一下,如下:


接下来一个个方法具体实现:
supplier():
首先先在这方法中打印一下日志,待之后看一下整个调用过程:
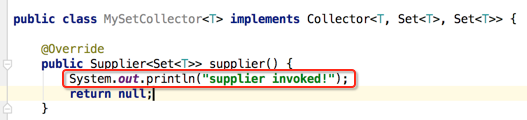
那接下来就是看如何实现呢?它的作用是生成一个存放中间结果的空的容器,看下它的返回值是:Supplier<Set<T>>,不传参数,返回一个Set<T>,这里咱们用HashSet,那可以采用方法引用,如下:

accumulator():
还是先打印日志便于运行观察:

该方法的主要作用是进行中间结果的不断累加,看一下它的返回类型BiConsumer<Set<T>, T>,接收两个参数,不返回值,注意一下这两个参数的顺序:第一个参数为不断增加的结果容器,第二个参数流中遍历的下一个元素,当然就是不断将第二个参数往第一个参数中累加,所以下面先用Lambda表达式的方式来实现一下:
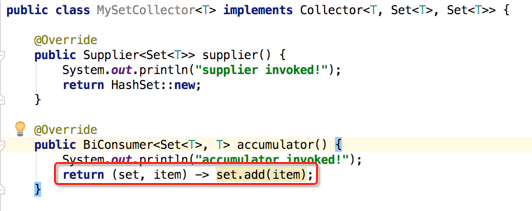
这时还是可以用方法引用:
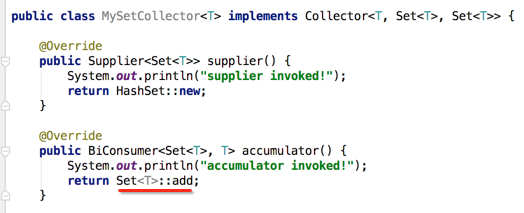
对于这个方法引用,其第一个参数是调用累加的那个中间结果容器,而第二个参数则是遍历的下一个元素。
那如果将这个Set换成HashSet呢?
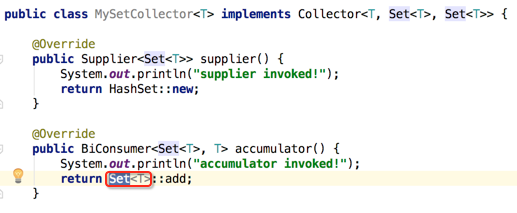

咱们先看替换完之后能不能编译:
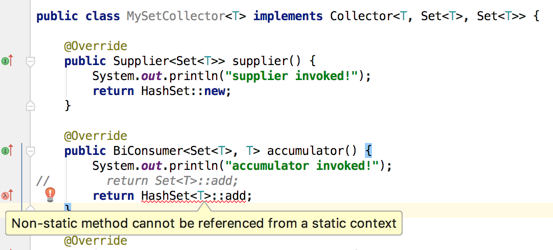
IDE提示貌似也没道出所有然来,很是奇怪,既然HashSet是Set的直接实现类,为啥就不行了呢?其实原因是这样:
假如这个HashSet替换完了是允许的,那假如咱们在supplier()函数中将HashSet改为TreeSet呢?那明显accumulator()方法的具体实现也得进行修改,而如果是面向接口那改了supplier()的具体实现完全不影响accumulator()的实现,所以说这个实现需要注意。
combiner():
同样先打印日志:

而此方法的作用就是将两个部分结果进行合并,所以可以这样实现:

finisher():
首先也打印日志:
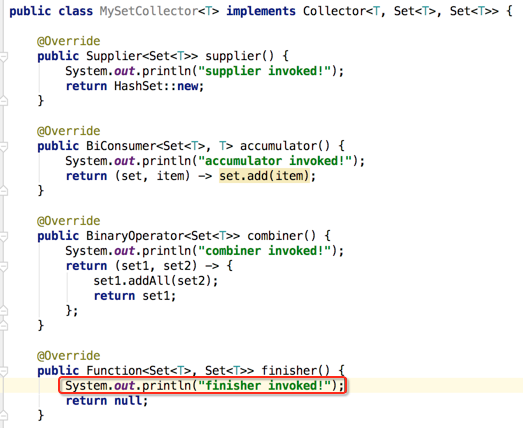
它的作用其实就是将中间累加的结果容器转换成最终的结果,而对于咱们这边的场景其最终结果类型也就是中间结果类型,所以直接将累加的中间结果容器返回既可,如下:

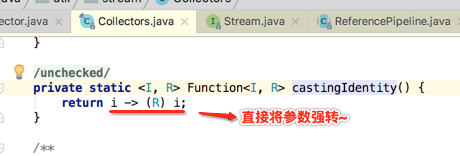
插个小细节,还可以用Function提供的一个静态方式来取而代之,之前咱们也介绍过:
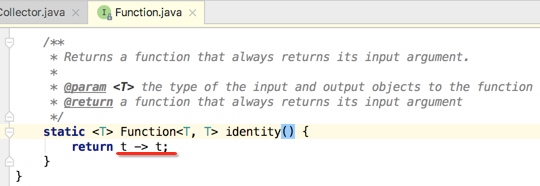
所以:
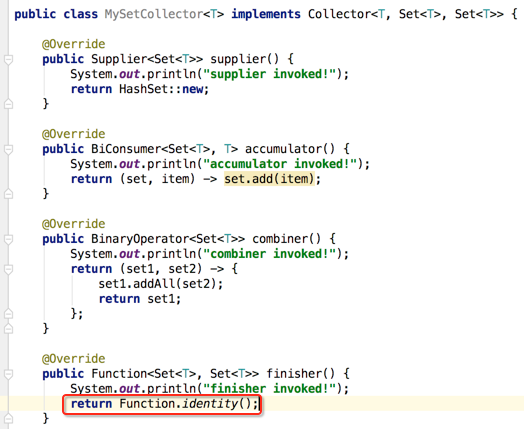
characteristics():
同样先增加日志:

它主要是决定收集器的一些特性的,那这里返回一个无序特性,如下:
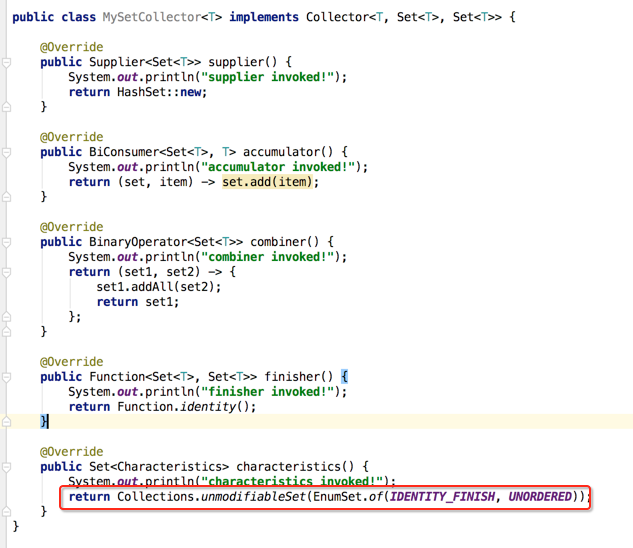
那这里面实现中涉及到的代码其实是参照Collectors类中的,如下:

至此,咱们自定义的收集器就已经定义好啦,接下来咱们来使用一下它,将定义的List转换成Set,具体如下:

看一下此时它返回的数据类型:
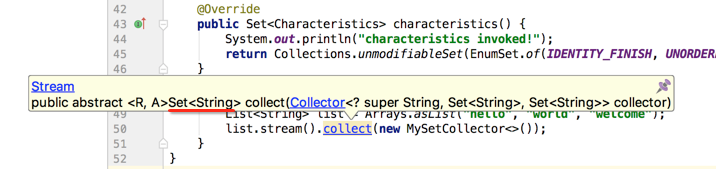
所以咱们用它来接收一下,并打印出结果:
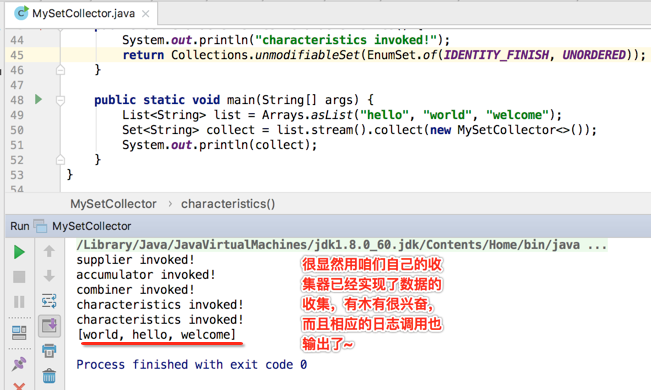
如果再增加一个重复的元素当然会被过滤掉,因为Set是会去重滴:

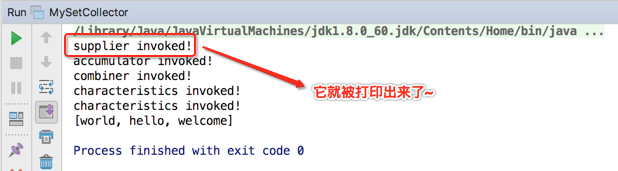
从日志打印的记录中发现,居然finisher()方法木要有被调用,这也是在开篇回顾Collector重要方法时提到了,它有时能调用,有时是不会调用的,当中间的结果容器的类型跟最终结果的类型是一致的话,其实该方法直接抛个异常就行了,不用实现,而咱们写的这种情况刚好就属于这种:

关于最终打印的日志输出,它的执行流程为啥是这样的呢?下面从stream.collect()的源码中找寻答案,如下:
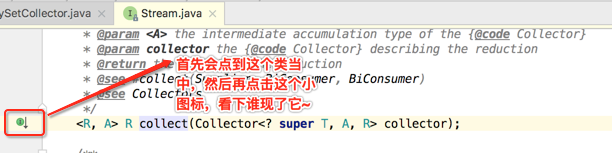
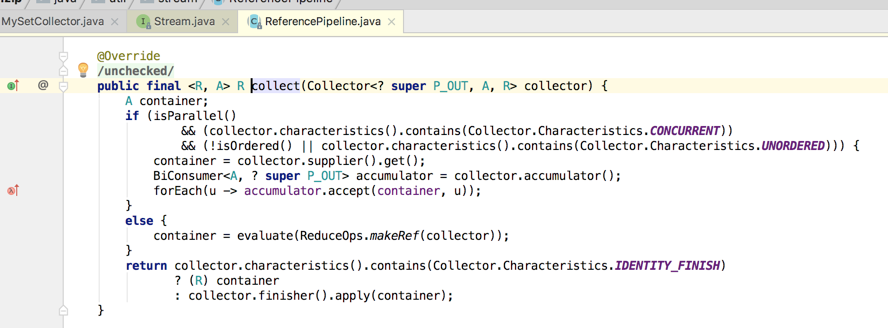
接下来只分析关键代码,因为主要是为了寻找为啥最终的输出顺序是这样的问题,先来看一下该方法的实现:
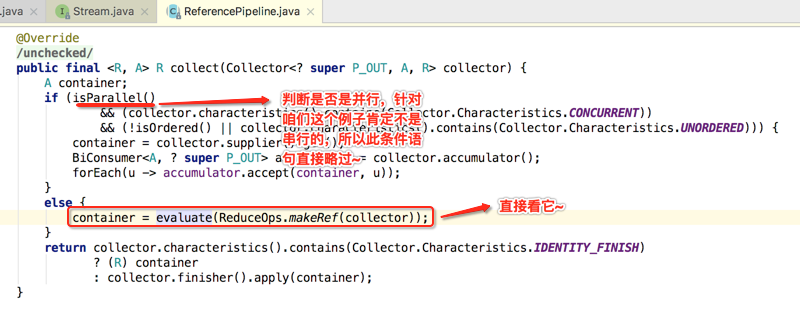
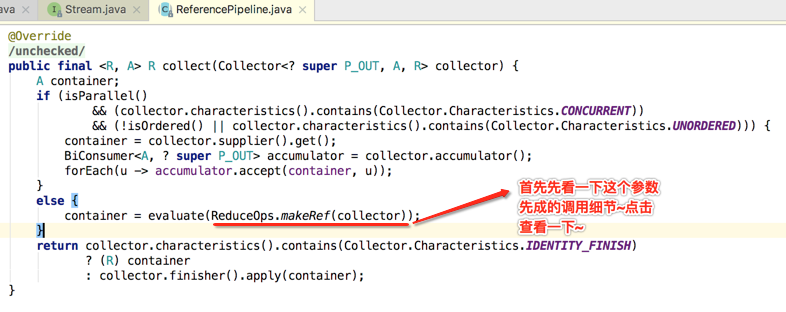
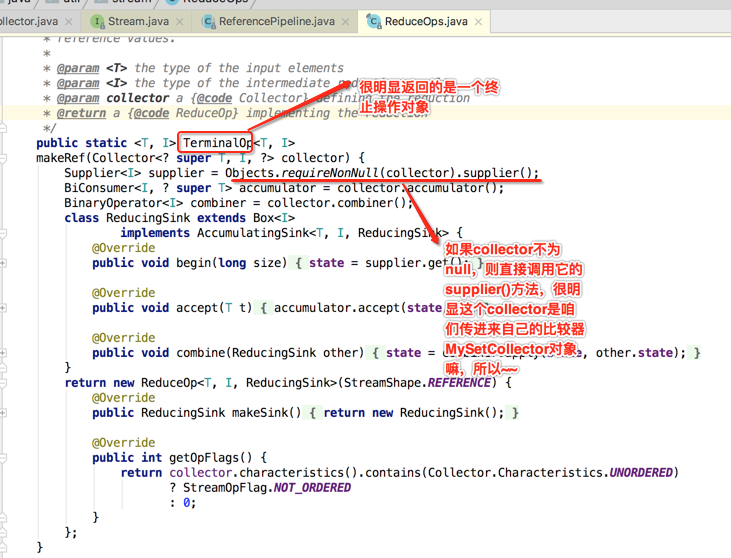

接着继续回到ReduceOps.makeRef()方法往下看:

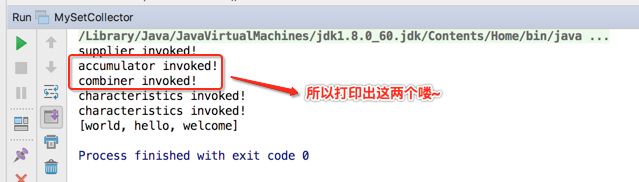
所以这三句话的调用就是在初始化时被调用的,但是!!!有一点需要注意,只是回调函数调用了,但是函数式接口并没有调用,如何理解,比如说:
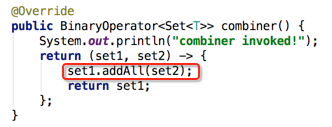
如果BinaryOperator函数式接口被调用的话,其Lambda表达式肯定会被执行,最终执行合并操作,这里说的函数式接口没调用是指并非真正的去执行了合并操作了,其实目前只是获取了函数式接口的实例而已,咱们再来体会下:

接着再来分析一下为啥这个被打印了两次,如下:
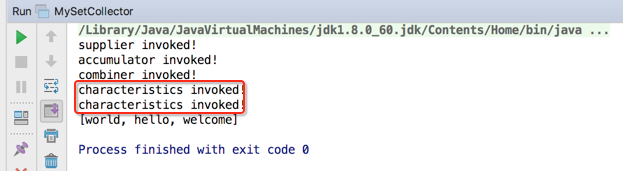
其实是在下面两处被调用的:
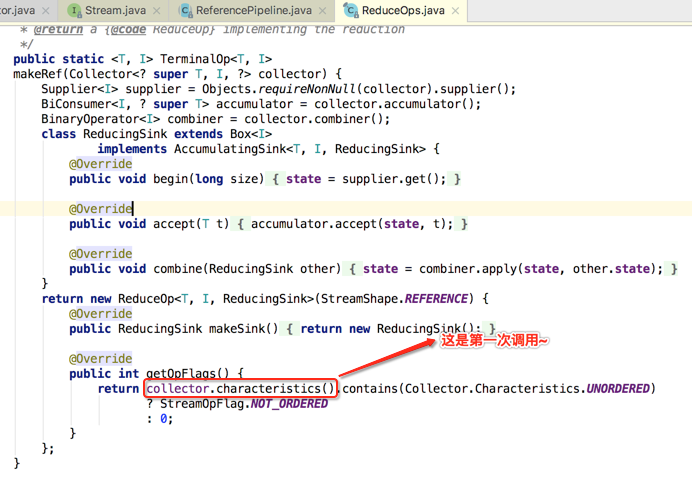
接着得回到它的上一级调用来看:
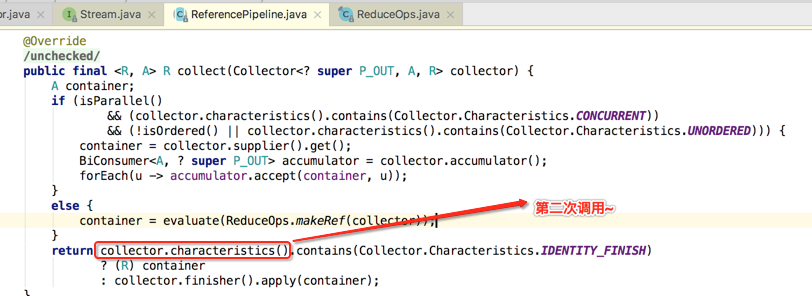
另外为啥finisher()方法木有被调用呢?其实也就是在刚才分析的代码处就可以明白了:
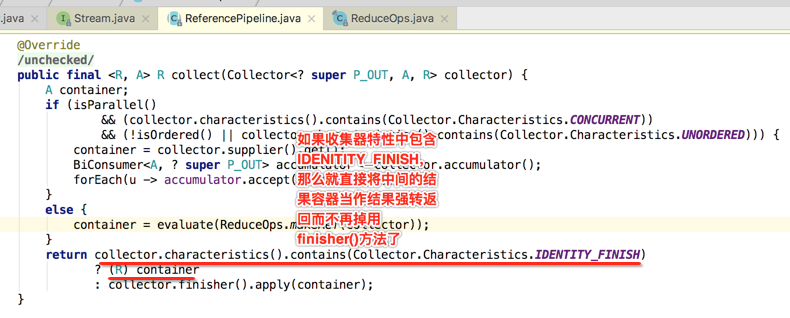

所以通过这个实现就能解释为啥咱们的finisher()方法木有掉用啦,原因就是由于咱们给收集器增加了如下特性:
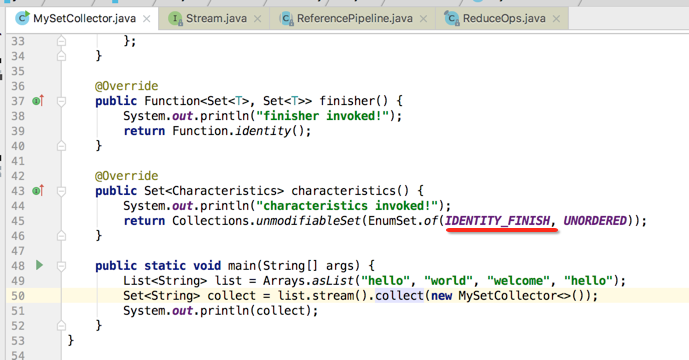
那接下来做个实验,将这个特性去掉,看是否这次能执行finisher()?

基于此咱们再来看一下系统收集器实现中的一个细节:
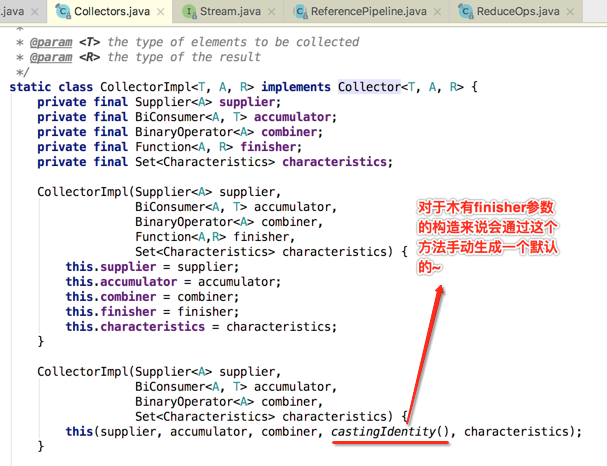
看一下它的具体实现,豁然开朗:
实际开发中可能自定义收集器的场景比较少,但是!!如果你研究清楚了如何自己来写一个收集器,那可以帮助我们更加自信的应用收集器的任何东东,也就是有了底层的支持才能走出咱们的自信,所以学会自定义还是非常有意义的~
java8学习之自定义收集器实现的更多相关文章
- java8学习之自定义收集器深度剖析与并行流陷阱
自定义收集器深度剖析: 在上次[http://www.cnblogs.com/webor2006/p/8342427.html]中咱们自定义了一个收集器,这对如何使用收集器Collector是极有帮助 ...
- Java8学习笔记(十)--自定义收集器
前言 以前写过Java8中的自定义收集器,当时只是在文章末尾放了个例子,觉得基本用法挺简单,而且有些东西没搞懂(比如combiner方法到底做什么的),没有专门写,过了一段时间又忘了,所以,即使还是没 ...
- Java8中重要的收集器Collector
Collector介绍 Java8的stream api能很方便我们对数据进行统计分类等工作,函数式编程的风格让我们方便并且直观地编写统计代码. 例如: Stream<Integer> s ...
- Java虚拟机JVM学习06 自定义类加载器 父委托机制和命名空间的再讨论
Java虚拟机JVM学习06 自定义类加载器 父委托机制和命名空间的再讨论 创建用户自定义的类加载器 要创建用户自定义的类加载器,只需要扩展java.lang.ClassLoader类,然后覆盖它的f ...
- java类加载器学习2——自定义类加载器和父类委托机制带来的问题
一.自定义类加载器的一般步骤 Java的类加载器自从JDK1.2开始便引入了一条机制叫做父类委托机制.一个类需要被加载的时候,JVM先会调用他的父类加载器进行加载,父类调用父类的父类,一直到顶级类加载 ...
- Struts学习之自定义拦截器
* 所有的拦截器都需要实现Interceptor接口或者继承Interceptor接口的扩展实现类 * 要重写init().intercept().destroy()方法 * in ...
- Struts2重新学习之自定义拦截器(判断用户是否是登录状态)
拦截器 一:1:概念:Interceptor拦截器类似于我们学习过的过滤器,是可以再action执行前后执行的代码.是web开发时,常用的技术.比如,权限控制,日志记录. 2:多个拦截器Interce ...
- struts2学习(6)自定义拦截器-登录验证拦截器
需求:对登录进行验证,用户名cy 密码123456才能登录进去: 登录进去后,将用户存在session中: 其他链接要来访问(除了登录链接),首先验证是否登录,对这个进行拦截: com.cy.mod ...
- 学习JVM--垃圾回收(二)GC收集器
1. 前言 在上一篇文章中,介绍了JVM中垃圾回收的原理和算法.介绍了通过引用计数和对象可达性分析的算法来筛选出已经没有使用的对象,然后介绍了垃圾收集器中使用的三种收集算法:标记-清除.标记-整理.标 ...
随机推荐
- 【转】Spark History Server 架构原理介绍
[From]https://blog.csdn.net/u013332124/article/details/88350345 Spark History Server 是spark内置的一个http ...
- HCL试验七
在静态路由的基础上实行动态路由 对每台路由器的直连ip编写动态路由命令 路由器1 rip 1 network 192.168.1.0 network 10.1.1.0 undo summary und ...
- 注入之Mysql-Getshell思路
- 通道的分离与合并,ROI,
通道的分离与合并 class Program { static void Main(String[] args) { Mat img = CvInvoke.Imread(@"C:\Users ...
- Fiddle-常用设置和操作记录
1.导出证书: 2.清空屏幕: 3.字段认识 4.保存会话: 5.解码
- JavaScript中好用的对象数组去重
对象数组去重 Demo数据如下: var items= [{ "specItems": [{ "id": "966480614728069122&qu ...
- Yii2.0中使用Union查询,并使用join,支持分页
$query1 = Class1::find()->where($where); $query2 = Class1::find()->alias('a')->join('left j ...
- Django 中事务的使用
目录 Django 中事务的使用 Django默认的事务行为 在HTTP请求上加事务 在View中实现事务控制 使用装饰器 使用context manager autocommit() commit_ ...
- 基于VS搭建OpenCV环境
OpenCV OpenCV的全称是Open Source Computer Vision Library,是一个跨平台的计算机视觉库.OpenCV是由英特尔公司发起并参与开发,以BSD许可证授权发行, ...
- 什么是 Serverless 应用引擎?优势有哪些?
Serverless 应用引擎(Serverless App Engine,简称 SAE)是面向应用的 Serverless PaaS 平台,能够帮助 PaaS 层用户免运维 IaaS,按需使用,按量 ...