理解PyTorch的自动微分机制
参考Getting Started with PyTorch Part 1: Understanding how Automatic Differentiation works
非常好的文章,讲解的非常细致。
注意这篇文章基于v0.3,其中的Variable和Tensor在后来把版本中已经合并。
from torch import FloatTensor
from torch.autograd import Variable
# Define the leaf nodes
a = Variable(FloatTensor([4]))
weights = [Variable(FloatTensor([i]), requires_grad=True) for i in (2, 5, 9, 7)]
# unpack the weights for nicer assignment
w1, w2, w3, w4 = weights
b = w1 * a
c = w2 * a
d = w3 * b + w4 * c
L = (10 - d)
L.backward()
for index, weight in enumerate(weights, start=1):
gradient, *_ = weight.grad.data
print(f"Gradient of w{index} w.r.t to L: {gradient}")
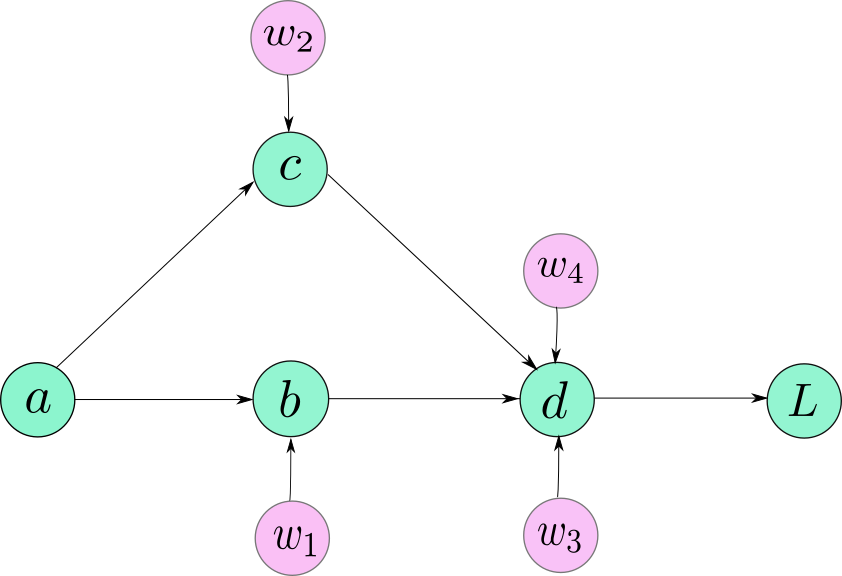
The computation graph is simply a data structure that allows you to efficiently apply the chain rule to compute gradients for all of your parameters.
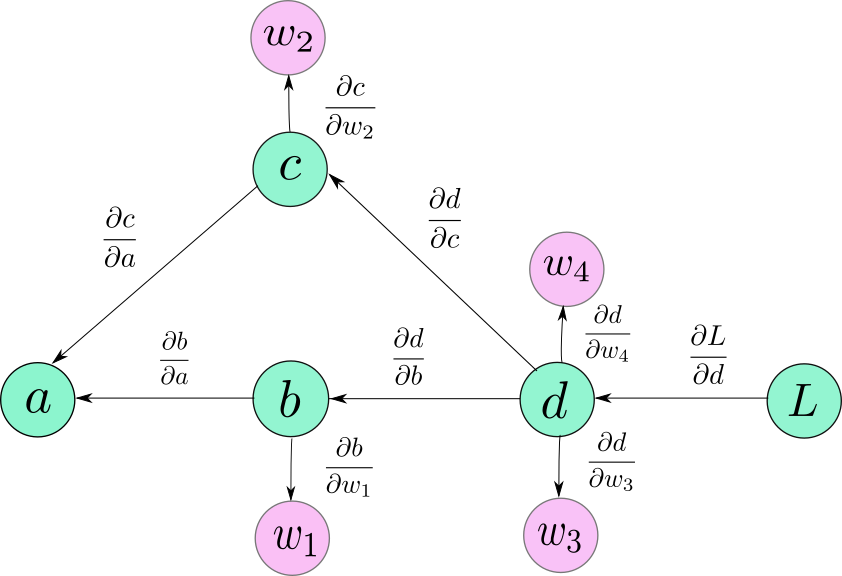
注意:前向传播计算图的边的方向是数据的流向,后向传播计算图的边的方向是梯度传播的流向,这两者的方向正好是相反的。对于计算某个节点直接后继节点的梯度,就是直接后继节点到该节点边上的导数,对于计算某个非直接后继节点的梯度,就是从非直接后继节点到该节点所经过的所有边上导数的乘积。
Graph leaves or leaf variables
官方文档中的"Graph leave" or "leaf variables"指的就是前向计算图中没有前驱的节点a,或者是反向计算图中没有后继的节点a。对于这样的节点我们一定要把requires_grad设置为True,否则,这些变量将不会包含在计算图中,并且叶不会计算它们的梯度。
当Python执行到我们上面写的代码时,也就是执行到节点a,b,c,w1[2,3,4],d,L的定义时,a computation graph is being generated on the fly. 当计算图的output被从input计算出来时,每个变量(节点)的forward function会cache输入的值,这些值在反向计算梯度时会被用到。(For example, if our forward function computes W*x, then d(W*x)/d(W) is x, the input that needs to be cached)
现在我要说的就是前面画的计算图并不是非常准确的,因为当PyTorch制造一个计算图时,并不是把Variable objects (Tensor objects)作为计算图的节点,而是把Function objects,准确的说是每个Variable的grad_fn属性作为计算图的节点。所以PyTorch的计算图看起来是这样的:
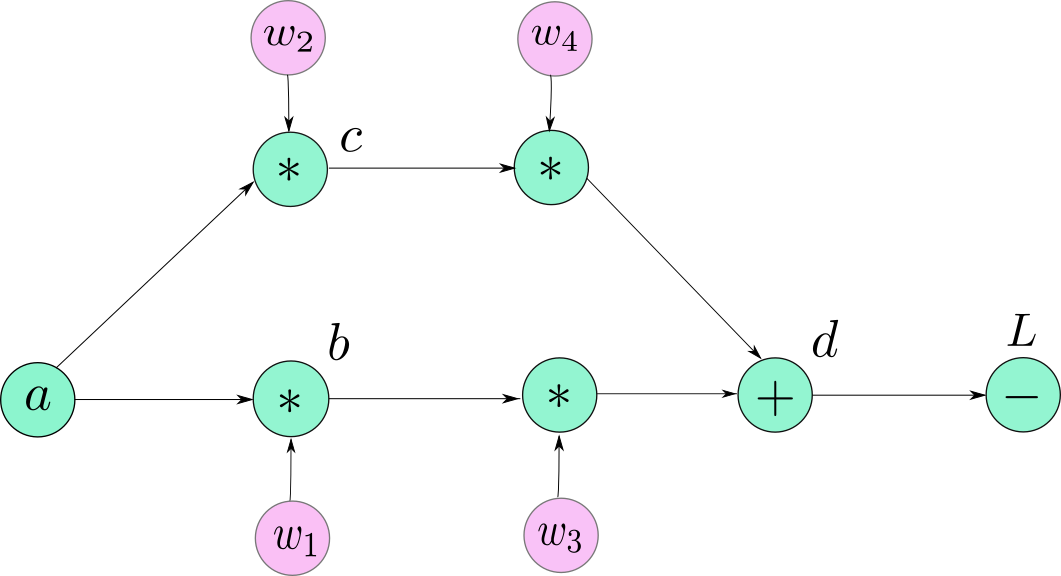
上图中,我仍然把原来的leaf node用Variable objects来表示,虽然它们也有自己的grad_fn的属性(叶子节点的grad_fn返回的是None。这很好理解,因为你不能在叶子节点上进行反向传播)。剩下的节点现在用它们的grad_fn来表示。我们可以看到有个节点d被用三个Functions(两个乘法一个加法)代替。
L节点对于任意叶子节点的梯度都可以通过该节点对应的Variable的.grad来访问(PyTorch默认的行为不允许访问非叶子节点的梯度)。
w1 = w1 — (learning_rate) * w1.grad #update the wieghts using GD
前面我说不能访问非叶子节点的梯度,这是Pytorch的默认行为。但是你可以改变这个默认行为,只要你在定义Variable后调用该Variable的.retain_grad(),你就可以访问它的grad属性。
import torch
x = torch.tensor([1., 1, 1, 1], requires_grad=True)
y = 2*x
z = y.mean()
z.backward()
print(x.grad, y.grad, z.grad)
'''
tensor([0.5000, 0.5000, 0.5000, 0.5000]) None None
'''
import torch
x = torch.tensor([1., 1, 1, 1], requires_grad=True)
y = 2*x
y.retain_grad()
z = y.mean()
z.retain_grad()
z.backward()
print(x.grad, y.grad, z.grad)
'''
tensor([0.5000, 0.5000, 0.5000, 0.5000]) tensor([0.2500, 0.2500, 0.2500, 0.2500]) tensor(1.)
'''
Dynamic Computation Graph
Pytorch 计算图的产生方式是 on the fly (不需要准备,随定义立即产生)。直到一个Variable(Tensor)的 forward function被调用之前,计算图中都不存在这个Variable(或者说是它的grad_fn) 的节点。计算图的产生是许多Variable被调用的结果。在那时,buffers会分配给计算图和中间值(用来后面计算梯度)。当你调用.backward(),梯度被计算出来后,这些buffers就被释放了,并且计算图被破坏了。你可以尝试在一个计算图上调用.backward()多次,你将会看到pytorch将会给你一个error。这时因为计算图在第一次调用backward()后就被销毁了,因此在第二次调用backward时是不存在计算图的。
如果你再一次调用forward,一个全新的计算图被产生。
这和Static Computation Graphs(TensorFlow使用的)是截然不同的,其中的静态图在执行程序之前要定义好。动态图机制允许你在运行时改变网络的架构,因为一个动态图仅仅在一段代码执行时产生。这意味着一个计算图可能在程序执行过程中被重复定义多次。动态图是debug更简单,更容易追踪错误来源。
Some Tricks of Trade
requires_grad 是Variable的一个属性,默认为False。这个属性在你不得不冻结某些layers并且阻止layers上的参数在训练中更新时是很方便的。你可以简单的将requires_grad设置为False,这样这些Variables将不会包括在计算图中。因此,没有梯度会传播到它们。
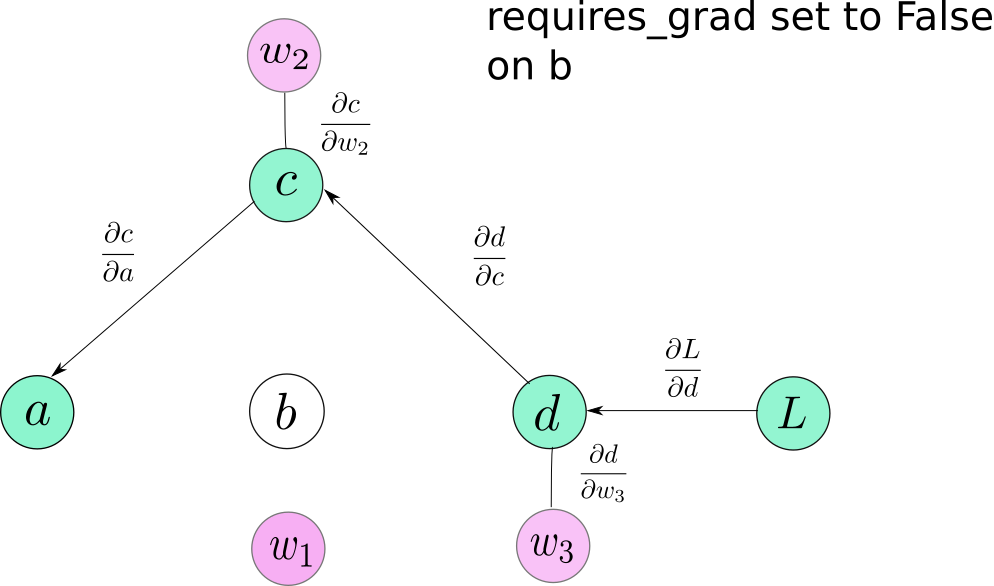
volatile 是Variable的另外一个属性,它会造成一个Variable从计算图中剔除当它被设置为True时。它和requires_grad是非常相似的,因为当它被设置为True时是具有传染性的。但是它比起requires_grad有一个更高的优先级,也就是一个Variable的requires_grad=True并且volatile=True,这个Variable就不会被包含到计算图中。
你可能会想为什么需要另外一个开关来覆盖requires_grad的值,而不是简单的将requires_grad设置为False,下面就说明原因。
当我们做推理(forward过程)而不需要梯度时,不去创建计算图是非常必要的。首先,创建计算图的开销可以消除,而且速度会提升。第二,如果我们创建一个计算图但是不调用backward(),用来缓存的buffers就不会被释放,这会导致你耗尽内存。
通常,我们的神经网络有许多层,我们在训练时可能会把requires_grad设置为True。为了避免在 inference时产生计算图,我们可以做两件事:1. 把所有layers的requires_grad设置为False; 2. 将input的volatile设置为True,这样可以保证后面的操作不会产生计算图。
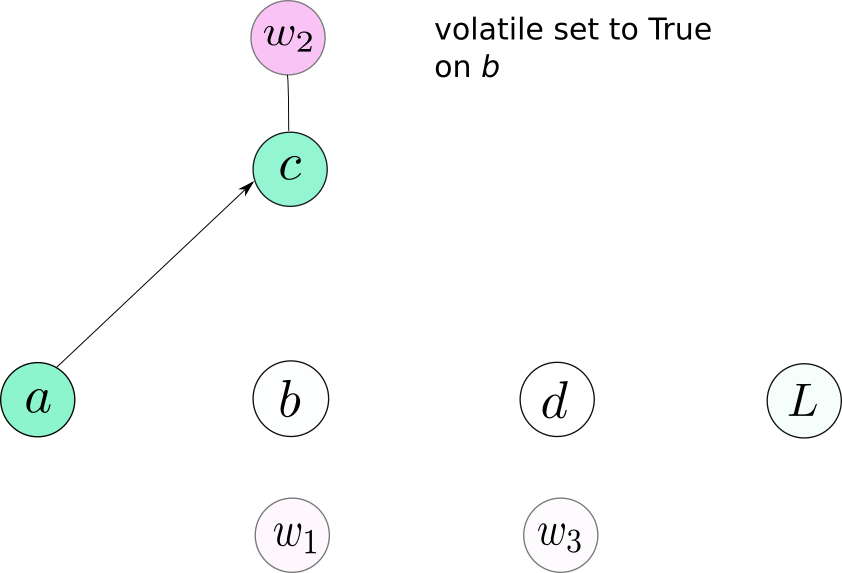
No graph is created for b or any node that depends on b.
Note: Pytorch v0.4 has no volatile argument for a combined Tensor/Variable class. Instead, the inference code should be put in a torch.no_grad() context manager.
with torch.no_grad():
# write your inference code here
So, that was Autograd for you. Understanding how Autograd works can save you a lot of headache when you’re stuck somewhere, or dealing with errors when you’re starting out.
理解PyTorch的自动微分机制的更多相关文章
- 【tensorflow2.0】自动微分机制
神经网络通常依赖反向传播求梯度来更新网络参数,求梯度过程通常是一件非常复杂而容易出错的事情. 而深度学习框架可以帮助我们自动地完成这种求梯度运算. Tensorflow一般使用梯度磁带tf.Gradi ...
- PyTorch自动微分基本原理
序言:在训练一个神经网络时,梯度的计算是一个关键的步骤,它为神经网络的优化提供了关键数据.但是在面临复杂神经网络的时候导数的计算就成为一个难题,要求人们解出复杂.高维的方程是不现实的.这就是自动微分出 ...
- Pytorch Autograd (自动求导机制)
Pytorch Autograd (自动求导机制) Introduce Pytorch Autograd库 (自动求导机制) 是训练神经网络时,反向误差传播(BP)算法的核心. 本文通过logisti ...
- pytorch学习-AUTOGRAD: AUTOMATIC DIFFERENTIATION自动微分
参考:https://pytorch.org/tutorials/beginner/blitz/autograd_tutorial.html#sphx-glr-beginner-blitz-autog ...
- PyTorch 自动微分示例
PyTorch 自动微分示例 autograd 包是 PyTorch 中所有神经网络的核心.首先简要地介绍,然后训练第一个神经网络.autograd 软件包为 Tensors 上的所有算子提供自动微分 ...
- PyTorch 自动微分
PyTorch 自动微分 autograd 包是 PyTorch 中所有神经网络的核心.首先简要地介绍,然后将会去训练的第一个神经网络.该 autograd 软件包为 Tensors 上的所有操作提供 ...
- MindSpore:自动微分
MindSpore:自动微分 作为一款「全场景 AI 框架」,MindSpore 是人工智能解决方案的重要组成部分,与 TensorFlow.PyTorch.PaddlePaddle 等流行深度学习框 ...
- ArrayList源码解析(二)自动扩容机制与add操作
本篇主要分析ArrayList的自动扩容机制,add和remove的相关方法. 作为一个list,add和remove操作自然是必须的. 前面说过,ArrayList底层是使用Object数组实现的. ...
- 附录D——自动微分(Autodiff)
本文介绍了五种微分方式,最后两种才是自动微分. 前两种方法求出了原函数对应的导函数,后三种方法只是求出了某一点的导数. 假设原函数是$f(x,y) = x^2y + y +2$,需要求其偏导数$\fr ...
随机推荐
- redis 学习(7) -- 有序集合
redis 学习(7) -- 有序集合 zset 结构 有序集合:有序.不能包含重复元素 每个节点包含:score和value两个属性,根据score进行排序 如图: zset 重要 API 含义 命 ...
- 部署k8s集群之环境搭建和etcd单节点安装
环境搭建以及etcd 单节点安装过程 安装之前的环境搭建 在进行k8s安装之前先把虚拟机准备好,这里准备的是三台虚拟机 主机名 ip地址 角色 master 172.16.163.131 master ...
- 01 Redis基础
NoSQL 学名(not only sql) 特点: 存储结构与mysql这一种关系型数据库完全不同,nosql存储的是KV形式 nosql有很多产品,都有自己的api和语法,以及业务场景 产品种类: ...
- 启动web项目报错:The server time zone value '�й���ʱ��' is unrecognized or represents more than one time zone.
解决: 在application.properties配置文件中的添加标红部分 spring.datasource.url=jdbc:mysql://127.0.0.1:3306/miaosha?se ...
- bilibili小程序项目总结
1.关于mock的使用 第一步:先到Mock官网(http://mockjs.com/)上面熟悉一下基本用法 第一步:具体使用实例: 下载wxMock.js和mock.js文件 下载地址:https: ...
- appium 自动化测试环境搭建
最近再学习appium,把学习的过程记录下来,以防止到时候 换个电脑就不知道这么安装搭建appium环境了. 环境搭建: 0.JDK环境是必备的,这里大家自行百度, 1.安装 node 环境,前辈 ...
- 黑马java课程视频java学习视频
资料获取方式,关注公总号RaoRao1994,查看往期精彩-所有文章,即可获取资源下载链接 更多资源获取,请关注公总号RaoRao1994
- Maven配置和使用
Eclipse下的Maven开发环境搭建. 现在要用到Eclipse开发Maven的项目,需要配置Maven,简单整理下配置方法. 1.下载Maven安装包,http://maven.apache.o ...
- 七、Vue Cli+ApiCloud
一.api.js (参考) 顶部注释: 底部注释: 二.导入 效果: 继续使用: 运行环境:用APP打开,浏览器没有api对象,只有APP运行环境才有API对象 代码如下: <template& ...
- shell 获取结果中的第n列,第n行
ls -l | awk '{print $5}' | sed -n '2p' awk 是很实用的文本处理命令,print 到后带的是你要获取第几列,sed -n 是指定第几行.