【消息中间件】kafka
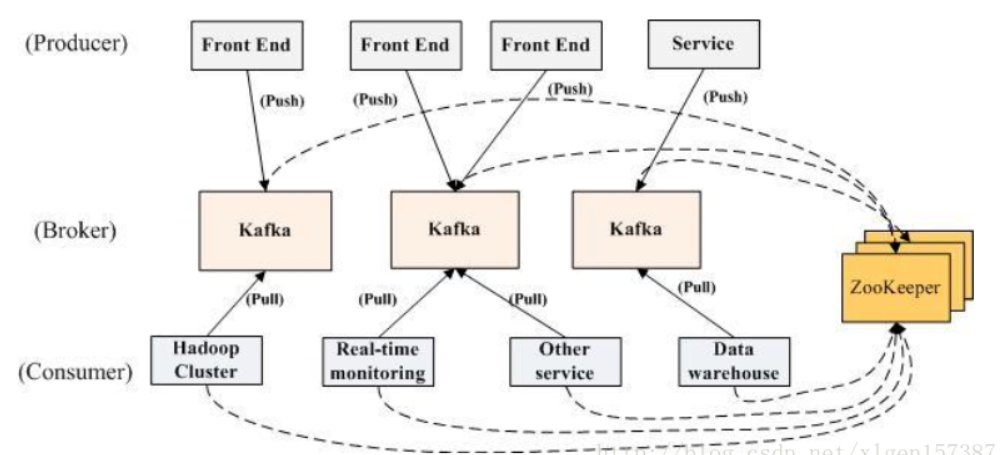
一、kafka整体架构
kafka是一个发布订阅模式的消息队列,生产者和消费者是多对多的关系,将发送者与接收者真正解耦;
生产者将消息发送到broker;
消费者采用拉(pull)模式订阅并消费消息;
二、生产者介绍
分区器:制定partition,按照msg key进行分区,保证同样key的消息投递到同一个partiton。例如,按照uid最后两位作为key,可以有100partiron,来保证相同uid的时间在一个partition中。
kafka发送消息是 批量发送+异步的方式来发送,性能提升,消息有序性无法保证;
三、消费者介绍
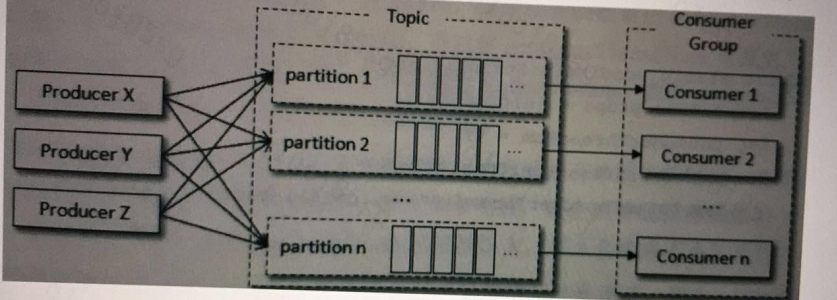
消费者是指调用poll方法的实体,可以是一个线程,也可以是一个服务;
为了避免消费者的浪费,消费者数量要小于partition数量;
3、拉取、处理消息模型
(1)同步消息处理:一个线程对应一个partiton,能够保证partiton内消息有序,消费性能受限于处理消息的速度。
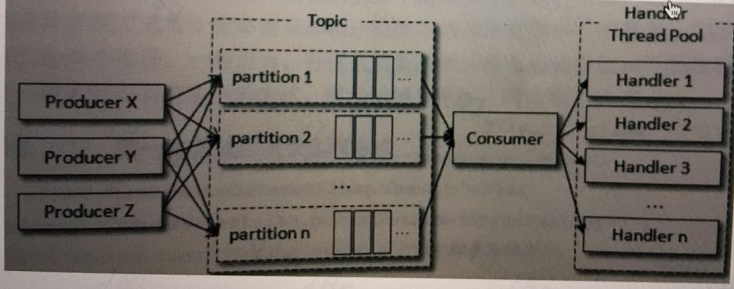
(2)异步处理消息:一个线程负责拉取消息,线程池负责处理消息的模式,不能保证partition内消息有序,消息消费速度快,节省tcp连接开销。
四、消息有序性及重复性
1、消息乱序产生原因:
(1)发送者:异步发送 + 发送失败重试导致的消息乱序
(2)接收者:单个拉消息的线程,多线程同时处理消息的先后顺序不同,导致消息被处理的时间乱序;
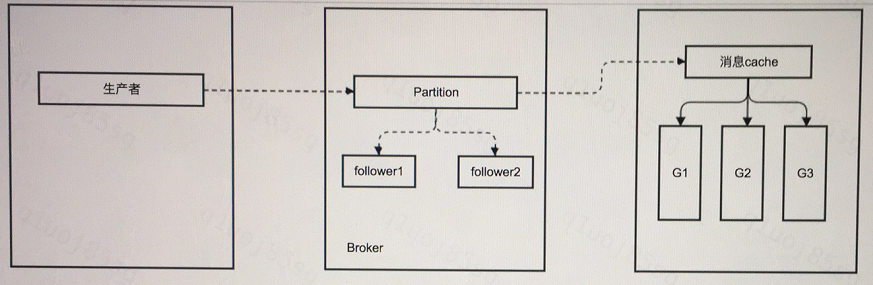
多个拉消息的线程,由于gc导致的消息被处理的乱序;
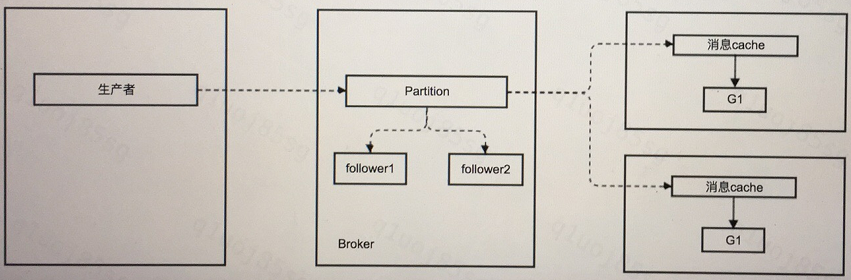
(3)broker:单partition内消息有序,多个partition之间消息无序;
2、消息重复产生原因
消费者提交消息offset与真正处理消息的时差导致的消息重复消费;
增加消费者引起的partiton与消费者之间的“再均衡”导致的消息重复消费;
结论,在保证性能的前提下,消息中间件不可能保证消息不重复投递,除非牺牲性能和高可用,需要下游做幂等。
3、从业务角度看到消息有序
要保证消息的严格有序,需要生产者、消费者、broker之间严密的配合并且牺牲掉系统的并发性,例如将topic的partiton设置为1个。而对于99%的业务需求来说,并不需要100%的按照时间戳的全局严格有序。
可以将全局消息拆成按照业务类型分区的有序,例如订单A的发单、完单、支付与订单B的发单、完单、支付之间并不需要严格有序,但是订单内各种事件的消息顺序却很重要,一个业务需要首先发单事件,并且在随后的支付事件时依赖于前面那个发单事件的一些属性。
所以我们可以将全局的消息按照业务属性拆成局部有序。
从上面的分析看,要保证消息有序性就要降低系统并行度,系统整体吞吐量下降。
严格的按照消息生产的时间戳有序是几乎不可能实现的,所以一个可用的系统是在正常情况下保证消息有序,在几种异常情况下允许乱序,并且对这几种异常情况导致的乱序做好监控和补救措施。
对于消息重复的情况,应该要求下游做好幂等,不能完全依赖于mq,因为mq在保证高可用和高吞吐凉的前提下是不可能做到消息不重复的。
【消息中间件】kafka的更多相关文章
- Spring Boot 2.0 教程 | 快速集成整合消息中间件 Kafka
欢迎关注个人微信公众号: 小哈学Java, 每日推送 Java 领域干货文章,关注即免费无套路附送 100G 海量学习.面试资源哟!! 个人网站: https://www.exception.site ...
- Spring Boot 2.0 快速集成整合消息中间件 Kafka
欢迎关注个人微信公众号: 小哈学Java, 每日推送 Java 领域干货文章,关注即免费无套路附送 100G 海量学习.面试资源哟!! 个人网站: https://www.exception.site ...
- 消息中间件kafka+zookeeper集群部署、测试与应用
业务系统中,通常会遇到这些场景:A系统向B系统主动推送一个处理请求:A系统向B系统发送一个业务处理请求,因为某些原因(断电.宕机..),B业务系统挂机了,A系统发起的请求处理失败:前端应用并发量过大, ...
- 消息中间件——kafka
1.1.1 什么是消息中间件 消息中间件利用高效可靠的消息传递机制进行平台无关的数据交流,并基于数据通信来进行分布式系统的集成.通过提供消息传递和消息排队模型,它可以在分布式环境下扩展进程间的通信.对 ...
- SpringBoot中使用消息中间件Kafka实现Websocket的集群
1.在实际项目中,由于数据量的增大及并发数的增多,我们不可能只用一台Websocket服务,这个时候就需要用到Webscoket的集群.但是Websocket集群会遇到一些问题.首先我们肯定会想到直接 ...
- 为什么你要使用这么强大的分布式消息中间件——kafka
为什么是kafka? 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到这样的一些问题: 我们想分析下用户行为(pageviews),以便我们设计出更好的广告位 我想对用户的搜索关键词进行统 ...
- 消息中间件kafka学习记录
目录 1. 概述 2. 环境准备 3. 命令行常用命令 4. java api实现 1. 概述 Apache Kafka是一个分布式消息系统,凭借其优异的特性而被广泛使用. 高性能:O(1)复杂度消息 ...
- 高并发系列之——MQ消息中间件Kafka
1.前言 1.1 包路径和源码 下载链接 基于发布订阅的分布式消息系统,使用scala语言编写. 特点:采用分区机制,每个分区可以放到不同的服务器上,提高了吞吐率,同时基于磁盘存储,以及副本机制可以确 ...
- 消息中间件 kafka rabbitmq 选型差异
https://www.zhihu.com/question/43557507 https://baijiahao.baidu.com/s?id=1610644333184173190&wfr ...
- 消息中间件--kafka(1)安装部署
一.概念 1.什么是kafka Kafka是由Apache软件基金会开发的一个开源的分布式流处理平台,由LinkedIn公司开发,使用 Scala和Java编写.Kafka是一个分布式.分区的.多副本 ...
随机推荐
- spring boot 尚桂谷学习笔记05 ---Web
------web 开发登录功能------ 修改login.html文件:注意加粗部分为 msg 字符串不为空时候 才进行显示 <!DOCTYPE html> <!-- saved ...
- 洛谷P2387 [NOI2014]魔法森林(LCT)
魔法森林 题目传送门 解题思路 把每条路按照\(a\)的值从小到大排序.然后用LCT按照b的值维护最小生成树,将边按照顺序放入.如果\(1\)到\(n\)有了一条路径,就更新最小答案.这个过程就相当于 ...
- USACO 5.5 章节
Picture 题目大意 IOI 1998 求n (<=5000)个矩形 覆盖的图形 的周长(包括洞), 坐标范围[-10000,10000] 题解 一眼离散化+2维线段树,但仔细一想 空间不太 ...
- kaggle-制作评分卡
https://blog.csdn.net/zpxcod007/article/details/80118580 制作A卡,申请评分卡 数据集:15万个样本,特征 主要预处理手段:缺失值,异常值,样本 ...
- FTP- Download, upload, Delete & find files
Public Function Func_FTP(Operation,ServerName,UserName,Password,RemoteLocation,LocalLocation) 'Set u ...
- 1.如何在JMeter中使用JUnit
您是否需要在测试过程中使用JUnit? 要回答这个问题,我们先来看看单元测试. 单元测试是软件测试生命周期中测试的最低分辨率. 运行单元测试时,需要在应用程序中使用最小的可测试功能,将其与其他代码隔离 ...
- [ERR] 1114 - The table 'xxx' is full
异常原因: 磁盘空间不足 解决办法: 1. 新增磁盘 2. 删除无用数据 信息补充: df: df -h #查询磁盘空间命令 du: du|sort -nr|more #显示目录或者文件所占空间 du ...
- $vim$配置以及$linux$
vim的配置 1 set nu "设置行标号 2 set tabstop=4 "这一条以及以下三条都把缩进设为4 3 set shiftwidth=4 4 set softtabs ...
- Https socket 连接
介: 本文主要介绍了网络安全通讯协议 SSL/TLS 和 Java 中关于安全通讯的实现部分.并通过一个简单的样例程序实现,来展示如何在 Java 平台上正确建立安全通讯. 在人类建立了通信系统之后, ...
- SetViewportOrgEx和SetWindowOrgEx
在MM_TEXT映射模式下使用这两个函数. 对于 BOOL SetViewportOrgEx( HDC hdc, // 设备内容HANDLE int X, // 新Viewport的x坐标 int Y ...